Python爬虫06-使用Scrapy框架爬取BOSS直聘招聘信息
Python爬虫06-使用Scrapy框架爬取BOSS直聘招聘信息
文章目录
- Python爬虫06-使用Scrapy框架爬取BOSS直聘招聘信息
- 1. 结构
- 2. 源码
- 2.1 boss.py
- 2.2 items.py
- 2.3 middlewares.py
- 2.4 pipeline.py
- 2.5 seetings.py
- 2.6 start.py
- 3. 踩到的坑
- 3.1 一步解决user-agent
- 3.2 写入数据库时遇到的问题
- 3.3 控制并发请求数、下载延迟
- 3.4 Rule 的使用
- 3.5 设置代理池
- 3.6 scrapy shell
- 4. 源码
1. 结构
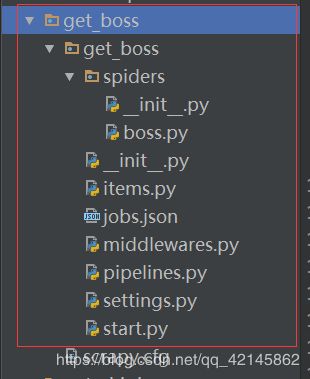
2. 源码
2.1 boss.py
# -*- coding: utf-8 -*-
import scrapy
from pyquery import PyQuery
from scrapy.http import Request
from scrapy.utils.response import get_base_url
from urllib.parse import urljoin
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import os
path = os.path.abspath(os.path.join(os.getcwd(), "../.."))
import sys
sys.path.append(path)
from get_boss.items import GetBossItem
headers = {
'x-devtools-emulate-network-conditions-client-id': "5f2fc4da-c727-43c0-aad4-37fce8e3ff39",
'upgrade-insecure-requests': "1",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'dnt': "1",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.8,en;q=0.6",
'cookie': "__c=1527989289; __g=-; lastCity=100010000; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fjob_detail%2Fc77944563dd5cc1a1XV70tW0ElM%7E.html%3Fka%3Dsearch_list_1_blank%26lid%3DTvnYVWp16I.search; JSESSIONID=""; __l=l=%2Fwww.zhipin.com%2F&r=; __a=33024288.1527773672.1527940079.1527989289.90.5.22.74; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1527774077,1527835258,1527940079,1527989289; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1527991981",
'cache-control': "no-cache",
'postman-token': "76554687-c4df-0c17-7cc0-5bf3845c9831",
'x-requested-with':'XMLHttpRequest',
'referer':"https://www.zhipin.com/job_detail/?query=&scity=100010000&industry=&position=",
# 'user-agent':ua #需要替换的
#'user-agent': 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52'
}
class BossSpider(CrawlSpider):
name = 'boss'
start_urls = ['https://www.zhipin.com/gongsir/5d627415a46b4a750nJ9.html?page=1']
url1 = 'https://www.zhipin.com' #用来做拼接
# 匹配职位列表页的规则
rules = (
Rule(LinkExtractor(allow=r'.+\?page=\d+'), callback="parse_url",follow=True),
)
# 匹配详情页的规则
# rules = (
# Rule(LinkExtractor(allow=r'.+job_detail/\w+~.html'), callback="detail_parse", follow=False),
# )
def parse_url(self, response):
item = GetBossItem()
for i in range(1,15):
url = response.xpath('//*[@id="main"]/div[2]/div[2]/div[2]/ul/li[{}]/a/@href'.format(str(i))).extract()
url = self.url1+str(url[0])
print(url)
# if item['url']:
yield Request(url,
callback=self.detail_parse,#回调详情页函数
meta={'item':item}, #将参数传递给meta#
priority=10,
dont_filter=True, #强制不过滤
#headers=headers
# headers=self.headers
)
def detail_parse(self,response):
item = response.meta['item'] #接收item
# 企业名称
dp_name = response.xpath('//div[@class="job-sec"]/div[@class="name"]/text()').get().strip()
# 企业类型
dp_type = response.xpath('//div[@class="level-list"]/li[@class="company-type"]/text()').getall()[0]
# 企业成立时间
dp_founded = response.xpath('//div[@class="level-list"]/li[@class="res-time"]/text()').getall()[0]
# 职位名称
job_name = response.xpath('//div[@class="company-info"]/div[@class="name"]/h1/text()').get().strip()
# 学历要求
education = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/p/text()').getall()[2]
# 工作经验要求
experience = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/p/text()').getall()[1]
# 薪资
salary = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/div[2]/span/text()').get().strip()
# 招聘状态
state = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/div[1]/text()').get().strip()
# 职位描述
description = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div/text()').getall()
description = str(description)
# 员工福利
welfare = response.xpath('//*[@id="main"]/div[1]/div/div/div[2]/div[3]/div[2]/span/text()').getall()
welfare = str(welfare)
# 工作地址
address = response.xpath('//div[@class="job-location"]/div[@class="location-address"]/text()').get().strip()
item['dp_name']=dp_name
item['dp_type']=dp_type
item['dp_founded']=dp_founded
item['job_name']=job_name
item['education']=education
item['experience']=experience
item['salary']=salary
item['state']=state
item['description']=description
item['welfare']=welfare
item['address']=address
yield item
2.2 items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GetBossItem(scrapy.Item):
dp_name = scrapy.Field()
dp_type = scrapy.Field()
dp_founded = scrapy.Field()
job_name = scrapy.Field()
education = scrapy.Field()
experience = scrapy.Field()
salary = scrapy.Field()
state = scrapy.Field()
description = scrapy.Field()
welfare = scrapy.Field()
address = scrapy.Field()
2.3 middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
from scrapy import signals
import time
from scrapy.http.response.html import HtmlResponse
from get_boss.settings import IPPOOL
# 请求头
class GetBossDownloaderMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36'
]
class MyproxiesSpiderMiddleware(object):
def __init__(self,ip=''):
self.ip=ip
def process_request(self, request, spider):
thisip=random.choice(IPPOOL)
print("this is ip:"+thisip["ipaddr"])
request.meta["proxy"]="http://"+thisip["ipaddr"]
2.4 pipeline.py
# -*- coding: utf-8 -*-
import pymysql
import re
from scrapy.exporters import JsonLinesItemExporter
class GetBossPipeline(object):
# def __init__(self):
# self.fp = open('jobs.json','wb')
# self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii=False)
#
# def process_item(self, item, spider):
# self.exporter.export_item(item)
# return item
#
# def close_spider(self,spider):
# self.fp.close()
def table_exists(self,con,table_name):
sql = "show tables;" #第一次使用需要将数据表删除
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
def process_item(self, item, spider):
connect = pymysql.connect(
user = 'root',
password = 'root',
db = 'MYSQL',
host = '127.0.0.1',
port = 3306,
charset = 'utf8'
)
con = connect.cursor()
con.execute("use w_lagouwang")
table_name = 'zhipinwang' #这张表是用来测试所有数据的 并非关键词表
if(self.table_exists(con,table_name) != 1):
# con.execute("drop table if exists zhipinwang")
sql = '''create table zhipinwang(dp_name varchar(40),dp_type varchar(40),dp_founded varchar(20),
job_name varchar(40),education varchar(40),experience varchar(20),salary varchar(20),state varchar(10),
description varchar(800),welfare varchar(200),address varchar(100))'''
con.execute(sql)
data = {'dp_name':item['dp_name'],'dp_type':item['dp_type'],'dp_founded':item['dp_founded'],
'job_name':item['job_name'],'education':item['education'],'experience':item['experience'],
'salary':item['salary'],'state':item['state'],'description':item['description'],
'welfare':item['welfare'],'address':item['address']}
dp_name = data['dp_name']
dp_type = data['dp_type']
dp_founded = data['dp_founded']
job_name = data['job_name']
education = data['education']
experience = data['experience']
salary = data['salary']
state = data['state']
description = data['description']
welfare = data['welfare']
address = data['address']
con.execute('insert into zhipinwang(dp_name,dp_type,dp_founded,job_name,education,experience,salary,state,description,welfare,address)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)',
[dp_name,dp_type,dp_founded,job_name,education,experience,salary,state,description,welfare,address])
connect.commit()
con.close()
connect.close()
return data
2.5 seetings.py



![]()
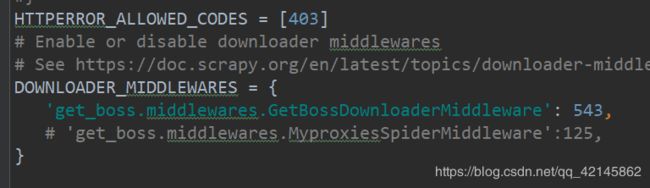

2.6 start.py
#encoding: utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl boss".split())
3. 踩到的坑
BOSS家的反爬,做的真是让人脑壳疼。。。
3.1 一步解决user-agent
最最最简单的解决user-agent的方法:全局设置(此方式设置后,覆盖掉scrapy默认的请求头,全局生效,即所有爬虫都可以享受 )
settings.py文件中找到如下代码:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'myspider (+http://www.yourdomain.com)'
解除注释,修改为自己的请求头:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
还想了解其他方法可以点击这里
3.2 写入数据库时遇到的问题
如职位描述:
# 职位描述
description = response.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div/text()').getall()
description = str(description)
向数据库中插入的是字符串且只能是一个字符串,而description返回的是一个字符串数组,数组不能直接插入到数据库中,所以要将该数组转换成一个字符串,否则将无法插入到数据库中。
3.3 控制并发请求数、下载延迟
#理论上一天是60/5 * 1 * 60 * 24 =17280条数据
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 5
3.4 Rule 的使用
强推,真的是太好用了,一句话解决了循环爬取页面
Rule是在定义抽取链接的规则:
class scrapy.contrib.spiders.
Rule
(link_extractor,callback=None,cb_kwargs=None,follow=None,process_links=None,process_request=None)
1、link_extractor 是一个Link Extractor对象。 是从response中提取链接的方式。在下面详细解释
follow是一个布尔值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback 为None,follow 默认设置为True,否则默认为False。
2、当follow为True时,爬虫会从获取的response中取出符合规则的url,再次进行爬取,如果这次爬取的response中还存在符合规则的url,则再次爬取,无限循环,直到不存在符合规则的url。
当follow为False是,爬虫只从start_urls 的response中取出符合规则的url,并请求。
3.5 设置代理池
免费的ip,别指望了…
3.6 scrapy shell
返回403:
1、在scrapy shell时加上请求头,如:
scrapy shell "https://movie.douban.com" -s USER_AGENT='Mozilla/5.0'
2、该网址不能直接访问,要先从上一级url中访问
3、我理解为网站的反爬
如:第一次访问直聘网页时,网址如下图所示
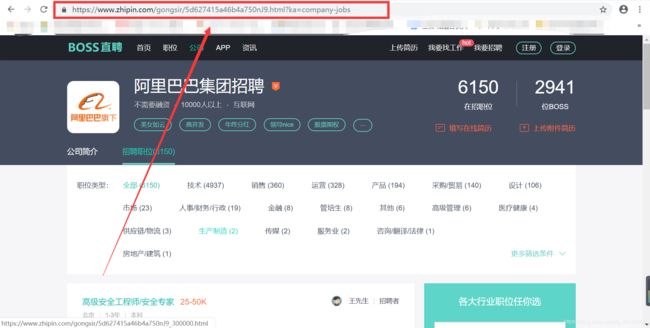
而当点击第二页之后再返回第一页时,网址就变了:
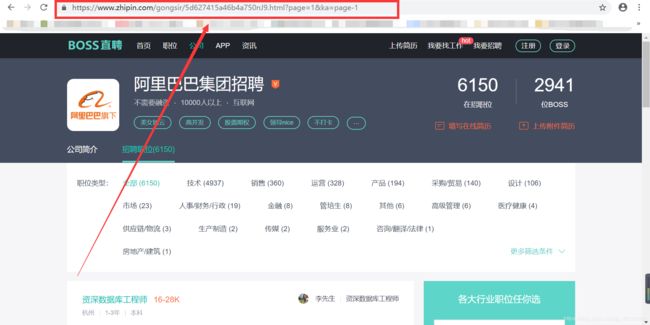
同样是第一页,但是在第一次访问和第二次访问时网址是不一样的,为了方便使用Rule规则,我选择使用第二次访问时的网址。
还有一个问题需要注意,如果此时直接请求第二次的网址,那么将会返回403。为什么呢。。我们把鼠标移动到页码上,发现,其实url是没有&ka=page-1的,当我们去点url中的&ka=page-1时,就可以正常请求url啦

4. 源码
https://download.csdn.net/download/qq_42145862/11349203