MapReduce中Shuffle机制的学习案例——房屋租赁信息
MapReduce中Shuffle机制的学习案例——房屋租赁信息
由于在《自己动手搭建一个简单的基于Hadoop的离线分析系统》系列中直接将清洗后的数据导入Hive中进行分析,没有使用到Hadoop中的MapReduce框架,因此这篇文章将通过该框架对输入数据进行清洗,并对清洗后的数据经行分析,数据源仍来源于同一网站的网络爬虫。
Hadoop版本:2.6.5
Shuffle机制
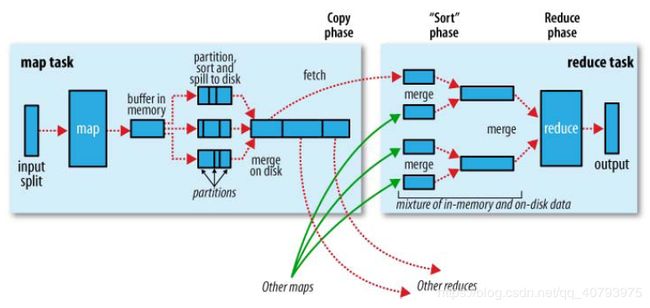
上图是MapReduce框架的原理图,其中Shuffle框架指的是“如何将Map阶段处理的数据传递给Reduce阶段”,具体过程是:
- 首先,经由Map处理过的信息不是直接写入文件中,而是写入本地的环形缓冲区中。
- 当缓冲区发生溢出时,通过键的compareTo方法对键-值对进行快速排序,并进行分区操作(如果配置了Reduce个数和自定义的Partitioner类,默认根据键执行Hash分组),然后写入到本地文件中,这个文件是不断进行滚动的,当产生新的溢出时,将会滚动到下一个文件进行上述操作。
- 缓冲区每次产生新的溢出时,新文件将会和旧文件一起进行合并,这里的“合并”是针对各个分区进行归并排序,这个操作在Map执行任务期间会运行多次。
- Reduce端将根据自己所属的分区号,从各个Map端的输出中提取出属于自己的一部分键-值对,并对这些来自于不同Map的键-值对进行归并排序,这个过程将会在内存与本地磁盘上执行多次。
- 归并排序后的键-值对集合中,相同键(可以根据Grouping进行自定义)的键-值对将作为一个输入被Reduce端进行读取,并做执行后续操作。
案例任务与相关类
1. 输入数据
房屋详细租赁信息,例如:
北京市 北京市 海淀区 338(总租金) 45(房屋面积) 2(居住人数) 北京市海淀区复兴路61号院 地铁万寿路直达天安门、301医院、美尔目医院
2. 输出数据
各个区/县的最高租金与详细租赁信息、最低租金与详细租赁信息、平均租金(元/人),并按照所属省进行归类输出,例如:
MAXINFO:北京市 北京市 东城区 398(总租金) 46(房屋面积) 2(居住人数) 北京市东城区广渠门夕照寺中街绿景苑小区六号一单元四楼 199.0(人均租金)
MININFO:北京市 北京市 东城区 520(总租金) 90(房屋面积) 7(居住人数) 北京市东城区冠城名敦道 74.28571(人均租金)
MEANPRICE:115.69858(人均租金)
3. Map类(M3RentinfoMapper)
将输入数据根据所需字段进行切分,切分后的信息封装为一个自定义类(RentinfoBean),自定义键(ComparableBean)并实现排序方法,将ComparableBean与RentinfoBean作为键-值对进行输出,例如:
ComparableBean [city=上海市, zone=浦东新区, priceforone=91.6] 上海市 上海市 浦东新区 458(总租金) 60(房屋面积) 5(居住人数) 上海市浦东新区陆家嘴街道钱仓路313弄
4. Reduce类(M3RentinfoReducer)
将输入数据进行相应处理,得到输出数据。
5. Shuffle相关类
自定义分区Partitioner类(PartitionBean)
自定义GroupingComparator类(GroupingBean)
自定义键的排序方法、Partitioner、GroupingComparator
自定义键的排序方法
MapReduce程序在处理数据的过程中会对数据排序(例如,Map输出的键-值对传输到Reduce端之前,会进行排序),排序的依据是Map输出的键,所以,我们如果要自定义排序方法,可以考虑将排序因素放到键中,让键实现 W r i t a b l e C o m p a r a b l e WritableComparable WritableComparable接口。
基本思路:自定义的类 C o m p a r a b l e B e a n ComparableBean ComparableBean实现 W r i t a b l e C o m p a r a b l e WritableComparable WritableComparable接口并封装排序所需信息,然后重写键的 c o m p a r e T o compareTo compareTo方法,并将该类作为Map输出的键。由于需要根据不同省对各自区\县的租金(元/人)进行分析,因此需要将市(city)、区/县(zone)和租金(priceforone)封装到 C o m p a r a b l e B e a n ComparableBean ComparableBean中。
package bean;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class ComparableBean implements WritableComparable<ComparableBean> {
//设置key中包含的字段:市、区、价格/人
private String city;
private String zone;
private String priceforone;
/**
* @return the city
*/
public String getCity() {
return city;
}
/**
* @param city the city to set
*/
public void setCity(String city) {
this.city = city;
}
/**
* @return the zone
*/
public String getZone() {
return zone;
}
/**
* @param zone the zone to set
*/
public void setZone(String zone) {
this.zone = zone;
}
/**
* @return the priceforone
*/
public String getPriceforone() {
return priceforone;
}
/**
* @param priceforone the priceforone to set
*/
public void setPriceforone(String priceforone) {
this.priceforone = priceforone;
}
/* (non-Javadoc)
* @see java.lang.Object#toString()
*/
@Override
public String toString() {
return "ComparableBean [city=" + city + ", zone=" + zone + ", priceforone=" + priceforone + "]";
}
@Override
public void readFields(DataInput input) throws IOException {
this.city = input.readUTF();
this.zone = input.readUTF();
this.priceforone = input.readUTF();
}
@Override
public void write(DataOutput output) throws IOException {
output.writeUTF(this.city);
output.writeUTF(this.zone);
output.writeUTF(this.priceforone);
}
//实现自定义compareTo方法
@Override
public int compareTo(ComparableBean o) {
int samecity = this.city.compareTo(o.city);
if (samecity == 0) {
int samezone = this.zone.compareTo(o.zone);
if (samezone == 0) {
return -Float.compare(Float.parseFloat(this.getPriceforone()), Float.parseFloat(o.getPriceforone()));
} else {
return samezone;
}
} else {
return samecity;
}
}
}
自定义Partitioner
Mapreduce中会将Map输出的键-值对,按照相同键进行分组,然后分发给不同的Reduce,默认的分发规则是根据键的hashcode%reduce数量来进行分发,因此,如果要按照我们自己的需求进行分区,则需要改写数据分发(分区)组件Partitioner。
基本思路:自定义一个 P a r t i t i o n B e a n PartitionBean PartitionBean继承抽象类 P a r t i t i o n e r Partitioner Partitioner,实现 g e t P a r t i t i o n getPartition getPartition方法并根据Map输出值 R e n t i n f o B e a n RentinfoBean RentinfoBean的 p r o v i n c e province province划分到对应分区中,并将该类作为任务所需的Partitioner类:job.setPartitionerClass(PartitionBean.class)。
package bean;
import java.util.HashMap;
import org.apache.hadoop.mapreduce.Partitioner;
public class PartitionBean extends Partitioner<ComparableBean, RentinfoBean> {
static HashMap<String, Integer> provincemap = new HashMap<String, Integer>();
static {
provincemap.put("北京市", 0);
provincemap.put("天津市", 1);
provincemap.put("重庆市", 2);
provincemap.put("上海市", 3);
}
//实现自定义getPartition方法
@Override
public int getPartition(ComparableBean kBean, RentinfoBean vBean, int numofpart) {
Integer partcode = provincemap.get(vBean.getProvince());
return partcode == null?numofpart:partcode;
}
}
自定义GroupingComparator
由于在Reduce端归并排序后的键-值对集合中,相同键的键-值对将作为一个输入被Reduce端进行读取,因此,我们可以通过自定义 G r o u p i n g C o m p a r a t o r GroupingComparator GroupingComparator类,实现自定义集合划分。
基本思路:自定义一个 G r o u p i n g B e a n GroupingBean GroupingBean继承 W r i t a b l e C o m p a r a t o r WritableComparator WritableComparator类,并根据集合划分所需要的信息重写该类的 c o m p a r e compare compare方法,将该类作为任务所需的GroupingComparator类:job.setGroupingComparatorClass(GroupingBean.class)。由于我们需要将具有相同的区/县信息划分为一个集合,因此需要将Map输出键 C o m p a r a b l e B e a n ComparableBean ComparableBean中的city和zone字段作为 c o m p a r e compare compare方法的依据,忽略不同租金对集合划分的影响。
package bean;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class GroupingBean extends WritableComparator {
protected GroupingBean() {
super(ComparableBean.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a, WritableComparable b) {
ComparableBean aBean = (ComparableBean) a;
ComparableBean bBean = (ComparableBean) b;
int samecity = aBean.getCity().compareTo(bBean.getCity());
if (samecity == 0) {
return aBean.getZone().compareTo(bBean.getZone());
} else {
return samecity;
}
}
}
Mapper与Reducer
static class M3RentinfoMapper extends Mapper<LongWritable, Text, ComparableBean, RentinfoBean> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ComparableBean, RentinfoBean>.Context context)
throws IOException, InterruptedException {
rentinfoBean = RentinfoPaser.parse(value.toString());
//获取房租价格/人
priceforonetemp = (Float.parseFloat(rentinfoBean.getPrice()) / Float.parseFloat(rentinfoBean.getNumofpp()));
comparableBean.setCity(rentinfoBean.getCity());
comparableBean.setZone(rentinfoBean.getZone());
comparableBean.setPriceforone(String.valueOf(priceforonetemp));
context.write(comparableBean, rentinfoBean);
}
}
static class M3RentinfoReducer extends Reducer<ComparableBean, RentinfoBean, NullWritable, M3InfoBean> {
@Override
protected void reduce(ComparableBean key, Iterable<RentinfoBean> values,
Reducer<ComparableBean, RentinfoBean, NullWritable, M3InfoBean>.Context context)
throws IOException, InterruptedException {
float sum_priceforonetemp = 0;
float priceforone = 0;
M3InfoBean bean = new M3InfoBean();
int infoBeannum = 1;
RentinfoBean rentinfoBean = new RentinfoBean();
for (RentinfoBean value : values) {
priceforone = Float.parseFloat(value.getPrice()) / Float.parseFloat(value.getNumofpp());
sum_priceforonetemp += priceforone;
if (infoBeannum == 1) {
bean.setMaxrentinfo(value.toString().concat("\001").concat(String.valueOf(priceforone)));
}
rentinfoBean = value;
infoBeannum ++;
}
bean.setMinrentinfo(rentinfoBean.toString().concat("\001").concat(String.valueOf(priceforone)));
bean.setMeanrentinfo(String.valueOf(sum_priceforonetemp / (infoBeannum - 1)));
context.write(NullWritable.get(), bean);
}
}
程序完整代码与各阶段输出
源数据、代码与输出文件
链接:https://pan.baidu.com/s/1UOH4_vP53OjI5LVmQ3rgiQ
提取码:vkcp