仿京东搜索实战项目—ElasticSearch小demo
仿京东搜索实战项目—ElasticSearch小demo
- 数据——爬虫
- 搜索功能
- 配置ES
- 解析爬取到的数据
- 前后端分离
- 效果展示
- 搜索高亮
- 总结
数据——爬虫
- 数据问题?数据库中获取,消息队列中获取,都可以称为数据源。也可用爬虫解决。(当前只需要少量数据进行测试,所以项目中需先进行数据爬取解析)
爬取数据:
获取请求返回的页面信息,筛选出我们想要的数据就OK。利用jsoup包来对网页元素进行爬取解析!
package com.zzh.utils;
import com.zzh.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
@Component
public class HtmlParseUtils {
// public static void main(String[] args) throws IOException {
// new HtmlParseUtils().parseJD("中国").forEach(System.out::println);
// }
public List<Content> parseJD(String keyword) throws IOException {
//获取请求 网页链接 https://search.jd.com/Search?keyword=java
//前提需要联网, 不能获取到ajax !
String url = "https://search.jd.com/Search?keyword="+keyword;
//解析网页(Jsoup返回Document就是页面Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有在js中可以使用的方法,这里都可以使用。
Element element = document.getElementById("J_goodsList");
//System.out.println(element.html());
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
//获取元素中的内容,这里的el就是每一个li标签!
ArrayList<Content> goodsList = new ArrayList<>();
for (Element el : elements) {
//关于图片特别多的网站,所有的图片都是延迟加载的!通过检察源码分析所需要的元素
//source-data-lazy-img
String img = el.getElementsByTag("img").eq(0).attr("src");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setImg(img);
content.setPrice(price);
content.setTitle(title);
goodsList.add(content);
}
return goodsList;
}
}
搜索功能
配置ES
对ElasticSearchClient简单配置,设置相应的IP及端口。
package com.zzh.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
//1.找对象
//2.放到spring 中待用
//3.如果是SpringBoot就先分析源码
//xxxAutoConfiguration xxxProperties
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
解析爬取到的数据
1.创建数据对应的实体类。
package com.zzh.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
private String title;
private String img;
private String price;
//可以自行扩展属性
}
2.首先在ES中创建一个存储数据的index,然后解析通过上述爬虫爬取到的相应数据,放入我们创建好的ES索引中。
3.获取存储进ES的数据,实现我们基本的搜索功能。
package com.zzh.service;
import com.alibaba.fastjson.JSON;
import com.zzh.pojo.Content;
import com.zzh.utils.HtmlParseUtils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.naming.directory.SearchResult;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
//业务编写
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//1.解析数据放入es索引中
public boolean parseContent( String keyword) throws IOException {
List<Content> contents = new HtmlParseUtils().parseJD(keyword);
//把查询出的数据放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
//取出执行请求
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
//看是否失败
return !bulk.hasFailures();
}
//2.获取这些数据,实现基本搜索功能
public List<Map<String, Object>> searchPage(String keyword, int pageNow, int pageSize) throws IOException {
if(pageNow <= 1){
pageNow = 1;
}
//基本条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNow);
sourceBuilder.size(pageSize);
//精准匹配关键字
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析上述结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
return list;
}
}
4.对应的请求编写
package com.zzh.controller;
import com.zzh.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
//请求编写
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public boolean parse(@PathVariable("keyword") String keyword) throws IOException {
return contentService.parseContent(keyword);
}
@GetMapping("/search/{keyword}/{pageNow}/{pageSize}")
public List<Map<String, Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNow") int pageNow,
@PathVariable("pageSize") int pageSize) throws IOException {
if(pageNow == 0){
pageNow = 1;
}
return contentService.searchPage(keyword, pageNow, pageSize);
}
}
前后端分离
放进相应的资源文件。利用vue实现前后端分离。
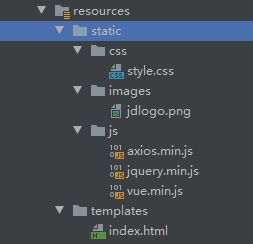
然后在需要进行上述搜索请求的网页中添加如下vue脚本,测试以index.html为例。
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>ES仿京东实战title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
h1>
<div class="header-extra">
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>天猫搜索legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text" autocomplete="off" value="dd" id="mq"
class="s-combobox-input" aria-haspopup="true">
div>
div>
<button type="submit" @click.prevent="searchKey" id="searchbtn">搜索button>
div>
fieldset>
form>
<ul class="relKeyTop">
ul>
div>
div>
div>
div>
div>
<div id="content">
<div class="main">
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
div>
<div class="attrValues">
<ul class="av-collapse row-2">
ul>
div>
div>
div>
div>
form>
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d">i>a>
<a class="fSort">人气<i class="f-ico-arrow-d">i>a>
<a class="fSort">新品<i class="f-ico-arrow-d">i>a>
<a class="fSort">销量<i class="f-ico-arrow-d">i>a>
<a class="fSort">价格<i class="f-ico-triangle-mt">i><i class="f-ico-triangle-mb">i>a>
div>
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
a>
div>
<p class="productPrice">
<em>{{result.price}}em>
p>
<p class="productTitle">
<a v-html="result.title"> a>
p>
<div class="productShop">
<span>店铺: *** span>
div>
<p class="productStatus">
<span>月成交<em>999笔em>span>
<span>评价 <a>3a>span>
p>
div>
div>
div>
div>
div>
div>
div>
<script th:src="@{/js/axios.min.js}">script>
<script th:src="@{/js/vue.min.js}">script>
<script>
new Vue({
el: "#app",
data:{
keyword: '', //搜索的关键字
results: [] //搜索的结果
},
methods:{
searchKey(){
var keyword = this.keyword;
console.log(keyword);
//对接后台的接口
axios.get("search/"+keyword+"/1/10").then(response=>{
console.log(response);
this.results = response.data; //绑定数据
})
}
}
})
script>
body>
html>
效果展示
完成上述一系列操作后,启动我们的springboot项目及ES,即可看到我们项目的效果。
1.访问链接http://localhost:9090/parse/{keyword} ——(keyword为你想要存储进ES的数据关键字,以java为例)。
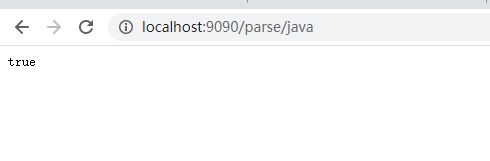
返回true说明爬取解析存储数据完成,我们可以到ES可视化工具ElasticSearch-head下查看。可以看到我们创建的jd_goods(该index需提前在ES中创建)下已经有数据了。

2.然后我们到搜索界面上,进行搜索,即可返回我们想要的结果。
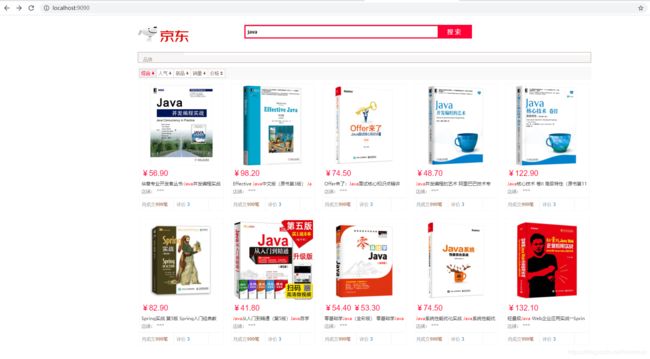
搜索高亮
要实现相应的搜索高亮显示,可以在上述Service中添加如下方法,设置需要高亮的字段属性,添加相应的标签,最后在得到结果时,对高亮的字段进行解析,用高亮字段去替换原来无高亮结果的字段。
//3.获取这些数据,实现基本搜索高亮功能
public List<Map<String, Object>> searchPageHighlight(String keyword, int pageNow, int pageSize) throws IOException {
if(pageNow <= 1){
pageNow = 1;
}
//基本条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNow);
sourceBuilder.size(pageSize);
//精准匹配关键字
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
//若要配置多个高亮,需设置
highlightBuilder.requireFieldMatch(false); // 多个高亮显示关闭
highlightBuilder.preTags("");
highlightBuilder.postTags("");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析上述结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //本身的结果
//解析高亮的字段,用高亮字段去替换原来无高亮结果的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
if(title != null){
Text[] fragments = title.fragments();
String new_title = "";
for (Text text : fragments) {
new_title += text;
}
sourceAsMap.put("title", new_title); // 高亮new_title字段替换原来的title字段
}
list.add(sourceAsMap);
}
return list;
}
总结
至此简单的ES搜索demo就完成了,关键是在对于ES中SearchRequest类,SearchSourceBuilder类及SearchResponse类的理解与使用。
参考: 仿京东搜索实战.