【Hive】06-HiveQL:查询
1、SELECT FROM语句
1.1、使用正则表达式来指定列
我们甚至可以使用正则表达式来选择我们想要的列。下面的查询将会从表stocks中选择symbol列和所有列名以price作为前缀的列:
SELECT symbol ,`price.*` FROM stocks;1.2、使用列值进行计算
用户不但可以选择表中的列,还可以使用函数调用和算术表达式来操作列值。例如,我们可以查询得到转换为大写的雇员姓名、雇员对应的薪水、需要缴纳的联邦税收比例以及扣除税收后再进行取整所得的税后薪资。我们甚至可以通过调用内置函数map_values提取出deductions字段map类型值的所有元素,然后使用内置的sum函数对map中所有元素进行求和运算。
SELECT upper(name),salary.deductions["FederaI Taxes"),round(salary*(1-deductions["Federal Taxes"])) FROM employees;1.3、算术运算符
Hive中支持所有典型的算术运算符。
算术运算符接受任意的数值类型。不过,如果数据类型不同,那么两种类型中值范围较小的那个数据类型将转换为其他范围更广的数据类型。(范围更广在某种意义上就是指一个类型具有更多的字节从而可以容纳更大范围的值。)例如,对于INT和BIGINT运算,INT会将类型转换提升为BIGINT。对于INT和FLOAT运算,INT将提升为FLOAT。可以注意到我们的查询语句中包含有(1-deductions[...])这个运算。因为字段deductions是FLOAT类型的,因此数字1会提升为FLOAT类型。
当进行算术运算时,用户需要注意数据溢出或数据下溢问题。Hive遵循的是底层Java中数据类型的规则,因此当溢出或下溢发生时计算结果不会自动转换为更广泛的数据类型。乘法和除法最有可能会引发这个问题。
用户需要注意所使用的数值数据的数值范围,并确认实际数据是否接近表模式中定义的数据类型所规定的数值范围上限或者下限,还需要确认人们可能对这些数据进行什么类型的计算。
如果用户比较担心溢出和下溢,那么可以考虑在表模式中定义使用范围更广的数据类型。不过这样做的缺点是每个数据值会占用更多额外的内存。
用户也可以使用特定的表达式将值转换为范围更广的数据类型。
有时使用函数将数据值按比例从一个范围缩放到另一个范围也是很有用的,例如按照10次方幂进行除法运算或取log值(指数值),等等。这种数据缩放也适用于某些机器学习计算中,用以提高算法的准确性和数值稳定性。
1.4、使用函数
我们前面的那个示例中还使用到了一个内置数学函数round(),这个函数会返回一个DOUBLE类型的最近整数。
1.4.1、数学函数
需要注意的是函数floor、round和ceil〈“向上取整")输人的是DOUBLE类型的
值,而返回值是BIGINT类型的,也就是将浮点型数转换成整型了。在进行数据类
型转换时,这些函数是首选的处理方式,而不是使用前面我们提到过的cast类型转
换操作符。
同样地,也存在基于不同的底(例如十六进制)将整数转换为字符串的函数。
1.4.2、聚合函数
聚合函数是一类比较特殊的函数,其可以对多行进行一些计算,然后得到一个结果值。
这类函数中最有名的两个例子就是count和avg。函数用于计算有多少行数据(或者某列有多少值),而函数avg可以返回指定列的平均值。
通常,可以通过设置属性hive.map.aggr值为true来提高聚合的性能,如下所示:
hive>SET hive.map.aggr=true;
hive>SELECT count(*),avg(salary) FROM employees;正如这个例子所展示的,这个设置会触发在map阶段进行的“顶级”聚合过程。(非顶级的聚合过程将会在执行一个GROBY后进行。)不过,这个设置将需要更多的内存。
多个函数都可以接受DISTINCT表达式。例如,我们可以通过这种方式计算排重后的交易码个数:
hive>SELECT count(DISTINCT symbol) FROM stocks;
0警告:等一下,结果为0?当使用count(DISTINCT col)而同时col是分区列时存在这个bug。
1.4.3、表生成函数
与聚合函数“相反的”一类函数就是所谓的表生成函数,其可以将单列扩展成多列或者多行。这里我们将简要地讨论下,然后列举出Hive目前所提供的一些内置表生成函数。
下面我们通过一个例子来进行讲解。如下的这个查询语句将employees表中每行记录中的subordinates字段内容转换成0个或者多个新的记录行。如果某行雇员记录subordinates字段内容为空的话,那么将不会产生新的记录;如果不为空的话,那么这个数组的每个元素都将产生一行新记录:
hive>SELECT explode(subordinates) AS sub FROM employees;
Mary Smith
Todd Jones
Bill King上面的查询语句中,我们使用AS sub子句定义了列别名sub。当使用表生成函数时,Hive要求使用列别名。用户可能需要了解其他许多的特性细节才能正确地使用这些函数。
下面是一个使用函数parse_url_tuple的例子,其中我们假设存在一张名为url_table的表,而且表中含有一个名为url的列,列中存储有很多网址:
SELECT parse_url_tuple(url,'HOST','PATH','QUERY') as (host,path,query) FROM urlt_able;1.4.4、其他内置函数
1.5、LIMIT语句
典型的查询会返回多行数据。LIMIT子句用于限制返回的行数:
SELECT upper(name),salary,deductions["Federal Taxes"],round(salary*(1-deductions["Federa1Taxes"]))
FROM employees LIMIT2;1.6、列别名
前面的示例查询语句可以认为是返回一个由新列组成的新的关系,其中有些新产生的结果列对于表来说是不存在的。通常有必要给这些新产生的列起一个名称,也就是别名。下面这个例子对之前的那个查询进行了修改,为第3个和第4个字段起了别名,别名分别为fed_taxes和salary_minus_fed_taxes。
SELECT upper(name),salary,deductions["Federal Taxes"] as fed_taxes,
round(salary * (1-deductions["Federal Taxes")) as salary_minus_fed_taxes
FROM employees LIMIT 2;1.7、嵌套SELECT语句
对于嵌套查询语句来说,使用别名是非常有用的。下面,我们使用前面的示例作为一个嵌套查询:
FROM (
SELECT upper(name),salary,deductions["Federal Taxes"] as fed_taxes,
round(salary * (1-deductions["Federal Taxes"])) as salary_minus_fed_taxes
FROM empioyees) e
SELECT e.name,e.salary_minus_fed_taxes
WHERE e.salary_minus_fed_taxes > 70000;从这个嵌套查询语句中可以看到,我们将前面的结果集起了个别名,称之为e,在这个语句外面嵌套查询了name和salary_minus_fed_taxes两个字段,同时约束后者的值要大于70000。
1.8、CASE…WHEN…THEN句式
CASE…WHEN…THEN语句和if条件语句类似,用于处理单个列的查询结果。
SELECT name,salary,
CASE
WHEN salary<50000.0 THEN 'low'
WHEN salary>50000.0 AND salary<70000.0 THEN 'middle'
WHEN salary>=70000.0 AND salary<100000.0 THEN 'high'
ELSE 'veryhigh'
END AS bracket FROM employees;1.9、什么情况下Hive可以避免进行MapReduce
对于本书中的查询,如果用户进行过执行的话,那么可能会注意到大多数情况下查询都会触发一个MapReduce任务(job)。Hive中对某些情况的查询可以不必使用MapReduce,也就是所谓的本地模式,例如:
SELECT * FROM employees;在这种情况下,Hive可以简单地读取employees对应的存储目录下的文件,然后输出格式化后的内容到控制台。
对于WHERE语句中过滤条件只是分区字段这种情况(无论是否使用LIMIT语句限制输出记录条数),也是无需MapReduce过程的。
SELECT * FROM employees WHERE country='US' AND state='CA' LIMIT 100;此外,如果属性hive.exec.mode.local.auto的值设置为true的话,Hive还会尝试使用本地模式执行其他的操作:
set hive.exec.mode.local.autoi=true;否则,Hive使用MapReduce来执行其他所有的查询。
提示:最好将set hive.exec.mode.local.autoi=true;这个设置增加到你的$HOME/.hiverc配置文件中。
2、WHERE语句
SELECT语句用于选取字段,WHERE语句用于过滤条件,两者结合使用可以查找到符合过滤条件的记录。和SELECT语句一样,在介绍WHERE语句之前我们已经在很多的简单例子中使用过它了。之前都是假定用户是见过这样的语句的,现在我们将更多地探讨一些细节。
WHERE语句使用谓词表达式,对于列应用在谓词操作符上的情况,稍后我们将进行讨论。有几种谓词表达式可以使用AND和OR相连接。当谓词表达式计算结果为时,相应的行将被保留并输出。
谓词可以引用和SELECT语句中相同的各种对于列值的计算。这里我们修改下之前的对于联邦税收的查询,过滤保留那些工资减去联邦税后总额大于70000的查询结果:
SELECT name,salary,deductions["Federal Taxes"],
salary(1-deductions["Federal Taxes"])
FROM employees
WHERE round(salary*(1-deductions["Federal Taxes"]))>70000;这个查询语句有点难看,因为第2行的那个复杂的表达式和WHERE后面的表达式是一样的。下面的查询语句通过使用一个列别名消除了这里表达式重复的问题,但是不幸的是它不是有效的:
SELECT name,salary,deductions["Federa1Taxes"],
salary * (1-deductions["FederaITaxes"])as salary_minus_fed_taxes
FROM employees
WHERE round(salary_minus_fed_taxes)>70000;FAILED:Error in semantic analysis:Line4:13 lnvalid table alias or
column refernce 'salary_minus_fed_taxes':(possible column names are:
name,salary,subordinates,deductions,address)
正如错误信息所提示的,不能在WHERE语句中使用列别名。不过,我们可以使用一个嵌套的SELECT语句:
SELECT e.* FROM
(SELECT name,salary,deductions["Federal Taxes"] as ded,
salary* (1-deductions["Federal Taxes"]) as salary_minus_fed_taxes
FROM employees) e
WHERE round(e.salary_minus_fed_taxes)>70000;2.1.关于浮点数比较
浮点数比较的一个常见陷阱出现在不同类型间作比较的时候(也就是FLOAT和DOUBLE比较)。思考下面这个对于员工表的查询语句,该语句将返回员工姓名、工资和联邦税,过滤条件是薪水的减免税款超过0.2(20%):
SELECT name,salary,deductions['Federal Taxes']
FROM employees WHERE deductions['Federal Taxes']>0.2;等一下!为什么deductions['FederalTaxes']=0.2的记录也被输出了?
这是个Hive的Bug吗?确实有个issue是关于这个问题的,但是其实际上反映了内部是如何进行浮点数比较的,这个问题几乎影响了在现在数字计算机中所有使用各种各样编程语言编写的软件。
当用户写一个浮点数时,比如0.2,Hive会将该值保存为DOUBLE型的。我们之前定义deductions这个map的值的类型是FLOAT型的,这意味着Hive将隐式地将税收减免值转换为DOUBLE类型后再进行比较。这样应该是可以的,对吗?
事实上,这样行不通。这里解释下为什么不能。数字0.2不能够使用FLOAT或DOUBLE进行准确表示。在这个例子中,0.2的最近似的精确值应略大于0.2,也就是0.2后面的若干个0后存在非零的数值。
为了简化一点,实际上我们可以说0.2对于FLOAT类型是0.2000001,而对于DOUBLE类型是0.200000000001。这是因为一个8个字节的DOUBLE值具有更多的小数位(也就是小数点后的位数)。当表中的FLOAT值通过Hive转换为DOUBLE值时,其产生的DOUBLE值是0.200000100000,这个值实际要比0.200000000001大。这就是为什么这个查询结果像是使用了>=而不是>了。
这个问题并非仅仅存在于Hive中或Java中(Hive是使用Java实现的)。而是所有使用IEEE标准进行浮点数编码的系统中存在的一个普遍的问题。
然而,Hive中有两种规避这个问题的方法。
首先,如果我们是从TEXTFILE文本文件中读取数据的话,也就是目前为止我们所假定使用的存储格式,那么Hive会从数据文件中读取字符串“0.2”然后将其转换为一个真实的数字。我们可以在表模式中定义对应的字段类型为DOUBLE而不是FLOAT。这样我们就可以对deductions["Federal Taxes']这个DOUBLE值和0.2这个DOUBLE值进行比较。不过,这种变化会增加我们查询时所需的内存消耗。同时,如果存储格式是二进制文件格式的话,我们也不能简单地进行这样的改变。
第2个规避方案是显式地指出0.2为FLOAT类型的。Java中有一个很好的方式能够达到这个目的:只需要在数值末尾加上字母F或f(例如,0.2f)。不幸的是,Hive并不支持这种语法,这里我们必须使用cast操作符。
下面这个是修改后的查询语句,其将0.2类型转换为FLOAT类型了。通过这个修改,返回结果是符合预期的:
SELECT name,salary,deductions['FederaI Taxes'] FROM employees
WHERE deductions['Federal Taxes"]>cast (0.2 AS FLOAT);注意cast操作符内部的语法:数值 AS FLOAT。
实际上,还有第3种解决方案,即:和钱相关的都避免使用浮点数。
对浮点数进行比较时,需要保特极端谨慎的态度。要避免任何从窄类型隐式转换到更广泛类型的操作。
3、GROUPBY语句
GROUPBY语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作。
SELECT year(ymd),avg(price_close) FROM stocks
WHERE exchange='NASDÄQ' AND symbol='AAPL'
GROUP BY year(ymd);HAVING语句
HAVING子句允许用户通过一个简单的语法完成原本需要通过子查询才能对GROUP BY语句产生的分组进行条件过滤的任务。如下是对前面的查询语句增加一个HAVING语句来限制输出结果中年平均收盘价要大于$50.0:
SELECT year(ymd),avg(price_close) FROM stocks
WHERE exchange='NASDAQ' AND symbol='AAPL'
GROUP BY year(ymd)
HAVING avg(price_close)>50.0;如果没使用HAVING子句,那么这个查询将需要使用一个嵌套SELECT子查询:
SELECT s2.year,s2.avg FROM
(SELECT year(ymd) AS year,avg(price_close) AS avg FROM stocks
WHERE exchange='NASDAQ' AND symbol='AAPL'
GROUP BY year(ymd)) s2
WHERE s2.avg>50.0;4、JOIN语句
Hive支持通常的SQL JOIN语句,但是只支持等值连接。
4.1、INNER JOIN
内连接(INNER JOIN)中,只有进行连接的两个表中都存在与连接标准相匹配的数据才会被保留下来。例如,如下这个查询对苹果公司的股价(股票代码AAPL)和IBM公司的股价(股票代码IBM)进行比较。股票表stocks进行自连接,连接条件是ymd字段(也就是year-month-day)内容必须相等。我们也称ymd字段是这个查询语句中的连接关键字。
SELECT a.ymd,a.price_close,b.price_close
FROM stocks a JOIN stocks b ON a.ymd=b.ymd
WHERE a.symbol='AAPL' AND b.symbol='IBM';ON子句指定了两个表间数据进行连接的条件。WHERE子句限制了左边表是AAPL的记录,右边表是IBM的记录。同时用户可以看到这个查询中需要为两个表分别指定表别名。
众所周知,IBM要比Apple老得多。IBM也比Apple具有更久的股票交易记录。不过,既然这是一个内连接(INNERJOIN),IBM的1984年9月7日前的记录就会被过滤掉,也就是Apple股票交易日的第一天算起!
标准SQL是支持对连接关键词进行非等值连接的,例如下面这个显示Apple和IBM对比数据的例子,连接条件是Apple的股票交易日期要比IBM的股票交易日期早。这个将会返回很少数据!标准SQL是支持对连接关键词进行非等值连接的,Hive中不支持,主要原因是通过MapReduce很难实现这种类型的连接。
同时,Hive目前还不支持在ON子句中的谓词间使用OR。
通过下面的例子我们来看下非自连接操作。dividends表的数据同样来自于infochimps.org:
CREATE EXTERNAL TABLE IF NOT EXISTS dividends(
ymd STRING,
dividend FLOAT
)
PARTITIONED BY(exchange STRING,symbol STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';下面这个例子就是苹果公司的stocks表和dividends表按照字段ymd和字段symbol作为等值连接键的内连接(INNER JOIN):
SELECT s.ymd,s.symbol,s.price_close,d.dividend
FROM stocks s JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
WHERE s.symbol='AAPL';用户可以对多于2张表的多张表进行连接操作。下面我们来对Apple公司、IBM公司和GE公司并排进行比较:
SELECT a.ymd,a.price_close,b.price_close,c.price_close
FROM stocks a JOIN stocks b ON a.ymd=b.ymd
JOIN stocks c ON a.ymd=c.ymd
WHERE a.symbol='AAPL' AND b.symbol='IBM' AND c.symbol='GE';大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中,会首先启动一个MapReducejob对表a和表b进行连接操作,然后会再启动一个MapReducejob将第一个MapReducejob的输出和表c进行连接操作。
提示:为什么不是表b和表c先进行连接操作呢?这是因为Hive总是按照从左到右的順序执行的。
4.2、JOIN优化
在前面的那个例子中,每个ON子句中都使用到了a.ymd作为其中一个JOIN连接键。在这种情况下,Hive通过一个优化可以在同一个MapReduce job中连接3张表。同样,如果b.ymd也用于ON子句中的话,那么也会应用到这个优化。
当对3个或者更多个表进行JOIN连接时,如果每个ON子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
Hive同时假定查询中最后一个表是最大的那个表。在对每行记录进行连接操作时,它会尝试将其他表缓存起来,然后扫描最后那个表进行计算。因此,用户需要保证连续查询中的表的大小从左到右是依次增加的。
幸运的是,用户并非总是要将最大的表放置在查询语句的最后面的。这是因为Hive还提供了一个“标记"机制来显式地告之查询优化器哪张表是大表,使用方式如下:
SELECT /*+STREAMTABLE(s)*/ s.ymd,s.symbol,s.price_close,d.dividend
FROM stocks s JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
WHERE s.symbol='AAPL';现在Hive将会尝试将表stocks作为驱动表,即使其在查询中不是位于最后面的。
4.3、LEFT OUTER JOIN
左外连接通过关键字LEFTOUTER进行标识:
SELECT s.ymd,s.symbol,s.price_close,d.dividend FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd=d.ymd AND s.symboI=d.symbol WHERE s.symbol='AAPL'在这种JOIN连接操作中,JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。JOIN操作符右边表中如果没有符合ON后面连接条件的记录时,那么从右边表指定选择的列的值将会是NULL。
因此,在这个结果集中,我们看到Apple公司的股票记录都返回了,而d.divldend字段的值通常是NULL。
4.4、OUTER JOIN
在我们讨论其他外连接之前,让我们来讨论一个用户应该明白的问题。
回想下,前面我们说过,通过在WHERE子句中增加分区过滤器可以加快查询速度。为了提高前面那个查询的执行速度,我们可以对两张表的exchange字段增加谓词限定:
SELECT s.ymd,s.symbol,s.price_close,d.dividend FROM stocks s LEFT OUTER JOIN dividends d ON
s.ymd=d.ymd AND s.symbol=d.symbol WHERE s.symbol='AAPL' AND s.exchange='NASDAQ' AND d.exchange='NASDAQ'不过,这时我们发现输出结果改变了,虽然我们可能认为我们不过增加了一个优化!
我们重新获得每年4条左右的股票交易记录,而且我们发现每年对应的股息值都是非NULL的。换句话说,这个效果和之前的内连接(INNER JOIN)是一样的!
在大多数的SQL实现中,这种现象实际上是比较常见的。之所以发生这种情况,是因为会先执行JOIN语句,然后再将结果通过WHERE语句进行过滤。在到达WHERE语句时,d.exchange字段中大多数值为NULL,因此这个“优化”实际上过滤掉了那些非股息支付日的所有记录。
一个直接有效的解决方式是:移除掉WHERE语句中对dividends表的过滤条件,也就是去除掉d.exchange='NASDAQ'这个限制条件。
SELECT s.ymd,s.symbol,s.price_close,d.dåvidend FROM stocks s LEFT OUTER JOIN dividends d ON
s.ymd=d.ymd AND s.symbol=d.symbol WHERE s.symbol='AAPL 'AND s.exchange='NASDAQ'这种方式并非很令人满意。用户可能会想知道是否可以将WHERE语句中的内容放置到ON语句里,至少知道分区过滤条件是否可以放置在ON语句中。对于外连接OUTER JOIN)来说是不可以这样的。
SELECT s.ymd,s.symbol,s.price_close.d.dividend
FROM stocks s LEFT OUTER JOIN dividends d
ON s.ymd=d.ymd AND s.symbol=d.symbol
AND s.symbol="APPL" AND s.exchange='NASDAQ' AND exchange='NASDAQ'对于外连接(OUTER JOIN)会忽略掉分区过滤条件。不过,对于内连接(INNER JOIN)使用这样的过滤谓词确实是起作用的!
幸运的是,有一个适用于所有种类连接的解决方案,那就是使用嵌套SELECT语句:
SELECT s.ymd,s.symbol,s.price_close,d.dividend FROM
(SELECT * FROM stocks WHERE symbol='AAPL' AND exchange='NASDAQ') s
LEFT OUTER JOIN
(SELECT * FROM dividends WHERE symbol='AAPL' ADD exchange='NASDAQ')d
ON s.ymd=d.ymd;嵌套SELECT语句会按照要求执行“下推”过程,在数据进行连接操作之前会先进行分区过滤。
提示:WHERE语句在连接操作执行后才会执行,因此WHERE语句应该只用于过滤那些非NULL值的列值。同时,和Hive的文档说明中相反的是,ON语句中的分区过滤条件外连接(OUTER JOIN)中是无效的,不过在内连接(INNER JOIN)中是有效的。
4.5、RIGHT OUTER JOIN
右外连接(RIGHTOUTERJOIN)会返回右边表所有符合WHERE语句的记录。左表中匹配不上的字段值用NULL代替。
这里我们调整下stocks表和divideneds表的位置来执行右外连接,并保留SELECT语句不变:
SELECT s.ymd,s.symbol,s.price_close,d.dividend
FROM dividends d RIGHT OUTER JOIN stocks s ON d.ymd=s.ymd AND d.symbol=s.symbol
WHERE s.symbol='AAPL'4.6、FULL OUTER JOIN
最后介绍的完全外连接(FULL OUTER JOIN)将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
如果我们将前面的查询改写成一个完全外连接查询的话,事实上获得的结果和之前的一样。这是因为不可能存在有股息支付记录而没有对应的股票交易记录的情况。
SELECT s.ymd,s.symböl,s.price_close,d.dividend
FROM dividends d FULL OUTER JOIN stocks s ON d.ymd=s.ymd AND d.symbol=s.symbol
WHERE s.symbol='AAPL'4.7、LEFT SEMI-JOIN
左半开连接(LEFT SEMI-JOIN)会返回左边表的记录,前提是其记录对于右边表满足ON语句中的判定条件。对于常见的内连接(INNERJOIN)来说,这是一个特殊的、优化了的情况。大多数的SQL方言会通过IN…EXISTS结构来处理这种情况。例如下面的例中所示的查询,其将试图返回限定的股息支付日内的股票交易记录,不过这个查询Hive是不支持的。
例、Hive中不支持的查询
SELECT s.ymd,s.symbol,s.price_close FROM stocks s
WHERE s.ymd,s.symbol IN
(SELECT d.ymd,d.symbol FROM dividends d)不过,用户可以使用如下的LEFT SEMIJOIN语法达到同样的目的:
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s LEFT SEMI JOIN dividends d ON s.ymd=d.ymd AND s.symbol请注意,SELECT和WHERE语句中不能引用到右边表中的字段。
Hive不支持右半开连接(RIGHTSEMI-JOIN).
SEMI-JOIN比通常的INNER JOIN要更高效,原因如下:对于左表中一条指定的记录,在右边表中一旦找到匹配的记录,Hive就会立即停止扫描。从这点来看,左边表中选择的列是可以预测的。
4.8、笛卡尔积JOIN
笛卡尔积是一种连接,表示左边表的行数乘以右边表的行数等于笛卡尔结果集的大小、也就是说如果左边表有5行数据,而右边表有6行数据,那么产生的结果将是30行数据:
SELECT * FROM stocks JOIN dividends;
如上面的查询,以stocks表和dividends表为例,实际上很难找到合适的理由来执行这类连接,因为一只股票的股息通常并非和另一只股票配对。此外,笛卡尔积会产生大量的数据。和其他连接类型不同,笛卡尔积不是并行执行的,而且使用MapReduce计算架构的话,任何方式都无法进行优化。
这里非常有必要指出,如果使用了错误的连接(JOIN)语法可能会导致产生一个执行时间长、运行缓慢的笛卡尔积查询。例如,如下这个查询在很多数据库中会被优化成内连接(INNER JOIN),但是在Hive中没有此优化:
SELECT * FROM stocks JOIN dividends
WHERE stock.symbol=dividends.symbol and stock.symbol='AAPL'在Hive中,这个查询在应用WHERE语句中的谓词条件前会先进行完全笛卡尔积计算。
这个过程将会消耗很长的时间。如果设置属性hive.mapred.mode值为strict的话,Hive会阻止用户执行笛卡尔积查询。
提示:笛卡尔积在一些情况下是很有用的·例如,假设有一个表表示用户偏好,另有一个表表示新闻文章,同时有一个算法会推测出用户可能会喜欢读哪些文章·这个时候就需要使用笛卡尔积生成所有用户和所有网页的对应关系的集合。
4.9、map-side JOIN
如果所有表中只有一张表是小表,那么可以在最大的表通过mapper的时候将小表完全放到内存中。Hive可以在map端执行连接过程(称为map-sideJOIN),这是因为Hive可以和内存中的小表进行逐一匹配,从而省略掉常规连接操作所需要的reduce过程。
即使对于很小的数据集,这个优化也明显地要快于常规的连接操作。其不仅减少了reduce过程,而且有时还可以同时减少map过程的执行步骤。
stocks表和dividends表之间的连接操作也可以利用到这个优化,因为dividends表中的数据集很小,已经可以全部放在内存中缓存起来了。
在Hivev0.7之前的版本中,如果想使用这个优化,需要在查询语句中增加一个标记来进行触发。如下面的这个内连接(INNER JOIN)的例子所示:

在一个比较快的MacBookPro笔记本电脑上执行上面这个优化后的查询大约需要23s,这明显比优化前执行所消耗的33s要快。在相同的股票样本数据集上执行,执行速度提高了大约3。
从Hive v0.7版本开始,废弃了这种标记的方式,不过如果增加了这个标记同样是有效的。如果不加上这个标记,那么这时用户需要设置属性hive.auto.convert.join的值为true,这样Hive才会在必要的时候启动这个优化。默认情况下这个属性的值是false。
hive>set hive.auto.convert.join=true;
hive>SELECT s.ymd,s.symbol,s.price_close,d.dividend
>FROM stocks s JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
>WHERE s.symbol='AAPL';需要注意的是,用户也可以配置能够使用这个优化的小表的大小。如下是这个属性的默认值(单位是字节):
hive.mapjoin.smalltable.flesze=25000000
如果用户期望Hive在必要的时候自动启动这个优化的话,那么可以将这一个(或两个)属性设置在$HOME/.hiverc文件中。
Hive对于右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUT ERJOIN)不支持这个优化。
如果所有表中的数据是分桶的,那么对于大表,在特定的情况下同样可以使用这个优化,详细介绍请参见“分桶表数据存储”中的介绍。简单地说,表中的数据必须是按照ON语句中的键进行分桶的,而且其中一张表的分桶的个数必须是另一张表分桶个数的若干倍。当满足这些条件时,那么Hive可以在map阶段按照分桶数据进行连接·因此这种情况下,不需要先获取到表中所有的内容,之后才去和另一张表中每个分桶进行匹配连接。
不过,这个优化同样默认是没有开启的。需要设置参数hive.optimize.bucketmapjoin为true才可以开启此优化:
set hive.optimize.bucketmapjoin=true;如果所涉及的分桶表都具有相同的分桶数,而且数据是按照连接键或桶的键进行排序的,那么这时Hwe可以执行一个更快的分类.合并连接(sort-mergeJOIN)。同样地,这个优化需要需要设置如下属性才能开启:
set hive.input.format.org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;6.5、ORDERBY和SORTBY
Hive中ORDERBY语句和其他的SQL方言中的定义是一样的。其会对查询结果集执行一个全局排序。这也就是说会有一个所有的数据都通过一个reducer进行处理的过程。对于大数据集,这个过程可能会消耗太过漫长的时间来执行。
Hive增加了一个可供选择的方式,也就是SORTBY,其只会在每个reducer中对数据进行排序,也就是执行一个局部排序过程。这可以保证每个reducer的输出数据都是有序的(但并非全局有序)。这样可以提高后面进行的全局排序的效率。
对于这两种情况,语法区别仅仅是,一个关键字是ORDER,另一个关键字是SORT。
用户可以指定任意期望进行排序的字段,并可以在字段后面加上ASC关键字(默认的),表示按升序排序,或加DESC关键字,表示按降序排序。
下面是一个使用ORDER BY的例子:
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s
ORDER BY s.ymd ASC,s.symbol DESC下面是一个类似的例子,不过使用的是SORT BY。
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s
SORT BY s.ymd ASC,s.symbol DESC;上面介绍的两个查询看上去几乎一样,不过如果使用的reducer的个数大于1的话,那么输出结果的排序就大不一样了。既然只保证每个reducer的输出是局部有序的,那么不同reducer的输出就可能会有重叠的。
因为ORDER BY操作可能会导致运行时间过长,如果属性hive.mapred.mode的值是strict的话,那么Hive要求这样的语句必须加有LIMIT语句进行限制。默认情况下,这个属性的值是nonstrict,也就是不会有这样的限制。
6、含有SORT BY的DISTRIBUTE BY
DISTRIBUTE BY控制map的输出在reducer中是如何划分的。MapReduce job中传输的所有数据都是按照键值对的方式进行组织的,因此Hive在将用户的查询语句转换成MapReducejob时,其必须在内部使用这个功能。
通常,用户不需要担心这个特性。不过对于使用了Streaming特性以及一些状态为UDAF(用户自定义聚合函数)的查询是个例外。还有,在另外一个场景下,使用这些语句是有用的。
默认情况下,MapReduce计算框架会依据map输人的键计算相应的哈希值,然后按照得到的哈希值将键·值对均匀分发到多个reducer中去。不过不幸的是,这也就意味着当我们使用SORTBY时,不同reducer的输出内容会有明显的重叠,至少对于排列顺序而言是这样,即使每个reducer的输出的数据都是有序的。
假设我们希望具有相同股票交易码的数据在一起处理。那么我们可以使用DISTRIBUTE BY来保证具有相同股票交易码的记录会分发到同一个reducer中进行处理,然后使用SORTBY来按照我们的期望对数据进行排序。如下这个例子就演示了这种用法:
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s
DISTRIBUTE BY s.symbol
SORT BY s.symbol ASC,s.ymd ASC当然,上面例子中的ASC关键字是可以省略掉的,因为其就是缺省值。这里加上了ASC关键字的原因,稍后我们将会进行简要的阐述。
DISTRIBUTE BY和GROUP BY在其控制着reducer是如何接受一行行数据进行处理这方面是类似的,而SORTBY则控制着reducer内的数据是如何进行排序的。需要注意的是,Hive要求DISTRIBUTEBY语句要写在DORTBY语句之前。
7、CLUSTER BY
在前面的例子中,s.symbol列被用在了DISTRIBUTE BY语句中,而s.symbol列和s.ymd位于SORT BY语句中。如果这2个语句中涉及到的列完全相同,而且采用的是升序排序方式(也就是默认的排序方式),那么在这种情况下,CLUSTER BY就等价于前面
的2个语句,相当于是前面2个句子的一个简写方式。
如下面的例子所示,我们将前面的查询语句中SORTBY后面的s.ymd字段去掉而只对s.symbol字段使用CLUSTER BY语句:
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s
CLUSTER BY s.symbol;因此排序限制中去除掉了s.ymd字段,所以输出中展示的是股票数据的原始排序方式,也就是降序排列。
使用DISTRIBUTEBY…SORTBY语句或其简化版的CLUSTERBY语句会剥夺SORTBY的并行性,然而这样可以实现输出文件的数据是全局排序的。
8、类型转换
在“基本数据类型”中我们简要提及了Hive会在适当的时候,对数值型数据类型进行隐式类型转换,其关键字是cast.例如,对不同类型的2个数值进行比较操作时就会有这种隐式类型转换。
这里我们讨论下cast函数,用户可以使用这个函数对指定的值进行显式的类型转换。
回想一下,前面我们介绍过的employees表中町列是使用FLOAT数据类型的。现在,我们假设这个字段使用的数据类型是STRING的话,那么我们如何才能将其作为FLOAT值进行计算呢?
如下这个例子会先将值转换为FLOAT类型,然后才会执行数值大小比较过程:
SELECT name,salary FROM employees
WHERE cast(salary AS FLOAT)<100000.0;类型转换函数的语法是cast(value AS TYPE)。如果例子中的salary字段的值不是合法的浮点数字符串的话,那么结果会怎么样呢?这种情况下,Hive会返回NULL。
需要注意的是,将浮点数转换成整数的推荐方式是使用round()或者flo0函数,而不是使用类型转换操作符cast。
类型转换BINARY值
Hive v0.8.0版本中新引人的BARY类型只支持将BARY类型转换为STRING类型。
不过,如果用户知道其值是数值的话,那么可以通过嵌套t()的方式对其进行类型转换,如下面例子所示,其中b字段类型是BINARY:
SELECT (2.0*cast(cast(b as string) as double)) from src用户同样可以将STRING类型转换为BINARY类型。
9、抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行分桶抽样来满足这个需求。
在下面这个例子中,假设numbers表只有number字段,其值是1到10。
我们可以使用rand()函数进行抽样,这个函数会返回一个随机值。前两个查询都返回了两个不相等的值,而第3个查询语句无返回结果:
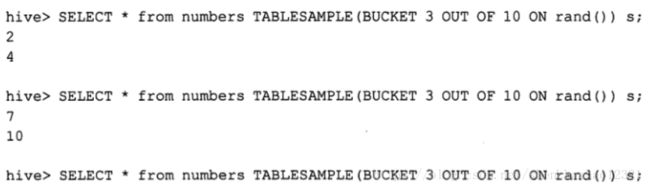
如果我们是按照指定的列而非rand()函数进行分桶的话,那么同一语句多次执行的返回值是相同的:
分桶语句中的分母表示的是数据将会被散列的桶的个数,而分子表示将会选择的桶的个数:
9.1、数据块抽样
Hive提供了另外一种按照抽样百分比进行抽样的方式,这种是基于行数的,按照输入路径下的数据块百分比进行的抽样:
SELECT * FROM numbersflat TABLESAMPLE(0.1 PERCENT) s;
这种抽样方式不一定适用于所有的文件格式·另外,这种抽样的最小抽样单元是一个HDFS数据块·因此,如果表的数据大小小于普通的块大小128MB的话,那么将会返回所有行。
基于百分比的抽样方式提供了一个变量,用于控制基于数据块的调优的种子信息:
hive.sample.seednumber
0
9.2、分桶表的输入裁剪
从第一次看TABLESAMPLE语句,精明的用户可能会得出“如下的查询和TABLESAMPLE操作相同”的结论:
SELECT * FROM numbersflat WHERE number%2=0对于大多数类型的表确实是这样的。抽样会扫描表中所有的数据,然后在每N行中抽取一行数据。不过,如果TABLESAMPLE语句中指定的列和CLUSTERED BY语句中指定的列相同,那么TABLESAMPLE查询就只会扫描涉及到的表的哈斯分区下的数据: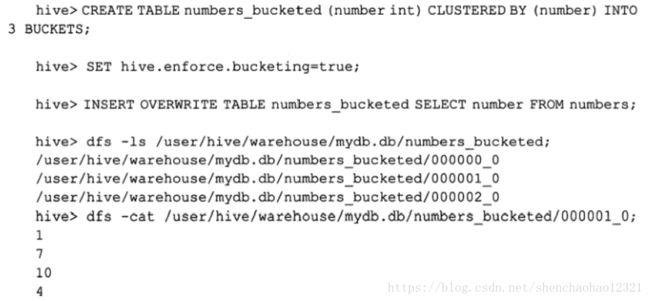
因为这个表已经聚集成3个数据桶了,下面的这个查询可以高效地仅对其中一个数据桶进行抽样: