Solid-state revolution: in-depth on how SSDs really work

Way back in 1997, when dinosaurs roamed the earth and I was working part-time at the local Babbage's for $4.25 an hour, I scraped together enough spare change to purchase a 3Dfx Voodoo-based Diamond Monster 3D video card. The era of 3D acceleration was in its infancy and the Voodoo chipset was the chipset to beat. It all seems a bit silly now, but when I slapped that sucker into my aging Pentium 90 and fired up the new card's pack-in version of MechWarrior 2—which had texture-mapping and visual effects that the original 2D version lacked—my jaw hit the floor. I couldn't wait to speed-dial my buddy Matt and tell him that his much-faster Pentium 166 no longer brought all the polygons to the yard.
That video card was the most important PC upgrade I ever made, sparking a total change in my perception of what computers could do. I didn't think I would ever again experience something as significant as that one single upgrade—until the first time I booted up a laptop with a solid-state drive (SSD) in it. Much like that first glimpse of a texture-mapped MechWarrior 2, that first fast boot signaled a sea change in how I thought and felt about computers.
The introduction of 3D graphics changed our perceptions of computing not because it made colors brighter or virtual worlds prettier—though it did those things and they are awesome—but because it made a smoothly responsive 30 and 60 frames per second gaming experience a standard. Solid-state drives have a similar effect. They're faster than spinning disk, to be sure, but their most important contribution isn't just that they are faster, but rather that they make the whole computer feel faster. They remove barriers between you and your PC, in effect thinning the glass between you and the things that you're doing with and through your computer.
Solid-state drives are odd creatures. Though they sound simple in theory, they store some surprisingly complex secrets. For instance, compare an SSD to a traditional magnetic hard drive. A modern multi-terabyte spinning hard disk plays tricks with magnetism and quantum mechanics, results of decades of research and billions of dollars and multiple Nobel Prizes in physics. The drives contain complex moving parts manufactured to extremely tight tolerances, with drive heads moving around just thousandths of a millimeter above platters rotating at thousands of revolutions per minute. A modern solid-state drive performs much more quickly, but it's also a more mundane on the inside, as it's really a hard drive-shaped bundle of NAND flash memory. Simple, right?
However, the controller software powering an SSD does some remarkable things, and that little hard drive-shaped bundle of memory is more correctly viewed as a computer in its own right.
Given that SSDs transform the way computers "feel," every geek should know at least a bit about how these magical devices operate. We'll give you that level of knowledge. But because this is Ars, we're also going to go a lot deeper—10,000 words deep. Here's the only primer on SSD technology you'll ever need to read.
Varying degrees of fast
It's easy to say "SSDs make my computer fast," but understanding why they make your computer fast requires a look at the places inside a computer where data gets stored. These locations can collectively be referred to as the "memory hierarchy," and they are described in great detail in the classic Ars article "Understanding CPU Caching and Performance."
It's an axiom of the memory hierarchy that as one walks down the tiers from top to bottom, the storage in each tier becomes larger, slower, and cheaper. The primary measure of speed we're concerned with here is access latency, which is the amount of time it takes for a request to traverse the wires from the CPU to that storage tier. Latency plays a tremendous role in the effective speed of a given piece of storage, because latency is dead time; time the CPU spends waiting for a piece of data is time that the CPU isn't actively working on that piece of data.
The table below lays out the memory hierarchy:
| Level | Access time | Typical size |
|---|---|---|
| Registers | "instantaneous" | under 1KB |
| Level 1 Cache | 1-3 ns | 64KB per core |
| Level 2 Cache | 3-10 ns | 256KB per core |
| Level 3 Cache | 10-20 ns | 2-20 MB per chip |
| Main Memory | 30-60 ns | 4-32 GB per system |
| Hard Disk | 3,000,000-10,000,000 ns | over 1TB |
At the very top of the hierarchy are the tiny chunks of working space inside a CPU where the CPU stores things it's actively manipulating; these are called registers. They are small—only a few hundred bytes total—and as far as memory goes, they have the equivalent of a Park Avenue address. They have the lowest latency of any segment of the entire memory hierarchy—the electrical paths from the parts of the CPU doing the work to the registers themselves are unfathomably tiny, never even leaving the core portion of the CPU's die. Getting data out in and out of a register takes essentially no time at all.
Adding more registers could potentially make the CPU compute faster, and as CPU designs get more advanced they do indeed tend to gain more (or larger) registers. But simply adding registers for the sake of having more registers is costly and complicated, especially as software has to be recompiled to take advantage of the extra register space. So data that the CPU has recently manipulated but that isn't being actively fiddled with at the moment is temporarily placed one level out on the memory hierarchy, into level 1 cache. This is still pricey real estate, being a part of the CPU die, but not as pricey as the registers. In a modern CPU, getting data out of the L1 cache takes three or four cycles (typically around a nanosecond or so) compared to zero cycles for the registers. The trade-off for that slower performance is that there's a lot more space in this tier—up to 32KB of data per CPU core in an Intel Ivy Bridge i7 CPU.
Data that the CPU expects to access again shortly is kept another level out, in the level 2 cache, which is slower and larger, and which carries still more latency (typically between 7 and 20 cycles).
Modern CPUs have level 3 caches as well, which have higher latencies again, and which can be several megabytes in size.
Even further down the hierarchy is the computer's main memory, which has much higher effective latency than the CPU's on-die cache. The actual RAM chips are rated for very low latency (DDR2 DRAM, for example, is typically rated for five nanoseconds), but the components are physically distant from the CPU and the effective latency is therefore higher—usually between 40 and 80 nanoseconds—because the electrical signals from the CPU have to travel through the motherboard's traces to reach the RAM.
At the bottom of the hierarchy sits our stalwart hard disk, the repository of all your programs, documents, pictures, and music. All roads lead here. Any time a program is executed, an MP3 is played, or any kind of data needs to be viewed or changed by you, the user, the computer calls on the disk to deliver it up.
Disks these days are large, but they are also glacially slow compared to the other tiers in the memory hierarchy, with latency a million times higher than the previous tier. While waiting for main memory to respond, the processor might have nothing to do for a few dozen cycles. While waiting for the disk to respond, it will twiddle its thumbs for millions of cycles.
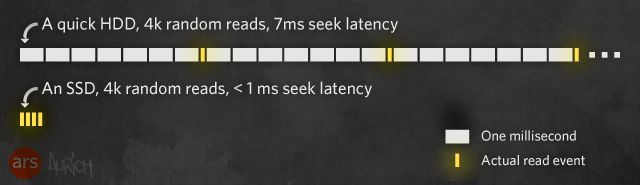
Worse, the latency of a spinning hard disk is variable, because the medium itself is in motion. In order to start an application like, say, Google Chrome, the hard disk may have to read data from multiple locations, which means that the drive heads have to seek around for the right tracks and in some cases even wait whole milliseconds for the correct blocks to rotate underneath them to be read. When we're defining latency in terms of billionths of a second in previous tiers, suddenly having to contend with intervals thousands of times larger is a significant issue. There are many tricks that modern computers and operating systems do to lessen this latency, including trying to figure out what data might be needed next and preemptively loading that data into RAM before it's actually requested, but it's impossible to overcome all of the latency associated with spinning disks.
On one hand, human beings like us don't operate in terms of milli-, micro-, or nanoseconds, at least not without the aid of serious drugs. A thousandth of a second is the same to us as a billionth of a second—both are intervals so small that they might as well be identical. However, with the computer doing many millions of things per second, those tiny fractions of time add up to very real subjective delays, and it can be frustrating when you click on Microsoft Word and stare at a spinning "Please wait!" cursor for seconds at a time. Waiting on the computer while it drags something off of a slow hard disk is disruptive to workflow and can be a jarring experience, especially if you've got a rapidly derailing train of thought barrelling through your head that you need to write down.
Solid-state drives provide an immediate boost to the subjective speed of the computer because they take a big chunk out of the largest amount of latency you experience. Firstly and more obviously, solid-state drives don't have moving heads and rotating platters; every block is accessible at the same speed as every other block, whether they're stored right next to each other or in different physical NAND chips. Reading and writing data to and from the solid-state drive is faster as well, so not only does the computer have to wait fewer milliseconds for its requests to be serviced, but the solid-state drive can also effectively read and write data faster. Quicker responses (lower latency) plus faster transfer speeds (more bandwidth) mean that an SSD can move more data faster—its throughput is higher.
Even just halving the latency of a spinning disk (and SSDs typically do far more than that) provides an incredible subjective improvement to the computing experience. Looking at the higher tiers in the memory hierarchy, it's easy to see why. If, for example, a sudden breakthrough in RAM design decreased the effective latency to and from a system's RAM by a factor of 10x, then calls to and from RAM would drop from a best case of 60ns to 6ns. Definitely impressive, but when looked at in terms of the total delay during an I/O operation from CPU to RAM to disk, there's still so much time spent waiting for the disk that it's an insignificant change. On the other hand, cutting the disk's effective latency from 5-10 milliseconds for a random read to less than a single millisecond for a random read—because any block of an SSD is always as readable as any other block, without having to position heads and wait for the platter to spin—you've just knocked out a tremendous percentage of the total amount of time that entire "CPU to RAM to disk" operation takes. In other words, the speed increases provided by an SSD are targeted right at the longest chain in the memory hierarchy.
Now, a solid-state drive isn't going to always be faster than a spinning hard disk. You can define and run benchmarks which highlight a hard disk's advantages over an SSD; a synthetic benchmark that repeatedly writes and rewrites data blocks on a full SSD without giving the SSD time to perform garbage collection and cleaning can overwhelm the SSD controller's ability to manage free blocks and can lead to low observed performance, for example (we'll get into what garbage collection is and why it's important in just a bit).
But in everyday use in the real world, when performing under an organic workload, there are almost no areas where simply having an SSD doesn't make the entire computer seem much faster.
So how does an SSD actually work? Let's take a peek inside.
Inside the box
Unlike spinning hard disks, which read and write data magnetically, an SSD reads and writes to a medium called NAND flash memory. Flash memory is non-volatile, which means that it doesn't lose its contents when it loses power like the DRAM used in your computer's memory does. It's the same stuff that lives inside your smartphones, mp3 players, and little USB thumb drives, and it comes from the same assembly lines. What makes an SSD so much faster than a thumb drive is a combination of how the NAND chips are addressed, and the various caching and computing shortcuts that the SSD's built-in controller uses to read and write the data.
"A given amount of storage built out of NAND flash would take up about 60 percent less physical space than the same structure built out of NOR flash."
Flash memory's non-volatility comes from the types of transistors used in its makeup—namely, floating gate transistors. Normal transistors are simple things; they're essentially just electronically controlled switches. Volatile memory, like a computer's RAM, uses a transistor coupled with a capacitor to indicate a zero or a one. The transistor is used to transfer charge to or drain charge from the capacitor, and that charge must be refreshed every few microseconds. A floating gate transistor, on the other hand, is more than just a switch, and doesn't have a needy external capacitor to hold a charge. Rather, a floating gate transistor creates a tiny cage (called the floating gate), and then encourages electrons to migrate into or out of that cage using a particular kind of quantum tunneling effect. The charge those electrons represent is permanently trapped inside the cage, regardless of whether or not the computer it's in is currently drawing power or not.
It's easy to see how a floating gate transistor could form the basis for a storage medium. Each transistor can store a single bit—a "1" if the cell is uncharged, a "0" if it is charged—so just pack a load of them together and there you are. The cells are customarily organized into a grid and then wired up. There are two types of flash memory used for storage today: NOR and NAND. Both have a grid of cells; how they differ is their wiring.
NOR flash
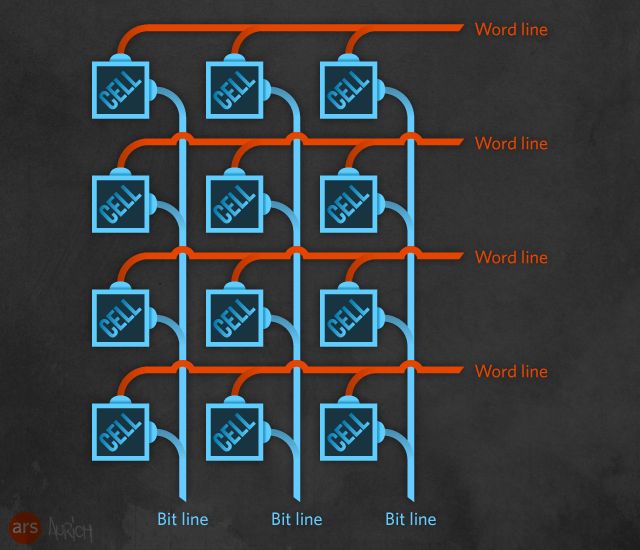
The simplest way to use transistors is to wire each row together and each column together, to allow each individual bit position to be read. This particular layout is used in NOR flash. The circuits connecting each row are called "word lines," while the ones for each column are "bit lines." Read operations are very simple with this arrangement: apply a voltage to each word line, and the bit lines will then show a voltage (or not) depending on whether each cell stores a 0 or a 1. This is similar to how volatile SDRAM is laid out.
To understand how this works in a bit more detail, we have to first understand floating gate transistors. A normal transistor has three connections named, depending on the technology being used, "base, collector, and emitter," or "gate, drain, and source." Floating gate transistors use the second set of terms.
When a voltage is applied to the gate (or the base, in the other kind of transistor), a current can then flow from the source to the drain (or from the collector to the emitter). When low voltages are applied to the gate, the voltage flowing from source to drain varies in proportion to the gate voltage (so a low gate voltage causes a low flow from source to drain, a high voltage causes a high one). When the gate voltage is high enough, the proportional response stops. This allows transistors to be used both as amplifiers (a small signal applied to the gate causes a proportionately larger signal at the source) and as switches (use only a high voltage or a zero voltage at the gate, and there's either a high current or no current between source and drain). (There's a truly excellent video showing how a transistor works in greater detail available on YouTube.)
The floating gate sits between the gate and the rest of the transistor, and it changes the behavior of the gate in an important way. The charge contained in the floating gate portion of the transistor alters the voltage threshold of the transistor. When the gate voltage is above a certain value, known as Vread, and typically around 0.5 V, the switch will always close. When the gate voltage is below this value, the opening of the switch is determined by the floating gate.
If the floating gate has no charge, then a low voltage applied to the gate can still close the switch and allow current to flow from source to drain. If the floating gate does store a charge, then the full Vread voltage needs to be applied to the gate for the current to flow. That is, whether or not the float gate contains a charge changes how much voltage must be applied to the transistor's gate in order for it to conduct or not conduct.
In the grid of cells, the word lines are connected to the transistors' gates. The bit lines are attached to their drains. The sources are connected to a third set of lines, called the source lines. As with the bit lines, all the transistors in the same column have their sources connected together.
We can read the contents of the cell by applying a low voltage to the gates, and seeing if a current flows. Specifically, the word line to which that cell is connected is energized to some voltage below Vread. Current will flow through the cell from the source line to its connected bit line if and only if the cell's float gate contains no charge (a 1). If the float gate contains a charge (a 0), the voltage threshold of the whole cell is too high for the small voltage to overcome. The bit line connected to that cell is then checked for current. If it has a current, it's treated as a logical 1; if it doesn't, it's a logical 0.
This arrangement of transistors is used in NOR flash. The reason it's named NOR is that it resembles a logical NOR—low current on the word line is NOR-ed against the charge in the float gate. If you apply Vread and the float gate has no charge, then the bit line shows charge (0 NOR 0 = 1), whereas the floating gate won't conduct the low read current if it contains a charge (0 NOR 1 = 0).
NOR flash has a big drawback. Though the design is conceptually simple, the chips themselves are quite complex because a big chunk of NOR flash is taken up with all those individual word line and bit line connections—each transistor has to have them and it results in a great deal of connectivity. In some applications where the ability to read and write in single-bit increments is a requirement, NOR flash fits the bill; for replacing hard disk drives, though, we don't need that extreme granularity of access. Hard drives aren't addressable down to the nearest byte; instead, you can only read and write whole sectors (traditionally 512 but increasingly 4096 bytes) at a time.
NAND flash
So on to a new arrangement, one that reduces all those connecting wires. Start with the same grid of transistors and the same word lines connecting the gates of each row. However, the connection of the bit lines changes. Each transistor in a column is connected in series, the drain of one feeding in to the source of the next. The first transistor in the column is connected to a regular transistor, the source select, and the source select to the source line. The last transistor in the column is then connected to another regular transistor, the bit line select, and that is connected to the bit line. The source select transistors and bit line select transistors all have their gates tied together, so they conceptually add extra rows above and below the word lines.
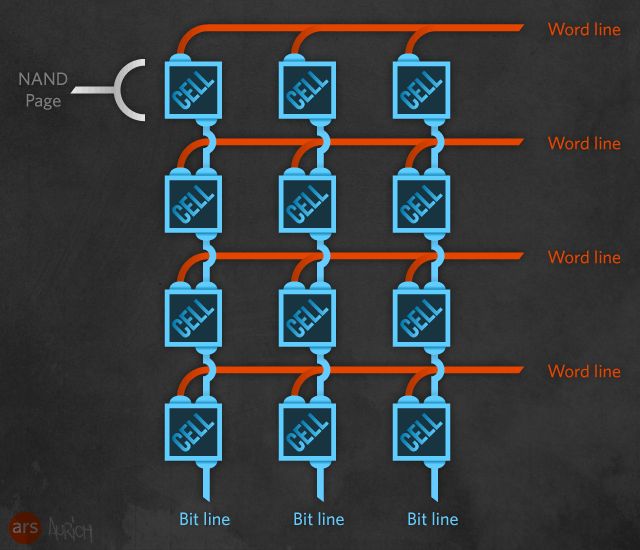
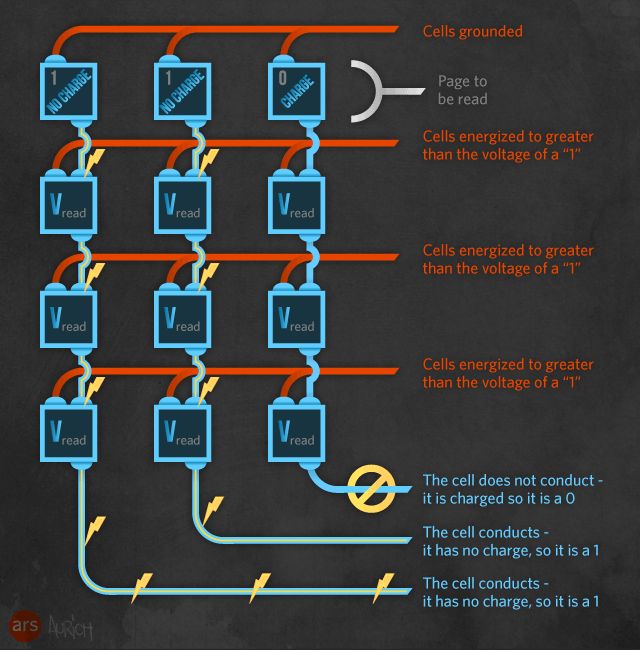
To read an individual bit within the grid, the bit line select and source select transistors are both turned on. Then, all the word lines that you're not reading have Vread applied to them, forcing the transistors to conduct regardless of whether they have a charge in their floating gates. Only the word line of the bit that you're interested in has the lower voltage applied to it. If that bit has a stored charge (and hence is a logical 0), the transistor will remain open, and no current will flow through the chain of transistors. If it has no stored charge (and hence is a logical 1), the transistor will close, and a current will flow. The presence or absence of a current on the bit line is detected and treated as a 1 or 0, respectively. All the bit lines will deliver a signal simultaneously, in parallel.
A typical flash memory grid has 32 to 256 columns (and hence 32 to 256 bit lines) and 4,096 to 65,536 rows (and hence 4,096 to 65,536 word lines). The total grid is called a block, and each row is called a page (in practice, the pages are a little larger still, to include error-correction and bookkeeping data).
This design is called NAND flash. Again, this is a reference to its similarity to a kind of logic gate, a NAND logic gate, meaning "not and" or "negated and."
Connecting the columns of flash cells to each other in series eliminates a tremendous amount of structure versus NOR flash; a given amount of storage built out of NAND flash would take up about 60 percent less physical space than the same structure built out of NOR flash.
But there's a downside, and that's the lost ability to read and write each bit individually. NAND flash can only read and write data one page—one row—at a time. Contrary to conventional wisdom, there's nothing inherent to the layout of NAND flash that prevents reading and writing from individual cells; rather, in sticking with NAND flash's design goal to be simpler and smaller than NOR flash, the standardized commands that NAND chips can accept and understand are structured such that pages are the smallest addressable unit. This saves on silicon space that would otherwise be needed to hold more instructions and the ability to hold a cell-to-page map.
Now let's put all this memory to use as storage and see how it works.
Reading pages, erasing blocks
We know that a page of NAND flash is physically made up of a row of cells and is the smallest thing that can be read from or written to an SSD, so how much data are we talking about? In a modern SSD with 25 or 20 nm elements, the page size is 8192 bytes. This fits nicely with most modern file systems, which often use cluster sizes of 4096 or 8192 bytes. Since the operating system deals in terms of clusters and the disk itself deals in terms of pages, having these two units of allocation being either the same or convenient multiples of each other helps ensure that the data structures an operating system commits to disk are easily accommodated by the drive's layout.
"The SSD can get slower and slower as it ages."
While SSDs can read and write to individual pages, they cannot overwrite pages. A freshly erased, blank page of NAND flash has no charges stored in any of its floating gates; it stores all 1s. 1s can be turned into 0s at the page level, but it's a one-way process (turning 0s back into 1s is a potentially dangerous operation because it uses high voltages). It's difficult to confine the effect only to the cells that need to be altered; the high voltages can cause changes to adjacent cells. This can be prevented with tunneling inhibition—you apply a very large amount of voltage to all the surrounding cells so that their electrons don't tunnel away along with the targeted cells—but this results in no small amount of stress on the cells being erased. Consequently, in order to avoid corruption and damage, SSDs are only erased in increments of entire blocks, since energy-intensive tunneling inhibition isn't necessary when you're whacking a whole bunch of cells at the same time. (There's a Mafia joke in here somewhere, I'm sure of it.)
Incidentally, while NOR flash allows bit-wise writing, it retains the other constraints: 1s can only be overwritten with 0s, and resetting 0s back to 1s requires erasing whole blocks at a time, again due to the high voltages and risk of damaging adjacent cells if it were performed at a smaller granularity.
The fact that you can read and write in pages but only erase in blocks leads to some odd behavior when compared to traditional storage. A magnetic hard disk can always write wherever it likes and update data "in-place." Flash storage can't. It can (essentially) only write to empty, freshly erased pages.
The most obviously bad side effect of this kind of scheme is that, unless the SSD has an available erased page ready and waiting for data, it can't immediately perform a write. If it has no erased pages, it will have to find a block with unused (but not yet erased) pages, erase the entire block, then write the block's old contents out along with the new page.
This means that the SSD can get slower and slower as it ages. When you pull your shiny new SSD out of the box and plug it in, it's full of erased pages. As you begin copying files to it, it begins busily writing out those files in pages, very quickly, making you happy you purchased it. Hooray! SSDs don't overwrite data, though, so as you change files and delete files and copy new files in, the changed and deleted files aren't actually changed or deleted—the SSD controller leaves them right where they are and writes in the changes and the new files in fresh pages.
In a current-generation SSD with 8192-byte pages, a block can be made up of as many as 256 separate pages, meaning that to write a tiny 8KB file, the SSD must actually first copy two whole megabytes of data into cache, then erase the whole block, then re-write most or all of the entire 2 MB. It obviously takes longer to read, erase, and rewrite 2MB than to simply write 8KB, and early generation solid-state drives developed a reputation for "getting slower" as they aged, precisely because they ran out of free pages and had to resort to these Tetris-like shenanigans when doing any writing. The SSD is constantly worrying about these things and doing everything it can to fix them; we'll get deep into how this works in just a few more sections.
MLC, easy as 1-2-3
Floating gate transistors, with their ability to store a little bit of charge, provide the core storage mechanism for flash. But they're a little more subtle than we previously described. They don't just store some charge or no charge: they can store a variable amount of charge. And this charge can be detected, because the more charge they store, the more voltage is needed to make them switch.
This gives rise to another dichotomy in flash storage: MLC and SLC, which stand for "Multi-Level Cell" and "Single-Level Cell," respectively. The "single" and "multi" refer to the number of different charge levels an individual cell can store. With only a single charge level, a cell can only contain one bit; it either has a stored charge or it doesn't. But with four levels, a cell will have one charge level, and hence one voltage threshold corresponding to 11, another for 10, a third for 01, and a fourth for 00—a total of two bits of storage. With eight levels, it could store three bits.
The use of multiple threshold voltages makes reading more complex. To determine which charge level is stored, a couple of schemes are possible. The flash system can test each possible threshold voltage in turn, to see which one is enough to make the transistor turn on. Alternatively, it can measure the current coming from the cell and compare this to known reference. Both SLC flash, with one charge level per cell, and MLC flash, with several, are widely used.
SLC cells are more reliable and less complex with a commensurately lower error rate because less can go wrong. They are also faster, because it's easier to read and write a single charge value to a cell than it is to play games with voltages to read one of several, and the cells can experience more write cycles before they go bad. This combination of greater reliability and greater cost means that today you usually find SLC solid-state drives in enterprise applications, running in large servers or even larger arrays. A common SLC SSD in the enterprise is the STEC ZeusIOPS, a 3.5" form factor SSD which usually comes with a Fibre Channel or SAS bus connector and which you'd find in something like this. Don't expect to be using this kind of drive at home; even if you happen to have a computer that can use SAS drives, street price on a SAS-flavored 200GB ZeusIOPS is at least $3,000 USD. The Fibre Channel variants cost considerably more.
MLC drives can store more information in the same number of cells. Two bits, with four discrete voltage thresholds per floating gate, are common for today's consumer and enterprise drives, and floating gates with eight levels/three bits are in the works. This increase in storage density brings with it an increase in complexity and write cycles, which in turn brings an increase in error rates and a decrease in how long each flash cell lasts before dying. However, the cost of MLC drives is fractional compared to SLC drives, and so in the consumer space, this is what we buy to put in our computers because this is what is affordable. Practically every consumer solid-state drive sold today is MLC; there are a number of "enterprise" MLC SSDs (like the Samsung SM825) which aim to provide a higher degree of reliability and longevity than standard MLC SSDs without as much of an SLC price premium.
Wait a second, though—"before dying"? "Longevity"? That sounds... somewhat ominous. And indeed, it can be.
The inevitability of entropy
For all its speed and awesomeness, flash has one big and hairy problem: it can only be used for a finite number of writes. This limitation has led to SSD controller manufacturers implementing an amazing array of workarounds, all geared toward prolonging the life of the flash cells. However, many of the tricks employed by SSD controllers to make them work well as fast random access storage are directly at odds with prolonging cell life, often putting the twin goals of quick storage and long life into an uneasy compromise.
We noted earlier that bits in a flash cell are read by varying the voltages on rows and columns of cells and then measuring the results, but we didn't get into how data is programmed into a NAND flash cell to begin with. Data can only be written to one page—one row of cells—at a time in NAND flash. Briefly, the SSD controller locates an empty page that is ready to be programmed, and then alters the voltage for that row (with the word line) to a high level and grounds the bit lines for each of the columns that need to be changed from a 1 (the default state, containing little or no charge) to 0 (charged). This causes a quantum tunneling effect to occur wherein electrons migrate into the cell and alter its charge. Kerzap!
At some point, charged cells need to be erased and returned to their default state so they can be reused to hold other data, so when it's necessary to do so or when the SSD has free time, blocks of cells undergo an erasure cycle that removes the charge from the cells. However, each time the cells go through a program/erase cycle, some charge is trapped in the dielectric layer of material that makes up the floating gates; this trapped charge changes the resistance of gates. As the resistance changes, the amount of current required to change a gate's state increases and the gate takes longer to flip. Over time, this change in resistance becomes significant enough that the amount of voltage required to write a 0 into the cell becomes so high, and the amount of time it takes for the cell to change becomes so long, that the cell becomes worthless as a component of a fast data storage device—SSDs stripe data across multiple blocks, and so the cells all need to have roughly identical write characteristics.
This degradation doesn't affect the ability to read data from an SSD, since reading is a mostly passive operation that involves checking the existing voltage in targeted cells. This behavior has long been observed on older and well-used USB thumb drives, which slowly "rot" into a read-only state. SSDs undergo the same type of degradation, and it's the job of the SSD controller to keep tabs on the write count of every cell and mark cells as unusable when they begin to degrade past the point of usability.
It turns out that even reading will slowly degrade NAND flash, and flash systems can be forced to eventually rewrite data after it's been read too many times. Fortunately, this effect seems less significant in practice than it sounds in theory.
MLC SSDs are much more susceptible to degradation than SLC SSDs, because each cell in an MLC drive has four possible states and stores two bits, and so each is more sensitive to changes in residual charge or difficulties adding new charge. Additionally, flash cells are continually decreasing in size as we push further and further down the semiconductor process size roadmap. The latest drop from a 25-nanometer to a 20-nanometer process—with the number referring to half of the typical distance between the individual cells—has also decreased the number of program/erase cycles the cells can endure, because they are physically smaller and can absorb less residual charge before they become too unresponsive to be useful. Progress gives—and progress takes away.

The specter of limited cell life looms over all NAND-based solid-state storage, but it's not necessarily a specter that most folks need worry about. The good news is that even the reduced number of program/erase cycles that a current-generation MLC SSD can bear are more than enough for most consumers. A solid-state drive purchased today should yield at least as much life as a spinning disk; because of the inevitable march of disk capacity, the majority of hard disk drives in consumer computers don't see much of a useful service life past five years, and numerous synthetic benchmarks give current-generation consumer SSDs at least 5 years of flawless service before any type of degradation sets in. Enterprise solid-state drives are a different matter, though—disks of any type in an enterprise setting are subjected to much tougher workloads than consumer disks, which is one major reason not to use consumer SSDs in the data center. Enterprise-grade SSDs, even ones based on MLC, are built to yield a much longer service life under much more stressful conditions than consumer drives.
More than a thumb drive to me
To make an SSD, you can't just plug a bare flash chip into your PC; the chip needs a controller of some kind. All flash controllers have to handle some of the same management of pages and blocks and the complexities of writing, but the controllers used in SSDs go much further than that.
On one hand, an SSD does look sort of like a big fat thumb drive in that the flash memory is of the same type as you'd find in a typical USB memory stick. However, there are obviously observable differences in speed—even a smoking fast USB memory stick isn't particularly fast when compared to a SATA 3 solid-state drive, which can read and write data at half a gigabyte per second. This type of speed is accomplished by writing to more than one flash chip at a time.
The SSD's controller—a processor that provides the interface between the SSD and the computer and that handles all of the decisions about what gets written to which NAND chips and how—has multiple channels it can use to address its attached NAND chips. In a method similar to traditional multi-hard disk RAID, the SSD controller writes and reads data in stripes across the different NAND chips in the drive. In effect, the single solid-state drive is treated like a RAID array of NAND.
Briefly, RAID—which stands for Redundant Array of Inexpensive Disks (anyone who says the "I" stands for "Independent" needs to learn about RAID 0 data recovery)—is a method long employed with hard disks to increase the availability of data (by putting data blocks on more than one disk) and the speed (by reading and writing from and to multiple disks at the same time). The most common form of RAID seen today in large storage scenarios is RAID 5, which combines striping—drawing a "stripe" of data across multiple disks—with some parity calculations. If a single disk in the RAID 5 array dies, everything on it can be recovered from the remaining disks in the array. For a more in-depth look at how RAID works and the different types of RAID, check out the classic Ars feature The Skinny on Raid.
At minimum, every SSD controller in every drive on the market today provides at least basic data striping with basic error correction, using that extra space in each page. Most controller manufacturers augment that with their own fancy proprietary striping schemes, which also typically include some level of parity-based data protection. Micron calls theirs RAIN, for Redundant Array of Independent NAND, which offers several different levels of striping and parity protection; LSI/SandForce calls its method RAISE, for "Redundant Array of Independent Silicon Elements," and provides enough data protection that the drive could continue operating even if an entire NAND chip goes bad.

Still, sometimes even streaming across multiple I/O channels to multiple NAND chips isn't enough to keep up with the data coming in across the bus that the computer expects the SSD to accept, so quite a few consumer SSDs contain some amount of DDR2 or DDR3 SDRAM, usually between 128 and 512 MB. Having a chunk of cache sitting there lets the SSD quickly receive data that it needs to write, even if it's too busy to actually write it at the moment; the data sits in the SDRAM cache until the controller is able to find time to send it down and actually commit it to NAND. All this happens transparently to the computer and you, the end user—regardless of whether or not the data has actually been written, the SSD controller reports back to the operating system that the write was completed successfully.
This greatly decreases the effective latency and increases the throughput of the SSD, but there's an obvious problem. The SDRAM in an SSD's cache is the same kind of SDRAM used for main memory—the kind that erases itself if it loses power. If the computer were to suffer a power loss while the SSD has data in cache that hasn't yet been committed to NAND, then that data would be completely gone, with consequences that could range from annoying to catastrophic. The most common consequence of a loss of uncommitted write cache would be file system corruption, which might or might not be repairable with a chkdsk or fsck; depending on what was being held in cache, the entire file system on the SSD could be unrecoverable.
This is obviously a bad thing, and most SSD manufacturers who bolster their drives' performance with a large SDRAM cache also include some mechanism to supply power to the SSD long enough to dump its cache contents out to NAND, usually in the form of a large capacitor. Whatever the mechanism, it only needs to provide the drive with power for a short amount of time, since it doesn't take terribly long to write out even a full 512MB of data to an SSD. However, not every SDRAM-cached SSD has a set of cache-powering capacitors—some have nothing at all, so be aware of the specs when picking one out. Most have something, though, and the speed benefits of stuffing some RAM into an SSD more than balance out the risks, which are quite manageable.
As an aside, it's difficult to find an SSD in the enterprise space that doesn't use SDRAM caching, but enterprise SSD manufacturers can count on the drives being used in, well, an enterprise—which usually means that they're in a server or storage array in a data center with redundant UPS-backed power. On top of that, most enterprise disk arrays like those from companies like EMC, NetApp, IBM, and Hitachi have built-in independent battery units designed to keep their disks spinning long enough to perform a complete array-wide de-stage of cache, which can take a while because those kinds of systems can have a terabyte or more of SDRAM set aside just for cache.
Tricks of the trade
In addition to handling the basic page management, striping, error-correction, and caching, SSD controllers also have to work to keep on top of flash's twin problems: block-level erasure, and finite lifetimes. There are several things that SSD manufacturers do these days to ensure that their drives remain quick throughout their entire life.
The first is over-provisioning, which simply means stuffing more NAND into a drive than it says on the box. Over-provisioning is done on most consumer SSDs today and on all enterprise SSDs, with the amount varying depending on the type and model of drive. Consumer SSDs that list "120 GB" of capacity generally have 128GB of actual NAND inside, for example; over-provisioning in the enterprise space is generally much larger, with some drives having as much as 100% additional capacity inside. Over-provisioning provides some breathing room so that there can potentially be free pages available to receive writes even if the drive is nearing capacity; additionally, in the event that some cells wear out prematurely or go bad, over-provisioning means that those bad cells can be permanently marked as unusable without a visible decrease in the drive's capacity. It's also possible to emulate the beneficial effects of over-provisioning by simply using less than the stated capacity of an SSD—for example, by purchasing a 90GB SSD, creating a 30GB partition, and leaving the rest unallocated. The controller itself doesn't care about the logical constructs built by the operating system—it will happily continue to write to new fresh pages as long as they're available.
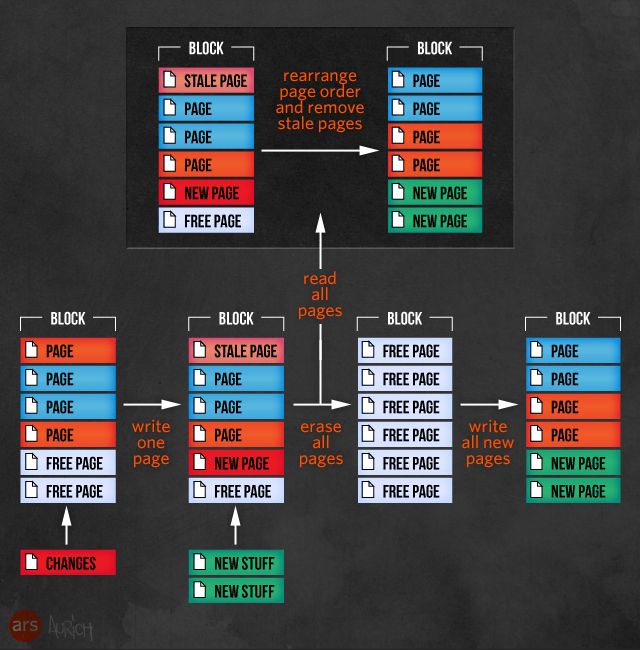
Garbage collection is another technique—or collection of techniques—to keep SSDs fast and fresh. As the contents of pages are modified—or more correctly as those pages are rewritten as new pages, since you can't overwrite pages—the SSD keeps track of which pages contain good data and which contain stale data. Those stale pages aren't doing anyone any good just sitting there, but they also can't be individually erased, so when the SSD controller has an opportune moment, it will garbage-collect those pages—that is, it will take an entire block that contains both good and stale pages, copy the good pages to a different block, and then erase the entire first block.
Garbage collection can be augmented with TRIM, which is a specific command that the operating system can send to an SSD to indicate that pages no longer contain valid data. SSDs know when pages need to be modified, but they have no understanding of when pages are deleted, because no modern operating systems really delete files. When Windows or OS X or your Linux distro of choice "deletes" a file, it simply adds a note in the file system saying that the clusters that make up that file are free for use again. Unfortunately for an SSD, none of that information is visible down at the level the SSD operates—the drive doesn't know what operating system or file system is in use. All it understands are pages and blocks, not clusters and files. Deleting files doesn't free up that file's pages to be ignored by garbage collection, which can lead to the unfortunate circumstance where a drive's garbage collection routines are gathering and moving pages that contain "data" that the file system has deleted, and so cannot access anyway. TRIM lets the operating system pass a note down to the SSD saying that a set of pages taken up by a deleted file can be considered stale, and don't have to be relocated along with good data. This can greatly increase the amount of free working space on your SSD, especially if you're regularly deleting large numbers of files.
Exactly when and how often an SSD goes in and performs garbage collection varies according to the controller and its firmware. At first glance, it would seem desirable to have a drive constantly performing garbage collection at a lower priority than user-driven IO; indeed, some SSDs do this, ensuring that there's always a big pool of free pages. However, things are never that simple in SSD land. Constant garbage collection can have significant implications for the life of the SSD, when compared against a less-aggressive garbage collection that strives to maintain a minimum amount of free pages. This is where write amplification comes into play.
Big bad write amplification
Write amplification sounds kind of awesome—like my data has been turned up to 11 and is ready to melt faces—but write amplification is actually a Very Bad Thing.
Write amplification refers to the difference between the amount of data "logically" written to an SSD (that is, the amount sent by the operating system to be written) and the amount actually written to the SSD (after garbage collection, block erasure, and so on are taken into consideration). It's usually expressed as a factor—so a write amplification of 2 means that committing 128KB of data to a drive results in 256KB of data written to the flash, on average. Because every flash cell can only perform a finite number of state changes across its lifetime, each write is ultimately a destructive operation. You want to limit the number of writes so that the drive can live longer.
SSDs are constantly moving stuff around, so the write amplification of a solid-state drive is never 1—your 128KB of data never results in just 128KB of writes, on average. Garbage collection is one potential aggravator of an SSD's write amplification factor in that more aggressive garbage collection generates more writes. If a drive is striving to always have the maximum possible amount of free space and is being aided by TRIM, it could perform a tremendous number of writes without user input, resulting in a high write amplification and corresponding reduction in the life of the drive's cells.
Wear leveling is another big factor behind a drive's write amplification number. Wear leveling refers to the bag of techniques the SSD uses to keep all of the flash cells at roughly the same level of use. The controller keeps track of which cells are receiving a high number of writes and which cells are sitting relatively idle, and then it rotates the used pages on the SSD around so that the cells hosting static files are swapped with cells holding active files. The goal is to ensure that no particular pages are singled out with more writes, and that all the cells age through their allotted lifespan of writes at roughly the same pace.
Wear leveling is a good thing and an absolute requirement on any flash-based drive, but much like garbage collection it greatly increases write amplification by performing a lot of data movement and truncating the lives of the very cells it tries to save. However, the alternative of not having wear leveling and garbage collection is far worse, so the goal is to find methods of doing both that balance the costs with the benefits.
The write amplification of a drive isn't a constant number and can change drastically as the drive's characteristics change. As free pages disappear, if garbage collection can't keep up with the demand, some or all writes turn into the dreaded read-erase-rewrite; this is extremely costly in terms of write amplification because an entire block of cells must instead be changed. With current-generation SSDs having 128 or 256 8192-byte pages per block, this results in a ridiculous amount of writing that must be done even for tiny changes. In the extreme case, updating even a single bit could result in a whole 2MB block being rewritten, an amplification factor of 16.8 million.
The developers of SSDs and their controllers have to balance the various problems with flash memory, and the different trade-offs they make (a lot of over-provisioning or barely any, MLC or SLC, aggressive garbage collection or not) all have an impact on the cost, performance, and longevity of the drives.
No company has a perfect solution, but one company, SandForce (purchased earlier this year by LSI), has taken a slightly different route with its controllers than others.
The road less traveled
Instead of a large pool of DRAM cache to hold incoming data until there's time and bandwidth to write the whole mess to flash, the SandForce SSD controllers instead attempt to reduce the amount of incoming data to a manageable level and then write that out to flash.
This is done by a combination of compression and block-level deduplication, and LSI is currently the only SSD controller manufacturer using this method. LSI calls its data-reducing technology "DuraWrite," which is part of its DuraClass technology suite. Unfortunately, non-marketing information about exactly what DuraWrite does is relatively difficult to come by. In a response to some criticisms of its technology, SandForce (pre-LSI acquisition) included this bit of information:
SandForce employs a feature called DuraWrite which enables flash memory to last longer through innovative patent pending techniques. Although SandForce has not disclosed the specific operation of DuraWrite and its 100% lossless write reduction techniques, the concept of deduplication, compression, and data differencing is certainly related.
SandForce brought a patent portfolio along with it when it was acquired by LSI, and we can dip toes into those documents to make some inferences. Although the response quoted above is from June 2011 and refers to "patent pending" techniques, there are several obviously relevant filings, including US7904619, System, Method, and Computer Program Product for Reducing Memory Write Operations Using Difference Information, issued in March 2011, and Techniques for Reducing Memory Write Operations Using Coalescing Memory, filed in March 2011 but not yet granted as of this feature's publication. The patents share a great deal of text and diagrams and are obviously complementary. They're vague on exact implementation details, as expected from documents describing general techniques and methods, but together describe a block-level deduplication scheme where incoming chunks of data to a storage medium are examined to see if they are different from the data already on the storage medium, and only the unique portions are sent on to be held in a small buffer and then written out to the flash. This is the essence of a "pre-process" or "ingest" block-level deduplication scheme, which deals not in files (which, remember, are constructs of the operating system, not something the drive knows anything about) but in the actual data structures on the drive. You'd find the same type of deduplication on, say, an EMC Data Domain backup system.
In addition to a block deduplicate-on-ingest, it has been demonstrated both through benchmarking and also through good old reverse engineering that SandForce controllers apply compression to their incoming data as well. Between the patent filing—assuming DuraWrite is indeed described there—and the reverse engineering, we can paint a rough logical picture of what happens during a write.
A SandForce SSD controller has a small amount of working buffer space instead of a big multi-megabyte pool, and as data comes in off the bus, the controller divides the data up into small pieces and compresses them, using some manner of hardware-assisted lossless algorithm, because speed is critical. The compressed blocks are then checked for their uniqueness—do they already exist somewhere else on the drive? If so, they're discarded. If not, then they're written down onto the NAND medium. The blocks are compressed prior to being written to disk to minimize writes; further, the blocks are compressed before being deduplicated because they must be compared for deduplication against the already-compressed blocks on the drive.
Doing the compression and deduplication at the block level without caring about files means that a tiny change to a large file won't result in the whole file being rewritten; the file will be chopped up into blocks and compressed; most of the file will be unchanged and will result in compressed blocks that are identical to those already on the drive, and those blocks will be discarded. Only a tiny amount of actual change has to be sent down to the drive. Taking it a step further, we're not limited to just single files—blocks that contain identical information between files are also compressed and deduplicated, so the blocks that make up an image file which you've cut and pasted into a dozen different Powerpoint documents won't be written more than once.
There are two obvious pitfalls with all this deduplication and compression business, which we'll only touch on very briefly. The first is that only storing unique pieces of things a single time seems to go against the speed- and availability-enhancing techniques SSDs. If a unique block is only stored once, then how is it protected against NAND failure? The answer is in the form of another patent (System and Method for Providing Data Redundancy After Reducing Memory Writes), which describes portions of LSI-SandForce's previously mentioned RAISE technology and assures us that even though a given block may be unique, a "block" is not an indivisible atomic construct and is still protected by being striped across NAND chips.
The second problem is that if SandForce-powered drives are compressing their data, what happens when they're asked to write data which has already been compressed? The answer to this is that they slow down. The data coming in is still chopped up into blocks and deduplicated, but SandForce-powered SSDs typically aren't as fast when writing compressed files. Fortunately, the difference isn't catastrophic with the latest-generation of SandForce controllers—they still tend to be quicker than their competitors.
Pitfalls aside, what happens to all the extra space you theoretically get with this deduplication and compression? If you take a huge file and copy-and-paste it a thousand times, is the SandForce-powered drive smart enough to not rewrite those non-unique blocks a thousand times, so you get to benefit from having a compressed and deduplicated drive by being able to fit a thousand gigabytes of data onto your 250GB SSD?
In a word, no. The space saved by deduplication and compression is a by-product of the true goals of these technologies in flash-based drives. It's telling that a close reading shows that these and other SandForce-produced patents talk about compression or deduplication not as ends themselves, but rather as means to a single overriding goal: increasing the life of flash memory by reducing write amplification.
The whole package
All of this paints a complex picture of the humble solid-state drive. Though physically it's not much more than some NAND chips and a controller in a familiar form factor, there's a tremendous amount of activity going on under the hood, with the SSD's controller acting like a miniature computer itself and the NAND chips acting like a set of individual hard disk drives in a RAID set. On one hand, an SSD resembles a computer in miniature—it's got a CPU, some RAM, some random access storage, and it runs complex programming. However, the more apt allusion is that the SSD is a pint-sized storage array, doing a lot of the things that the big enterprise data center arrays do, except in miniature—things like deduplication, compression, and rebalancing data to deal with hot spots and wear.
Which raises one last question: SSDs in the consumer space provide an amazing boost in the subjective computing experience, but what are they good for in the enterprise space, where RAID, deduplication, and compression are all de rigueur?
Spending millions
If you look at the websites of enterprise storage companies like EMC, NetApp, and Dell, you'll see that solid-state drives are all over the place in the data center. EMC and Dell both offer enterprise drive arrays that can contain a combination of spinning disk and solid-state disk, and automatically move data between them based on how "hot" the data is; NetApp and EMC offer the ability to use solid-state storage as system-wide cache, greatly improving the IO capability of the whole array.
Any large storage array these days will be attached via Fibre Channel or iSCSI or some other block-level connection to one or more servers, and potentially might also be serving files directly over the network to distributed clients. For an array full of spinning disks, keeping information flowing quickly usually means paying at least nominal attention to how the disks themselves are organized. What capacity disks do you need to use? Do you need large disks to add capacity, or do you need smaller disks because you need the performance boost from having lots of disks share in the workload? What rotational speed should the disks have? What RAID level do you use, both for performance and for redundancy? How many RAID groups do you bind up together into a volume that you can present out to hosts? Do you stripe data across multiple volumes to increase performance? If so, how many?
"In most cases, no other upgrade will provide the same level of subjective improvement as moving from a magnetic disk to an SSD."
SSDs trade cost per gigabyte for almost universally increased performance, and the traditional balancing act of adding disks for storage capacity versus adding disks for their I/O bandwidth becomes quite a bit less important. The "slowest" current-generation enterprise-grade SSD you could purchase today is many times faster under almost every workload than even the fastest 15,000 RPM Fibre Channel spinning disk. The same thing that makes them shine as latency-crushing devices in the consumer world also comes through here—a random read and write latency graph that remains roughly flat even as the drive's workload increases. Compare that against an enterprise Fibre Channel or SAS drive struggling to service IO as things get busy, and watch the latency climb as the disk's queue fills.
Another often-overlooked issue is that large storage arrays are almost inevitably sold with three to five years of prepaid maintenance included, so SSDs in large storage arrays are effectively immune to any wear-related issues, because even if the I/O is at such a constant high level that the NAND chips begin to approach their write cycle limits, the vendors will simply replace the drives. Drive-level RAID or mirroring will rebuild the data structures stored on the replaced drives and things continue on with minimal downtime.
Talking about storage arrays is fun, but the arrays usually come at significant cost. It's not every company that can afford to drop a million dollars on a FAS6000-series or a Symmetrix VMAX and a petabyte of Fibre Channel disks and SSD. However, solid-state drives have their place all across the data center, not just in SAN arrays. Realistically, any task that performs a lot of I/O operations and is affected by latency benefits hugely from being migrated to a solid-state drive. Databases, particularly ones with a high transaction rate and which generate tremendous log files, are the most obvious candidates. Every single database alteration produces a large amount of I/O activity to both the database itself and also to the transaction logs, and every single one of those operations brings with it a certain amount of latency. The raw bandwidth of the drive doesn't matter in this case—with a spinning disk, you're waiting on the drive's heads to swing where they need to be and the disk platter to rotate under the heads. Those tiny latencies add up, and putting a database and its log files onto SSDs can provide a fast and near-total fix for database performance issues.
There are obviously still times when spinning disk makes sense, because SSDs come at a significant dollars-per-gigabyte premium over spinning disk, sometimes as much as 1000 percent. A RAID10 array of four fast spinning disks could meet or beat a single enterprise SSD's throughput under many circumstances, and sometimes that might be the right choice.
Finally, "solid-state drive" doesn't always have to look like a disk. A lot of the compromises about current SSD designs, especially in the enterprise, have to do with taking a technology that is fundamentally different from spinning disk and packaging it up so that it looks, walks, talks, and smells just like a SATA or SCSI spinning disk. SSDs have the same connectors and transfer data over the same cables and busses as regular disks; the operating systems of attached hosts see them and treat them as disks (with TRIM support being the only exception).
Fusion-io takes somewhat of a different approach, and instead of providing disk-like SSDs that you put in arrays or servers, it is packaging its NAND flash products on PCIe cards, skipping the host's SATA or SCSI bus entirely. Fusion-io cards are designed to be extremely low-latency by eliminating many of the IO components separating a host's CPU and its storage. Rather than simply giving you a regular disk, Fusion-io cards can be managed as block devices (like a standard SSD) or can also be used as cache to augment existing storage.
There's also another area of solid-state that we haven't touched on. For this entire article, the only type of solid-state storage we've focused on has been NAND flash. However, Texas Memory Systems sells a line of rack-mount appliances filled to the brim with something even lower-latency and faster than NAND flash: DRAM. An all-DRAM storage array is something that you'd deploy where latency absolutely must be as close to zero as possible (Texas Memory Systems lists "critical financial exchange, securities trading, and bank applications" as their largest deployed areas). Cost per usable gigabyte is usually quite high, but when the requirements dictate near-zero latency, this is the kind of thing you'd use.
Few downsides
Should you buy a solid-state drive today? It's hard to say no. In the consumer space, the prices continue to drop, with some models available at or below that magical USD $1 per gigabyte price point which seems to demarcate the emotional line between "Why the hell is this so expensive?" and "ONE CLICK PURCHASE, YO." We've all got 3D accelerators these days, and in most cases, no other upgrade will provide the same level of subjective improvement as moving from a magnetic disk to an SSD. Just about every task you do with your home computer involves random access storage, and SSDs make exactly that tier of the memory hierarchy both faster and more responsive.
Lee would like to extend a special thanks to our Microsoft Editor, Peter Bright, for technical assistance concerning NOR and NAND flash reads/writes.