DeepLearning.ai笔记:(5-3) -- 序列模型和注意力机制
title: ‘DeepLearning.ai笔记:(5-3) – 序列模型和注意力机制’
id: dl-ai-5-3
tags:
- dl.ai
categories: - AI
- Deep Learning
date: 2018-10-18 18:39:10

基础模型
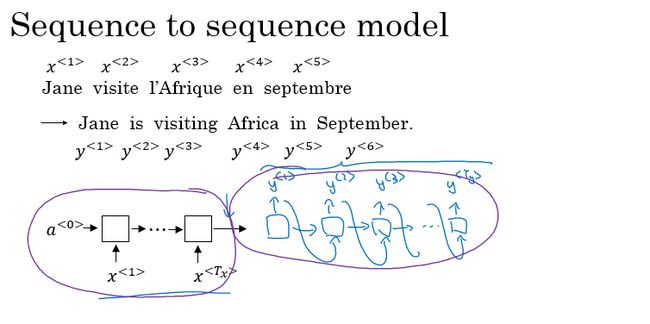
sequence to sequence 模型:
sequence to sequence 模型最为常见的就是机器翻译,假如这里我们要将法语翻译成英文。
对于机器翻译的序列对序列模型,如果我们拥有大量的句子语料,则可以得到一个很有效的机器翻译模型。模型的前部分使用一个编码网络来对输入的法语句子进行编码,后半部分则使用一个解码网络来生成对应的英文翻译。网络结构如下图所示:
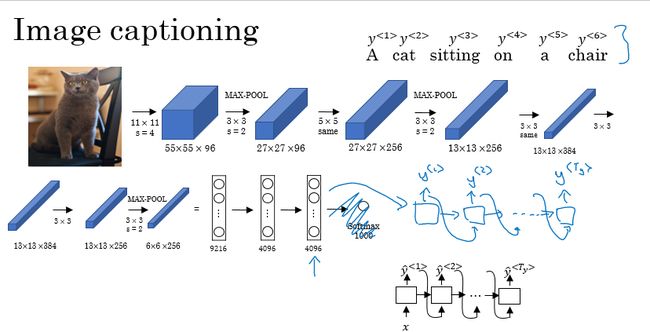
还有输入图像,输出描述图片的句子的:
挑选最可能的句子
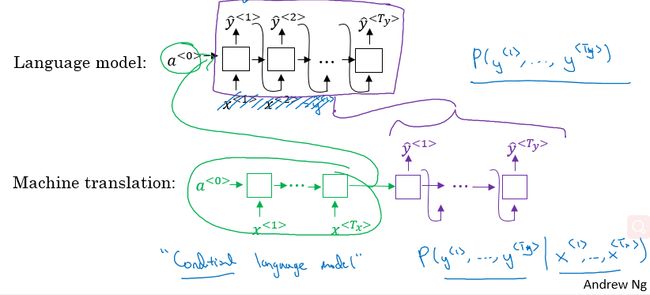
机器翻译:条件语言模型
对于机器翻译来说和之前几节介绍的语言模型有很大的相似性但也有不同之处。
在语言模型中,我们通过估计句子的可能性,来生成新的句子。语言模型总是以零向量开始,也就是其第一个时间步的输入可以直接为零向量;
在机器翻译中,包含了编码网络和解码网络,其中解码网络的结构与语言模型的结构是相似的。机器翻译以句子中每个单词的一系列向量作为输入,所以相比语言模型来说,机器翻译可以称作条件语言模型,其输出的句子概率是相对于输入的条件概率。
集束搜索(Beam search)
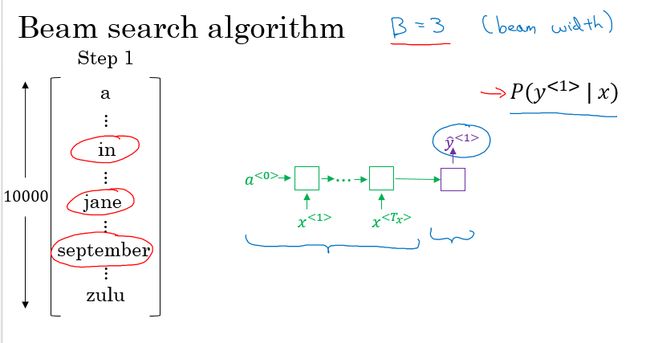
Beam search 算法:
这里我们还是以法语翻译成英语的机器翻译为例:
-
Step 1:对于我们的词汇表,我们将法语句子输入到编码网络中得到句子的编码,通过一个softmax层计算各个单词(词汇表中的所有单词)输出的概率值,通过设置集束宽度(beam width)的大小如3,我们则取前3个最大输出概率的单词,并保存起来。
-
Step 2:在第一步中得到的集束宽度的单词数,我们分别对第一步得到的每一个单词计算其与单词表中的所有单词组成词对的概率。并与第一步的概率相乘,得到第一和第二两个词对的概率。有3×10000个选择,(这里假设词汇表有10000个单词),最后再通过beam width大小选择前3个概率最大的输出对;

- Step 3~Step T:与Step2的过程是相似的,直到遇到句尾符号结束。

集束搜索的改进
上面的集束搜索有个问题,就是因为每一项的概率都很小,所以句子越长,概率越小,因此会倾向于选择比较短的句子,这样是不太好的。
首先,为了保证不会太小而导致数值下溢,先取对数,把连乘变成求和。
然后在前面加上一个系数
1 T y α \frac{1}{T_{y}^{\alpha}} Tyα1
当 α \alpha α 为 1 时,就表示概率为句子长度的平均;为0时,就表示没有系数;在这里一般取 α = 0.7 \alpha = 0.7 α=0.7
集束搜索讨论:
Beam width:B的选择,B越大考虑的情况越多,但是所需要进行的计算量也就相应的越大。在常见的产品系统中,一般设置B = 10,而更大的值(如100,1000,…)则需要对应用的领域和场景进行选择。
相比于算法范畴中的搜索算法像BFS或者DFS这些精确的搜索算法,Beam Search 算法运行的速度很快,但是不能保证找到目标准确的最大值。
集束搜索的误差分析
集束搜索算法是一种近似搜索算法,也被称为启发式搜索算法。而不是一种精确的搜索。
如果我们的集束搜素算法出现错误了要怎么办呢?如何确定是算法出现了错误还是模型出现了错误呢?此时集束搜索算法的误差分析就显示出了作用。
模型分为两个部分:
- RNN 部分:编码网络 + 解码网络
- Beam Search 部分:选取最大的几个值
误差分析
计算人类翻译的概率P(y∗|x)以及模型翻译的概率P(ŷ |x)
-
P(y∗|x) > P(ŷ |x):Beam search算法选择了ŷ ,但是y∗ 却得到了更高的概率,所以Beam search 算法出错了;
-
P(y∗|x) <= P(ŷ |x) 的情况:翻译结果y∗相比ŷ 要更好,但是RNN模型却预测P(y∗|x)
Bleu 得分(选修)
PASS
注意力模型直观理解
之前我们的翻译模型分为编码网络和解码网络,先记忆整个句子再翻译,这对于较短的句子效果不错,但是对于很长的句子,翻译结果就会变差。
回想当我们人类翻译长句子时,都是一部分一部分的翻译,翻译每个部分的时候也会顾及到该部分周围上下文对其的影响。同理,引入注意力机制,一部分一部分的翻译,每次翻译时给该部分及上下文不同的注意力权重以及已经译出的部分,直至翻译出整个句子。
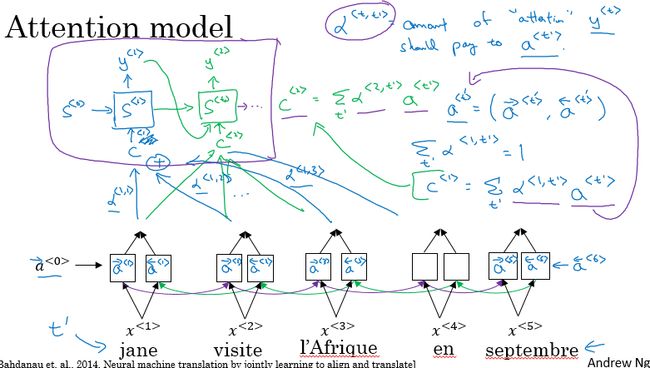
注意力模型
以一个双向的RNN模型来对法语进行翻译,得到相应的英语句子。其中的每个RNN单元均是LSTM或者GRU单元。
对于双向RNN,通过前向和后向的传播,可以得到每个时间步的前向激活值和反向激活值,我们用一个符号来表示前向和反向激活值的组合。
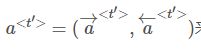
然后得到每个输入单词的注意力权重:
![]()
计算公式为:
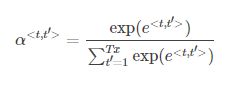
这里的KaTeX parse error: Expected '}', got '\>' at position 17: …^{

语音识别
语音识别就是将一段音频转化为相应文本。
之前用音位来识别,现在 end-to-end 模型中已经不需要音位了,但是需要大量的数据常见的语音数据大小为300h、3000h或者更大。
注意力模型的语音识别
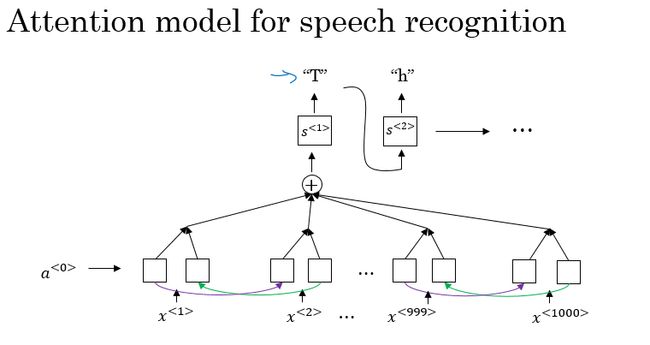
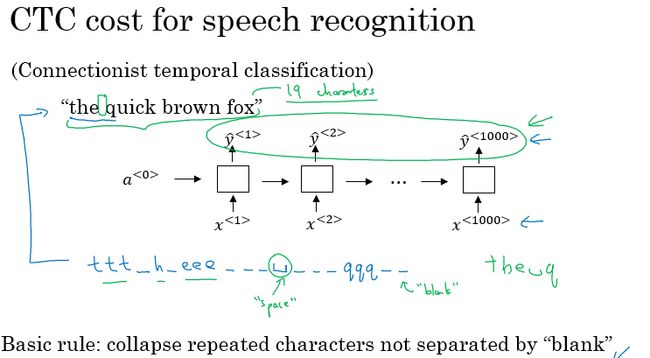
CTC 损失函数的语音识别
另外一种效果较好的就是使用CTC损失函数的语音识别模型(CTC,Connectionist temporal classification)
模型会有很多个输入和输出,对于一个10s的语音片段,我们就能够得到1000个特征的输入片段,而往往我们的输出仅仅是几个单词。
在CTC损失函数中,允许RNN模型输出有重复的字符和插入空白符的方式,强制使得我们的输出和输入的大小保持一致。
触发字检测
触发字检测:关键词语音唤醒。
一种可以简单应用的触发字检测算法,就是使用RNN模型,将音频信号进行声谱图转化得到图像特征或者使用音频特征,输入到RNN中作为我们的输入。而输出的标签,我们可以以触发字前的输出都标记为0,触发字后的输出则标记为1。
一种简单应用的触发字检测算法,就是使用RNN模型,将音频信号进行声谱图转化音频特征,输入到RNN中作为我们的输入。而输出的标签,非触发字的输出都标记为0,触发字的输出则标记为1。
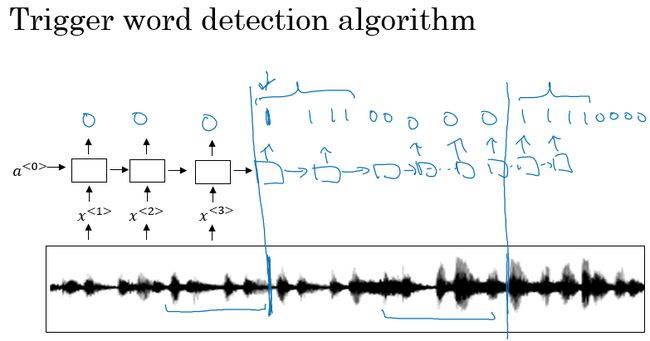
上面方法的缺点就是0、1标签的不均衡,0比1多很多。一种简单粗暴的方法就是在触发字及其之后多个目标标签都标记为1,在一定程度上可以提高系统的精确度。