Mysql常见的面试总结
第一题
CREATE TABLE `table1` (
`name` VARCHAR(20) DEFAULT NULL,
`kecheng` VARCHAR(20) DEFAULT NULL,
`fenshu` INT(10) DEFAULT NULL
);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('张三','语文',81);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('张三','数学',75);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('李四','语文',76);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('李四','数学',76);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('王五','语文',81);
INSERT INTO table1(NAME,kecheng,fenshu) VALUES('王五','数学',100);
#求出每门课都大于80分的学生姓名
第一种方法:
SELECT NAME FROM table1 GROUP BY NAME
HAVING MIN(fenshu)>80
第二种方法:
SELECT NAME FROM table1 GROUP BY NAME
HAVING COUNT(1)=SUM(CASE WHEN fenshu>80 THEN 1 ELSE 0 END)
第三种方法:
SELECT NAME FROM table1 GROUP BY NAME
HAVING NAME NOT IN (SELECT NAME FROM table1 WHERE fenshu<=80)
第二题
CREATE TABLE `table2` (
`语文` INT(10) DEFAULT NULL,
`数学` INT(10) DEFAULT NULL,
`英语` INT(10) DEFAULT NULL
);
INSERT INTO table2(语文,数学,英语) VALUES(58,70,80);
有一张表,3个字段是语文,数学,英语, 有1条记录分别表示语文68,数学70,英语80, 得出结果分数变等级(>=80分是优秀, >=60分是及格, <60是不及格)
SELECT CASE WHEN 语文>=80 THEN '优秀' WHEN 语文>=60 THEN '及格' WHEN 语文<60 THEN '不及格' END 语文,
CASE WHEN 数学>=80 THEN '优秀' WHEN 数学>=60 THEN '及格' WHEN 数学<60 THEN '不及格' END 数学,
CASE WHEN 英语>=80 THEN '优秀' WHEN 英语>=60 THEN '及格' WHEN 英语<60 THEN '不及格' END 英语
FROM table2
第三题
CREATE TABLE `table3` (
`date` VARCHAR(20) DEFAULT NULL,
`result` VARCHAR(10) DEFAULT NULL
)
#查询出来的结果:
#date 胜 负
#2011-02-01 2 1
#2011-02-02 1 1
SELECT DATE,
(SELECT COUNT(1) FROM table3 WHERE DATE=t.date AND result='胜') AS 胜,
(SELECT COUNT(1) FROM table3 WHERE DATE=t.date AND result='负') AS 负
FROM table3 t GROUP BY DATE
第四题
#1 2005001 张三 0001 数学 69
#2 2005002 李四 0001 数学 89
#3 2005001 张三 0001 数学 69
CREATE TABLE IF NOT EXISTS `student_test` (
id INT UNSIGNED AUTO_INCREMENT,
stu_id VARCHAR(10) NULL,
NAME VARCHAR(10) NULL,
couser_id VARCHAR(10) NULL,
couser VARCHAR(10) NULL,
score DECIMAL(10,2) NULL,
PRIMARY KEY (id)
)
INSERT INTO student_test(id,stu_id,NAME,couser_id,couser,score) VALUES(NULL,'2005001','张三','0001','数学',69);
INSERT INTO student_test(id,stu_id,NAME,couser_id,couser,score) VALUES(NULL,'2005002','李四','0001','数学',89);
INSERT INTO student_test(id,stu_id,NAME,couser_id,couser,score) VALUES(NULL,'2005001','张三','0001','数学',69);
#删除冗余字段, 保留ID最小的那个
DELETE FROM student_test WHERE id NOT IN (
SELECT * FROM (
SELECT MIN(id) FROM student_test GROUP BY stu_id,NAME,couser_id,couser,score
) s
)
第五题
CREATE TABLE IF NOT EXISTS `product` (
id INT UNSIGNED AUTO_INCREMENT,
NAME VARCHAR(10) NULL,
STATUS VARCHAR(10) NULL,
PRIMARY KEY (id)
)
INSERT INTO product(id,NAME,STATUS) VALUES(NULL,'苹果','好吃');
INSERT INTO product(id,NAME,STATUS) VALUES(NULL,'梨','难吃');
INSERT INTO product(id,NAME,STATUS) VALUES(NULL,'橘子','好吃');
INSERT INTO product(id,NAME,STATUS) VALUES(NULL,'葡萄',NULL);
#现在需要把status的‘好吃’更新为‘0’,‘难吃’更新为‘1’
UPDATE product SET STATUS=(CASE WHEN STATUS='好吃' THEN '0' WHEN STATUS='难吃' THEN '1' END)
1
第六题
1) 创建一张学生表,包含以下信息,学号,姓名,年龄,性别,家庭住址,联系电话
CREATE TABLE IF NOT EXISTS `t_student` (
stu_id INT UNSIGNED AUTO_INCREMENT,
NAME VARCHAR(10) NULL,
age INT NULL,
gender VARCHAR(2) NULL,
address VARCHAR(50) NULL,
phone VARCHAR(11) NULL,
PRIMARY KEY (stu_id)
);
#2) 修改学生表的结构,添加一列信息,学历
ALTER TABLE t_student ADD COLUMN `education` VARCHAR(20) NOT NULL;
#3) 修改学生表的结构,删除一列信息,家庭住址
ALTER TABLE t_student DROP COLUMN address;
#4) 向学生表添加如下信息:
INSERT INTO t_student(stu_id,NAME,age,gender,phone,education) VALUES(NULL,'A',22,'男','123456','小学');
INSERT INTO t_student(stu_id,NAME,age,gender,phone,education) VALUES(NULL,'B',21,'男','119','中学');
INSERT INTO t_student(stu_id,NAME,age,gender,phone,education) VALUES(NULL,'C',23,'男','110','高中');
INSERT INTO t_student(stu_id,NAME,age,gender,phone,education) VALUES(NULL,'D',18,'女','114','大学');
#5) 修改学生表的数据,将电话号码以11开头的学员的学历改为“大专”
UPDATE t_student SET education='大专' WHERE phone LIKE '11%';
#6) 删除学生表的数据,姓名以C开头,性别为‘男’的记录删除
DELETE FROM t_student WHERE NAME LIKE 'C%' AND gender='男';
#7) 查询学生表的数据,将所有年龄小于22岁的,学历为“大专”的,学生的姓名和学号示出来
SELECT stu_id,NAME FROM t_student WHERE age<22 AND education='大专'
#8) 查询学生表的数据,查询所有信息,列出前25%的记录
SELECT * FROM t_student WHERE stu_id<=(SELECT COUNT(*) FROM t_student)*0.25;
#9) 查询出所有学生的姓名,性别,年龄降序排列
SELECT NAME,gender,age FROM t_student ORDER BY age DESC;
#10) 按照性别分组查询所有的平均年龄
SELECT gender,AVG(age) FROM t_student GROUP BY gender;
第七题
CREATE TABLE IF NOT EXISTS test1(
a DECIMAL(10,2) NOT NULL,
b DECIMAL(10,2) NOT NULL,
c DECIMAL(10,2) NOT NULL,
d VARCHAR(10) NOT NULL
)
INSERT INTO test1(a,b,c,d) VALUES(0.5,1.5,2.0,'A1');
INSERT INTO test1(a,b,c,d) VALUES(1.5,0.5,0.5,'A1');
INSERT INTO test1(a,b,c,d) VALUES(0.5,0.5,1.5,'A1');
INSERT INTO test1(a,b,c,d) VALUES(1.5,1.5,1.5,'B1');
INSERT INTO test1(a,b,c,d) VALUES(0.5,2.0,2.0,'B1');
INSERT INTO test1(a,b,c,d) VALUES(1.5,2.0,0.5,'B1');
统计a,b,c三列大于1的个数
SELECT
SUM(CASE WHEN a > 1 THEN 1 ELSE 0 END) a,
SUM(CASE WHEN b > 1 THEN 1 ELSE 0 END) b,
SUM(CASE WHEN c > 1 THEN 1 ELSE 0 END) c
FROM test1;
按a分组, 用b排序取top1
其实用hive或者Oracle很简单了, 直接用row_number即可
方法一
SELECT test1.*
FROM test1
JOIN (SELECT a,MAX(b) maxb FROM test1 GROUP BY a) t
ON test1.b=t.maxb
GROUP BY a
方法二
SELECT a, SUBSTRING_INDEX(GROUP_CONCAT(b ORDER BY b DESC),',',1) b,
SUBSTRING_INDEX(GROUP_CONCAT(c ORDER BY b DESC),',',1) c,
SUBSTRING_INDEX(GROUP_CONCAT(d ORDER BY b DESC),',',1) d
FROM test1 GROUP BY a;
用到了下面的两个函数:
group_concat(v)
先看看它的语法:
group_concat([DISTINCT] 要连接的字段 [ORDER BY ASC/DESC 排序字段] [SEPARATOR
‘分隔符’])
举例:
select GROUP_CONCAT(c ORDER BY b DESC) from test1 group a
#解析: 按a进行分组, 把c字段的值打印在一起, 逗号分割(默认), 并且c字段按b排序
substring_index(v1, v2, v3) – 将v1按照v2进行分割取下标为v3的值
从表中随机取出3条数据
下面这种方法虽然可以取出随机记录, 但是不推荐, 数据量大的话会很慢很慢
SELECT * FROM test1 ORDER BY RAND() LIMIT 3
可以使用下面这种方法
SELECT *
FROM (SELECT test1.*, RAND() r FROM test1) t
ORDER BY t.r LIMIT 3
第八题
Table表有三个字段ID,Name,Location, 请以两种方式写出SQL语句删除表中ID以及Name都重复的记录.
CREATE TABLE table4(
ID INT NOT NULL,
NAME VARCHAR(10) NOT NULL,
Location VARCHAR(12) NOT NULL
);
INSERT INTO table4(ID,NAME,Location) VALUES(1,'zhangsan','bj');
INSERT INTO table4(ID,NAME,Location) VALUES(1,'zhangsan','bj');
INSERT INTO table4(ID,NAME,Location) VALUES(2,'lisi','bj');
INSERT INTO table4(ID,NAME,Location) VALUES(3,'wangwu','sh');
第一种方法
DELETE FROM table4 WHERE (id,NAME) IN (
SELECT * FROM (SELECT id,NAME FROM table4 GROUP BY ID,NAME HAVING COUNT(1)>1) t)
第二种方法
DELETE FROM table4 WHERE (id,NAME) IN (
SELECT * FROM(
SELECT id,NAME FROM table4 t1 WHERE (
(SELECT COUNT(1) FROM table4 t2 WHERE t1.ID=t2.ID AND t1.Name=t2.Name)>1
)
) tmp)
第九题
现有BOOKS表, 查询所有图书中价格小于60元的作者有多少本图书在售
CREATE TABLE books(
bno INT NOT NULL,
bname VARCHAR(10) NOT NULL,
author VARCHAR(10) NOT NULL,
price DECIMAL(10,2) NOT NULL
)
INSERT INTO books VALUES(1,'倚天屠龙记','金庸',12.99);
INSERT INTO books VALUES(2,'雪山飞狐','金庸',64.99);
INSERT INTO books VALUES(3,'东方不败','金庸',12.99);
INSERT INTO books VALUES(4,'仙逆','耳根',72.99);
INSERT INTO books VALUES(5,'求魔','耳根',12.99);
答案:
使用子查询查出图书价格小于60的作者有哪些, 然后按照作者分组, 查询这些作者的图书数量.
SELECT author,COUNT(1) FROM books GROUP BY author HAVING author IN
(SELECT DISTINCT(author) FROM books WHERE price<60)
第十题
表中有A,B,C三列, 用SQL语句实现, 依次取A,B,C中第一个不为空的值
CREATE TABLE table_null(
A VARCHAR(10),
B VARCHAR(10),
C VARCHAR(10)
)
INSERT INTO table_null VALUES(NULL,NULL,NULL);
INSERT INTO table_null VALUES('abc',NULL,NULL);
INSERT INTO table_null VALUES(NULL,'ccc',NULL);
INSERT INTO table_null VALUES(NULL,NULL,'ddd');
答案:
分别按照每一个字段分组, 所有为NUll的分为一组, 然后取不为null的第一条即可.
SELECT * FROM
(SELECT A FROM table_null GROUP BY A LIMIT 1,1) t1 JOIN
(SELECT B FROM table_null GROUP BY B LIMIT 1,1) t2 JOIN
(SELECT C FROM table_null GROUP BY C LIMIT 1,1) t3
第十一题
有一张表stu_score, 所有课程都>=90则特优, 所有课程都>=80则优秀, 都>=60则及格, 否则挂科.
CREATE TABLE stu_score(
kecheng VARCHAR(10),
stu_id INT,
score INT
)
INSERT INTO stu_score VALUES('001',1,90);
INSERT INTO stu_score VALUES('002',1,92);
INSERT INTO stu_score VALUES('001',2,80);
INSERT INTO stu_score VALUES('002',2,92);
INSERT INTO stu_score VALUES('001',3,76);
INSERT INTO stu_score VALUES('002',3,92);
INSERT INTO stu_score VALUES('001',4,50);
INSERT INTO stu_score VALUES('002',4,92);
答案:
按照学号分组, 使用 CASE WHEN 判断最小分数 MIN(score) 是否满足条件.
SELECT
stu_id, (CASE WHEN MIN(score)>=90 THEN '特优' WHEN MIN(score)>=80 THEN '优秀' WHEN MIN(score)>=60 THEN '及格' ELSE '挂科' END) stat
FROM stu_score GROUP BY stu_id
第十二题
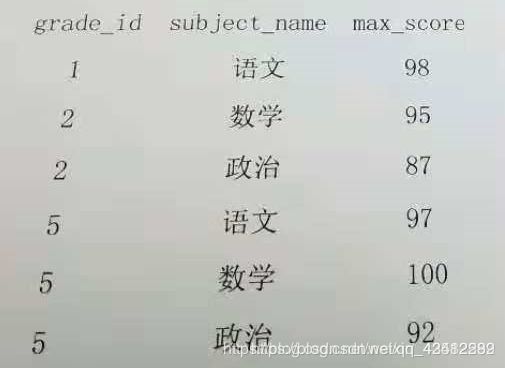
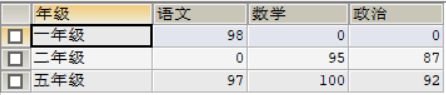
运用SQL实现数据转换
转换前:
转换后:
CREATE TABLE test33(
grade_id INT,
subject_name VARCHAR(10),
max_score INT
)
INSERT INTO test33 VALUES(1,'语文',98);
INSERT INTO test33 VALUES(2,'数学',95);
INSERT INTO test33 VALUES(2,'政治',87);
INSERT INTO test33 VALUES(5,'语文',97);
INSERT INTO test33 VALUES(5,'数学',100);
INSERT INTO test33 VALUES(5,'政治',92);
答案:
SELECT 年级,
SUM(CASE WHEN 语文 IS NULL THEN 0 ELSE 语文 END) 语文,
SUM(CASE WHEN 数学 IS NULL THEN 0 ELSE 数学 END) 数学,
SUM(CASE WHEN 政治 IS NULL THEN 0 ELSE 政治 END) 政治
FROM
(
(SELECT
(CASE grade_id WHEN 1 THEN '一年级' WHEN 2 THEN '二年级' WHEN 5 THEN '五年级' END) 年级,
(CASE subject_name WHEN '语文' THEN max_score ELSE NULL END) 语文,
(CASE subject_name WHEN '数学' THEN max_score ELSE NULL END) 数学,
(CASE subject_name WHEN '政治' THEN max_score ELSE NULL END) 政治
FROM test33
) UNION (
SELECT
(CASE grade_id WHEN 1 THEN '一年级' WHEN 2 THEN '二年级' WHEN 5 THEN '五年级' END) 年级,
(CASE subject_name WHEN '语文' THEN max_score ELSE NULL END) 语文,
(CASE subject_name WHEN '数学' THEN max_score ELSE NULL END) 数学,
(CASE subject_name WHEN '政治' THEN max_score ELSE NULL END) 政治
FROM test33
) UNION (
SELECT
(CASE grade_id WHEN 1 THEN '一年级' WHEN 2 THEN '二年级' WHEN 5 THEN '五年级' END) 年级,
(CASE subject_name WHEN '语文' THEN max_score ELSE NULL END) 语文,
(CASE subject_name WHEN '数学' THEN max_score ELSE NULL END) 数学,
(CASE subject_name WHEN '政治' THEN max_score ELSE NULL END) 政治
FROM test33
)
) t1 GROUP BY 年级
第十三题
A表与B表结构相同, 现在想用B表的数据更新A表的用户姓名, 存在就更新, 不存在就添加.
表A
CREATE TABLE A(
user_id VARCHAR(10),
user_name VARCHAR(20)
)
CREATE TABLE B(
user_id VARCHAR(10),
user_name VARCHAR(20)
)
答案:
mysql有这样的语法: ON DUPLICATE KEY UPDATE 对唯一索引或主键索引可以实现更新.
#给B表添加唯一索引
ALTER TABLE B ADD UNIQUE KEY user_name(user_name)
#存在相同的user_name就执行UPDATE
INSERT INTO B (user_id,user_name) SELECT user_id,user_name FROM A
ON DUPLICATE KEY UPDATE user_id=VALUES(user_id),user_name=VALUES(user_name)
下面列几个常见的Hive必考HQL
#1. 级联求和问题 #######################
select a.username, a.month, max(a.salSum), sum(b.salSum) as salSum
from
(select username, month, sum(salary) as salSum from t_salary_detail group by username,month) a
join
(select username, month, sum(salary) as salSum from t_salary_detail group by username,month) b
on a.username=b.username
where a.month>=b.month
group by a.username,a.month;
#2. 连续3个月都有销售额的商家 #######################
select shopid,count(flag) as cnt
from
(select shopid,dt,sale,rn,date_sub(to_date(dt),rn) as flag
from
(select shopid,dt,sale,
row_number() over(partition by shopid order by dt) as rn
from t_jd
) tmp
) tmp2
group by shopid,flag having cnt>=3
#3. 求TOPN问题 #######################
--统计每日最热门页面的top10
select month,day,request,request_count, od
from
(select
month,day,request,request_count,
row_number() over(distribute by concat(month,day) sort by request_count desc) as od
from
(select month,day,request,count(1) as request_count
from ods_weblog_detail
where datestr='20130918'
group by request,month,day having request is not null
) b
) c where od<=10
#4. 行转列, 列转行问题 #######################
–当前有用户人生阶段表lifeStage, 有用户唯一ID字段uid,用户人生阶段字段stage,其中stage字段内容为各个人生阶段标签按照英文逗号分割的拼接内容,
–如:计划买车,已买房, 并且每个用户的内容不同, 请使用hive sql统计每个人生阶段的用户量.
–考察点: lateral view使用, explode函数
select stage_someone,count(distinct uid) as uids
from lifeStage
lateral view explode(split(stage,',')) lifeStage_tmp as stage_someone
group by stage_someone;
–和上一题相同的数据场景, 但是lifeStage中每行数据存储一个用户的人生阶段数据
–如: 一行数据uid是43, stage内容为计划买车, 另一行数据uid字段为43,stage字段为已买房, 请输出类似于uid为43,stage字段为计划买车,已买房这样的新整合数据.
–考察点: collect_set函数, concat_ws函数
select uid,concat_ws(',',collect_set(stage_someone)) as stage
from lifestage_multline
group by uid
#5. 多表关联的基础上, 行转列与列转行问题 #######################
–权限组表(g)中记录了组id和组名称,用户表(u)记录了用户id和用户名称,权限表(gu)是权限组表和用户表的关系,记录了每一个权限组与用户的对应关系
–题目是根据gt和ut表将gu表中的所有id转换为名称
create table gu_trans as
select t.gname as gname,concat_ws(',',collect_set(t.uname)) as uname
from
(select g.gname,u.uname
from
(select gid,s_uid
from gu lateral view explode(split(uid,',')) b as s_uid) tmp
join g on tmp.gid=g.gid
join u on tmp.s_uid=u.uid
) t
group by t.gname