摘要
本文主要是笔者第一次接触kaggle入门竞赛的一次记录,整个过程是通过jupyter notebook实现的。第一次接触这类比赛,过程中参考了很多大佬的文章学习,在此尽自己所能记录一下学习过程与总结,有什么理解错误的地方望大家指出,感谢!
可能需要的参考链接:
jupyter notebook的搭建
10分钟python seaborn绘图入门 (Ⅱ): barplot 与 countplot
为什么要用交叉验证
代码和数据:
码云
正文
我打算分这几步走:
- 数据准备:在这一部分,对数据做一个初步的认识,首先,结合统计学知识以及用seaborn简单的绘图,挖取与生还率相关性较大的特征。再者,参考各路大神的经验,添一些比较合理简单的新特征。
- 数据清洗:先对数据进行简单的处理,便于先选取一个效果好的基准模型,因为听说“应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高”,那就这样办吧。
- 基准模型:把清洗过的数据先套入3个基本的算法:线性回归、逻辑回归、随机森林,并通过交叉验证看看哪个比较合适。
- 特征工程: 我的理解就是在这个步骤要去创造一些额外的特征,来提高模型预测的准确率。这个步骤感觉上十分耗时,但也是整个项目的灵魂。
- 融合模型: 这里我只尝试把逻辑回归模型以及随机森林模型融合起来,其他的还是不太懂,学会了再添。
1 数据准备
1.1 在kaggle平台上把数据download下来:https://www.kaggle.com/c/titanic
1.2 导入数据包与数据集
# 引入需要用的库
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
#导入数据
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train.head()#看看数据前5行,大概了解一下情况
我们可以看到每一行数据拥有12个属性:

对于每一个变量,它们的含义如下:
PassengerId:乘客ID
Survived:是否获救
Pclass:乘客社会地位,1为Upper,2为Middle,3是Lower
Name:乘客姓名
Sex:性别
Age:年龄
SibSp:堂兄弟妹个数
Parch:父母与小孩个数
Ticket:船票信息
Fare:票价
Cabin:客舱
Embarked:登船港口
1.3数据初认识
一起看看这些数据的基本信息:
train.info()
--------------------------------------------------
output:
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
----------------------------------------------------
test.info()
----------------------------------------------------
output:
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
可以发现
- Cabin> Age> Embarked 在training set上包含空值。
- Cabin > Age 在test set上是不完整的
还有各个特征的数据类型,如训练集上2个float,5个int,5个object,都是要注意一下的,为后面的数据清洗、特征工程等做准备。
再来看看详细点的描述,看看能不能知道更多信息
train.describe()

从输出的表格,可以知道:
- 实际乘客人数(891)是总样本泰坦尼克号(2,224)上的40%。
- 约38%的样本存活。
- 大多数乘客(> 75%)没有与父母或孩子一起旅行。
- 近70%的乘客没有带上兄弟姐妹和/或配偶。
- 票价差异很大,最高票价高达512美元,但大部分乘客票价都不高。
- 老年乘客很少,大部分都是年轻人。
1.4数据初步探索(统计学与绘图)
现在开始使用统计学与绘图,目的是初步了解数据之间的相关性,为构造特征工程以及模型建立做准备。
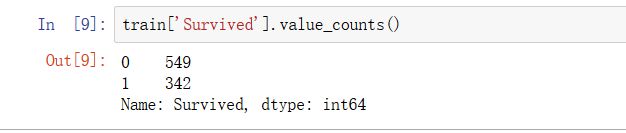
首先,我们了解一下死亡人数和生存人数是549:342
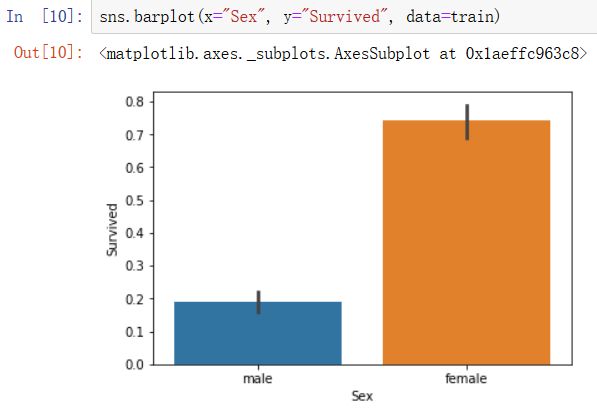
1)对于性别这一特性,我们通过电影知道是女士先行,男士断后的,因此猜测女性的存活率应该比男性高,在训练集中也是如此:
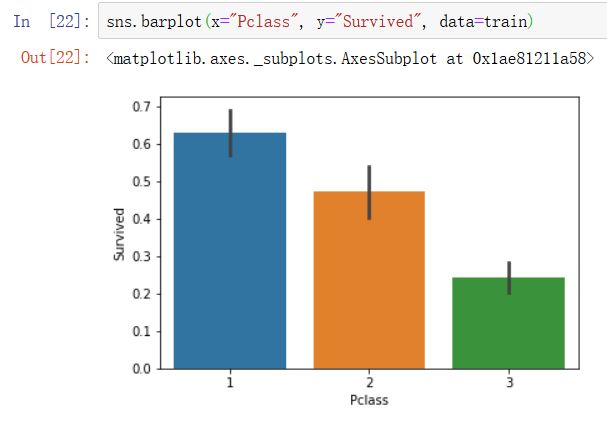
2)乘客的社会阶级,也与其是否生还有着很大的相关性,这也说明了即使在如此特殊的情况下,Power和Money依然尽责地发挥它们的作用。
- 有一定的配偶或/和兄弟姐妹在船上困难时互相帮助,能提高生还率,但太多的话反而降低生还率。

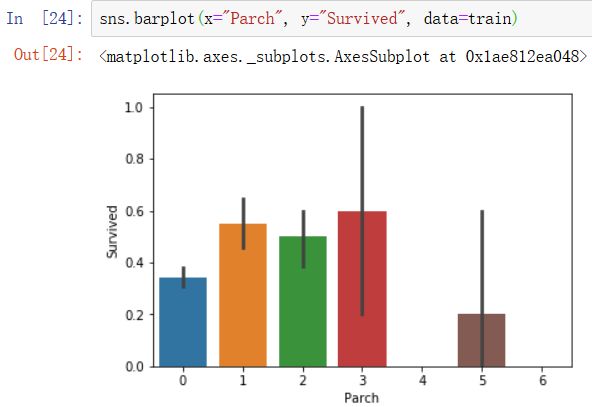
4)同理,父母儿子在船上的数量也是适中的人生存率才大,这两个特征类似可以拼在一起组成一个family size的特征,这是乘客在船上通过亲情友情,而不是金钱权利带来的生存率的提升的特征。
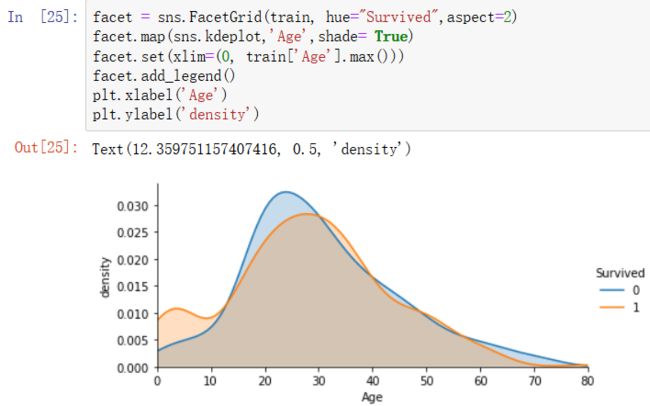
5)从年龄不同导致的不同生还情况的密度图可以看出,在年龄15岁的左侧,生还率有明显差别,密度图非交叉区域面积非常大,但在其他年龄段,则差别不是很明显,因此可以考虑将此年龄偏小的区域分离出来。
简单的理解:孩子在电影中也是先走的人群,暂定15岁以下为孩子的判定标准
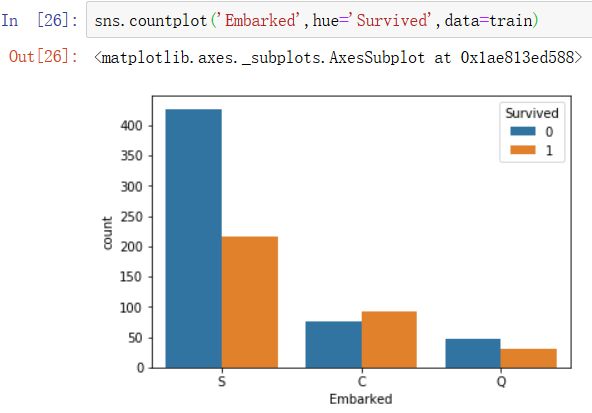
6)若是乘客在C港口登船的话,生存率会更高。有没可能是C港口是比较发达的贵族区域呢?登船的都是社会高级人士(生存率高的人)?
2 数据清洗
很多机器学习算法为了训练模型,要求所传入的特征中不能有空值。缺失值处理的方式通常有以下几种:
1.如果是数值类型,用平均值或中位数取代
2.如果是分类数据,用最常见的类别取代
3,使用模型预测缺失值,例如:K-NN
对于Age,我们这里使用中位数去填补缺失值
[input]
age_median = train['Age'].median() # 中位数
train.loc[train['Age'].isnull(),'Age'] = age_median #把所有的空值换成中位数
train.info()#看看情况怎么样
[output]
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
ok,这样Age就没有缺失值了。
对于字符串的数据,我们可以把他们进行替换,换成数字:
[input]
# 把机器学习不能处理的字符值转换成机器学习可以处理的数值
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
# 通过统计三个登船地点人数最多的填充缺失值
train["Embarked"] = train["Embarked"].fillna("S")
# 字符处理
train.loc[train["Embarked"] == "S", "Embarked"] = 0
train.loc[train["Embarked"] == "C", "Embarked"] = 1
train.loc[train["Embarked"] == "Q", "Embarked"] = 2
train.info()
[output]
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null int64
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 891 non-null int64
dtypes: float64(2), int64(7), object(3)
memory usage: 83.6+ KB
就剩下一个Cabin了,但是他实在是太少了我等下可能不打算用到它,先不动了。
3基准模型
将处理好的特征,用交叉验证分成11组,每次抽10组做训练集,剩下一组做测试集。
它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型,这么做可以在一定程度上减小过拟合。
3.1 线性回归模型
# 选择清洗过的特征
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# 将m个样本平均分成11份进行交叉验证
kf = KFold(n_splits=11,random_state=1)
#导入线性回归
alg = LinearRegression()
predictions = []
for train_L, test_L in kf.split(train):
#train_predictors选取训练用的特征
train_predictors = (train[predictors].iloc[train_L, :])
# train_target选取了目标特征,这里是Survived
train_target = train["Survived"].iloc[train_L]
# 丢进线性回归模型进行训练
alg.fit(train_predictors, train_target)
# 用剩下的一份数据作为测试集进行预测
test_predictions = alg.predict(train[predictors].iloc[test_L, :])
predictions.append(test_predictions)
# 使用线性回归得到的结果是在区间[0,1]上的某个值,需要将该值转换成0或1
predictions = np.concatenate(predictions, axis=0)
predictions[predictions > .5] = 1
predictions[predictions <= .5] = 0
# 查看模型准确率
accuracy = sum(predictions == train["Survived"]) / len(predictions)
print(accuracy)
[output]
0.7934904601571269
大概接近百分之80的准确率。
3.2 逻辑回归模型
因为本来就是二分类问题,所以逻辑回归比线性回归更合适,代码更简洁
from sklearn.model_selection import cross_val_score
#导入逻辑回归模型
alg = LogisticRegression(random_state=1)
# 交叉验证
scores = cross_val_score(alg, train[predictors], train["Survived"], cv=11)
# 取scores的平均值
print(scores.mean())
[output]
0.8002744244614163
sklearn.model_selection.cross_val_score()函数学习
3.3 随机森林
#导入随机森林模型
alg = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
kf = KFold(n_splits=11,random_state=1)
# 交叉验证
scores = cross_val_score(alg, train[predictors], train["Survived"], cv=kf)
print(scores.mean())
[output]
0.8170594837261503
4 特征工程
1)仔细看一下Name这个字段,发现每个人的称呼都是在第一个逗号后,到第一个句号前,利用这一点把每个人的称呼提取出来:
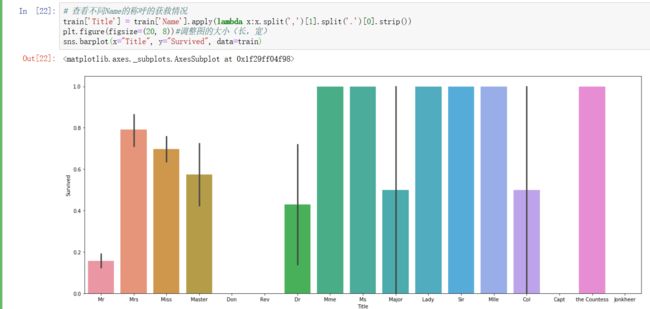
咱们再给它们归一个类:
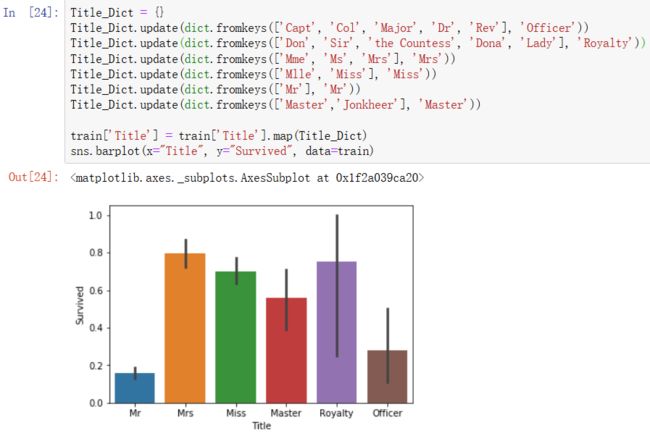
2)来把之前的兄弟姐妹父母儿子(SibSp+Parch)加起来组成一个FamilySize,FamilySize=Parch+SibSp+1:
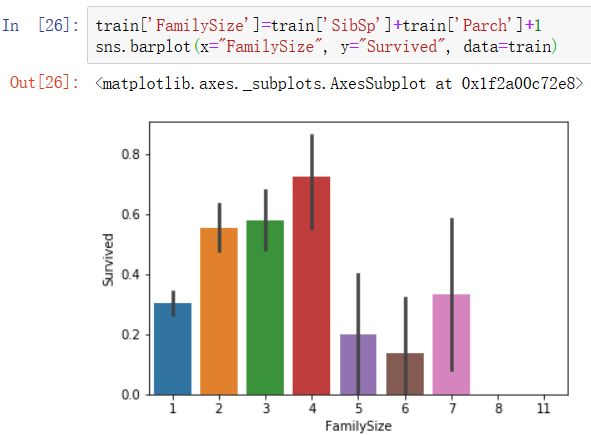
按生存率把FamilySize分为三类,0代表了超低生存率,1代表中等生存率,2代表了较高生存率,由此构成FamilyLabel特征。

3)不同甲板的乘客幸存率不同
新增Deck_Group特征,一个Deck由很多个Cabin组成。由于Cabin存在大量缺失值,先用'Unknown'填充一下吧,再提取Cabin中的首字母构成乘客的甲板号。
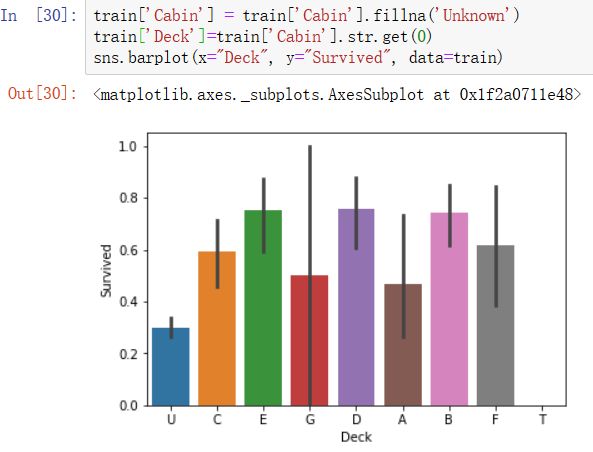
- 神奇的发现Cabin缺失的朋友们在这场灾难中更加难以存活
- 不同船舱距离救生船附近的距离不同,可能导致离得近的或者高级舱存活率高
给他们分一个组吧:
 Deck_Group
Deck_Group
4)新增TicketGroup特征,统计每个乘客的共票号数。
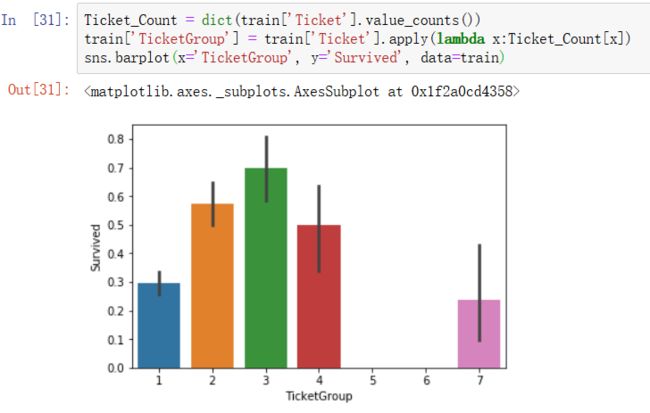
- 与2至4人共票号的乘客幸存率较高
- 与FamilySize一样操作,构建一个TicketGroup特征
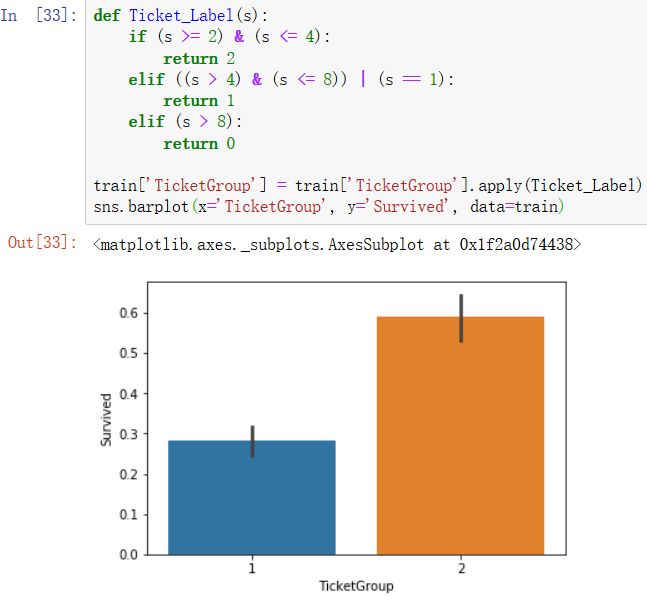
看看每个特征对生存率的相关性大小:
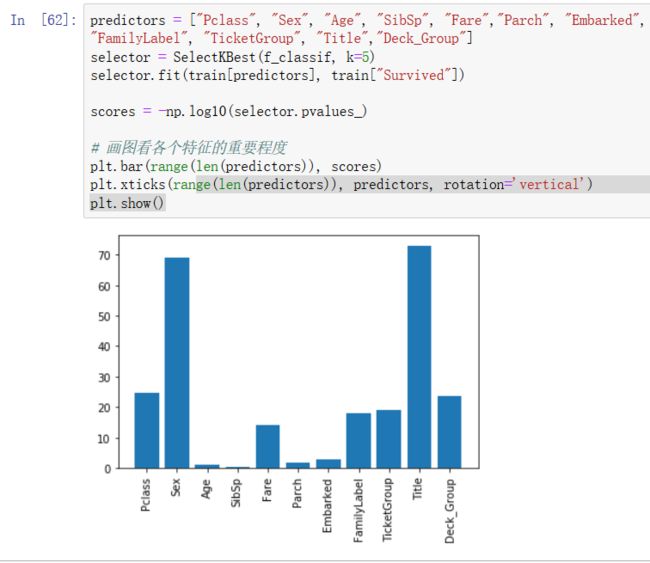
可以看到最重要的除了众所周知的Sex,还有称谓Title;较为重要的是阶级,票价,家庭规模,票号相同数以及甲板号的不同,有一些也是比较出乎意料的
用这些我们要用来训练的特征再跑一次随机森林模型:
predictors = ["Pclass", "Sex", "Age", "SibSp", "Fare","Parch", "Embarked",
"FamilyLabel", "TicketGroup", "Title","Deck_Group"]
alg = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
kf = KFold(n_splits=9,random_state=1)
scores = cross_val_score(alg, train[predictors], train["Survived"], cv=kf)
print(scores.mean())
[output]
0.8305274971941637
准确率达到了百分之83,较之前有所提升
5 融合模型
模型融合就是训练多个模型,然后按照一定的方法集成过个模型,因为它容易理解、实现也简单,同时效果也很好,在工业界的很多应用,kaggle比赛中也经常拿来做模型集成。
algorithms = [
[RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt'),
['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilyLabel', 'TicketGroup', 'Title','Deck_Group']],
[LogisticRegression(random_state=1),
['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked', 'FamilyLabel', 'TicketGroup', 'Title','Deck_Group']]
]
kf = KFold(n_splits=9,random_state=1)
predictions = []
for train_L, test_L in kf.split(train):
train_target = train['Survived'].iloc[train_L]
full_test_predictions = []
for alg, predictors in algorithms:
alg.fit(train[predictors].iloc[train_L, :], train_target)
test_prediction = alg.predict_proba(train[predictors].iloc[test_L, :].astype(float))[:, 1]
full_test_predictions.append(test_prediction)
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
test_predictions[test_predictions > .5] = 1
test_predictions[test_predictions <= .5] = 0
predictions.append(test_predictions)
predictions = np.concatenate(predictions, axis=0)
accuracy = sum(predictions == train['Survived']) / len(predictions)
print(accuracy)
[output]
0.8529741863075196
融合之后准确率提高到了百分之85,挺意外的。