大数据学习——TensorFlow学习笔记1—keras、梯度下降算法、多层感知器
一、tensorflow的特点与概述《TENSORFLOW ROADMAP》
1、What’s the point of this open source project?
The point of this repository is that the resources are being targeted. The organization of the resources is such that the user can easily find the things he/she is looking for. If someone knows what is being located, it is very easy to find the most related resources. Even if someone doesn’t know what to look for, in the beginning, the general resources have been provided.
这个存储库的要点是资源是有目标的。资源的组织是这样的,用户可以很容易地找到他/她正在寻找的东西。如果有人知道被定位的位置,就很容易找到最相关的资源。即使有人不知道要寻找什么,在一开始,一般的资源已经提供了。
2、How to make the most of this effort?
For finding the most relevant resources, please at first look through the general resources.
为了找到最相关的资源,请首先查看一般的资源。
3、Installation
Installation from the source is recommended because the user can build the desired TensorFlow binary for the specific architecture.
建议从源代码开始安装,因为用户可以为特定的体系结构构建所需的TensorFlow二进制文件。
搭建linux环境,github的TensorFlow入门教程:
https://github.com/machinelearningmindset/TensorFlow-Course
VMware、Ubuntu、python、...
搭建windows环境,哔哩哔哩的TensorFlow2.0入门与实践课程:
https://www.bilibili.com/video/BV1Zt411T7zE
anaconda3、VS2015、TensorFlow-cpu
miniconda3、VS2015、TensorFlow-gpu
二、tf.keras建立线性回归,实现一定的预测功能
1、问题描述
单变量线性回归法(假设x代表学历,f(x)代表收入):
f(x)=ax+b
通过已知数据建立受教育年限x与收入f(x)的预测模型,模型中得出权重a、偏置b则再次输入x时即可预测f(x)的值
2、数据分析
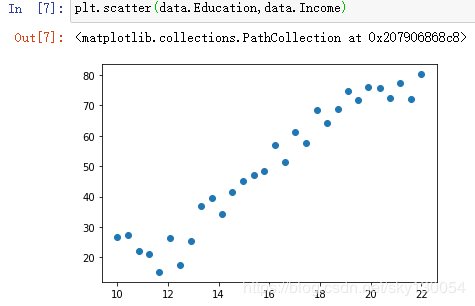
3、建立模型求解权重a、偏置b:
目标:使预测函数f(x)与真实值之间的整体误差最小,即找到合适的权重a、偏置b,使得损失函数均方差z=((f(x)-y)^2)/n越小越好
损失函数:
使用均方差作为成本函数,即预测值和真实值之间的平方取均值z=((f(x)-y)^2)/n
使用梯度下降算法减少loss值
#编译model,使用梯度下降算法对损失函数优化
model.compile(optimizer='adam', #优化方法:adam,沿着梯度下降方向计算变量
loss='mse' #优化目标:损失函数z=((f(x)-y)^2)/n
)
4、tf.keras训练与预测
tf.keras训练一般步骤与执行预测完整代码:

模型预测结果:

输入某受教育年限得出预测收入

三、深度学习核心算法-梯度下降算法原理
梯度下降算法是一种致力于找到函数极值点的算法。所谓"学习”便是改进模型参数,以便通过大量训练步骤将损失最小化。将梯度下降法应用于寻找损失函数的极值点,便构成了依据输入数据的模型学习。
梯度的输出向量表明了在每个位置损失函数增长最快的方向,可将它视为表示了在函数的每个位置向哪个方向移动函数值可以增长。
例:单变量线性函数f(x)=ax+b,损失函数z=((f(x)-y)^2)/n
tf.keras封装的初始化变量操作可随机初始化变量a、b,再计算寻找梯度(即改变a、b的值)使损失函数z变小,寻找z变化最快的方向(即求z导数的大小),沿该方向改变a、b的值以求出损失函数z的最小值。
a、b值改变的大小代表学习速度,学习速度过小导致迭代次数太多,学习速度太大导致z在极值点附近徘徊而达不到极值点,随机初始化变量的条件可排除局部极值点问题。前面代码:'adam'表示默认学习速度0.01
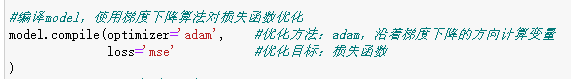
四、多层感知器原理
1、单个神经元
计算输入特征的加权和,然后使用一个激活函数(或传递函数)计算出一个输出值,线性激活则没有激活直接输出。

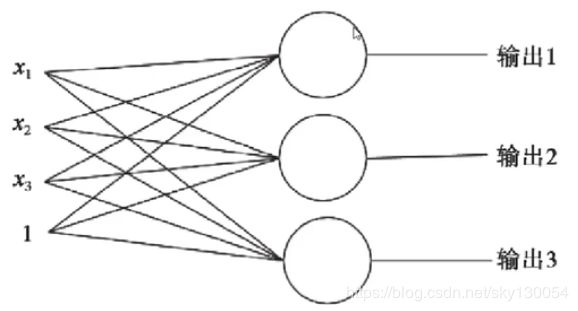
2、单层神经元(多分类)
多个特征*权重,分别输出。
使用单层神经元无法拟合“异或”运算。神经元要求数据必须是线性可分的,异或问题无法找到一条直线分割两个类。

3、多层感知器
生物的神经元一层一层连接起来, 当神经信号达到某一个条件,这个神经元就会激活,然后继续传递信息下去。
为了继续使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入端和输出端之间插入更多的神经元。多层则是多了隐含层,隐含层实际上可以有很多层。

在神经元之间设置激活(信息传递)条件,可拟合出高阶输出、非线性问题、现实世界的丰富问题。
4、激活函数
每个神经元都必须有激活函数。它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性。该函数取所有输入的加权和,进而生成一个输出信号。可以把它看作输入和输出之间的转换。使用适当的激活函数,可以将输出值限定在一个定义的范围内。
relu函数:

sigmoid函数:
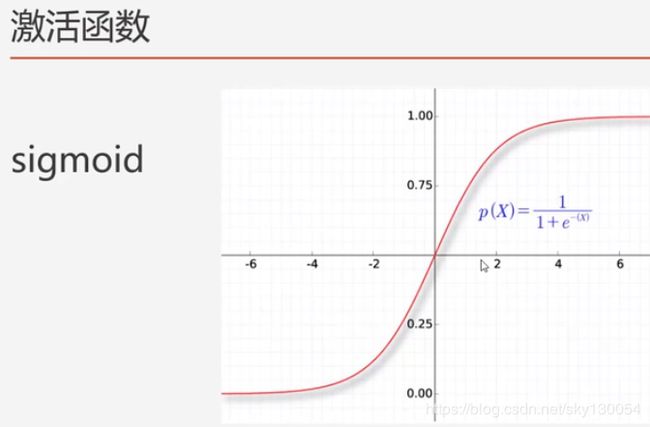
tanh函数:
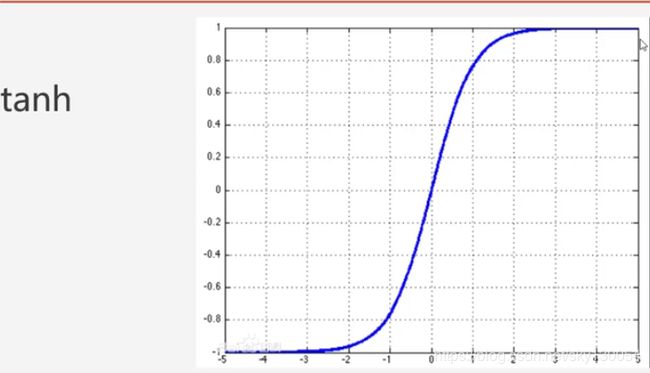
Leak relu函数:
五、多层感知器实现
1、问题描述
将一种广告投放到TV、newspaper、radio上时不同组合的情况会对应不同的销售量。
通过已知数据建立广告投放到TV、newspaper、radio上时不同打广告程度的组合情况与销售量的预测模型,模型中得出三种广告的权重与偏置,则再次输入三种特征值时即可预测销量
2、数据分析
获取广告在Tv、radio、newspaper的投放量与销量的关系数据
广告在TV的投放量与销量的关系图,可观察出为线性关系

广告在radio的投放量与销量的关系图,可观察出同样近似为线性关系
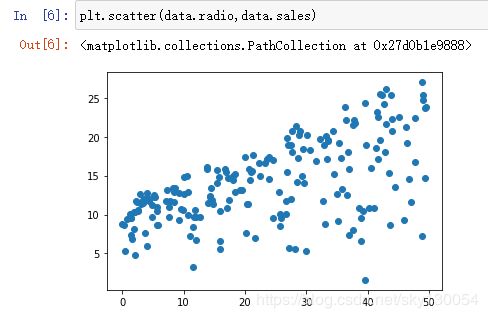
广告在newspaper的投放量与销量的关系图,可观察出线性关系较差

3、建立模型
结合得出的模型框架与上图可找到神经网络原理:
中间层Dense(隐含层)包含10个隐藏单元,中间层Dense输入有40个参数(每个隐藏单元3个输入特征Tv、radio、newspaper与一个偏置参数),中间层Dense输出维度为10,分别是10个隐藏层输出结果。
输出层Dense输入11个参数(十个隐藏单元分别乘权重与一个偏置参数),输出层Dense输出维度为1。
4、训练与预测
配置优化器adam,损失函数同样选择均方差mse,然后开始训练

训练结束后开始预测,用该模型预测自己前10行数据情况下的销售量

输出实际销售量与预测值作对比
代码与数据集链接:https://pan.baidu.com/s/1rW6bPONVvrfGVndAh91nRA 提取码:j4tw