【隐匿撕源码】从方法中解剖HashMap(1.7详尽)
前面的话
这篇文章只针对hashMap
ConcurrentHashMap以后会补充 在本文中不会
本文需要你要知道一些HaspMap的基础知识 比如说是map是一个key value的键值对形式
以及底层是数组+链表的形式、Hash算法、位运算等前置知识
本文需要大量结合源码 所以我尽量会把文本内容放在源码里面以图片的方式进行讲解
此文会对1.7HashMap源码逐层剖析 做到最详细的HashMap解剖 此文会把1.7的HashMap所有方法一一详解
文章略长 欢迎和我一起在阅读源码的过程中寻找快乐 有疑问欢迎留言
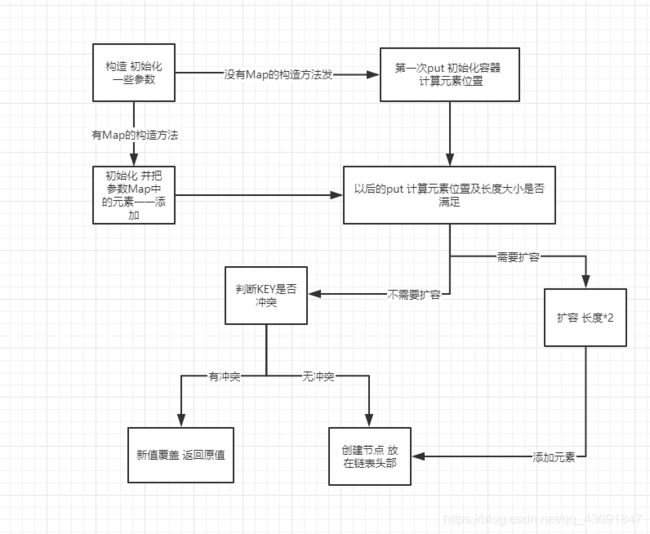
1.7HashMap
先搂一眼属性
带着翻译看官方
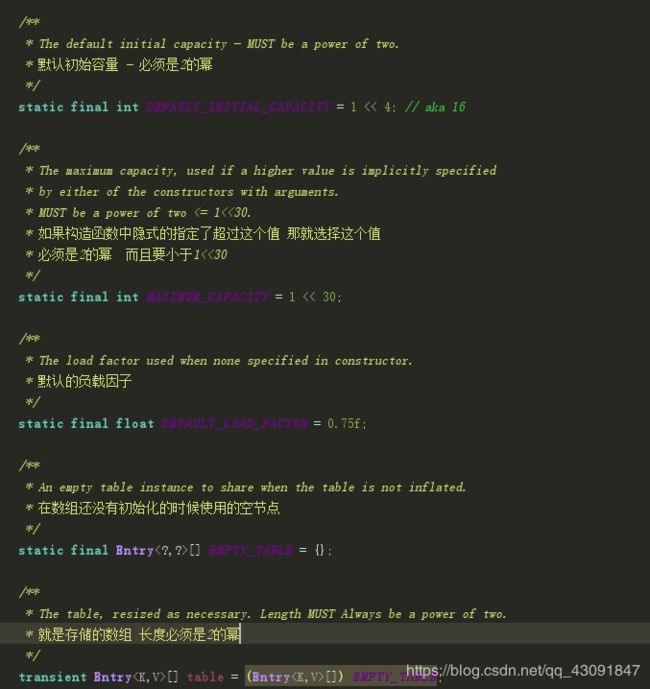
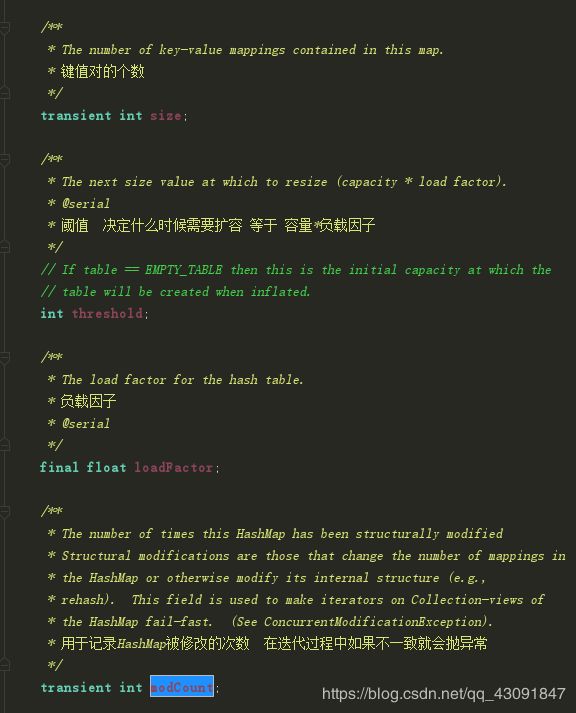
不要纠结这些属性是干嘛的 先有个了解 便于之后的内容
构造方法都干了什么事?
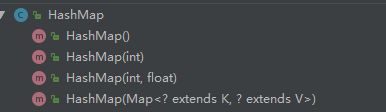
HaspMap的构造方法一共有4个
总的来说就是设置 负载因子 和table数组的容量 这里提一个有趣的地方
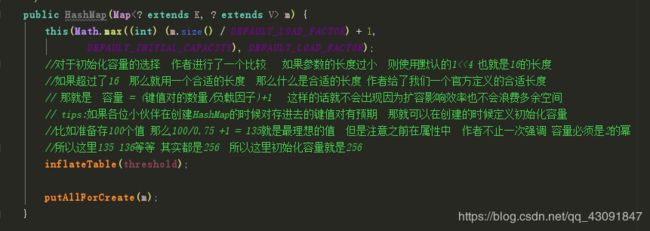

这里打一个断点输出一下table的length 看一看到底是多少
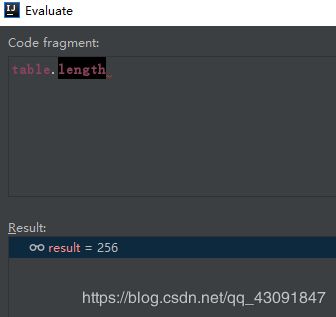
idea告诉我们是256 说明确实是这样 好的 我们继续往下走
前三个构造方法最终都会调用HashMap(int initialCapacity, float loadFactor) 这个构造方法

这里注意一个位置
![]()
他将初始化的容量赋值给了阈值 这是为什么?
卖个关子 : 最后一个构造方法HashMap(Map m)这里面有些内容我们需要在put中讲解 我们先看put再回来研究这个构造方法
带着这两个疑问我们进入put方法中一探究竟
put()流程概述
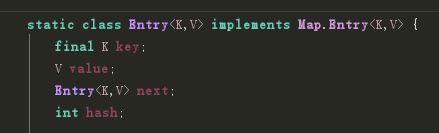
一个key、value对 在map中是以Entry的内部类形式存储的 一个Entry保存了4个属性
接下来我们正式进入 put方法的源码中

这就是一个put方法的全貌 我们逐行分析

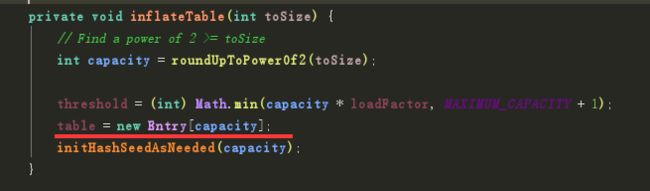
这就是初始化HashMap的方法 我们先看红线代码 这行代码初始化了一个Entry数组 这就是真正创建容器的一行代码 那这个capacity(容量具体是怎么得到的?)
这里进行了两个操作 分别如下:
接下来就是重头戏了! 本文叫 从方法中解剖HashMap,就是要详尽分析所有HashMap的方法,
那么 这个roundUpPowerOf2() 是怎么得到最小的2的幂呢 接下来就是解剖环节!
roundUpPowerOf2:HashMap位运算神论的开篇
不说废话 进入源码
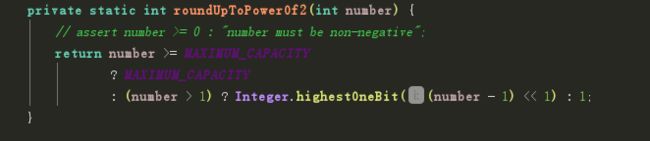
这里用三元运算符判断了大小 大于阈值用阈值 小于1用1
核心方法是这个Integer.highestOneBit((number - 1) << 1)
Integer.highestOneBit();
//这个方法是Integer 的方法 方法内容是可以的到小于等于参数的2的幂
因为这是Integer的方法 我另起一篇文章 详解这个方法是怎么得到小于等于参数的幂的
详解 Integer.highestOneBit()
这个方法是找到小于 参数的2的幂 但是我们要找到大于参数的2的幂 所以就是里面的参数
(number-1)<<1起的作用
比如我们要找大于等于10的 2的幂 对于这个方法 我们就要把10变大 变成多少呢?
变成大于16小于32的数 所以 -1 之后左移 就能达到这个目的 这个-1是为了防止这个数字正好是2的幂
所以先-1
这就是 roundUpPowerOf2()这个方法所有内容
至于为什么数组长度一定是2的幂次方数 后文会找到答案
数组初始化完成 我们继续回到put方法中
判空情况暂时略过
int hash = hash(key);
//这里使用用的是HashMap自己的hash算法
//不需要关心具体的算法 只需要知道所有的Object都可以计算成hash就可以了

在493行的位置 开始计算了一个Entry在数组中的位置
indexFor()

这个方法说明了为什么数组长度必须是2的幂次方数
首先 这个h 是计算出来的hash值 我们可以理解为是一个随机数
这个length是数组长度 为什么要-1呢?
因为他是2的幂 -1之后一定是 所有位上都是1
比如 16 0001 0000 -1之后是 0000 1111
这样和hash值进行&运算的时候 得到的结果一定是在数组之内
同时 这种方法可以提升hash值的一个散列型 就是分布的更均匀
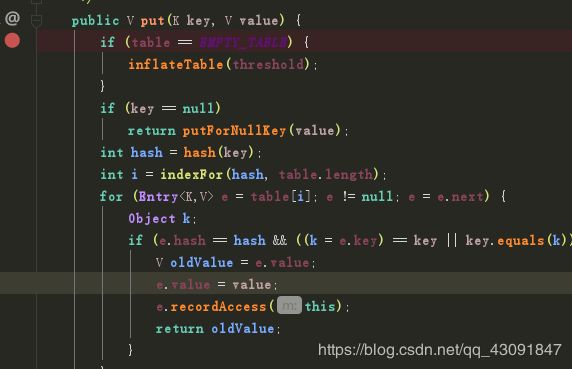
冲突替换
当我们通过indexFor()方法得到了数组位置之后 这个位置上应该是一个链表 接下来做的就是一个遍历的过程
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//这里判断如果key是相同的 那么就覆盖掉这个值 并且返回原值
V oldValue = e.value;
e.value = value;
e.recordAccess(this); //这个方法和init()一样 都是一个空方法
return oldValue;
}
}
一直到这里 我们都没有真正的把KEY和VALUE put到我们的集合中
接下来。。 就是真正put的地方了
万众期待的KV键值对终于要进入到我们的容器中了
modCount++;//这个是和并发有关的 暂时忽略
addEntry(hash, key, value, i); //真正添加元素的方法
return null;
真正添加的元素的方法 addEntry()
不对BB 源码走起
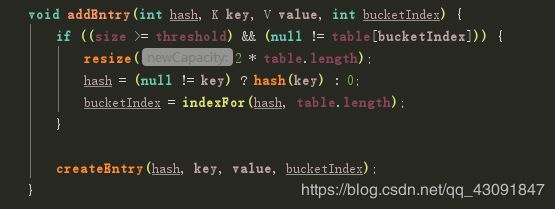
这里一共分为两步
第一步是判断长度大小 是否需要扩容
第二步时添加到指定位置中
扩容

阈值 = 容器长度*负载因子
扩容的长度是之前容器长度的2倍
进行的操作是判断长度是否超过了HashMap所能承受的最大长度
如果符合标准 就将老数组的内容移动到扩容之后的数组中
在转移的过程中 我们注意一个点
![]()
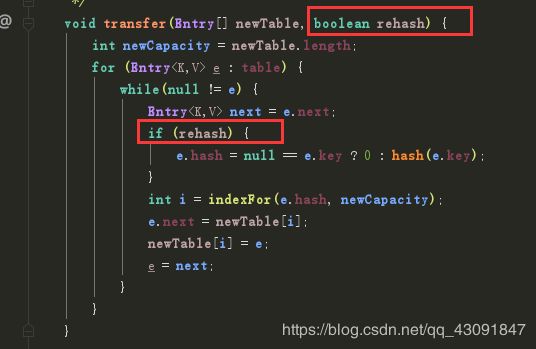
在这里 不是所有转移的元素都需要rehash的 rehash就是重新计算hash值
如果需要rehash 根据扩容之后的容量大小重新计算新数组中的哈希值和数组位置 添加进去
这个重新计算的hash值 只有两种情况 一个是位置不变 一个是 (原位置+扩容的长度)
举个例子: 原位置是3 原长度是8 那么新位置只有3 和11两种情况
目的就是把原来比较长的链表分散开来
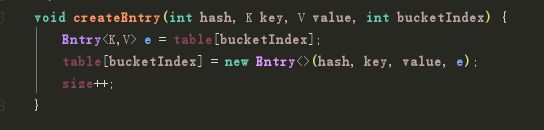
最后就是真正添加内容 就是把Entry放在了数组指定位置的头节点
把坑补上
前面我们在构造方法中留了一个没有看 现在把源码补上

在这里同样指定了 负载因子 容量大小等初始化数值 并且初始化了数组
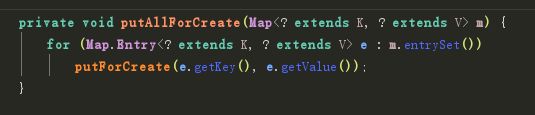
在这里遍历了参数Map 同时每个元素都添加到里面去
总结