使用jsoup爬虫抓取一个URL
这两天开始写爬虫,本意是想在各大音乐网站上爬些音乐到本地来听的。后来发现这好像并没有我想象的那么容易,我也是醉了。索性把我学习爬虫的经过写成博客,慢慢总结吧。
爬虫最重要的部分就在于如何解析获取到的HTML文档,在这方面我使用了jsoup,一个简单好用的HTML解析器。通过Maven注入到项目之中。我一开始练习爬数据的网站是http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/index.html,里面的数据正好可以满足初学者的练习使用。
这是完整的代码:
package root.worm;
import org.jsoup.Jsoup;
import org.jsoup.helper.Validate;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.PrintWriter;
public class GetMessageFromWeb{
//主程序方法
public static void main(String[] args) throws IOException {
String URL = args[0];
System.out.println("正在抓取"+URL+"......");
//开始抓取URL中的HTML文档
Search(URL);
}
//递归的URL抓取
public static void Search(String URL) throws FileNotFoundException {
//通过网络/本地获取到了HTML文本
String FileName = "本地html保存";
Document document = GetLoccalHtmlText(URL,FileName);
//根据要抓取网页的信息来决定抓取的方式以及配置,这需要我们对要爬取的网页的源码有一定的了解
//根据网页源码,数据都在含有class属性的tr标签中,使用此方法可以抽取所有满足条件的元素
Elements elements = document.select("tr[class]");
//接下来是我需要在整个HTML文档中抓取的重要信息
//-----------------------------------------------------------------------
System.out.println("在整个文档内抓取的关键信息如下:");
for (Element element : elements){
//抓取地区名称信息
System.out.print(element.text()+" ");
// 抓取下一层地区的绝对路径并打印
String AfterPlace = element.select("td")
.last().select("a[href]").attr("abs:href");
System.out.println(AfterPlace);
}
//-----------------------------------------------------------------------
//Document就是抓取到的HTML文档,在jsoup中它被封装成了对象
System.out.println("抓取到的网页源码");
//这是抓取到的全部HTML文档
System.out.println(document);
}
//从网络上获取HTML文本
public static Document GetWebHtmlText(String URL){
Document document = null;
try {
//直接向URL发出GET请求获取HTML文档(Document)
document = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}
//从本地获取HTML文本,一般来说对于一个网站只爬取一次,然后直接把文档存在本地
//这是为了防止每次都从URL中获取Document而产生的403错误
public static Document GetLoccalHtmlText(String URL, String FileName) {
String FilePath = "C:\\Users\\Lenovo\\Desktop\\"+FileName+".html";
File file = new File(FilePath);
Document document = null;
try {
document = Jsoup.parse(file,"UTF-8");
} catch (IOException e) {
System.out.println("本机没有此文件,正在抓取中......");
//从网络上获取Document
document = GetWebHtmlText(URL);
System.out.println("抓取成功!\n保存中......");
//对这个网站的爬取会出现绝对地址和相对地址的问题
//我采取的方法是:在保存到本地的时候对Document中的URL地址做修改,使其变成绝对路径
//因为我是在文档保存的方法里进行的操作,所以Document要作为参数被传入到方法里
document = Save_Text(document,URL,FileName);
System.out.println("保存成功!");
}
return document;
}
//把HTML文档存储在本地
public static Document Save_Text(Document document, String Url, String FileName){
String FilePath = "C:\\Users\\Lenovo\\Desktop\\"+FileName+".html";
File file = new File(FilePath);
Integer Flag = 0;
try {
//定义输出流
PrintWriter printWriter = new PrintWriter(file);
//获取页面中带有class属性的tr标签,就是存放信息的标签,可以通过浏览器获取到相关信息
Elements elements = document.select("tr[class]");
//因为要把网页上的文档保存到本地,保存的时候使用的是UTF-8编码,所以本地文档中的编码也需要调整成UTF-8
document.select("meta").attr("content","charset=UTF-8");
//从访问的URL中获得绝对路径的前半部分
String Before_Url = Url.substring(0,Url.lastIndexOf("/")+1);
//对每一个标签做遍历
for (Element element : elements) {
//列名后没有地址,所以第一次不能打印(根据网页元素的排列而设定)
Flag++;
if(Flag > 1) {
//每个标签中含有两个标签,我们要的是最后一个标签中的标签的href元素
//绝对路径的前半部分+后半部分即为该URL中的URL的地址
String After_Url = element.select("td").last().
select("a[href]").attr("href");
//这就是合成出来的绝对地址
String Abs_Url = Before_Url + After_Url;
//把Document中的相对路径换成绝对路径
element.select("td").last().
select("a[href]").attr("href", Abs_Url);
}
}
//文档经过修改后存放在本地
//存的时候采用UTF-8编码,因为本地都采用的是UTF-8编码
printWriter.println(new String(document.toString().getBytes("UTF-8")));
printWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}
}
现在一步一步的来看抓取的思路。
抓取思路
一、Document查找
首先查找是否存在本地HTML文档,第一次的话肯定是没有的,所以一开始的时候需要在URL中获取到HTML文档(Document)
//从本地获取HTML文本,一般来说对于一个网站只爬取一次,然后直接把文档存在本地
//这是为了防止每次都从URL中获取Document而产生的403错误
public static Document GetLoccalHtmlText(String URL, String FileName) {
String FilePath = "C:\\Users\\Lenovo\\Desktop\\"+FileName+".html";
File file = new File(FilePath);
Document document = null;
try {
document = Jsoup.parse(file,"UTF-8");
} catch (IOException e) {
System.out.println("本机没有此文件,正在抓取中......");
//从网络上获取Document
document = GetWebHtmlText(URL);
System.out.println("抓取成功!\n保存中......");
//对这个网站的爬取会出现绝对地址和相对地址的问题
//我采取的方法是:在保存到本地的时候对Document中的URL地址做修改,使其变成绝对路径
//因为我是在文档保存的方法里进行的操作,所以Document要作为参数被传入到方法里
document = Save_Text(document,URL,FileName);
System.out.println("保存成功!");
}
return document;
}这个方法的逻辑是这样的:先查找本地文件是否存在对应的HTML文档,如果没有就直接调用GetWebHtmlText()方法,从网页上获取。获取成功后,直接把获取到的HTML文档(Document)保存在本地文件中。在下一次爬取的时候就可以直接从本地获取到Document了,不用再去URL获取了。注释中的问题在后面有解释。
二、从URL中获得Document
第一次启动程序,本地文件中是不存在HTML文档的,所以按照上面方法的结论,此时应该从URL中获取。
//从网络上获取HTML文本
public static Document GetWebHtmlText(String URL){
Document document = null;
try {
//直接向URL发出GET请求获取HTML文档(Document)
document = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}这里使用的HTML解析器是jsoup,它提供了一系列方法来获取Document,这里可以直接来通过URL获取其网页的HTML文档,获取文档直接返回就可以了。
三、Document保存到本地
刚刚在保存的方法之前,有一段注释说了绝对路径和相对路径的问题。我在这里先解释一下:
首先看下,第一次直接从网页上获得的完整的Document
2017年统计用区划代码

统计用区划代码
名称
140100000000
太原市
140200000000
大同市
140300000000
阳泉市
140400000000
长治市
140500000000
晋城市
140600000000
朔州市
140700000000
晋中市
140800000000
运城市
140900000000
忻州市
141000000000
临汾市
141100000000
吕梁市
阳泉市
可以看出来,href属性的值都为绝对路径,这是因为这些数据都是直接从网上拿下来的,没有经过任何处理,而且,我在一开始主要信息抓取的地方使用了:
String AfterPlace = element.select("td").last().select("a[href]").attr("abs:href");在进行href属性提取的时候我提取的是绝对路径,所以,最终我抓取出的数据为:

这些数据就是从网络直接拿来的Document中一模一样的一部分,现在其实还没什么问题,但是如果Document保存到文件中,第二次从文件中提取Document的时候就会出现问题了。
相对地址和绝对地址
先看下人家的网页源码
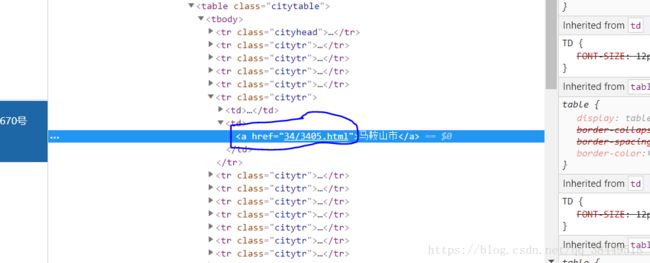
上面通过URL直接获取的Document中的href属性是绝对路径啊,但是这里为啥是相对路径呢?
这是因为这个网站相当于一个项目,是运行在服务器的目录下的,我们直接通过URL获取的Document中是含有这个网站的项目目录的。绝对路径就是这里的相对路径加上项目目录。所以一开始的Document中式可以拿出来绝对路径的。
但是保存在文件里的Document是不含有网站的项目路径的,所以显而易见的就不能获取绝对路径了,只会拿到相对路径,是没什么用的,也点不进去。
解决方法是:我们可以把相对路径先提取出来,绝对路径的话,可以从要爬取的URL上获得,两者拆分拼接一下就成为绝对路径了,然后用绝对路径替换掉相对路径再保存到文件里,不就解决问题了么。
路径替换
//把HTML文档存储在本地
public static Document Save_Text(Document document, String Url, String FileName){
String FilePath = "C:\\Users\\Lenovo\\Desktop\\"+FileName+".html";
File file = new File(FilePath);
Integer Flag = 0;
try {
//定义输出流
PrintWriter printWriter = new PrintWriter(file);
//获取页面中带有class属性的tr标签,就是存放信息的标签,可以通过浏览器获取到相关信息
Elements elements = document.select("tr[class]");
//因为要把网页上的文档保存到本地,保存的时候使用的是UTF-8编码,所以本地文档中的编码也需要调整成UTF-8
document.select("meta").attr("content","charset=UTF-8");
//从访问的URL中获得绝对路径的前半部分
String Before_Url = Url.substring(0,Url.lastIndexOf("/")+1);
//对每一个标签做遍历
for (Element element : elements) {
//列名后没有地址,所以第一次不能打印(根据网页元素的排列而设定)
Flag++;
if(Flag > 1) {
//每个标签中含有两个标签,我们要的是最后一个标签中的标签的href元素
//绝对路径的前半部分+后半部分即为该URL中的URL的地址
String After_Url = element.select("td").last().
select("a[href]").attr("href");
//这就是合成出来的绝对地址
String Abs_Url = Before_Url + After_Url;
//把Document中的相对路径换成绝对路径
element.select("td").last().
select("a[href]").attr("href", Abs_Url);
}
}
//文档经过修改后存放在本地
//存的时候采用UTF-8编码,因为本地都采用的是UTF-8编码
printWriter.println(new String(document.toString().getBytes("UTF-8")));
printWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}有详细的注释,也就不用多说什么了。
路径替换完毕后直接存到文件里就可以了,这里一定要注意编码的转换,要不然全都是乱码。
现在展示一下:
一、先启动程序,从网页获取Document

嗯现在抓取到了想要的信息了。
二、本地文件查看
没有乱码,网页爬下来了。
三、第二次爬取(从文件中)

抓取到了绝对路径,可以直接点进去。
这只是小练习,总结一下,仅供个人学习使用。