【学习点滴】linux调试工具、cmake和网络抓包
目录
gdb
多进程调试
多线程调试:
gdb底层原理
Linux下查看服务器端的并发连接个数:
Valgrind
memcheck
strace
Linux下,绑定1024以下的端口需要root权限!
webbench 压测工具
wireshark 网络抓包记录
tcpdump
traceroute
iftop
iperf
perf
linux下各种日志
makefile 的编写
cmake 的编写
VIM的常用操作
这是一篇工具博客,记录了各种工具的使用和体验
gdb
编译cpp文件应使用g++
若运行错误程序不产生core文件,可使用
ulimit -a
来查看当前是否开启
先用#ulimit -a可以查看系统core文件的大小限制(第一行),core文件大小设置为0, 即没有打开core dump设置;我这个是改变了的。
user@ubuntu:~/usegdb$ ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 8333
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 8333
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
临时改变方法:
使用#ulimit -c [kbytes]可以设置系统允许生成的core文件大小;
ulimit -c 0 不产生core文件
ulimit -c 100 设置core文件最大为100k
ulimit -c unlimited 不限制core文件大小
永久改变方法:
#vi /etc/profile 然后,在profile中添加:
ulimit -c 1073741824
(但是,若将产生的转储文件大小大于该数字时,将不会产生转储文件)
或者
ulimit -c unlimited
这样重启机器后生效了。 或者, 使用source命令使之马上生效。
#source /etc/profile
更改core dump生成路径
因为core dump默认会生成在程序的工作目录,但是有些程序存在切换目录的情况,导致core dump生成的路径没有规律,
所以最好是自己建立一个文件夹,存放生成的core文件。
我建立一个 /data/coredump 文件夹,在根目录data里的coredump文件夹。
调用如下命令
echo /data/coredump/core.%e.%p> /proc/sys/kernel/core_pattern
将更改core文件生成路径,自动放在这个/data/coredump文件夹里。
%e表示程序名, %p表示进程id

设置 Core Dump 的核心转储文件目录和命名规则
/proc/sys/kernel/core_uses_pid 可以控制产生的 core 文件的文件名中是否添加 pid 作为扩展 ,如果添加则文件内容为 1 ,否则为 0
proc/sys/kernel/core_pattern 可以设置格式化的 core 文件保存位置或文件名 ,比如原来文件内容是 core-%e
可以这样修改 :
echo "/corefile/core-%e-%p-%t" > core_pattern
将会控制所产生的 core 文件会存放到 /corefile 目录下,产生的文件名为 core- 命令名 -pid- 时间戳
以下是参数列表 :
%p - insert pid into filename 添加 pid
%u - insert current uid into filename 添加当前 uid
%g - insert current gid into filename 添加当前 gid
%s - insert signal that caused the coredump into the filename 添加导致产生 core 的信号
%t - insert UNIX time that the coredump occurred into filename 添加 core 文件生成时的 unix 时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加命令名
core文件的使用
在core文件所在目录下键入:
gdb -c core (-c指定core文件)
它会启动GNU的调试器,来调试core文件,并且会显示生成此core文件的程序名,中止此程序的信号等等
如果你已经知道是由什么程序生成此core文件的,比如MyServer崩溃了生成core.12345,那么用此指令调试:
gdb -c core MyServer
内核映像转储(dump core),内核映像转储是指将进程数据在内存的映像和进程在内核结构中的部分内容以一定格式转储到文件系统,并且进程退出执行,这样做的好处是为程序员 提供了方便,使得他们可以得到进程当时执行时的数据值,允许他们确定转储的原因,并且可以调试他们的程序。
gdb使用:
bt=back trace 打印堆栈信息:
首先信件一个bengkui.cpp文件写入如下程序
#include
#include
using namespace std;
void core_test1()
{
int i = 0;
//below will call segmentfault
scanf("%d", i);
printf("%d", i);
}
int main()
{
core_test1();
return 0; 该程序在core_test1()内部scanf的时候回崩溃,i前面应该加上&
编译的时候带上-g选项,这样才能用gdb调试core
g++ bengkui.cpp -g -o benkui接着运行程序./bengkui
输入2就会触发 段错误(核心转储),
user@ubuntu:~/study$ ./bengkui
2
段错误 (核心已转储)
user@ubuntu:~/study$ ll
总用量 584
drwxrwxr-x 3 user user 4096 Apr 24 20:09 ./
drwxr-xr-x 23 user user 4096 Apr 24 19:59 ../
-rwxrwxr-x 1 user user 19704 Apr 20 10:35 bengkui*
-rw-rw-r-- 1 user user 228 Apr 20 10:35 bengkui.c
-rw------- 1 user user 561152 Apr 24 20:09 core
drwxrwxr-x 2 user user 4096 Feb 24 21:38 socket_demo/
然后用gdb调试这个程序
gdb ./bengkui core在gdb下使用 r 来运行程序,出现段错误,然后bt即可看进程退出时的栈的内存状态
(gdb) r
Starting program: /home/user/study/bengkui
2
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff76eade5 in _IO_vfscanf_internal (s=, format=,
argptr=argptr@entry=0x7fffffffe238, errp=errp@entry=0x0) at vfscanf.c:1902
(gdb) bt
#0 0x00007ffff76eade5 in _IO_vfscanf_internal (s=, format=,
argptr=argptr@entry=0x7fffffffe238, errp=errp@entry=0x0) at vfscanf.c:1902
#1 0x00007ffff76f587b in __scanf (format=) at scanf.c:33
#2 0x0000000000400769 in core_test1 () at bengkui.c:9
#3 0x0000000000400789 in main () at bengkui.c:17
(gdb) proc_info
Undefined command: "proc_info". Try "help".
(gdb) info proc
process 2335
cmdline = '/home/user/study/bengkui'
cwd = '/home/user/study'
exe = '/home/user/study/bengkui'
GDB 常用操作
上边的程序比较简单,不需要另外的操作就能直接找到问题所在。现实却不是这样的,常常需要进行单步跟踪,设置断点之类的操作才能顺利定位问题。下边列出了GDB一些常用的操作。
- 启动程序:run
- 设置断点:b 行号|函数名 如 b 22 或者 b main 多文件下打断点 b main.cpp:147
b +offset/-offset 在当前行的前面或者后面的offset停住
b filename:linenum 在某文件的某行打断点
b filename:function 在某文件某个函数入口处停住
b *address 在程序的运行地址处停住
b 没有参数在下一行停住
b where if condition 在满足条件的那一行停住
- 删除断点:delete 断点编号
- 禁用断点:disable 断点编号
- 启用断点:enable 断点编号
- 单步跟踪:next 也可以简写 n
- 单步跟踪:step 也可以简写 s
step count 一次性执行count步,有函数进入函数
next count 一次性执行count步,不进入函数
finish 运行函数,知道当前函数完成返回,并打印出函数返回时的堆栈地址、返回值和参数信息
until 退出循环体
- 打印变量:print 变量名字 如print i
x 按十六进制格式显示变量
d 按十进制格式显示变量
u 按十六进制格式显示无符号整型退出
o 按八进制格式显示变量
t 按二进制格式显示变量t 按二进制格式显示变量
a 按十六进制格式显示变量
c 按字符格式显示变量
f 按浮点数格式显示变量
- 设置变量:set var=value 如set var i=1
- 查看变量类型:ptype var
- 顺序执行到结束:cont
- 顺序执行到某一行: util lineno
- 打印堆栈信息:bt
frame x 切换到第x帧。其中x会在bt命令中显示,从0开始。0表示栈顶。简写为f。
up/down x 往栈顶/栈底移动x帧。当不输入x时,默认为1。
print x打印x的信息,x可以是变量,也可以是对象或者数组。简写为p。
print */&x 打印x的内容/地址。
call 调用函数。注意此命令需要一个正在运行的程序。
- 查看寄存器的内容:info registers/all-registers
- display 变量名 可以追踪变量的值 对应undisplay 变量编号 可以取消追踪(info display查看)
- info local 可以打印出当前所有的变量值
- finish 跳出当前函数
- u 跳出单次循环
- del或d 断点编号(info b可以查看) 可以删除断点
- ptype 变量名 可以看一个变量的类型
- list 显示多行源代码 如: list -30 显示第30行为中心的10行代码 list 函数名 显示此函数为中心的10行代码
list - 显示之前的代码
- watch 可设置观察点(watchpoint)。使用观察点可以使得当某表达式的值发生变化时,程序暂停执行。 如watch i
执行该命令前,必须保证程序已经运行
watch expr 为表达式expr设置一个观察点一旦表达式的值有变化,马上停止程序
rwatch expr 当表达式被读时,停住程序
awctah expr 当表达式的值被读或者背写时,停住程序
- continue 或 c 继续执行(如从上个断点往下)
- attach pid 可以调试正在运行的进程 (attach附着后,用正常的指令调试)
- detach 断开附着,使得程序继续正常运行
-
exammine命令:
查看内存地址的值。语法是:x/u addr
(gdb) attach 3273
Attaching to process 3273
[New LWP 3274]
[New LWP 3275]
[New LWP 3276]
[New LWP 3277]
[New LWP 3327]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007ff4a4285a13 in epoll_wait () at ../sysdeps/unix/syscall-template.S:84
84 ../sysdeps/unix/syscall-template.S: 没有那个文件或目录.
(gdb) bt
#0 0x00007ff4a4285a13 in epoll_wait () at ../sysdeps/unix/syscall-template.S:84
#1 0x000000000040ba23 in Epoll::poll (this=0x7ff4a3b67010)
at /home/user/WebServer-master/WebServer/Epoll.cpp:104
#2 0x000000000040c6d4 in EventLoop::loop (this=this@entry=0x7ffffcbedea0)
at /home/user/WebServer-master/WebServer/EventLoop.cpp:119
#3 0x000000000040a2bc in main (argc=3, argv=0x7ffffcbee028)
at /home/user/WebServer-master/WebServer/Main.cpp:53
ps -ef | grep "main"(main此处是可执行文件名)搜索到子进程pid
多进程调试
https://www.cnblogs.com/JN-PDD/p/6953136.html
1.单独调试子进程
我们可以先运行程序,然后再另一终端使用ps -ef | grep "main"(main此处是可执行文件名)搜索到子进程pid,然后启动gdb,在将其附加(attach)到gdb调试器上
attach child-pid 使用该命令后,直接run即可,和调试普通程序就没区别了
dettach 脱离进程
2.使用调试器选项follow-fork-mode
我们知道如果不设置任何选项,gdb默认调试父进程。调试器选项用法如下:
set follow-fork-mode mode 其中mode的可选值是parent和child,分别表示调试父进程和子进程。
info inferiors 查询正在调试的进程
inferior processnum 切换进程
默认设置下,在调试多进程程序时GDB只会调试主进程。但是GDB(>V7.0)支持多进程的分别以及同时调试,换句话说,GDB可以同时调试多个程序。只需要设置follow-fork-mode(默认值:parent)和detach-on-fork(默认值:on)即可。我们还可以使用catch fork指令,如果fork异常,会停止程序。
follow-fork-mode detach-on-fork 说明
parent on 只调试主进程(GDB默认)
child on 只调试子进程
parent off 同时调试两个进程,gdb跟主进程,子进程block在fork位置
child off 同时调试两个进程,gdb跟子进程,主进程block在fork位置
设置方法:set follow-fork-mode [parent|child] set detach-on-fork [on|off]
多线程调试:
gdb调试一般有两种模式:all-stop模式和no-stop模式(gdb7.0之前不支持no-stop模式)。
1.all-stop模式
在这种模式下,当你的程序在gdb由于任何原因而停止,所有的线程都会停止,而不仅仅是当前的线程。一般来说,gdb不能单步所有的线程。因为线程调度是gdb无法控制的。无论什么时候当gdb停止你的程序,它都会自动切换到触发断点的那个线程。
2.no-stop模式(网络编程常用)
顾名思义,启动不关模式。当程序在gdb中停止,只有当前的线程会被停止,而其他线程将会继续运行。这时候step,next这些命令就只对当前线程起作用。
gdb支持的命里有两种类型:前台的(同步的)和后台(异步 )的。区别很简单,同步的在输出提示符之前会等待程序report一些线程已经终止的信息,异步则是直接返回。所以我们需要set target-async 1。set pagination off不要出现 Type
下面是常用命令:
info threads 显示所有线程
thread
break filename:linenum thread all 在所有线程相应行设置断点,注意如果主线程不会执行到该行,并且启动all-stop模式,主线程执行n或s会切换过去 如break file.c:100 thread all 在file.c文件第100行处为所有经过这里的线程设置断点。
对指定线程或者所有线程执行同样的操作,比如查看调用栈信息:thread apply ID1 ID2/all bt
set scheduler-locking off|on|step
在使用step或者continue命令调试当前被调试线程的时候,其他线程也是同时执行的,
怎么只让被调试程序执行呢?
通过这个命令就可以实现这个需求。
off 不锁定任何线程,也就是所有线程都执行,这是默认值。
on 只有当前被调试程序会执行。
step 在单步的时候,除了next过一个函数的情况
(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,
只有当前线程会执行。
show scheduler-locking 显示当前模式
thread apply all command 每个线程执行同意命令,如bt。或者thread apply 1 3 bt,即线程1,3执行bt。
如thread apply 2 n 让线程2继续执行程序
主要是我们要用能用的上的,比如no-stop模式,一般多线程调试就很有用的。
使用示例:
线程产生通知:在产生新的线程时, gdb会给出提示信息
(gdb) r
Starting program: /root/thread
[New Thread 1073951360 (LWP 12900)]
[New Thread 1082342592 (LWP 12907)]---以下三个为新产生的线程
[New Thread 1090731072 (LWP 12908)]
[New Thread 1099119552 (LWP 12909)]
查看线程:使用info threads可以查看运行的线程。
(gdb) info threads
4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
* 1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb)
注意,行首为gdb分配的线程ID号,对线程进行切换时,使用该ID号码。
另外,行首的星号标识了当前活动的线程
切换线程:
使用 thread THREADNUMBER 进行切换,THREADNUMBER 为上文提到的线程ID号。
下例显示将活动线程从 1 切换至 4。
(gdb) info threads
4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
* 1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb) thread 4
[Switching to thread 4 (Thread 1099119552 (LWP 12940))]#0 0xffffe002 in ?? ()
(gdb) info threads
* 4 Thread 1099119552 (LWP 12940) 0xffffe002 in ?? ()
3 Thread 1090731072 (LWP 12939) 0xffffe002 in ?? ()
2 Thread 1082342592 (LWP 12938) 0xffffe002 in ?? ()
1 Thread 1073951360 (LWP 12931) main (argc=1, argv=0xbfffda04) at thread.c:21
(gdb)
以上即为使用gdb提供的对多线程进行调试的一些基本命令。
待我好好做个实际调试的例子
大牛调试教程:可以好好研究研究
https://blog.csdn.net/wu_cai_/article/details/79669842
gdb底层原理
gdb主要功能的实现依赖于一个系统函数ptrace,通过man手册可以了解到,ptrace可以让父进程观察和控制其子进程的检查、执行,改变其寄存器和内存的内容,主要应用于打断点(也是gdb的主要功能)和打印系统调用轨迹。
函数原型如下:
#include
long ptrace(enum __ptrace_request request, pid_t pid,void *addr, void *data); ptrace系统调用的request主要选项
- PTRACE_TRACEME
表示本进程将被其父进程跟踪,交付给这个进程的所有信号(除SIGKILL之外),都将使其停止,父进程将通过wait()获知这一情况。
- PTRACE_ATTACH
attach到一个指定的进程,使其成为当前进程跟踪的子进程,子进程的行为等同于它进行了一次PTRACE_TRACEME操作。但是,需要注意的是,虽然当前进程成为被跟踪进程的父进程,但是子进程使用getppid()的到的仍将是其原始父进程的pid。
这下子gdb的attach功能也就明朗了。当你在gdb中使用attach命令来跟踪一个指定进程/线程的时候,gdb就自动成为改进程的父进程,而被跟踪的进程则使用了一次PTRACE_TRACEME,gdb也就顺理成章的接管了这个进程。
- PTRACE_CONT
继续运行之前停止的子进程。可同时向子进程交付指定的信号。
更多参数请man ptrace。
gdb 2种调试方式
1)attach并调试一个已经运行的进程:
确定需要进行调试的进程id
运行gdb,输入attch pid,如:gdb 12345。gdb将对指定进行执行如下操作:ptrace(PTRACE_ATTACH,pid,0,0)
2)运行并调试一个新的进程
运行gdb,通过命令行参数或file指定目标调试程序,如gdb ./test
输入run命令,gdb执行下述操作:
通过fork()系统调用创建一个新进程
在新创建的子进程中调用ptrace(PTRACE_TRACEME,0,0,0)
在子进程中通过execv()系统调用加载用户指定的可执行文件
gdb调试的基础—信号
gdb调试的实现都是建立在信号的基础上的,在使用参数为PTRACE_TRACEME或PTRACE_ATTACH的ptrace系统调用建立调试关系后,交付给目标程序的任何信号首先都会被gdb截获。
因此gdb可以先行对信号进行相应处理,并根据信号的属性决定是否要将信号交付给目标程序。
- 1、设置断点:
断点原理:
1) 断点的实现原理,就是在指定的位置插入断点指令,当被调试的程序运行到断点的时候,产生SIGTRAP信号。该信号被gdb捕获并进行断点命中判定,当gdb判断出这次SIGTRAP是断点命中之后就会转入等待用户输入进行下一步处理,否则继续。
2) 断点的设置原理: 在程序中设置断点,就是先将该位置的原来的指令保存,然后向该位置写入int 3。当执行到int 3的时候,发生软中断,内核会给子进程发出SIGTRAP信号,当然这个信号会被转发给父进程。然后用保存的指令替换int3,等待恢复运行。
3) 断点命中判定:gdb把所有的断点位置都存放在一个链表中,命中判定即把被调试程序当前停止的位置和链表中的断点位置进行比较,看是断点产生的信号,还是无关信号。
4) 条件断点的判定:原理同3),只是恢复断点处的指令后,再多加一步条件判断。若表达式为真,则触发断点。由于需要判断一次,因此加入条件断点后,不管有没有触发到条件断点,都会影响性能。在x86平台,某些硬件支持硬件断点,在条件断点处不插入int 3,而是插入一个其他指令,当程序走到这个地址的时候,不发出int 3信号,而是先去比较一下特定寄存器和某个地址的内容,再决定是否发送int 3。因此,当你的断点的位置会被程序频繁地“路过”时,尽量使用硬件断点,会对提高性能有帮助。
- 2、next单步调试:
next指令可以实现单步调试,即每次只执行一行语句。一行语句可能对应多条及其指令,当执行next指令时,gdb会计算下一条语句对应的第一条指令的地址,然后控制目标程序走到该位置停止。ptrace本身支持单步功能,调用ptrace(PTRACE_SINGLESTEP,pid,...)即可。
Linux下查看服务器端的并发连接个数:
netstat -nat|grep ESTABLISHED|wc -l
这个返回的数字就是当前并发的连接数的了。
查看所有状态的个数:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
解释:
返回结果示例:
LAST_ACK 5 (正在等待处理的请求数)
SYN_RECV 30
ESTABLISHED 1597 (正常数据传输状态)
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057 (处理完毕,等待超时结束的请求数)
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
Valgrind
一个进程的空间是开辟在内存上的,包括栈、堆都是在内存上,只是分区不同,因此调试内存泄露实际上用ps -aux也可以进行判断,此进程的内存占用量是否一直在增长
原文:https://blog.csdn.net/ydyang1126/article/details/72667411
1. 什么是内存泄漏
内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的、大小任意的(内存块的大小可以在程序运行期决定)、使用完后必须显示释放的内存。应用程序一般使用malloc、realloc、new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块。否则,这块内存就不能被再次使用,造成这块内存泄漏。
2. 内存泄漏的检测
C++程序缺乏相应的手段来检测内存信息,只能使用top指令观察进程的动态内存总额。而且程序退出时,我们无法获知任何内存泄漏信息。
使用Linux命令回收内存:可以使用ps、kill两个命令检测内存使用情况和进行回收。
在使用超级用户权限时使用命令“ps”,它会列出所有正在运行的程序名称和对应的进程号(PID)。
kill命令的工作原理是向Linux操作系统的内核送出一个系统操作信号和程序的进程号(PID)。
3. Valgrind
3.1 Valgrind体系结构
Valgrind是一套Linux下,开源的仿真调试工具的集合。Valgrind由内核(core)以及基于内核的其他调试工具组成。内核类似于一个框架(framework),它模拟了一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的内存调试任务。Valgrind的体系结构如下图所示:
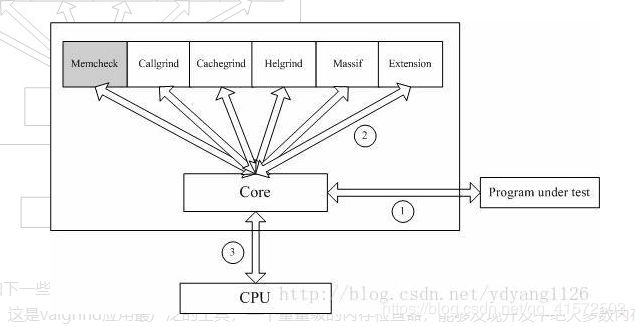
Valgrind包括如下一些工具:
1. Memcheck。这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。这也是本文将重点介绍的部分。
2. Callgrind。它主要用来检查程序中函数调用过程中出现的问题。
3. Cachegrind。它主要用来检查程序中缓存使用出现的问题。
4. Helgrind。它主要用来检查多线程程序中出现的竞争问题。
5. Massif。它主要用来检查程序中堆栈使用中出现的问题。
6. Extension。可以利用core提供的功能,自己编写特定的内存调试工具。
3.2 Valgrind.Memcheck 检测内存原理
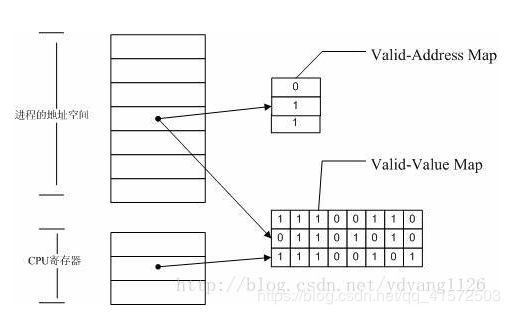
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。
1. Valid-Value 表:
对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于 CPU 的每个寄存器,也有一个与之对应的 bit 向量。这些 bits 负责记录该字节或者寄存器值是否具有有效的、已初始化的值。
2. Valid-Address 表
对于进程整个地址空间中的每一个字节(byte),还有与之对应的 1 个 bit,负责记录该地址是否能够被读写。
检测原理:
当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
如何知道那些地址是合法的(内存已分配)?
维护一张合法地址表(Valid-address (A) bits),当前所有可以合法读写(已分配)的地址在其中有对应的表项。该表通过以下措施维护- 全局数据(data, bss section)--在程序启动的时候标记为合法地址
- 局部变量--监控sp(stack pointer)的变化,动态维护
- 动态分配的内存--截获 分配/释放 内存的调用 :malloc, calloc, realloc, valloc, memalign, free, new, new[], delete and delete[]
- 系统调用--截获mmap映射的地址
- 其他--可以显示知会memcheck某地字段是合法的
局限:
-memcheck无法检测global和stack上的内存溢出(也无法检测我们自定义的内存池的内存泄露,因为自定义内存池的申请释放过程不经过malloc、free、new、delete),因为溢出的地方也在Valid-address (A) bits中。这是由memcheck 的工作原理决定的。
-慢,20到30倍,被虚拟CPU解释一遍,当然慢
-内存占用高,因为要维护两张表格,而这两张表的维度正比于程序的内存
3.3 Valgrind使用
第一步 准备可执行程序
1、为了使valgrind发现的错误更精确,能够定位到源代码行,建议在编译时加上-g参数。
2、编译优化选项请选择O0,虽然这会降低程序的执行效率。
示例程序文件名为:sample.c, 选用的编译器为gcc。
生成可执行程序
gcc –g –O0 sample.c –o sample
第二步 在valgrind下,运行可执行程序。
valgrind /sample
第三步:分析valgrind的输出信息。
Valgrind支持很多工具:memcheck,addrcheck,cachegrind,Massif,helgrind和Callgrind等。在运行Valgrind时,你必须指明想用的工具,如果省略工具名,默认运行memcheck。
memcheck
memcheck探测程序中内存管理存在的问题。它检查所有对内存的读/写操作,并截取所有的malloc/new/free/delete调用。因此memcheck工具能够探测到以下问题:
- 使用未初始化的内存
- 读/写已经被释放的内存
- 读/写内存越界
- 读/写不恰当的内存栈空间
- 内存泄漏
- 使用malloc/new/new[]和free/delete/delete[]不匹配。
- src和dst的重叠
使用例子:
首先编写程序
#include
using namespace std;
int main()
{
int *a = new int(2);
//delete a;
return 0;
} g++ -g -o test.c test编译,然后
./valgrind --tool=memcheck --leak-check=full --log-file=test.log ./test
--log-file=test.log将指定输出存在test.log文件中,cat他可以看到
==14766== Memcheck, a memory error detector
==14766== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==14766== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==14766== Command: ./test
==14766== Parent PID: 2126
==14766==
==14766==
==14766== HEAP SUMMARY:
==14766== in use at exit: 72,708 bytes in 2 blocks
==14766== total heap usage: 2 allocs, 0 frees, 72,708 bytes allocated
==14766==
==14766== 4 bytes in 1 blocks are definitely lost in loss record 1 of 2
==14766== at 0x4C2E4B6: operator new(unsigned long) (vg_replace_malloc.c:344)
==14766== by 0x400717: main (test.c:7)
==14766==
==14766== LEAK SUMMARY:
==14766== definitely lost: 4 bytes in 1 blocks
==14766== indirectly lost: 0 bytes in 0 blocks
==14766== possibly lost: 0 bytes in 0 blocks
==14766== still reachable: 72,704 bytes in 1 blocks
==14766== suppressed: 0 bytes in 0 blocks
==14766== Reachable blocks (those to which a pointer was found) are not shown.
==14766== To see them, rerun with: --leak-check=full --show-leak-kinds=all
==14766==
==14766== For lists of detected and suppressed errors, rerun with: -s
==14766== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 0 from 0)
definitely lost: 确定有内存泄漏,表示在程序退出时,该内存无法回收,也没指针指向该内存(首地址);
indirectly lost: 间接内存泄漏,比如结构体中定义的指针指向的内存无法回收;
possibly lost: 可能出现内存泄漏,比如程序退出时,没有指针指向一块内存的首地址了,但由其他某个指针能推算出首地址;
still reachable: 程序没主动释放内存,在退出时候该内存仍能访问到,比如全局 new 的对象没 delete,由于操作系统会回收,所以此类问题可忽略;
最严重的是 definitely lost 和 indirectly lost,检测结果文件中已给出了具体函数和源文件。
https://blog.51cto.com/ljy789/1827249
strace
Linux下,进程不能直接访问硬件设备。当进程需要访问硬件设备时(读取磁盘文件、接收网络数据等),则必须由用户态切换为内核态,然后通过系统调用来访问硬件设备。
strace是跟踪进程执行时的系统调用和所接收的信号(即它跟踪到一个进程产生的系统调用,包括参数、返回值、执行消耗的时间)。
每一行都是一条系统调用,等号左边是系统调用的函数名和参数,右边是该调用的返回值
strace显示这些调用的参数并返回符号形式的值。
strace从内核接收信息,而且不需要以任何特殊的方式来构建内核
参数:
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column 设置返回值的输出位置.默认 为40.
-e expr 指定一个表达式,用来控制如何跟踪.格式:[qualifier=][!]value1[,value2]...
qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open 表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none. 注意有些shell使用!来执行历史记录里的命令,所以要使用\\.
-e trace=set 只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file 只跟踪有关文件操作的系统调用.
-e trace=process 只跟踪有关进程控制的系统调用.
-e trace=network 跟踪与网络有关的所有系统调用.
-e strace=signal 跟踪所有与系统信号有关的系统调用.
-e trace=ipc 跟踪所有与进程通讯有关的系统调用.
-e abbrev=set 设定strace输出的系统调用的结果集.-v 等于abbrev=none.默认为abbrev=all.
-e raw=set 将指定的系统调用的参数以十六进制显示.
-e signal=set 指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set 输出从指定文件中读出 的数据.例如: -e read=3,5 -e write=set 输出写入到指定文件中的数据.
-o filename 将strace的输出写入文件filename
-p pid 跟踪指定的进程pid.
-s strsize 指定输出的字符串的最大长度.默认为32.文件名一直全部输出.
-u username 以username的UID和GID执行被跟踪的命令
实例:
1.追踪系统调用
strace ./bengkuiuser@ubuntu:~/study$ strace ./bengkui
execve("./bengkui", ["./bengkui"], [/* 34 vars */]) = 0 开启新进程
brk(NULL) = 0x6b3000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=89572, ...}) = 0
mmap(NULL, 89572, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7fec448c2000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/usr/lib/x86_64-linux-gnu/libstdc++.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0 \235\10\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0644, st_size=1566440, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fec448c1000
mmap(NULL, 3675136, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7fec44331000
mprotect(0x7fec444a3000, 2097152, PROT_NONE) = 0
mmap(0x7fec446a3000, 49152, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x172000) = 0x7fec446a3000
mmap(0x7fec446af000, 13312, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7fec446af000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\t\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1868984, ...}) = 0
mmap(NULL, 3971488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7fec43f67000
mprotect(0x7fec44127000, 2097152, PROT_NONE) = 0
mmap(0x7fec44327000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1c0000) = 0x7fec44327000
mmap(0x7fec4432d000, 14752, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7fec4432d000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libm.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\0V\0\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0644, st_size=1088952, ...}) = 0
mmap(NULL, 3178744, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7fec43c5e000
mprotect(0x7fec43d66000, 2093056, PROT_NONE) = 0
mmap(0x7fec43f65000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x107000) = 0x7fec43f65000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libgcc_s.so.1", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0p*\0\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0644, st_size=89696, ...}) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fec448c0000
mmap(NULL, 2185488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7fec43a48000
mprotect(0x7fec43a5e000, 2093056, PROT_NONE) = 0
mmap(0x7fec43c5d000, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x15000) = 0x7fec43c5d000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fec448bf000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fec448bd000
arch_prctl(ARCH_SET_FS, 0x7fec448bd740) = 0
mprotect(0x7fec44327000, 16384, PROT_READ) = 0
mprotect(0x7fec43f65000, 4096, PROT_READ) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fec448bc000
mprotect(0x7fec446a3000, 40960, PROT_READ) = 0
mprotect(0x600000, 4096, PROT_READ) = 0
mprotect(0x7fec448d8000, 4096, PROT_READ) = 0
munmap(0x7fec448c2000, 89572) = 0
brk(NULL) = 0x6b3000
brk(0x6e5000) = 0x6e5000
fstat(0, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0
read(0, 2 这个位置调用scanf,我输入了2,引发段错误
"2\n", 1024) = 2
--- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=0} ---
+++ killed by SIGSEGV (core dumped) +++
段错误 (核心已转储)
2.跟踪信号传递
首先,strace ./bengkui,等到等待输入的那一步时,不输入任何东西,然后打开另外一个窗口,输入命令:killall bengkui
我们观察第一次打开的strace窗口中,此时,我们看见程序退出了,结果如下
read(0, 0x16f6c20, 1024) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=2441, si_uid=1000} ---
+++ killed by SIGTERM +++
3.系统调用统计(可以用来看cpu占用率那么高到底在做啥)
使用-c参数,它会将进程的所有系统调用做一个统计分析展示出来
user@ubuntu:~/study$ strace -c ./bengkui
2
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 5 read
0.00 0.000000 0 5 open
0.00 0.000000 0 5 close
0.00 0.000000 0 6 fstat
0.00 0.000000 0 16 mmap
0.00 0.000000 0 9 mprotect
0.00 0.000000 0 1 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 6 6 access
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 58 6 total
段错误 (核心已转储)
这里清楚的告诉我们,在这一过程中调用了哪些系统函数,调用了多少次,消耗了多少时间等信息,这对我们分析一个程序是很有帮助的
其他常用参数的使用:
(1)重定向输出
-o 将strace 的结果输出到文件中
若不指定 -o 参数的话,默认的输出设备是STDERR,也就是说,使用 -o filename 和 2>filename 的结果是一样的。
如
strace -o text.txt ./bengkui即将结果保存在text.txt中
(2)对系统调用进行计时
-T 将每个系统调用所花费的时间打印出来
每个调用的花销体现在调用行最右边的尖括号里边(下面只是调用的一部分)
(3)系统调用的时间
-t/-tt/-ttt
-t 精确到秒
-tt 精确到微秒
-ttt 精确到微秒,而且时间表示为unix时间戳
(4)截断输出
-s 指定trace结果的每一行输出的字符串长度
strace -s 5 ./bengkui
(5)追踪现有的进程
-p pid
sudo strace -p 2019可以追踪正在运行的进程
我一追踪自己写的server进程他就挂了。。。
追踪webserver:每过一段时间,就会调用一次epoll_wait。出现第一个accept时,是我在另一个终端telnet 127.0.0.1 80 造成的,但是请求的内容输错了,所以没有发送正常的响应信息。
user@ubuntu:~$ sudo strace -p 3273
strace: Process 3273 attached
dup(2) = 14
fcntl(14, F_GETFL) = 0x8002 (flags O_RDWR|O_LARGEFILE)
fstat(14, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0
write(14, "epoll wait error: Interrupted sy"..., 42) = 42
close(14) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [{EPOLLIN, {u32=5, u64=11826489472294322181}}], 4096, 10000) = 1
accept(5, {sa_family=AF_INET, sin_port=htons(49714), sin_addr=inet_addr("127.0.0.1")}, [16]) = 14
stat("/etc/localtime", {st_mode=S_IFREG|0644, st_size=554, ...}) = 0
fcntl(14, F_GETFL) = 0x2 (flags O_RDWR)
fcntl(14, F_SETFL, O_RDWR|O_NONBLOCK) = 0
setsockopt(14, SOL_TCP, TCP_NODELAY, [1], 4) = 0
write(9, "\1\0\0\0\0\0\0\0", 8) = 8
accept(5, 0x7ffffcbecd50, 0x7ffffcbecd4c) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, [], 4096, 10000) = 0
epoll_wait(3, ^[[A
^Cstrace: Process 3273 detached
如果用的-c:
user@ubuntu:~$ sudo strace -p 3273 -c
strace: Process 3273 attached
^C
strace: Process 3273 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.012000 1714 7 epoll_wait
0.00 0.000000 0 3 write
0.00 0.000000 0 1 close
0.00 0.000000 0 2 stat
0.00 0.000000 0 1 fstat
0.00 0.000000 0 1 dup
0.00 0.000000 0 4 2 accept
0.00 0.000000 0 2 setsockopt
0.00 0.000000 0 5 fcntl
------ ----------- ----------- --------- --------- ----------------
100.00 0.012000 26 2 total
ps -aux
netstat -anp
netstat -ant
lsof -i:8888
lsof -p pid
netstat -tln 查看所有端口的使用情况
ufw防火墙即uncomplicated firewall的简称 Ubuntu下的防火墙
Linux下,绑定1024以下的端口需要root权限!
若server想bind 80端口,要用sudo来./server
典型使用场景举例
场景一:目标机的22端口外网没有打开,通过本地端口转发实现通过其他端口访问ssh的22端口
案例:192.168.240.129机器的22端口未对外开放,但开放了3000~4000之间的端口,因此通过3000端口转发到22实现ssh登录
sudo iptables -t nat -A PREROUTING -p tcp -i eth0 -d 192.168.240.129 --dport 3000 -j DNAT --to 192.168.240.129:22
这个属于本机端A端口转发到本机的B端口
telnet命令通常用来远程登录。telnet程序是基于TELNET协议的远程登录客户端程序。Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的 能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制Web服务器的方法。
但是,telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh方式了。但仍然有很多别的系统可能采用了telnet方式来提供远程登录,因此弄清楚telnet客户端的使用方式仍是很有必要的。
telnet命令还可做别的用途,比如确定远程服务的状态,比如确定远程服务器的某个端口是否能访问。
命令格式:
telnet[参数][主机]
https://www.cnblogs.com/fjping0606/p/5852049.html
在运维工作中,压力测试是一项很重要的工作。比如在一个网站上线之前,能承受多大访问量、在大访问量情况下性能怎样,这些数据指标好坏将会直接影响用户体验。但是,在压力测试中存在一个共性,那就是压力测试的结果与实际负载结果不会完全相同,就算压力测试工作做的再好,也不能保证100%和线上性能指标相同。面对这些问题,我们只能尽量去想方设法去模拟。所以,压力测试非常有必要,有了这些数据,我们就能对自己做维护的平台做到心中有数。
webbench 压测工具
Webbench是知名的网站压力测试工具,它是由Lionbridge公司(http://www.lionbridge.com)开发。
Webbench能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webbench的标准测试可以向我们展示服务器的两项内容:每秒钟响应请求数和每秒钟传输数据量。webbench不但能具有便准静态页面的测试能力,还能对动态页面(ASP,PHP,JAVA,CGI)进 行测试的能力。还有就是他支持对含有SSL的安全网站例如电子商务网站进行静态或动态的性能测试。
Webbench最多可以模拟3万个并发连接去测试网站的负载能力。
Webbench实现的核心原理是:父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。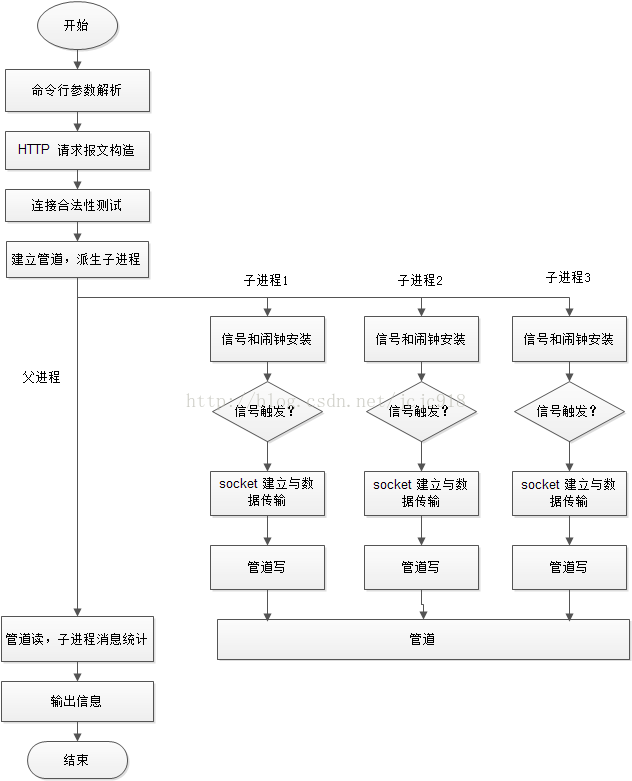
1、WebBench安装
# yum install -y gcc ctags
# wget http://www.ha97.com/code/webbench-1.5.tar.gz
# tar zxvf webbench-1.5.tar.gz
# cd webbench-1.5
# make
# make install
2、WebBench使用
webbench -c 1000 -t 60 http://test.domain.com/phpinfo.php
webbench -c 并发数 -t 运行测试时间 URL
user@ubuntu:~$ webbench -c 200 -t 20 -f http://baidu.com/
Webbench - Simple Web Benchmark 1.5
Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software.
Benchmarking: GET http://baidu.com/
200 clients, running 20 sec, early socket close.
Speed=7932 pages/min, 0 bytes/sec.
Requests: 2644 susceed, 0 failed.
自己写的服务器程序绑定端口为8888,webbench用的是http协议,连的应该是80端口
| -f | --force | 不需要等待服务器响应 |
| -r | --reload | 发送重新加载请求 |
| -t | --time | 运行多长时间,单位:秒" |
| -p | --proxy server:port | 使用代理服务器来发送请求 |
| -c | --clients | 创建多少个客户端,默认1个" |
| -9 | --http09 | 使用 HTTP/0.9 |
| -1 | --http10 | 使用 HTTP/1.0 协议 |
| -2 | --http11 | 使用 HTTP/1.1 协议 |
| --get | 使用 GET请求方法 | |
| --head | 使用 HEAD请求方法 | |
| --options | 使用 OPTIONS请求方法 | |
| --trace | 使用 TRACE请求方法 | |
| -?/-h | --help | 打印帮助信息 |
| -V | --version | 显示版本号 |
linux下把可执行文件添加进环境变量中:
#查看PATH:
echo $PATH方法一
export PATH=/usr/local/bin:$PATH
#配置完后可以通过echo $PATH查看配置结果。
#生效方法:立即生效
#有效期限:临时改变,只能在当前的终端窗口中有效,当前窗口关闭后就会恢#复原有的path配置
#用户局限:仅对当前用户
方法二:
#通过修改.bashrc文件:
vim ~/.bashrc
#在最后一行添上:
export PATH=/usr/local/bin:$PATH
#生效方法:(有以下两种)
#1、关闭当前终端窗口,重新打开一个新终端窗口就能生效
#2、输入“source ~/.bashrc”命令,立即生效
#有效期限:永久有效
#用户局限:仅对当前用户
方法三:
#通过修改profile文件:
vim /etc/profile
export PATH=/usr/local/bin:$PATH
#生效方法:系统重启
#有效期限:永久有效
#用户局限:对所有用户
方法四:
#通过修改environment文件:
vim /etc/environment
在PATH="/usr/local/sbin:/usr/sbin:/usr/bin:/sbin:/bin"中加入
":/usr/local/bin"
#生效方法:系统重启
#有效期限:永久有效
#用户局限:对所有用户
wireshark 网络抓包记录
wireshark是非常流行的网络封包分析软件,功能十分强大。可以截取各种网络封包,显示网络封包的详细信息。使用wireshark的人必须了解网络协议,否则就看不懂wireshark了。
为了安全考虑,wireshark只能查看封包,而不能修改封包的内容,或者发送封包。
wireshark能获取HTTP,也能获取HTTPS,但是不能解密HTTPS,所以wireshark看不懂HTTPS中的内容,总结,如果是处理HTTP,HTTPS 还是用Fiddler, 其他协议比如TCP,UDP 就用wireshark.

TCP包的具体内容
从下图可以看到wireshark捕获到的TCP包中的每个字段。

看到这, 基本上对wireshak有了初步了解, 现在我们看一个TCP三次握手的实例
三次握手过程为

这图我都看过很多遍了, 这次我们用wireshark实际分析下三次握手的过程。
打开wireshark, 打开浏览器输入 http://www.baidu.com
在wireshark中输入http过滤, 然后选中GET / HTTP/1.1的那条记录,右键然后点击"Follow TCP Stream 即追踪TCP流",然后可以把弹出的窗口关掉,
这样做的目的是为了得到与浏览器打开网站相关的数据包,将得到如下图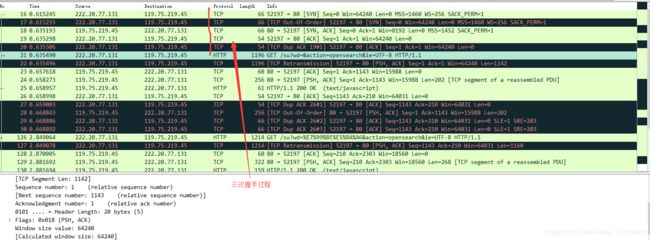
图中可以看到wireshark截获到了三次握手的三个数据包。第四个包才是HTTP的, 这说明HTTP的确是使用TCP建立连接的。
可以看到,第一次握手的报文帧长度为66byte,逐一查看各层信息知道:
传输层首部长32+数据长0 (固定首部20字节,加上选项可能超过20)
网络层首部长20
但是链路层和物理层没看到有关字节数,只有物理层写了![]() ,应该是加上一些链路层协议信息吧,如封装成帧、差错检测、透明传输的字节填充,ppp协议的首部尾部字节8字节,那么还剩下66-32-20-8=8字节不知道是啥,我猜测可能是ppp协议的字节填充子类的。
,应该是加上一些链路层协议信息吧,如封装成帧、差错检测、透明传输的字节填充,ppp协议的首部尾部字节8字节,那么还剩下66-32-20-8=8字节不知道是啥,我猜测可能是ppp协议的字节填充子类的。
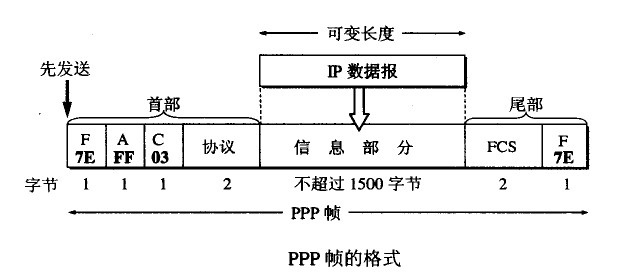
1.PPP帧的格式
PPP帧的首部
- 首部中的标志字段F(Flag),规定为0x7E(符号0x表示它后面的字符是用十六进制表示的。十六进制的7E的二进制表示是01111110),标志字段表示一个帧的开始。
PPP帧的信息字段部分
- 信息字段的长度是可变的,不超过1500字节。
PPP帧的尾部
- 尾部中的第一个字段(2个字节)是使用CRC的帧检验序列FCS。
- 尾部中的标志字段F(Flag),规定为0x7E(符号0x表示它后面的字符是用十六进制表示的。十六进制的7E的二进制表示是01111110),标志字段表示一个帧的结束。
2. 透明传输的实现方式
当信息字段中出现和标志字段一样的比特(0x7E)组合时,就必须采取一些措施使这种形式上和标志字段一样的比特组合不出现在信息字段中。
2.1 字节填充——PPP使用异步传输
当PPP使用异步传输时,它把转移符定义为0x7D,并使用字节填充。
RFC1662规定了如下填充方法:
(1)把信息字段中出现的每一个0x7E字节转变为2字节序列(0x7D,0x5E)。
(2)若信息字段中出现一个0x7D的字节(即出现了和转义字符一样的比特组合),则把转义字符0x7D转变为2字节序列(0x7D,0x5D)。
(3)若信息字段中出现ASCII码的控制字符(即数值小于0x20的字符),则在该字符前面要加入一个0x7D字节,同时将该字符的编码加以改变。例如,出现0x03(在控制字符中是“传输结束”ETX)就要把它转变为2字节序列的(0x7D,0x31)。
由于在发送端进行了字节填充,因此在链路上传送的信息字节数就超过了原来的信息字节数。但接收端在接收到数据后再进行与发送端字节填充相反的变换,就可以正确地恢复出原来的信息。
2.2 零比特填充——PPP使用同步传输
当PPP使用同步传输时,使用零比特填充。
零比特填充的具体方法:
(1)在发送端先扫描整个信息字段(通常使用硬件实现,但也可以用软件实现,但是会慢一些)。
(2)只要发现有5个连续的1,则立即填入一个0。
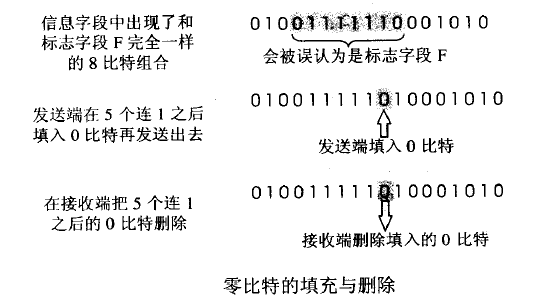
(3)接收端在收到一个帧时,先找到标志字段F以确定帧的边界,接着再用硬件对其中的比特流进行扫描,每当发现5个连续1时,就把5个连续1后的一个0删除,以还原成原来的信息比特流。
因此通过这种零比特填充后的数据,就可以保证在信息字段中不会出现连续6个1。
2019.8.22又看了一次:
选择一个不带数据的TCP包,多为三次握手的报文,发现这个帧长度为54bytes
54=20+20+14,那么这个14byte是哪来的呢?
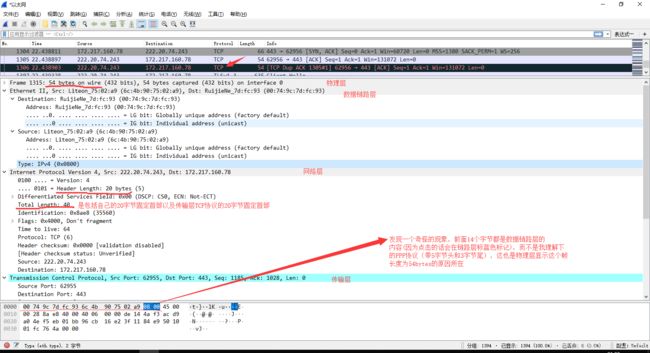
我查了一下,这里用的不是PPP协议,而是Ethernet II协议
以太网是当今现有局域网采用的最通用的通信协议标准。该协议定义了局域网中采用的电缆类型和信号处理方式
它由6个字节的目的MAC地址,6个字节的源MAC地址,2个字节的类型域(用于标示封装在这个Frame、里面的数据的类型)
接下来是46-1500字节的数据和4字节的帧校验。
报头8 目标地址6 源地址6 以太类型2 有效负载46-1500 帧检验序列4
报头:8字节,前7个0,1交替的字节(10101010)用来同步接收站,一个1010101011字节指出帧的开始位置。
报头提供接收器同步和帧界定服务。
目标地址:6个字节,单播多播或者广播。单播地址叫个人、物理、硬件或MAC地址,广播地址为全1,0xFF FF FF FF。
源地址:6个字节。指出发送节点的单点广播地址。
以太类型:2个字节,用来指出以太网帧内所含的上层协议。即帧格式的协议标识符。对于IP报文来说,该字段值是0x0800。
对于ARP信息来说,以太类型字段的值是0x0806。
有效负载:由一个上层协议的协议数据单元PDU构成。可以发送的最大有效负载是1500字节。
由于以太网的冲突检测特性,有效负载至少是46个字节。如果上层协议数据单元长度少于46个字节,必须增补到46个字节。
帧检验序列:4个字节。验证比特完整性。
Destination:目标地址为C4:01:20:E8:00:00
SOURCE:源地址为c4:02:21:e8:00:00
上文中标黑的是我在报文中有发现的,即目标地址6 源地址6 以太类型2 ,共14字节,这样就没错了。但是还有报头8和帧检验序列4共12字节没有看到,可能是wireshark是用这头和尾来识别一个报文的,所以不显示?
这样一来,14字节谜案终于告破。
tcpdump
tcpdump是一个用于截取网络分组,并输出分组内容的工具。凭借强大的功能和灵活的截取策略,使其成为类UNIX系统下用于网络分析和问题排查的首选工具
tcpdump 支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息
- 命令格式
tcpdump [ -DenNqvX ] [ -c count ] [ -F file ] [ -i interface ] [ -r file ]
[ -s snaplen ] [ -w file ] [ expression ]- 抓包选项:
-c:指定要抓取的包数量。
-i interface:指定tcpdump需要监听的接口。默认会抓取第一个网络接口
-n:对地址以数字方式显式,否则显式为主机名,也就是说-n选项不做主机名解析。
-nn:除了-n的作用外,还把端口显示为数值,否则显示端口服务名。
-P:指定要抓取的包是流入还是流出的包。可以给定的值为"in"、"out"和"inout",默认为"inout"。
-s len:设置tcpdump的数据包抓取长度为len,如果不设置默认将会是65535字节。对于要抓取的数据包较大时,长度设置不够可能会产生包截断,若出现包截断,输出行中会出现"[|proto]"的标志(proto实际会显示为协议名)。但是抓取len越长,包的处理时间越长,并且会减少tcpdump可缓存的数据包的数量,从而会导致数据包的丢失,所以在能抓取我们想要的包的前提下,抓取长度越小越好。
- 输出选项:
-e:输出的每行中都将包括数据链路层头部信息,例如源MAC和目标MAC。
-q:快速打印输出。即打印很少的协议相关信息,从而输出行都比较简短。
-X:输出包的头部数据,会以16进制和ASCII两种方式同时输出。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-v:当分析和打印的时候,产生详细的输出。
-vv:产生比-v更详细的输出。
-vvv:产生比-vv更详细的输出。
- 其他功能性选项:
-D:列出可用于抓包的接口。将会列出接口的数值编号和接口名,它们都可以用于"-i"后。
-F:从文件中读取抓包的表达式。若使用该选项,则命令行中给定的其他表达式都将失效。
-w:将抓包数据输出到文件中而不是标准输出。可以同时配合"-G
time"选项使得输出文件每time秒就自动切换到另一个文件。可通过"-r"选项载入这些文件以进行分析和打印。
-r:从给定的数据包文件中读取数据。使用"-"表示从标准输入中读取。
- 原语总结
类型:host、net、port、ip proto、protochain等
传输方向:src、dst、dst or src、dst and src等
协议:ip、arp、rarp、tcp、udp、icmp、http等
单位原语格式
协议 + [传输方向] + 类型 + 具体数值
eg:ip src host 192.168.0.106
eg:src ip proto '\tcp'
- tcpdump原语组合方式
- !或not
- && 或 and
- || 或 or
- 必要时用括号提高某一部分表达式的优先级
例如:
下文中ens33表示网卡,Ubuntu下一般是eth0, vnn含义见上文的参数
$ tcpdump -i ens33 -vnn -c 1 dst port 22
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
12:11:27.522941 IP (tos 0x0, ttl 64, id 21657, offset 0, flags [DF], proto TCP (6), length 40)
192.168.0.105.54999 > 192.168.0.106.22: Flags [.], cksum 0xb18d (correct), ack 2182327416, win 2051, length 0
1 packet captured
1 packet received by filter
0 packets dropped by kernel
& tcpdump -i ens33 -vnn -c 1 dst net 192.168.0.0/24
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
12:06:19.030478 IP (tos 0x10, ttl 64, id 61901, offset 0, flags [DF], proto TCP (6), length 172)
192.168.0.106.22 > 192.168.0.105.54999: Flags [P.], cksum 0x82c2 (incorrect -> 0x2add), seq 2182311952:2182312084, ack 2364588497, win 255, length 132
1 packet captured
2 packets received by filter
0 packets dropped by kernel
$ tcpdump -i ens33 -vnn -c 1 dst host 192.168.0.106
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
01:10:03.673075 IP (tos 0x0, ttl 64, id 16278, offset 0, flags [DF], proto TCP (6), length 40)
192.168.0.105.61237 > 192.168.0.106.22: Flags [.], cksum 0x5346 (correct), ack 1305983704, win 2052, length 0
1 packet captured
1 packet received by filter
0 packets dropped by kernel
常用案例
- 抓取包含10.10.10.122的数据包
tcpdump -i ens33 -vnn host 10.10.10.122
- 抓取包含10.10.10.0/24网段的数据包
tcpdump -i ens33 -vnn net 10.10.10.0/24
tcpdump -i ens33 -vnn net 10.10.10.0 mask 255.255.255.0
- 抓取包含端口22的数据包
tcpdump -i ens33 -vnn port 22
- 抓取udp协议的数据包
tcpdump -i ens33 -vnn udp
- 抓取icmp协议的数据包
tcpdump -i ens33 -vnn icmp
- 抓取arp协议的数据包
tcpdump -i ens33 -vnn arp
- 抓取ip协议的数据包
tcpdump -i ens33 -vnn ip proto ip
tcpdump -i ens33 -vnn ip
- 抓取源ip是10.10.10.122的数据包
tcpdump -i ens33 -vnn src host 10.10.10.122
- 抓取目标ip是10.10.10.122的数据包
tcpdump -i ens33 -vnn dst host 10.10.10.122
- 抓取源端口是22的数据包
tcpdump -i ens33 -vnn src port 22
- 抓取源ip是10.10.10.253且目的端口是22的数据包
tcpdump -i ens33 -vnn src host 10.10.10.122 and dst port 22
- 抓取源ip是10.10.10.122或者端口是22的数据包
tcpdump -i ens33 -vnn src host 10.10.10.122 or port 22
- 抓取源ip是10.10.10.122且端口不是22的数据包
tcpdump -i ens33 -vnn src host 10.10.10.122 and not port 22
- 抓取源ip是10.10.10.2且端口是22,或源ip是10.10.10.65且目的端口是80的数据包。
tcpdump -i ens33 -vnn \(src host 10.10.10.2 and port 22 \) or \(src ip host 10.10.10.65 and prot 80\)
- 抓取源ip是10.10.10.59且目的端口是22,或者源ip是10.10.10.68且目的端口是80的数据包
tcpdump -i ens33 -vnn '\(src host 10.10.10.59 and dst port 22\) 'or '\(src host 10.10.10.68 and dst prot 80\)'
- 把抓取的数据包记录存到/tmp/fill文件中,当抓取100个数据包后就退出程序
tcpdump -i ens33 -c 100 -w /tmp/fill
- 从/tmp/fill记录中读取tcp协议的数据包。
tcpdump -i ens33 -r /tmp/fill tcp
- 从/tmp/fill记录中读取包含10.10.10.58的数据包。
tcpdump -i ens33 -r /tmp/fill host 10.10.10.58
- 过滤数据包类型是多播并且端口不是22、不是icmp协议的数据包。
tcpdump -i ens33 ether multicast and not port 22 and 'not icmp'
- 过滤协议类型是ip并且目标端口是22的数据包
tcpdump -i ens33 -n ip and dst prot 22
- tcpdump可识别的关键字包括ip、igmp、tcp、udp、icmp、arp等
- 过滤抓取mac地址是某个具体的mac地址、协议类型是arp的数据包
tcpdump -i ens33 ether src host 00:0c:29:2f:a7:50 and arp
- 过滤抓取协议类型是ospf的数据包
tcpdump -i ens33 ip proto ospf
直接在tcpdump中使用的协议关键字只有ip、igmp、tcp、udp、icmp、arp等,其他的传输层协议没有可直接识别的关键字
可以使用关键字proto或者ip proto加上在/etc/protocols中能够找到的协议或者相应的协议编号进行过滤。更加高层的协议,例如http协议需要用端口号来过滤
- 过滤长度大于200字节的报文
tcpdump -i ens33 greater 200
- 过滤协议类型为tcp的数据包
tcpdump tcp
- 查找端口号大于23的所有tcp数据流
tcpdump -i ens33 -c 1 -vnn 'tcp[0:2] & 0xffff > 0x0017 '
sudo tcpdump -i eth0 host 180.101.49.12 and tcp
发送http请求可用 curl "www.baidu.com" 或curl ip
traceroute
原文:https://blog.csdn.net/llq_200/article/details/81034345
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。linux系统中,我们称之为traceroute,在MS Windows中为tracert。 traceroute通过发送小的数据包到目的设备直到其返回,来测量其需要多长时间。一条路径上的每个设备traceroute要测3次(默认发送3个包)。输出结果中包括每次测试的时间(ms)和设备的名称(如有的话)及其IP地址。
- 工作原理:
Traceroute最简单的基本用法是:traceroute hostname
Traceroute程序的设计是利用ICMP及IP header的TTL(Time To Live)栏位(field)。首先,traceroute送出一个TTL是1的IP datagram(其实,每次送出的为3个40字节的包,包括源地址,目的地址和包发出的时间标签)到目的地,当路径上的第一个路由器(router)收到这个datagram时,它将TTL减1。此时,TTL变为0了,所以该路由器会将此datagram丢掉,并送回一个「ICMP time exceeded」消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),traceroute 收到这个消息后,便知道这个路由器存在于这个路径上,接着traceroute 再送出另一个TTL是2 的datagram,发现第2 个路由器...... traceroute 每次将送出的datagram的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个datagram 抵达目的地。当datagram到达目的地后,该主机并不会送回ICMP time exceeded消息,因为它已是目的地了,那么traceroute如何得知目的地到达了呢?
Traceroute在送出UDP datagrams到目的地时,它所选择送达的port number 是一个一般应用程序都不会用的端口(30000 以上),所以当此UDP datagram 到达目的地后该主机会送回一个「ICMP port unreachable」的消息,而当traceroute 收到这个消息时,便知道目的地已经到达了。所以traceroute 在Server端也是没有所谓的Daemon 程式。
Traceroute提取发 ICMP TTL到期消息设备的IP地址并作域名解析。每次 ,Traceroute都打印出一系列数据,包括所经过的路由设备的域名及 IP地址,三个包每次来回所花时间。
- 用法:
实例1:traceroute 用法简单、最常用的用法
命令: traceroute www.baidu.com
$ traceroute www.baidu.com
traceroute to www.baidu.com (180.101.49.11), 30 hops max, 60 byte packets
1 9.112.63.129 (9.112.63.129) 40.720 ms 40.931 ms 41.039 ms
2 9.112.123.8 (9.112.123.8) 10.630 ms 10.787 ms 13.910 ms
3 * 10.196.39.229 (10.196.39.229) 0.714 ms 0.600 ms
4 10.196.95.33 (10.196.95.33) 1.563 ms 10.196.0.58 (10.196.0.58) 1.297 ms 10.196.0.66 (10.196.0.66) 1.331 ms
5 182.254.127.120 (182.254.127.120) 1.692 ms 1.899 ms 1.853 ms
6 * * *
7 101.95.225.81 (101.95.225.81) 2.432 ms 101.95.225.173 (101.95.225.173) 2.324 ms 124.74.232.201 (124.74.232.201) 2.963 ms
8 101.95.218.197 (101.95.218.197) 3.183 ms 101.95.218.249 (101.95.218.249) 4.152 ms 101.95.218.237 (101.95.218.237) 2.467 ms
9 202.97.74.134 (202.97.74.134) 5.139 ms 202.97.74.122 (202.97.74.122) 5.968 ms 202.97.19.254 (202.97.19.254) 6.043 ms
10 58.213.94.2 (58.213.94.2) 7.290 ms 58.213.94.110 (58.213.94.110) 9.524 ms 58.213.95.118 (58.213.95.118) 9.225 ms
11 * 58.213.94.126 (58.213.94.126) 8.706 ms *
12 58.213.96.90 (58.213.96.90) 7.767 ms 58.213.96.102 (58.213.96.102) 9.399 ms 58.213.96.94 (58.213.96.94) 9.001 ms
13 * * *
14 * * *
15 * * *
16 * * *
17 * * *
18 * * *
19 * * *
20 * * *
21 * * *
22 * * *
23 * * *
24 * * *
25 * * *
26 * * *
27 * * *
28 * * *
29 * * *
30 * * *说明:
记录按序列号从1开始,每个纪录就是一跳 ,每跳表示一个网关,我们看到每行有三个时间,单位是 ms,其实就是-q的默认参数。探测数据包向每个网关发送三个数据包后,网关响应后返回的时间;如果您用 traceroute -q 4 www.58.com ,表示向每个网关发送4个数据包。
有时我们traceroute 一台主机时,会看到有一些行是以星号表示的。出现这样的情况,可能是防火墙封掉了ICMP的返回信息,所以我们得不到什么相关的数据包返回数据。
有时我们在某一网关处延时比较长,有可能是某台网关比较阻塞,也可能是物理设备本身的原因。当然如果某台DNS出现问题时,不能解析主机名、域名时,也会 有延时长的现象;您可以加-n 参数来避免DNS解析,以IP格式输出数据。
如果在局域网中的不同网段之间,我们可以通过traceroute 来排查问题所在,是主机的问题还是网关的问题。如果我们通过远程来访问某台服务器遇到问题时,我们用到traceroute 追踪数据包所经过的网关,提交IDC服务商,也有助于解决问题;
实例2:跳数设置
命令: traceroute -m 10 www.baidu.com
$ traceroute -m 10 www.baidu.com
traceroute to www.baidu.com (180.101.49.12), 10 hops max, 60 byte packets
1 9.112.63.129 (9.112.63.129) 5.272 ms 5.697 ms 5.870 ms
2 9.112.122.218 (9.112.122.218) 6.492 ms 6.644 ms 6.671 ms
3 * * *
4 10.196.0.66 (10.196.0.66) 1.298 ms * *
5 182.254.127.120 (182.254.127.120) 1.758 ms 1.836 ms *
6 180.163.27.205 (180.163.27.205) 1.212 ms * 101.226.242.29 (101.226.242.29) 2.205 ms
7 101.95.209.33 (101.95.209.33) 3.242 ms 101.95.225.177 (101.95.225.177) 19.016 ms 101.95.225.81 (101.95.225.81) 3.786 ms
8 101.95.218.205 (101.95.218.205) 2.581 ms 101.95.218.241 (101.95.218.241) 3.381 ms 101.95.218.245 (101.95.218.245) 2.474 ms
9 202.97.74.146 (202.97.74.146) 5.249 ms 202.97.29.118 (202.97.29.118) 9.181 ms 202.97.29.126 (202.97.29.126) 8.589 ms
10 58.213.94.98 (58.213.94.98) 8.819 ms 58.213.94.6 (58.213.94.6) 7.908 ms 58.213.95.6 (58.213.95.6) 7.791 ms实例3:探测包使用的基本UDP端口设置6888
命令:
traceroute -p 6888 www.baidu.com
$ traceroute -p 6888 www.baidu.com
traceroute to www.baidu.com (180.101.49.11), 30 hops max, 60 byte packets
1 9.112.63.129 (9.112.63.129) 6.958 ms 7.332 ms 7.108 ms
2 9.112.123.8 (9.112.123.8) 5.755 ms 5.875 ms 5.987 ms
3 * * *
4 10.196.0.66 (10.196.0.66) 1.293 ms 10.196.0.58 (10.196.0.58) 1.243 ms 10.196.95.29 (10.196.95.29) 1.554 ms
5 182.254.127.120 (182.254.127.120) 1.968 ms 182.254.127.119 (182.254.127.119) 1.762 ms 1.666 ms
6 * 101.226.242.17 (101.226.242.17) 1.862 ms *
7 101.95.225.89 (101.95.225.89) 2.224 ms 101.95.225.189 (101.95.225.189) 23.447 ms 23.422 ms
8 101.95.219.9 (101.95.219.9) 4.335 ms 101.95.218.197 (101.95.218.197) 2.385 ms 101.95.218.213 (101.95.218.213) 2.394 ms
9 202.97.29.114 (202.97.29.114) 9.524 ms 202.97.74.134 (202.97.74.134) 5.501 ms 202.97.66.202 (202.97.66.202) 8.413 ms
10 58.213.94.110 (58.213.94.110) 8.714 ms 58.213.95.118 (58.213.95.118) 8.720 ms *
11 58.213.95.126 (58.213.95.126) 9.402 ms * 58.213.95.134 (58.213.95.134) 7.622 ms
12 58.213.96.74 (58.213.96.74) 8.460 ms 58.213.96.126 (58.213.96.126) 8.772 ms 58.213.96.54 (58.213.96.54) 8.246 ms
...- 命令参数:
-d 使用Socket层级的排错功能。
-f 设置第一个检测数据包的存活数值TTL的大小。
-F 设置勿离断位。
-g 设置来源路由网关,最多可设置8个。
-i 使用指定的网络界面送出数据包。
-I 使用ICMP回应取代UDP资料信息。
-m 设置检测数据包的最大存活数值TTL的大小。
-n 直接使用IP地址而非主机名称。
-p 设置UDP传输协议的通信端口。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-s 设置本地主机送出数据包的IP地址。
-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程。
-w 设置等待远端主机回报的时间。
-x 开启或关闭数据包的正确性检验。
iftop
监控网卡流量

iperf
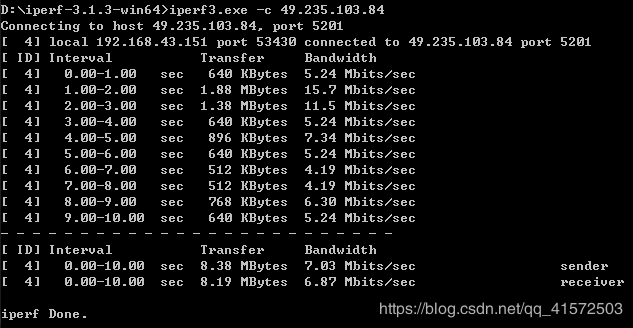
网络性能评估主要是监测网络带宽的使用率,将网络带宽利用最大化是保证网络性能的基础,但是由于网络设计不合理、网络存在安全漏洞等原因,都会导致网络带宽利用率不高。要找到网络带宽利用率不高的原因,就需要对网络传输进行监控,此时就需要用到一些网络性能评估工具,而Iperf就是这样一款网络带宽测试工具,本节将详细介绍一下Iperf的使用。
Iperf能做什么(详见https://www.cnblogs.com/klb561/p/9215952.html)
Iperf是一款基于TCP/IP和UDP/IP的网络性能测试工具,它可以用来测量网络带宽和网络质量,还可以提供网络延迟抖动、数据包丢失率、最大传输单元等统计信息。网络管理员可以根据这些信息了解并判断网络性能问题,从而定位网络瓶颈,解决网络故障。
windows安装网址https://iperf.fr/iperf-download.php#windows
linux 直接sudo apt install iperf3
测试吞吐量例子
linux 端命令行输入 iperf3 -s

windows端 iperf3 -c 49.235.103.84
perf
原文链接:https://blog.csdn.net/dillanzhou/article/details/82861817
https://www.cnblogs.com/arnoldlu/p/6241297.html
Perf 是内置于Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。linux2.6及后续版本都自带该工具,几乎能够处理所有与性能相关的事件。
Perf工具可用来对软件进行优化,包括算法优化(空间复杂度、时间复杂度)和代码优化(提高执行速度、减少内存占用)。还可以评估程序对硬件资源的使用情况,例如各级cache的访问次数,各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。也可以评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数等。
perf top适合监控整个系统的性能,stat比较适合单个程序的性能分析,record/report更适合对程序进行更细粒度的分析。
- perf常用参数
-C 指定统计的CPU核心编号,不指定时统计全部核心(等价于-a)
-e 指定统计事件
-p 只统计特定pid指定的进程中产生的事件
-t 只统计特定tid指定的线程中产生的事件
-K 隐藏内核中的函数符号
-U 隐藏用户态的函数符号
-g perf record工具专用的参数,记录函数的调用栈信息
其他参数可以通过man perf-top等命令查看perf工具集的手册了解。
使用perf之前肯定要知道perf能监控哪些性能指标吧?那么就要使用perf list进行查看,通常使用的指标是cpu-clock/task-clock等,具体要根据需要来判断
- perf list
perf list命令可以列出perf支持的内置事件列表。输出的列表如下所示:
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
…
cpu-clock [Software event]
task-clock [Software event]
context-switches OR cs [Software event]
…
ext4:ext4_allocate_inode [Tracepoint event]
kmem:kmalloc [Tracepoint event]
module:module_load [Tracepoint event]
workqueue:workqueue_execution [Tracepoint event]
sched:sched_{wakeup,switch} [Tracepoint event]
syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event]
…不同内核版本列出的结果不一样多…不过基本是够用的,但是无论多少,我们可以基本将其分为三类
Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样
Software Event 是内核软件产生的事件,比如进程切换,tick 数等
Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等
具体监控哪个变量的话,譬如使用后面的perf report工具,则加-e 监控指标,如
perf report -e cpu-clock ls
监控运行ls命令时的cpu时钟占用监控
- perf stat
perf stat可以用于统计分析系统或者特定软件的整体执行情况。
$perf stat ./t1
Performance counter stats for './t1':
262.738415 task-clock-msecs # 0.991 CPUs
2 context-switches # 0.000 M/sec
1 CPU-migrations # 0.000 M/sec
81 page-faults # 0.000 M/sec
9478851 cycles # 36.077 M/sec (scaled from 98.24%)
6771 instructions # 0.001 IPC (scaled from 98.99%)
111114049 branches # 422.908 M/sec (scaled from 99.37%)
8495 branch-misses # 0.008 % (scaled from 95.91%)
12152161 cache-references # 46.252 M/sec (scaled from 96.16%)
7245338 cache-misses # 27.576 M/sec (scaled from 95.49%)
0.265238069 seconds time elapsed 如上图所示,在默认情况下,perf stat会统计cycles、instructions、cache-misses、context-switches等对系统或软件性能影响最大的几个硬件和软件事件。通过这些统计情况,基本上就能了解软件的运行效率是受CPU影响较大还是IO影响较大,是受运算指令数影响较大还是内存访问影响较大。通过指令数、缓存访问数等统计还能大致判断软件性能是否符合对应的功能设计,是否有代码级优化的可能。
例子:
$ sudo perf stat
^C
Performance counter stats for 'system wide':
6084.136557 cpu-clock (msec) # 1.000 CPUs utilized
1,946 context-switches # 0.320 K/sec
0 cpu-migrations # 0.000 K/sec
2,136 page-faults # 0.351 K/sec
cycles
instructions
branches
branch-misses
6.084153948 seconds time elapsed
$ sudo perf stat -p 32495
^C
Performance counter stats for process id '32495':
9.054988 task-clock (msec) # 0.000 CPUs utilized
76 context-switches # 0.008 M/sec
0 cpu-migrations # 0.000 K/sec
3,922 page-faults # 0.433 M/sec
cycles
instructions
branches
branch-misses
61.575801254 seconds time elapsed 解释如下:
cpu-clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
context-switches:程序在运行过程中上下文的切换次数。
CPU-migrations:程序在运行过程中发生的处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
CPU迁移和上下文切换:发生上下文切换不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换。发生上下文切换有可能只是把上下文从当前CPU中换出,下一次调度器还是将进程安排在这个CPU上执行。
page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数。如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz。可以用cycles / task-clock算出。
stalled-cycles-frontend:指令读取或解码的质量步骤,未能按理想状态发挥并行左右,发生停滞的时钟周期。
stalled-cycles-backend:指令执行步骤,发生停滞的时钟周期。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。branch-misses是预测错误的分支指令数。网上例子
$ sudo perf stat
^C
Performance counter stats for 'system wide':
40904.820871 cpu-clock (msec) # 5.000 CPUs utilized
18,132 context-switches # 0.443 K/sec
1,053 cpu-migrations # 0.026 K/sec
2,420 page-faults # 0.059 K/sec
3,958,376,712 cycles # 0.097 GHz (49.99%)
574,598,403 stalled-cycles-frontend # 14.52% frontend cycles idle (49.98%)
9,392,982,910 stalled-cycles-backend # 237.29% backend cycles idle (50.00%)
1,653,185,883 instructions # 0.42 insn per cycle
# 5.68 stalled cycles per insn (50.01%)
237,061,366 branches # 5.795 M/sec (50.02%)
18,333,168 branch-misses # 7.73% of all branches (50.00%)
8.181521203 seconds time elapsed
perf top
perf top可以用于观察系统和软件内性能开销最大的函数列表。通过观察不同事件的函数列表可以分析出不同函数的性能开销情况和特点,判断其优化方向。例如如果某个函数在perf top -e instructions中排名靠后,却在perf top -e cache-misses和perf top -e cycles中排名靠前,说明函数中存在大量cache-miss造成CPU资源占用较多,就可以考虑优化该函数中的内存访问次数和策略,来减少内存访问和cache-miss次数,从而降低CPU开销。
在较新的内核版本中,perf top还可以深入到函数对应的汇编指令中,明确指出是哪些指令占用了计算资源,可以非常明确的指明软件性能热点。
- perf record和perf report
perf record一般和perf report搭配使用。perf record可以记录系统或软件一段时间内的事件统计情况,再通过perf report进行文本界面的展示。使用perf record可以将时间段内的情况记录下来,进行整个时段的分析,或者复制到其他设备上做后续分析,这是其他命令不支持的。perf record还有一个特别的参数-g,可以支持记录函数的调用关系。使用这个参数,就不止能够看到性能开销高的函数列表,还能看到这些函数是如何被调用和使用的。在很多情况下,性能开销高的函数都是memcpy之类的系统基础函数,其本身是没有什么优化空间的,能够优化的是调用memcpy的方式和次数。通过perf record -g就能够分析出这些函数的调用关系,从而找到真正需要优化的代码位置。(代码级的分析工具)
- perf bench
perf bench作为benchmark工具的通用框架,包含sched/mem/numa/futex等子系统,all可以指定所有。
perf bench可用于评估系统sched/mem等特定性能。
perf bench sched:调度器和IPC机制。包含messaging和pipe两个功能。
perf bench mem:内存存取性能。包含memcpy和memset两个功能。
perf bench numa:NUMA架构的调度和内存处理性能。包含mem功能。
perf bench futex:futex压力测试。包含hash/wake/wake-parallel/requeue/lock-pi功能。
perf bench all:所有bench测试的集合
例如:
$ perf bench sched all
# Running sched/messaging benchmark...
# 20 sender and receiver processes per group
# 10 groups == 400 processes run
Total time: 0.975 [sec]
# Running sched/pipe benchmark...
# Executed 1000000 pipe operations between two processes
Total time: 4.082 [sec]
4.082204 usecs/op
244965 ops/sec
linux下各种日志
centos6系统开始使用rsyslogd日志,他比原先的syslog更加先进且向下兼容之
确定服务是否启动:
1.ps -aux | grep rsyslogd 查看当前服务是否启动
2.chkconfig -- list | grep rsyslog 查看是否开机自启动(列出在各个级别下)
常见日志
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一,系统出现问题时,首先检查这个
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件
/var/log/utmp 记录当前已登录的用户的信息。不能vi,可通过w,who,users等命令来查询
/var/log/btmp 记录错误登录的日志,这个文件是二进制文件,不能直接vi查看,而要使用lastb命令查看,直接在命令行输入lastb 即可
/var/log/dmesg 记录了系统在开机时内核自检的信息。也可以使用dmesg命令直接查看内核自检信息
/var/log/lastlog 记录系统中所有用户最后一次登录时间的日志,也是二进制文件不能直接vi,用lastlog命令查看。;
/var/log/secure 记录验证和授权方面的信息,只要涉及账户和密码的程序都会记录,比如系统登录。ssh、su、sudo等,甚至添加用户、修改用户密码
日志格式:时间、主机名、程序名、具体事件信息
如
![]()
系统运行级别:
0:关机
1:单用户模式,类似windows的安全模式,主要用于系统修复
2:不完全的命令行模式,(多用户状态的但没有网络服务
3:完全命令行模式,就是标准字符界面(多用户状态有网络服务
4:保留
5:图形界面
6:系统重启
runlevel :查看运行级别命令
init 运行级别 :改变运行级别明命令
vim /etc/inittab 的最后一行 :修改默认运行级别
Linux开机流程
加载BIOS的硬件信息与进行自我测试,并依据设置取得第一个可启动设备;
读取并执行第一个启动设备内MBR(主引导分区)的Boot Loader(即是gurb等程序);
依据Boot Loader的设置加载Kernel,Kernel会开始检测硬件与加载驱动程序(常见的驱动程序放在内核中,其余的放在硬盘的/lib目录,需要的时候再加载);
在硬件驱动成功后,Kernel会主动调用init进程(/sbin/init),而init会取得runlevel信息;
init执行/etc/rc.d/rc.sysinit文件来准备软件的操作环境(如网络、时区等)(初始化系统);
init执行runlevel的各个服务的启动(script方式);
init执行/etc/rc.d/rc.local文件(服务程序);
init执行终端机模拟程序mingetty来启动login程序,最后等待用户登录。
makefile 的编写
在应用时候,定下的规则一般这样:
①如果这个工程没有编译过,那么我们的所有c文件都要编译并被链接。
②如果这个工程的某几个c文件被修改,那么我们只编译被修改的c文件,并链接目标程序。(所以先分别把各个.c编译成.o,再一起链接)
③如果这个工程的头文件被改变了,那么我们需要编译引用了这几个头文件的c文件,并链接目标程序。
所以只要我们的makefile写得够好,所有的这一切,我们只用一个make命令就可以完成,make命令会自动智能地根据当前的文件修改的情况来确定哪些文件需要重编译,从而自己编译所需要的文件和链接目标程序。
gcc编译过程:
c文件 汇编文件 二进制文件 可执行文件
hello.c ----> hello.i --------> hello.s ---------> hello.o ----------> a.out
gcc -E gcc -S gcc -c gcc
预处理器 编译器 汇编器 链接器
如: gcc -E hello.c -o hello.i
预编译:
1.头文件.h 和库文件引用进来
2.宏定义展开
makefile:用于多个.c文件编译的脚本语言
创建一个没有后缀的文件,命名为Makefile
- #是注释
- 如果命令太长,你可以使用反斜框(‘/’)作为换行符。make对一行上有多少个字符没有限制。
- 显示规则
a.语法格式:
目标文件:依赖文件
TAB 指令
b. 第一个目标文件是我们的终极目标
c. .伪目标 .PHONY
如每一次编译,都把之前的那些中间文件都删除
hello:hello.o
gcc hello.o -o hello
hello.o:hello.S
gcc -c hello.S -o hello.o
hello.S:hello.i
gcc -S hello.i -o hello.S
hello.i:hello.c
gcc -E hello.c -o hello.i
.PHONY:
#删除所有文件
clearall:
rm -rf hello.i hello.S hello.o hello
#删除过程文件
clean:
rm -rf hello.i hello.S hello.o使用:bash中输入 make clearall 就会删除所有文件,同理,输入 make clean 就会删除过程文件
输入make,就会自动执行那几条编译命令,并生成hello 就可以./hello执行了。
例子:
现有3对.c .h文件分别是circle.c cube.c main.c
编写Makefile如下:
test:circle.o cube.o main.o
gcc circle.o cube.o main.o -o test
circle.o:circle.c
gcc -c circle.c -o circle.o
cube.cube.c
gcc -c cube.c -o cube.o
main.main.c
gcc -c main.c -o main.o
.PHONY:
clean:
rm -rf circle.o cube.o main.o test

在默认的方式下,也就是我们只输入make命令。那么,
1、make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
2、如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“test”这个文件,并把这个文件作为最终的目标文件。
3、如果test文件不存在,或是test所依赖的后面的 .o 文件的文件修改时间要比test这个文件新,那么,他就会执行后面所定义的命令来生成test这个文件。
4、如果test所依赖的.o文件也存在,那么make会在当前文件中找目标为.o文件的依赖性,如果找到则再根据那一个规则生成.o文件。(这有点像一个堆栈的过程)
5、当然,你的C文件和H文件是存在的啦,于是make会生成 .o 文件,然后再用 .o 文件生命make的终极任务,也就是执行文件test了。
于是在我们编程中,如果这个工程已被编译过了,当我们修改了其中一个源文件,比如circle.c,那么根据我们的依赖性,我们的目标circle.o会被重编译(也就是在这个依性关系后面所定义的命令),于是circle.o的文件也是最新的啦,于是circle.o的文件修改时间要比test要新,所以test也会被重新链接了。
原文:https://blog.csdn.net/haoel/article/details/2887
- 变量
变量 =(替换) +=(追加) :=(常量)
如 TARGET = test 定义变量TARGET并替换为test(类似c语言的宏)
CC :=gcc 常量
TARGET = test
Obj = circle.o cube.o main.o
CC:=gcc
$(TARGET):$(Obj)
$(CC) $(Obj) -o $(TARGET)
circle.o:circle.c
$(CC) -c circle.c -o circle.o
cube.cube.c
$(CC) -c cube.c -o cube.o
main.main.c
$(CC) -c main.c -o main.o
.PHONY:
clean:
rm -rf $(Obj) $(TARGET)
#变量 =(替换) +=(追加) :=(常量)这样,如果有新的 .o 文件加入,我们只需简单地修改一下 Obj 变量就可以了
- 隐含规则
%.c 指任意一个.c文件 %.o 指任意一个.o文件
*.c 指所有的.c文件 *.o 指所有的.o文件
TARGET = test
Obj = circle.o cube.o main.o
CC:=gcc
$(TARGET):$(Obj)
$(CC) $(Obj) -o $(TARGET)
%.o:%.c
$(CC) -c %.c -o %.o #任意一个.c文件都是由.o文件通过gcc -c .c文件 -o .o文件得到的
.PHONY:
clean:
rm -rf *.o &(TARGET)- 通配符
$^:依赖文件列表所有所有文件的名字
$@:表示目标的名字
$<:依赖文件列表的第一个文件的名字
$?:构造依赖文件列表中更新过的文件
波浪号(“~”)字符在文件名中也有比较特殊的用途。如果是“~/test”,这就表示当前用户的$HOME目录下的test目录。而“~hchen/test”则表示用户hchen的宿主目录下的test目录。
例如:
1 test1.o:test1.c
2 gcc -o $@ $<
$@:就是test1.o
$<:就是test1.c
1 test1.o:test1.c head.c
2 gcc -o $@ $^
$^:就是test1.c head.c原文:https://blog.csdn.net/haoel/article/details/2888
- make自动推导
GNU的make很强大,它可以自动推导文件以及文件依赖关系后面的命令,于是我们就没必要去在每一个[.o]文件后都写上类似的命令,因为,我们的make会自动识别,并自己推导命令。这种方法,也就是make的“隐晦规则”。
只要make看到一个[.o]文件,它就会自动的把[.c]文件加在依赖关系中,如果make找到一个whatever.o,那么whatever.c,就会是whatever.o的依赖文件。并且 cc -c whatever.c 也会被推导出来,于是,我们的makefile再也不用写得这么复杂。我们的是新的makefile又出炉了。
objects = main.o kbd.o command.o display.o insert.o search.o files.o utils.o
edit : $(objects)
cc -o edit $(objects)
main.o : defs.h
kbd.o : defs.h command.h #将自动推导kbd.c
command.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
.PHONY : clean
clean :
-rm edit $(objects)
- 清空目标文件的规则
每个Makefile中都应该写一个清空目标文件(.o和执行文件)的规则,这不仅便于重编译,也很利于保持文件的清洁。这是一个“修养”
.PHONY意思表示clean是一个“伪目标”,。而在rm命令前面加了一个小减号的意思就是,也许某些文件出现问题,但不要管,继续做后面的事。当然,clean的规则不要放在文件的开头,不然,这就会变成make的默认目标,相信谁也不愿意这样。不成文的规矩是——“clean从来都是放在文件的最后”。
- 引用其它的Makefile
在Makefile使用include关键字可以把别的Makefile包含进来,这很像C语言的#include,被包含的文件会原模原样的放在当前文件的包含位置。include的语法是:
include
filename可以是当前操作系统Shell的文件模式(可以保含路径和通配符)
在include前面可以有一些空字符,但是绝不能是[Tab]键开始。include和
include foo.make *.mk $(bar)
等价于:
include foo.make a.mk b.mk c.mk e.mk f.mk
make命令开始时,会把找寻include所指出的其它Makefile,并把其内容安置在当前的位置。就好像C/C++的#include指令一样。如果文件都没有指定绝对路径或是相对路径的话,make会在当前目录下首先寻找,如果当前目录下没有找到,那么,make还会在下面的几个目录下找:
1、如果make执行时,有“-I”或“--include-dir”参数,那么make就会在这个参数所指定的目录下去寻找。
2、如果目录
如果有文件没有找到的话,make会生成一条警告信息,但不会马上出现致命错误。它会继续载入其它的文件,一旦完成makefile的读取,make会再重试这些没有找到,或是不能读取的文件,如果还是不行,make才会出现一条致命信息。如果你想让make不理那些无法读取的文件,而继续执行,你可以在include前加一个减号“-”。如:
-include
其表示,无论include过程中出现什么错误,都不要报错继续执行。和其它版本make兼容的相关命令是sinclude,其作用和这一个是一样的。
- make的工作方式
GNU的make工作时的执行步骤入下:(想来其它的make也是类似)
1、读入所有的Makefile。
2、读入被include的其它Makefile。
3、初始化文件中的变量。
4、推导隐晦规则,并分析所有规则。
5、为所有的目标文件创建依赖关系链。
6、根据依赖关系,决定哪些目标要重新生成。
7、执行生成命令。
1-5步为第一个阶段,6-7为第二个阶段。第一个阶段中,如果定义的变量被使用了,那么,make会把其展开在使用的位置。但make并不会完全马上展开,make使用的是拖延战术,如果变量出现在依赖关系的规则中,那么仅当这条依赖被决定要使用了,变量才会在其内部展开。
- 文件搜寻
在一些大的工程中,有大量的源文件,我们通常的做法是把这许多的源文件分类,并存放在不同的目录中。所以,当make需要去找寻文件的依赖关系时,你可以在文件前加上路径,但最好的方法是把一个路径告诉make,让make在自动去找。
Makefile文件中的特殊变量“VPATH”就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当当前目录找不到的情况下,到所指定的目录中去找寻文件了。
VPATH = src:../headers
上面的的定义指定两个目录,“src”和“../headers”,make会按照这个顺序进行搜索。目录由“冒号”分隔。(当然,当前目录永远是最高优先搜索的地方)
另一个设置文件搜索路径的方法是使用make的“vpath”关键字(注意,它是全小写的),这不是变量,这是一个make的关键字,这和上面提到的那个VPATH变量很类似,但是它更为灵活。它可以指定不同的文件在不同的搜索目录中。这是一个很灵活的功能。它的使用方法有三种:
1、vpath
为符合模式
2、vpath
清除符合模式
3、vpath
清除所有已被设置好了的文件搜索目录。
vapth使用方法中的
vpath %.h ../headers
该语句表示,要求make在“../headers”目录下搜索所有以“.h”结尾的文件。(如果某文件在当前目录没有找到的话)
我们可以连续地使用vpath语句,以指定不同搜索策略。如果连续的vpath语句中出现了相同的
vpath %.c foo
vpath %.c blish
vpath %.c bar
其表示“.c”结尾的文件,先在“foo”目录,然后是“blish”,最后是“bar”目录。
vpath %.c foo:bar
vpath %.c blish
而上面的语句则表示“.c”结尾的文件,先在“foo”目录,然后是“bar”目录,最后才是“blish”目录。
- 伪目标
最早先的一个例子中,我们提到过一个“clean”的目标,这是一个“伪目标”,
clean:
rm *.o temp
正像我们前面例子中的“clean”一样,即然我们生成了许多文件编译文件,我们也应该提供一个清除它们的“目标”以备完整地重编译而用。 (以“make clean”来使用该目标)
因为,我们并不生成“clean”这个文件。“伪目标”并不是一个文件,只是一个标签,由于“伪目标”不是文件,所以make无法生成它的依赖关系和决定它是否要执行。我们只有通过显示地指明这个“目标”才能让其生效。当然,“伪目标”的取名不能和文件名重名,不然其就失去了“伪目标”的意义了。
当然,为了避免和文件重名的这种情况,我们可以使用一个特殊的标记“.PHONY”来显示地指明一个目标是“伪目标”,向make说明,不管是否有这个文件,这个目标就是“伪目标”。
.PHONY : clean
只要有这个声明,不管是否有“clean”文件,要运行“clean”这个目标,只有“make clean”这样。于是整个过程可以这样写:
.PHONY: clean
clean:
rm *.o temp
伪目标一般没有依赖的文件。但是,我们也可以为伪目标指定所依赖的文件。伪目标同样可以作为“默认目标”,只要将其放在第一个。一个示例就是,如果你的Makefile需要一口气生成若干个可执行文件,但你只想简单地敲一个make完事,并且,所有的目标文件都写在一个Makefile中,那么你可以使用“伪目标”这个特性:
all : prog1 prog2 prog3
.PHONY : all
prog1 : prog1.o utils.o
cc -o prog1 prog1.o utils.o
prog2 : prog2.o
cc -o prog2 prog2.o
prog3 : prog3.o sort.o utils.o
cc -o prog3 prog3.o sort.o utils.o
我们知道,Makefile中的第一个目标会被作为其默认目标。我们声明了一个“all”的伪目标,其依赖于其它三个目标。由于伪目标的特性是,总是被执行的,所以其依赖的那三个目标就总是不如“all”这个目标新。所以,其它三个目标的规则总是会被决议。也就达到了我们一口气生成多个目标的目的。“.PHONY : all”声明了“all”这个目标为“伪目标”。
- wildcard 介绍
在Makefile规则中,通配符会被自动展开。但在变量的定义和函数引用时,通配符将失效。这种情况下如果需要通配符有效,就需要使用函数“wildcard”,它的用法是:$(wildcard PATTERN...) 。在Makefile中,它被展开为已经存在的、使用空格分开的、匹配此模式的所有文件列表。如果不存在任何符合此模式的文件,函数会忽略模式字符并返回空。需要注意的是:这种情况下规则中通配符的展开和上一小节匹配通配符的区别。
一般我们可以使用“$(wildcard *.c)”来获取工作目录下的所有的.c文件列表。复杂一些用法;可以使用“$(patsubst %.c,%.o,$(wildcard *.c))”,首先使用“wildcard”函数获取工作目录下的.c文件列表;之后将列表中所有文件名的后缀.c替换为.o。这样我们就可以得到在当前目录可生成的.o文件列表。因此在一个目录下可以使用如下内容的Makefile来将工作目录下的所有的.c文件进行编译并最后连接成为一个可执行文件:
#sample Makefile
objects := $(patsubst %.c,%.o,$(wildcard *.c))
foo : $(objects)
cc -o foo $(objects)这里我们使用了make的隐含规则来编译.c的源文件。对变量的赋值也用到了一个特殊的符号(:=)。
1、wildcard : 扩展通配符
2、notdir : 去除路径
3、patsubst :替换通配符
例子:
建立一个测试目录,在测试目录下建立一个名为sub的子目录
$ mkdir test
$ cd test
$ mkdir sub
在test下,建立a.c和b.c2个文件,在sub目录下,建立sa.c和sb.c2 个文件
建立一个简单的Makefile
src=$(wildcard *.c ./sub/*.c)
dir=$(notdir $(src))
obj=$(patsubst %.c,%.o,$(dir) )
all:
@echo $(src)
@echo $(dir)
@echo $(obj)
@echo "end"执行结果分析:
第一行输出:
a.c b.c ./sub/sa.c ./sub/sb.c
wildcard把 指定目录 ./ 和 ./sub/ 下的所有后缀是c的文件全部展开。
第二行输出:
a.c b.c sa.c sb.c
notdir把展开的文件去除掉路径信息
第三行输出:
a.o b.o sa.o sb.o
在$(patsubst %.c,%.o,$(dir) )中,patsubst把$(dir)中的变量符合后缀是.c的全部替换成.o,
任何输出。
或者可以使用
obj=$(dir:%.c=%.o)
效果也是一样的。
这里用到makefile里的替换引用规则,即用您指定的变量替换另一个变量。
它的标准格式是
$(var:a=b) 或 ${var:a=b}
它的含义是把变量var中的每一个值结尾用b替换掉a
$^:依赖文件列表所有所有文件的名字
$@:表示目标的名字
$<:依赖文件列表的第一个文件的名字
$?:构造依赖文件列表中更新过的文件
看一个例子:
SOURCE := $(wildcard *.cpp)
OBJS := $(patsubst %.c,%.o,$(patsubst %.cpp,%.o,$(SOURCE))) #在OBJS中 把.cpp和.c的文件变成.o的后缀
TARGET := myserver
CC := g++
LIBS := -lpthread -lopencv_core -lopencv_imgproc -lopencv_highgui
INCLUDE:= -I./usr/local/include/opencv
CFLAGS := -std=c++11 -g -Wall -O3 $(INCLUDE)
CXXFLAGS:= $(CFLAGS)
.PHONY : objs clean veryclean rebuild all
all : $(TARGET)
objs : $(OBJS)
rebuild: veryclean all
clean :
rm -fr *.o
veryclean : clean
rm -rf $(TARGET)
$(TARGET) : $(OBJS)
$(CC) $(CXXFLAGS) -o $@ $(OBJS) $(INCLUDE) $(LIBS)- gcc 编译选项
- Wall 会打开一些很有用的警告选项,建议编译时加此选项。
-O0
-O1
-O2
-O3
编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-g
只是编译器,在编译的时候,产生调试信息。
-llibrary
定制编译的时候使用的库
例子用法
gcc -lcurses hello.c
使用curses库编译程序
-M
生成文档关联的信息。包含目标文档所依赖的任何源代码您能够用gcc -M hello.c来测试一下,很简单。
-include file
包含某个代码,简单来说,就是便以某个文档,需要另一个文档的时候,就能够用他设定,功能就相当于在代码中使用 #include
例子用法:
gcc hello.c -include /root/pianopan.h
-static:此选项将禁止使用动态库,所以,编译出来的东西,一般都很大。
-share:此选项将尽量使用动态库,所以生成文档比较小,但是需要系统由动态库。
-std:指定C标准,如-std=c99使用c99标准,-std=gnu99,使用C99 再加上 GNU 的一些扩展。
-Idir:指定头文件路径。在您是用#include"file"的时候,gcc/g++会先在当前目录查找您所定制的头文档,假如没有找到,他回到缺省 的头文档目录找,假如使用-I定制了目录,他会先在您所定制的目录查找,然后再按常规的顺序去找. 如
-I ./usr/local/include/opencv
cmake 的编写
https://www.hahack.com/codes/cmake/#
什么是cmake?
你或许听过好几种 Make 工具,例如 GNU Make ,QT 的 qmake ,微软的 MS nmake,BSD Make(pmake),Makepp,等等。这些 Make 工具遵循着不同的规范和标准,所执行的 Makefile 格式也千差万别。这样就带来了一个严峻的问题:如果软件想跨平台,必须要保证能够在不同平台编译。而如果使用上面的 Make 工具,就得为每一种标准写一次 Makefile ,这将是一件让人抓狂的工作。
CMake就是针对上面问题所设计的工具:它首先允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程,然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件,如 Unix 的 Makefile 或 Windows 的 Visual Studio 工程。从而做到“Write once, run everywhere”。显然,CMake 是一个比上述几种 make 更高级的编译配置工具。一些使用 CMake 作为项目架构系统的知名开源项目有 VTK、ITK、KDE、OpenCV、OSG 等
在 linux 平台下使用 CMake 生成 Makefile 并编译的流程如下:
- 编写 CMake 配置文件 CMakeLists.txt 。
- 执行命令
cmake PATH或者ccmake PATH生成 Makefile, 其中,PATH是 CMakeLists.txt 所在的目录。 - 使用
make命令进行编译。
ccmake 和 cmake 的区别在于前者提供了一个交互式的界面。
例子:
对于简单的项目,只需要写几行代码就可以了。例如,假设现在我们的项目中只有一个源文件 main.cc
首先编写 CMakeLists.txt 文件,并保存在与 main.cc 源文件同个目录下:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo1)
# 指定生成目标
add_executable(Demo main.cc)
MakeLists.txt 的语法比较简单,由命令、注释和空格组成,其中命令是不区分大小写的。符号 # 后面的内容被认为是注释。命令由命令名称、小括号和参数组成,参数之间使用空格进行间隔。
对于上面的 CMakeLists.txt 文件,依次出现了几个命令:
cmake_minimum_required:指定运行此配置文件所需的 CMake 的最低版本;project:参数值是Demo1,该命令表示项目的名称是Demo1。 (为整个工程设置一个工程名)add_executable: 将名为 main.cc 的源文件编译成一个名称为 Demo 的可执行文件。
编译项目
之后,在当前目录执行 cmake . ,得到 Makefile 后再使用 make 命令编译得到 Demo1 可执行文件。
[ehome@xman Demo1]$ cmake .
-- The C compiler identification is GNU 4.8.2
-- The CXX compiler identification is GNU 4.8.2
-- Check for working C compiler: /usr/sbin/cc
-- Check for working C compiler: /usr/sbin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working CXX compiler: /usr/sbin/c++
-- Check for working CXX compiler: /usr/sbin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/ehome/Documents/programming/C/power/Demo1
[ehome@xman Demo1]$ make
Scanning dependencies of target Demo
[100%] Building C object CMakeFiles/Demo.dir/main.cc.o
Linking C executable Demo
[100%] Built target Demo多个源文件
同一目录,多个源文件
上面的例子只有单个源文件。现在假如把 power 函数单独写进一个名为 MathFunctions.c 的源文件里,使得这个工程变成如下的形式:
./Demo2
|
+--- main.cc
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
这个时候,CMakeLists.txt 可以改成如下的形式:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 指定生成目标
add_executable(Demo main.cc MathFunctions.cc)
唯一的改动只是在 add_executable 命令中增加了一个 MathFunctions.cc 源文件。这样写当然没什么问题,但是如果源文件很多,把所有源文件的名字都加进去将是一件烦人的工作。更省事的方法是使用 aux_source_directory 命令,该命令会查找指定目录下的所有源文件,然后将结果存进指定变量名。其语法如下:
aux_source_directory( )
因此,可以修改 CMakeLists.txt 如下:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 查找当前目录下的所有源文件
# 并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 指定生成目标
add_executable(Demo ${DIR_SRCS})
这样,CMake 会将当前目录所有源文件的文件名赋值给变量 DIR_SRCS ,再指示变量 DIR_SRCS 中的源文件需要编译成一个名称为 Demo 的可执行文件。
多个目录,多个源文件
现在进一步将 MathFunctions.h 和 MathFunctions.cc 文件移动到 math 目录下。
./Demo3
|
+--- main.cc
|
+--- math/
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
对于这种情况,需要分别在项目根目录 Demo3 和 math 目录里各编写一个 CMakeLists.txt 文件。为了方便,我们可以先将 math 目录里的文件编译成静态库再由 main 函数调用。
根目录中的 CMakeLists.txt :
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo3)
# 查找当前目录下的所有源文件
# 并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 添加 math 子目录
add_subdirectory(math)
# 指定生成目标
add_executable(Demo main.cc)
# 添加链接库
target_link_libraries(Demo MathFunctions)
该文件添加了下面的内容: 第3行,使用命令 add_subdirectory 指明本项目包含一个子目录 math,这样 math 目录下的 CMakeLists.txt 文件和源代码也会被处理 。第6行,使用命令 target_link_libraries 指明可执行文件 main 需要连接一个名为 MathFunctions 的链接库 。
子目录中的 CMakeLists.txt:
# 查找当前目录下的所有源文件
# 并将名称保存到 DIR_LIB_SRCS 变量
aux_source_directory(. DIR_LIB_SRCS)
# 生成链接库
add_library (MathFunctions ${DIR_LIB_SRCS})
VIM的常用操作

1.删除字符
要删除一个字符,只需要将光标移到该字符上按下"x"。
2.删除一行
删除一整行内容使用"dd"命令。删除后下面的行会移上来填补空缺。
3.删除换行符
在Vim中你可以把两行合并为一行,也就是说两行之间的换行符被删除了:命令是"J"。
4.撤销
如果你误删了过多的内容。显然你可以再输入一遍,但是命令"u" 更简便,它可以撤消上一次的操作。
5.重做
如果你撤消了多次,你还可以用CTRL-R(重做)来反转撤消的动作。换句话说,它是对撤消的撤消。撤消命令还有另一种形式,"U"命令,它一次撤消对一行的全部操作。第二次使用该命令则会撤消前一个"U"的操作。用"u"和CTRL-R你可以找回任何一个操作状态。
6.追加
"i"命令可以在当前光标之前插入文本。
"a"命令可以在当前光标之后插入文本。
"o"命令可以在当前行的下面另起一行,并使当前模式转为Insert模式。
"O"命令(注意是大写的字母O)将在当前行的上面另起一行。
7.使用命令计数
假设你要向上移动9行。这可以用"kkkkkkkkk"或"9k"来完成。事实上,很多命令都可以接受一个数字作为重复执行同一命令的次数。比如刚才的例子,要在行尾追加三个感叹号,当时用的命令是"a!!!"。另一个办法是用"3a!"命令。3说明该命令将被重复执行3次。同样,删除3个字符可以用"3x"。指定的数字要紧挨在它所要修饰的命令前面。
8.退出
要退出Vim,用命令"ZZ"。该命令保存当前文件并退出Vim。
9.放弃编辑
丢弃所有的修改并退出,用命令":q!"。用":e!"命令放弃所有修改并重新载入该文件的原始内容。
10.以Word为单位的移动
使用"w"命令可以将光标向前移动一个word的首字符上;比如"3w"将光标向前移动3个words。"b"命令则将光标向后移动到前一个word的首字符上。
"e"命令会将光标移动到下一个word的最后一个字符。命令"ge",它将光标移动到前一个word的最后一个字符上。、
11.移动到行首或行尾
"$"命令将光标移动到当前行行尾。如果你的键盘上有一个键,它的作用也一样。"^"命令将光标移动到当前行的第一个非空白字符上。"0"命令则总是把光标移动到当前行的第一个字符上。键也是如此。"$"命令还可接受一个计数,如"1$"会将光标移动到当前行行尾,"2$"则会移动到下一行的行尾,如此类推。"0"命令却不能接受类似这样的计数,命令"^"前加上一个计数也没有任何效果。
12.移动到指定字符上
命令"fx"在当前行上查找下一个字符x(向右方向),可以带一个命令计数"F"命令向左方向搜索。"tx"命令形同"fx"命令,只不过它不是把光标停留在被搜索字符上,而是在它之前的一个字符上。提示:"t"意为"To"。该命令的反方向版是"Tx"。这4个命令都可以用";"来重复。以","也是重复同样的命令,但是方向与原命令的方向相反。
13.以匹配一个括号为目的移动
用命令"%"跳转到与当前光标下的括号相匹配的那一个括号上去。如果当前光标在"("上,它就向前跳转到与它匹配的")"上,如果当前在")"上,它就向后自动跳转到匹配的"("上去.
14.移动到指定行
用"G"命令指定一个命令计数,这个命令就会把光标定位到由命令计数指定的行上。比如"33G"就会把光标置于第33行上。没有指定命令计数作为参数的话, "G"会把光标定位到最后一行上。"gg"命令是跳转到第一行的快捷的方法。
另一个移动到某行的方法是在命令"%"之前指定一个命令计数比如"50%"将会把光标定位在文件的中间. "90%"跳到接近文件尾的地方。
命令"H","M","L",分别将光标跳转到第一行,中间行,结尾行部分。
15.告诉你当前的位置
使用CTRL-G命令。"set number"在每行的前面显示一个行号。相反关闭行号用命令":set nonumber"。":set ruler"在Vim窗口的右下角显示当前光标位置。
16.滚屏
CTRL-U显示文本的窗口向上滚动了半屏。CTRL-D命令将窗口向下移动半屏。一次滚动一行可以使用CTRL-E(向上滚动)和CTRL-Y(向下滚动)。要向前滚动一整屏使用命令CTRL-F。另外CTRL-B是它的反向版。"zz"命令会把当前行置为屏幕正中央,"zt"命令会把当前行置于屏幕顶端,"zb"则把当前行置于屏幕底端.
17.简单搜索 可用来搜索函数名
"/string"命令可用于搜索一个字符串。要查找上次查找的字符串的下一个位置,使用"n"命令。如果你知道你要找的确切位置是目标字符串的第几次出现,还可以在"n"之前放置一个命令计数。"3n"会去查找目标字符串的第3次出现。
"?"命令与"/"的工作相同,只是搜索方向相反."N"命令会重复前一次查找,但是与最初用"/"或"?"指定的搜索方向相反。
如果查找内容忽略大小写,则用命令"set ignorecase", 返回精确匹配用命令"set noignorecase" 。
18.在文本中查找下一个word
把光标定位于这个word上然后按下"*"键。Vim将会取当前光标所在的word并将它作用目标字符串进行搜索。"#"命令是"*"的反向版。还可以在这两个命令前加一个命令计数:"3*"查找当前光标下的word的第三次出现。
19.查找整个word
如果你用"/the"来查找Vim也会匹配到"there"。要查找作为独立单词的"the"使用如下命令:"/the\>"。"\>"是一个特殊的记法,它只匹配一个word的结束处。近似地,"\<"匹配到一个word的开始处。这样查找作为一个word的"the"就可以用:"/\"。
20.高亮显示搜索结果
开启这一功能用":set hlsearch",关闭这一功能:":set nohlsearch"。如果只是想去掉当前的高亮显示,可以使用下面的命令:":nohlsearch"(可以简写为noh)。
21.匹配一行的开头与结尾
^ 字符匹配一行的开头。$字符匹配一行的末尾。
所以"/was$"只匹配位于一行末尾的单词was,所以"/^was"只匹配位于一行开始的单词was。
22.匹配任何的单字符
.这个字符可以匹配到任何字符。比如"c.m"可以匹配任何前一个字符是c,后一个字符是m的情况,不管中间的字符是什么。
23.匹配特殊字符
放一个反斜杠在特殊字符前面。如果你查找"ter。",用命令"/ter\。"
24.使用标记
当你用"G"命令从一个地方跳转到另一个地方时,Vim会记得你起跳的位置。这个位置在Vim中是一个标记。使用命令" `` "可以使你跳回到刚才的出发点。
``命令可以在两点之间来回跳转。CTRL-O命令是跳转到你更早些时间停置光标的位置(提示:O意为older). CTRL-I则是跳回到后来停置光标的更新的位置(提示:I在键盘上位于O前面)。
注:使用CTRL-I 与按下键一样。
25.具名标记
命令"ma"将当前光标下的位置名之为标记"a"。从a到z一共可以使用26个自定义的标记。要跳转到一个你定义过的标记,使用命令" `marks "marks就是定义的标记的名字。命令" 'a "使你跳转到a所在行的行首," `a "会精确定位a所在的位置。命令:":marks"用来查看标记的列表。
命令delm!删除所有标记。
26.操作符命令和位移
"dw"命令可以删除一个word,"d4w"命令是删除4个word,依此类推。类似有"d2e"、"d$"。此类命令有一个固定的模式:操作符命令+位移命令。首先键入一个操作符命令。比如"d"是一个删除操作符。接下来是一个位移命。比如"w"。这样任何移动光标命令所及之处,都是命令的作用范围。
27.改变文本
操作符命令是"c",改变命令。它的行为与"d"命令类似,不过在命令执行后会进入Insert模式。比如"cw"改变一个word。或者,更准确地说,它删除一个word并让你置身于Insert模式。
"cc"命令可以改变整行。不过仍保持原来的缩进。
"c$"改变当前光标到行尾的内容。
快捷命令:x 代表dl(删除当前光标下的字符)
X 代表dh(删除当前光标左边的字符)
D 代表d$(删除到行尾的内容)
C 代表c$(修改到行尾的内容)
s 代表cl(修改一个字符)
S 代表cc(修改一整行)
命令"3dw"和"d3w"都是删除3个word。第一个命令"3dw"可以看作是删除一个word的操作执行3次;第二个命令"d3w"是一次删除3个word。这是其中不明显的差异。事实上你可以在两处都放上命令记数,比如,"3d2w"是删除两个word,重复执行3次,总共是6个word。
28.替换单个字符
"r"命令不是一个操作符命令。它等待你键入下一个字符用以替换当前光标下的那个字符。"r"命令前辍以一个命令记数是将多个字符都替换为即将输入的那个字符。要把一个字符替换为一个换行符使用"r"。它会删除一个字符并插入一个换行符。在此处使用命令记数只会删除指定个数的字符:"4r"将把4个字符替换为一个换行符。
29.重复改动
"."命令会重复上一次做出的改动。"."命令会重复你做出的所有修改,除了"u"命令CTRL-R和以冒号开头的命令。"."需要在Normal模式下执行,它重复的是命令,而不是被改动的内容,
30.Visual模式
按"v"可以进入Visual模式。移动光标以覆盖你想操纵的文本范围。同时被选中的文本会以高亮显示。最后键入操作符命令。
31.移动文本
以"d"或"x"这样的命令删除文本时,被删除的内容还是被保存了起来。你还可以用p命令把它取回来。"P"命令是把被去回的内容放在光标之前,"p"则是放在光标之后。对于以"dd"删除的整行内容,"P"会把它置于当前行的上一行。"p"则是至于当前行的后一行。也可以对命令"p"和"P"命令使用命令记数。它的效果是同样的内容被取回指定的次数。这样一来"dd"之后的"3p"就可以把被删除行的3 份副本放到当前位置。
命令"xp"将光标所在的字符与后一个字符交换。
32.复制文本(VIM编辑器内复制)
"y"操作符命令会把文本复制到一个寄存器3中。然后可以用"p"命令把它取回。因为"y"是一个操作符命令,所以你可以用"yw"来复制一个word. 同样可以使用命令记数。如下例中用"y2w"命令复制两个word,"yy"命令复制一整行,"Y"也是复制整行的内容,复制当前光标至行尾的命令是"y$"。
33.文本对象
"diw" 删除当前光标所在的word(不包括空白字符) "daw" 删除当前光标所在的word(包括空白字符)
34.快捷命令
x 删除当前光标下的字符("dl"的快捷命令)
X 删除当前光标之前的字符("dh"的快捷命令)
D 删除自当前光标至行尾的内容("d$"的快捷命令)
dw 删除自当前光标至下一个word的开头
db 删除自当前光标至前一个word的开始
diw 删除当前光标所在的word(不包括空白字符)
daw 删除当前光标所在的word(包括空白字符)
dG 删除当前行至文件尾的内容
dgg 删除当前行至文件头的内容
如果你用"c"命令代替"d"这些命令就都变成更改命令。使用"y"就是yank命令,如此类推。
35.编辑另一个文件
用命令":edit foo.txt",也可简写为":e foo.txt"。
36.文件列表
可以在启动Vim时就指定要编辑多个文件,用命令"vim one.c two.c three.c"。Vim将在启动后只显示第一个文件,完成该文件的编辑后,可以用令:":next"或":n"要保存工作成果并继续下一个文件的编辑,命令:":wnext"或":wn"可以合并这一过程。
37.显示当前正在编辑的文件
用命令":args"。
38.移动到另一个文件
用命令":previous" ":prev"回到上一个文件,合并保存步骤则是":wprevious" ":wprev"。要移到最后一个文件":last",到第一个":first".不过没有":wlast"或者":wfirst"这样的命令。可以在":next"和":previous"命令前面使用一个命令计数。
39.编辑另一个文件列表
不用重新启动Vim,就可以重新定义一个文件列表。命令":args five.c six.c seven.h"定义了要编辑的三个文件。
39.自动存盘
命令":set autowrite","set aw"。自动把内容写回文件: 如果文件被修改过,在每个:next、:rewind、:last、:first、:previous、:stop、:suspend、:tag、:!、:make、CTRL-] 和 CTRL-^命令时进行。
命令":set autowriteall","set awa"。和 'autowrite' 类似,但也适用于":edit"、":enew"、":quit"、":qall"、":exit"、":xit"、":recover" 和关闭 Vim 窗口。置位本选项也意味着 Vim 的行为就像打开 'autowrite' 一样。
40.切换到另一文件
要在两个文件间快速切换,使用CTRL-^。
41.文件标记
以大写字母命名的标记。它们是全局标记,它们可以用在任何文件中。比如,正在编辑"fab1.Java",用命令"50%mF"在文件的中间设置一个名为F的标记。然后在"fab2.java"文件中,用命令"GnB"在最后一行设置名为B的标记。在可以用"F"命令跳转到文件"fab1.java"的半中间。或者编辑另一个文件,"'B"命令会再把你带回文件"fab2.java"的最后一行。
要知道某个标记所代表的位置是什么,可以将该标记的名字作为"marks"命令的参数":marks M"或者连续跟上几个参数":marks MJK"
可以用CTRL-O和CTRL-I可以跳转到较早的位置和靠后的某位置。
42.查看文件
仅是查看文件,不向文件写入内容,可以用只读形式编辑文件。用命令:
vim -R file。如果是想强制性地避免对文件进行修改,可以用命令:
vim -M file。
43.更改文件名
将现有文件存成新的文件,用命令":sav(eas) move.c"。如果想改变当前正在编辑的文件名,但不想保存该文件,就可以用命令:":f(ile) move.c"。
44.分割一个窗口
打开一个新窗口最简单的办法就是使用命令:":split"。CTRL-W 命令可以切换当前活动窗口。
45.关闭窗口
用命令:"close".可以关闭当前窗口。实际上,任何退出文件编辑的命令":quit"和"ZZ"都会关闭窗口,但是用":close"可以阻止你关闭最后一个Vim,以免以意外地整个关闭了Vim。
46.关闭除当前窗口外的所有其他窗口
用命令:":only",关闭除当前窗口外的所有其它窗口。如果这些窗口中有被修改过的,你会得到一个错误信息,同时那个窗口会被留下来。
47.为另一个文件分隔出一个窗口
命令":split two.c"可以打开第二个窗口同时在新打开的窗口中开始编辑作为
参数的文件。如果要打开一个新窗口并开始编辑一个空的缓冲区,使用命令:":new"。
48.垂直分割
用命令":vsplit或::vsplit two.c"。同样有一个对应的":vnew"命令,用于垂直分隔窗口并在其中打开一个新的空缓冲区。
49.切换窗口
CTRL-W h 到左边的窗口
CTRL-W j 到下面的窗口
CTRL-W k 到上面的窗口
CTRL-W l 到右边的窗口
CTRL-W t 到顶部窗口
CTRL-W b 到底部窗口
50.针对所有窗口操作的命令
":qall"放弃所有操作并退出,":wall"保存所有,":wqall"保存所有并退出。
51.为每一个文件打开一个窗口
使用"-o"选项可以让Vim为每一个文件打开一个窗口:
"vim -o one.txt two.txt three.txt"。
52.使用vimdiff查看不同
"vimdiff main.c~ main.c",另一种进入diff模式的办法可以在Vim运行中操作。编辑文件"main.c",然后打开另一个分隔窗口显示其不同:
":edit main.c"
":vertical diffpatch main.c.diff"。
53.页签
命令":tabe(dit) thatfile"在一个窗口中打开"thatfile",该窗口占据着整个的Vim显示区域。命令":tab split/new"结果是新建了一个拥有一个窗口的页签。以用"gt"命令在不同的页签间切换。
很多人使用vim的时候, 会发现函数跳转的功能没有,怎么办?vim提供了强有力的函数跳转的插件功能!
首先要安装ctags, 在ubuntu下直接输入
sudo apt-get install exuberant-ctags
接着,在源文件目录树(这里是在/home/ballack/test/目录下)执行如下命令:
ctags -R .
即可在/home/ballack/test目录下生成一个tags文件, 这个文件就是所有函数和变量的索引列表。

接着打开用vim打开任一文件,找到模块定义函数,通过快捷键 " CTRL + ] ", 即可快速跳转到函数定义处
此时如果想要回到跳转之前的位置, 只需要通过快捷键“ CTRL + T ”即可。这种方式不局限于同一文件中的跳转,也适合于不同文件之间的跳转,而且按了多少次“ CTRL + ] ”,就可以按多少次“ CTRL + T ”原路返回,非常方便好用!!!