springboot2.x初探(五)
这一篇文章还是接着上一篇继续分析。
还是先上一张图:

我们继续看第十三步创建异常报告实例:
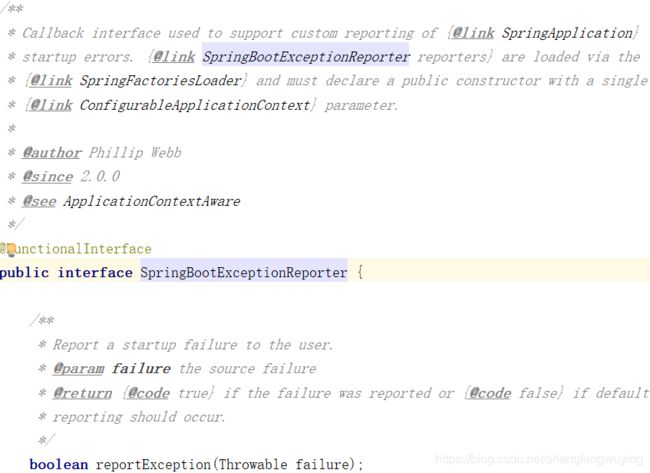
这个类就是一个报告SpringApplication启动过程中的错误的。具体的创建过程我们就不再细看,继续下一个步骤:
14.准备上下文:

代码中第一行和第二行是设置context的环境和资源加载器、类加载器、注册了一个单例的beannamegenerator,applyinitializers是将获取到的initializer中设置好context。对于listeners.contextPrepared方法:
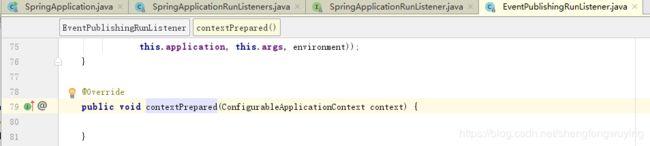
发现这个listener中没有东西,其他的listener还不知道。

这个方法中设置了一系列的读取工具,并将主类加入了excludeFilter中。
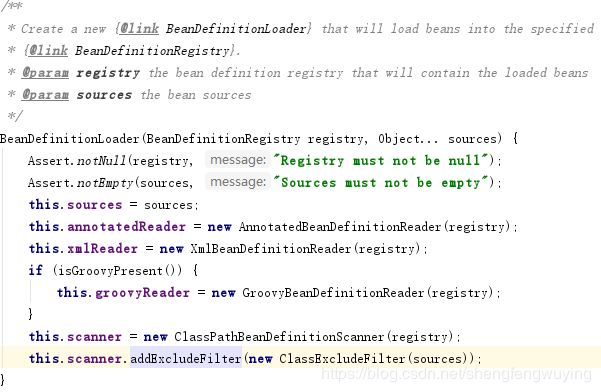
下面看prepareContext方法中的最后一行:


这其中最主要的是context.addApplicationListener(listener);这句,将读取的listener添加到context中。到这里第十四步就看完了,这一步主要就是给context设置各种加载器和监听器,执行初始化器的初始化方法。
下面我们看refreshContext:

方法很简单,看来主要的内容都在refresh方法中了:

下面这段代码比较长我分了三段来截图:
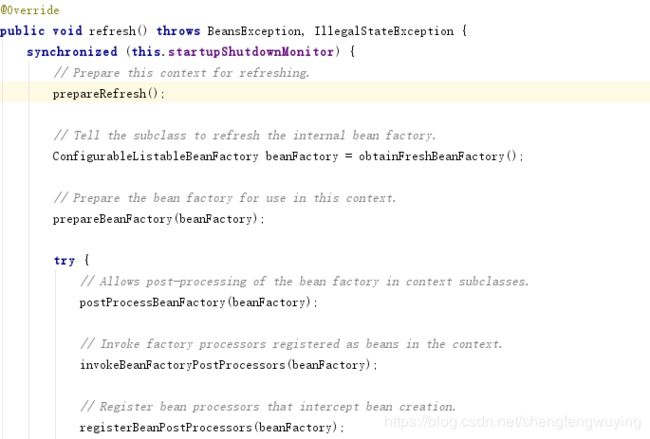


我们一步一步来看:
![]()
看看具体方法:


根据注释我们知道这个方法主要就做了三件事事情:设置启动时间、设置激活标志、运行初始化为属性赋值。
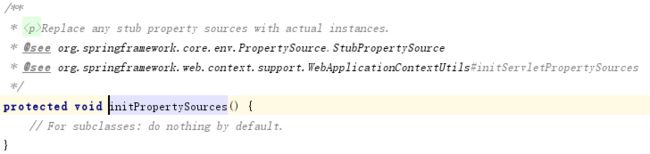
我们看到这里的赋值交给了子类去实现。我们前面已经知道我们的context是:AnnotationConfigServletWebServerApplicationContext,我们在它的类中以及它的父类中查找这个 initPropertySources方法,最终在GenericWebApplicationContext中找到了这个方法:

这里经过debug发现什么都没有运行,因为之后跟的代码中有if的判断都没有通过。
我们接着看下一个步骤:

从注释我们知道这一步是告诉子类去刷新内部的bean工厂。

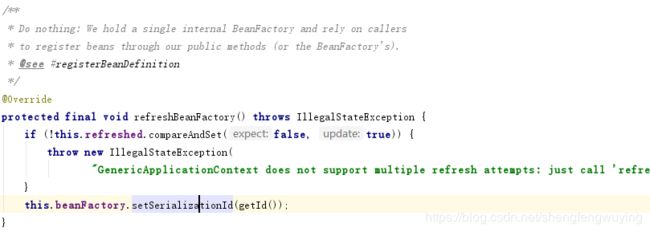
这个refreshBeanFactory方法什么都没干,就是设置了一个id。然后getBeanFactory方法就返回了一个DefaultListableBeanFactory。
下面继续看下一步:

这个就是设置了一系列的东西,自己下面看源码吧。
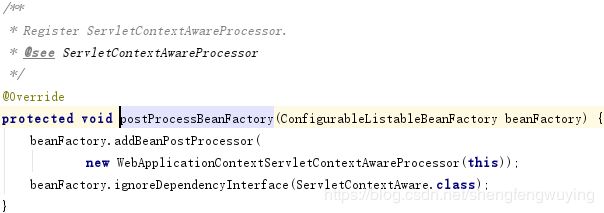
继续下一步:


下面这个图是上图中调用的父类方法:
经过debug我们发现basePackage和annotatedClasses都是空:
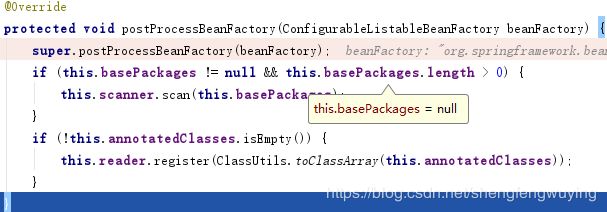
继续看下一个步骤:

刚才调试的时候遇到个疑问,当我运行完

这个方法之后,打印出来好几行日志,其中有一条:

已经加载了配置文件,但是在前面的调试过程中我并没有发现加载这个配置文件的过程呀,很有可能是我落掉了,于是从这条日志入手开始回溯,最终在
![]()
这里发现了源头,原来准备环境的时候就已经加载了配置文件,这里面有个

监听器的环境准备,一路跟下去到了这里:

当循环到ConfigFileApplicationLilstener的时候,执行了它的方法:
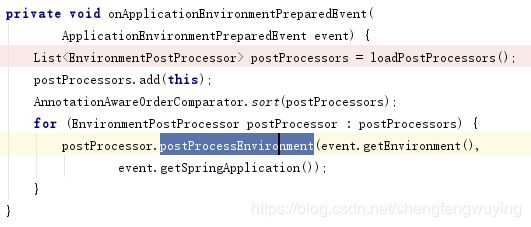


到了这里看注释就很明白了,就是添加配置文件到环境中。具体的看load方法:

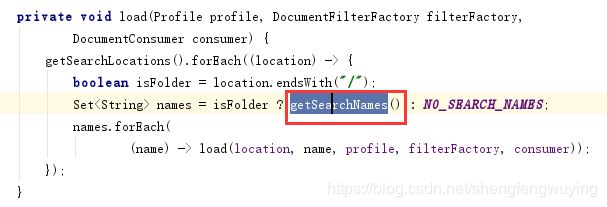
这个方法中调用了另外一个带参数的load方法:

这里调用了一个getSearchlocations方法:

这是方法中用到的三个常量:

![]()
![]()
我的应用中前两个配置都没有,所以就用的第三个常量来查找,根据注释我们知道查找的顺序是从后往前,若多个路径下都存在配置文件则以最后一个为准,所以我们一般将配置文件就放在classpath路径下,保证以这个配置为准。
代码中还有一个方法:
如下:
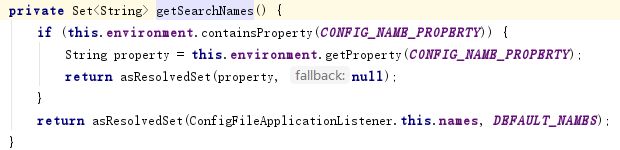
其中用到的常量:

![]()
然后加载文件:

这里面要文件后缀,后缀是从PropertySourceLoader中获取的,我们看道propertySourceLoaders中有两个PropertySourceLoader,PropertiesPropertySourceLoader和YamlPropertySourceLoader,我们看看他们分别使用什么后缀:


总共有四种后缀,也就是说支持4中后缀的配置文件。后面就是加载的过程了,这里就不再深入了,下面再继续看吧。
我们继续看这个:
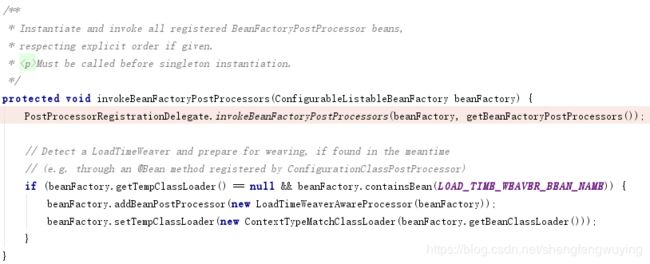
这个invoke的方法很长,我们慢慢看:
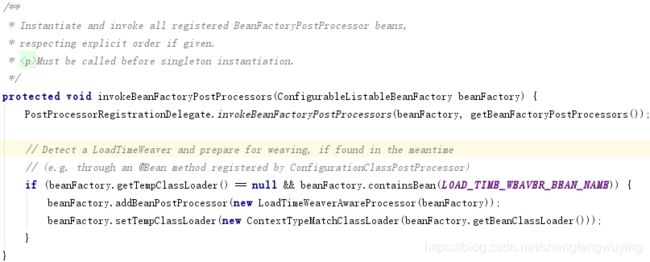
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List regularPostProcessors = new ArrayList<>();
List registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
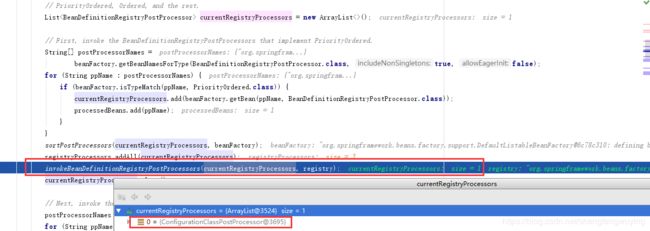
List currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List priorityOrderedPostProcessors = new ArrayList<>();
List orderedPostProcessorNames = new ArrayList<>();
List nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
List nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}

当运行到这里
的时候就正式进入了加载我们自己写的类的过程了:



这个方法也很大:
/**
* Build and validate a configuration model based on the registry of
* {@link Configuration} classes.
*/
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List configCandidates = new ArrayList<>();
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) ||
ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set candidates = new LinkedHashSet<>(configCandidates);
Set alreadyParsed = new HashSet<>(configCandidates.size());
do {
parser.parse(candidates);
parser.validate();
Set configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
candidates.clear();
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
} 当循环完毕上面的 7 个candidateNames之后:
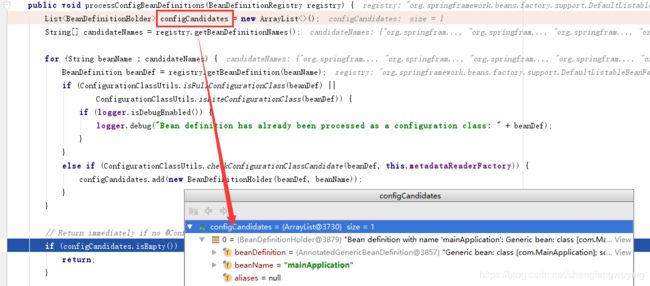
configCondidates中只有我们自己的启动类。

接下来的parse方法才是真正开始解析。

![]()


在上图的 do 处调用了下图的方法:

从注释可以知道这个方法就是用来通过读取注解、成员、方法等来创建一个完全的配置类的。
这个方法很大:
/**
* Apply processing and build a complete {@link ConfigurationClass} by reading the
* annotations, members and methods from the source class. This method can be called
* multiple times as relevant sources are discovered.
* @param configClass the configuration class being build
* @param sourceClass a source class
* @return the superclass, or {@code null} if none found or previously processed
*/
@Nullable
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
到了下图的方法处:

又是一个parse方法:

这个方法也很大:
public Set parse(AnnotationAttributes componentScan, final String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
} 内容主要是设置scanner,我们直接看最后一行:
/**
* Perform a scan within the specified base packages,
* returning the registered bean definitions.
* This method does not register an annotation config processor
* but rather leaves this up to the caller.
* @param basePackages the packages to check for annotated classes
* @return set of beans registered if any for tooling registration purposes (never {@code null})
*/
protected Set doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
Set candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
在上面方法体中的第四行处调用了下面的方法:
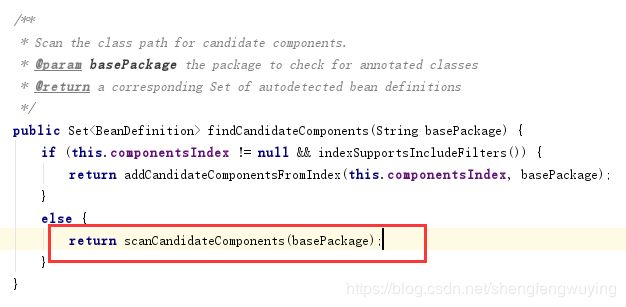
然后调用的第二个分支的代码:

从代码中可以看到传入的basePackage是come,这个是在上面的调用过程中解析出来的我们的主类所在的包的路径。
private Set scanCandidateComponents(String basePackage) {
Set candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
} 然后在方法体中的第三行代码拼接了要搜索的路径:

然后从改路径中获取类保存到数组中:
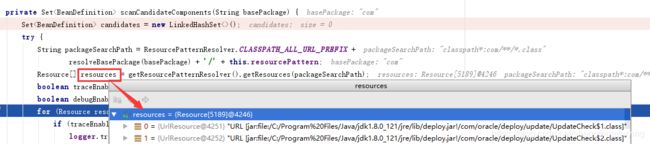
我们看到加载了5000多个类文件,其中就包括了我们自己写的类。
加载的过程:


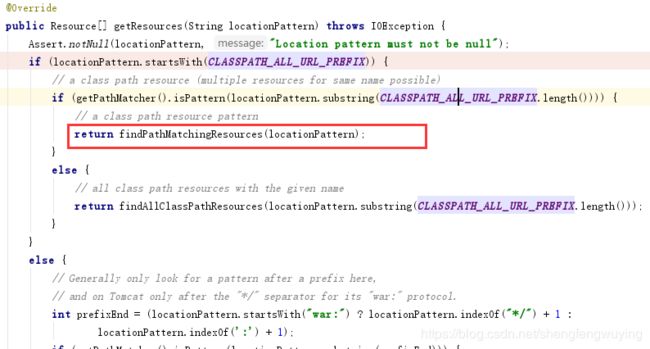
这里是一个递归的调用,加载的过程用使用到了双亲委派模型,如下:
下图是一个中间过程,展示了获取到我们写的类路径下的东西:
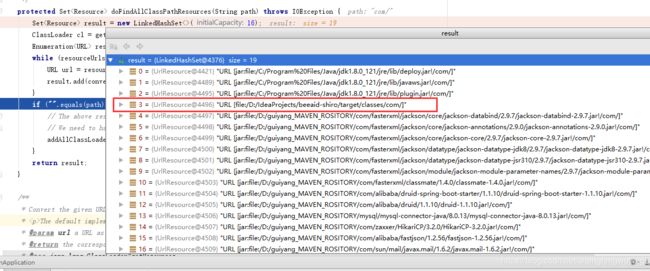
下面这个方法是具体的读取路径下的类文件的,并且逐个读取类的名称、父类、接口、属性、方法等信息,这个方法在ClassReader类中,这个类是spring中的。它的原理就是将类文件读取到字符数组后,调用这个accept方法来逐个读取类信息的。
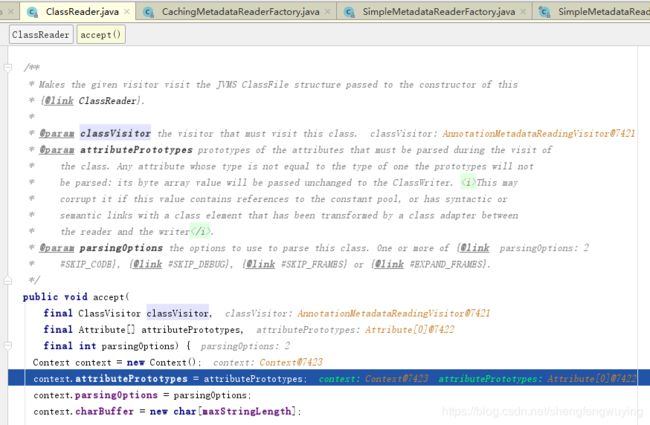
这个accept方法很大,内容很多,我觉得我没有获得其中的真谛,还是水平有限啊!!!
上面的doscan方法最后返回的:

我们写的类的东西。
后面还有很多内容,下面有时间再分析吧。