MySQL · 引擎特性 · InnoDB文件系统管理(二)
传统压缩存储格式
当你创建或修改表,指定row_format=compressed key_block_size=1|2|4|8 时,创建的ibd文件将以对应的block size进行划分。例如key_block_size设置为4时,对应block size为4kb。
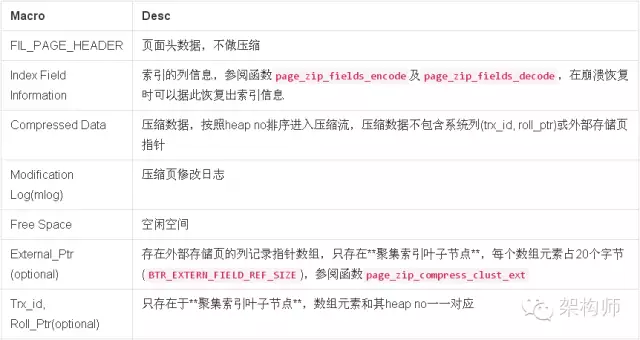
压缩页的格式可以描述如下表所示:

在内存中通常存在压缩页和解压页两份数据。当对数据进行修改时,通常先修改解压页,再将DML操作以一种特殊日志的格式记入压缩页的mlog中。以减少被修改过程中重压缩的次数。主要包含这几种操作:
-
Insert: 向mlog中写入完整记录
-
Update:
-
Delete-insert update,将旧记录的dense slot标记为删除,再写入完整新记录
-
In-place update,直接写入新更新的记录
-
-
Delete: 标记对应的dense slot为删除
页压缩参阅函数 page_zip_compress
页解压参阅函数 page_zip_decompress
系统数据页
这里我们将所有非独立的数据页统称为系统数据页,主要存储在ibdata中,如下图所示:
ibdata的三个page和普通的用户表空间一样,都是用于维护和管理文件页。其他Page我们下面一一进行介绍。
FSP_IBUF_HEADER_PAGE_NO
Ibdata的第4个page是Change Buffer的header page,类型为FIL_PAGE_TYPE_SYS,主要用于对ibuf btree的Page管理。
FSP_IBUF_TREE_ROOT_PAGE_NO
用于存储change buffer的根page,change buffer目前存储于Ibdata中,其本质上也是一颗btree,root页为固定page,也就是Ibdata的第5个page。
IBUF HEADER Page 和Root Page联合起来对ibuf的数据页进行管理。
首先Ibuf btree自己维护了一个空闲Page链表,链表头记录在根节点中,偏移量在PAGE_BTR_IBUF_FREE_LIST处,实际上利用的是普通索引根节点的PAGE_BTR_SEG_LEAF字段。Free List上的Page类型标示为FIL_PAGE_IBUF_FREE_LIST
每个Ibuf page重用了PAGE_BTR_SEG_LEAF字段,以维护IBUF FREE LIST的前后文件页节点(PAGE_BTR_IBUF_FREE_LIST_NODE)
由于root page中的segment字段已经被重用,因此额外的开辟了一个Page,也就是Ibdata的第4个page来进行段管理。在其中记录了ibuf btree的segment header,指向属于ibuf btree的inode entry。
关于ibuf btree的构建参阅函数 btr_create
FSP_TRX_SYS_PAGE_NO/FSP_FIRST_RSEG_PAGE_NO
ibdata的第6个page,记录了InnoDB重要的事务系统信息,主要包括:
Macro bytes Desc TRX_SYS 38 每个数据页都会保留的文件头字段 TRX_SYS_TRX_ID_STORE 8 持久化的最大事务ID,这个值不是实时写入的,而是256次递增写一次 TRX_SYS_FSEG_HEADER 10 指向用来管理事务系统的segment所在的位置 TRX_SYS_RSEGS 128 * 8 用于存储128个回滚段位置,包括space id及page no。每个回滚段包含一个文件segment( trx_rseg_header_create ) …… 以下是Page内UNIV_PAGE_SIZE - 1000的偏移位置 TRX_SYS_MYSQL_LOG_MAGIC_N_FLD 4 Magic Num ,值为873422344 TRX_SYS_MYSQL_LOG_OFFSET_HIGH 4 事务提交时会将其binlog位点更新到该page中,这里记录了在binlog文件中偏移量的高位的4字节 TRX_SYS_MYSQL_LOG_OFFSET_LOW 4 同上,记录偏移量的低4位字节 TRX_SYS_MYSQL_LOG_NAME 4 记录所在的binlog文件名 …… 以下是Page内UNIV_PAGE_SIZE - 200 的偏移位置 TRX_SYS_DOUBLEWRITE_FSEG 10 包含double write buffer的fseg header TRX_SYS_DOUBLEWRITE_MAGIC 4 Magic Num TRX_SYS_DOUBLEWRITE_BLOCK1 4 double write buffer的第一个block(占用一个extend)在ibdata中的开始位置,连续64个page TRX_SYS_DOUBLEWRITE_BLOCK2 4 第二个dblwr block的起始位置 TRX_SYS_DOUBLEWRITE_REPEAT 12 重复记录上述三个字段,即MAGIC NUM, block1, block2,防止发生部分写时可以恢复 TRX_SYS_DOUBLEWRITE_SPACE_ID_STORED 4 用于兼容老版本,当该字段的值不为TRX_SYS_DOUBLEWRITE_SPACE_ID_STORED_N时,需要重置dblwr中的数据
在5.7版本中,回滚段既可以在ibdata中,也可以在独立undo表空间,或者ibtmp临时表空间中,一个可能的分布如下图所示(摘自我之前的这篇文章)。
由于是在系统刚启动时初始化事务系统,因此第0号回滚段头页总是在ibdata的第7个page中。
事务系统创建参阅函数 trx_sysf_create
InnoDB最多可以创建128个回滚段,每个回滚段需要单独的Page来维护其拥有的undo slot,Page类型为FIL_PAGE_TYPE_SYS。描述如下:
Macro bytes Desc TRX_RSEG 38 保留的Page头 TRX_RSEG_MAX_SIZE 4 回滚段允许使用的最大Page数,当前值为ULINT_MAX TRX_RSEG_HISTORY_SIZE 4 在history list上的undo page数,这些page需要由purge线程来进行清理和回收 TRX_RSEG_HISTORY FLST_BASE_NODE_SIZE(16) history list的base node TRX_RSEG_FSEG_HEADER (FSEG_HEADER_SIZE)10 指向当前管理当前回滚段的inode entry TRX_RSEG_UNDO_SLOTS 1024 * 4 undo slot数组,共1024个slot,值为FIL_NULL表示未被占用,否则记录占用该slot的第一个undo page
回滚段头页的创建参阅函数 trx_rseg_header_create
实际存储undo记录的Page类型为FIL_PAGE_UNDO_LOG,undo header结构如下
Macro bytes Desc TRX_UNDO_PAGE_HDR 38 Page 头 TRX_UNDO_PAGE_TYPE 2 记录Undo类型,是TRX_UNDO_INSERT还是TRX_UNDO_UPDATE TRX_UNDO_PAGE_START 2 事务所写入的最近的一个undo log在page中的偏移位置 TRX_UNDO_PAGE_FREE 2 指向当前undo page中的可用的空闲空间起始偏移量 TRX_UNDO_PAGE_NODE 12 链表节点,提交后的事务,其拥有的undo页会加到history list上
undo页内结构及其与回滚段头页的关系参阅下图:
关于具体的Undo log如何存储,本文不展开描述,可阅读我之前的这篇文章:MySQL · 引擎特性 · InnoDB undo log 漫游
FSP_DICT_HDR_PAGE_NO
ibdata的第8个page,用来存储数据词典表的信息 (只有拿到数据词典表,才能根据其中存储的表信息,进一步找到其对应的表空间,以及表的聚集索引所在的page no)
Dict_Hdr Page的结构如下表所示:
Macro bytes Desc DICT_HDR 38 Page头 DICT_HDR_ROW_ID 8 最近被赋值的row id,递增,用于给未定义主键的表,作为其隐藏的主键键值来构建btree DICT_HDR_TABLE_ID 8 当前系统分配的最大事务ID,每创建一个新表,都赋予一个唯一的table id,然后递增 DICT_HDR_INDEX_ID 8 用于分配索引ID DICT_HDR_MAX_SPACE_ID 4 用于分配space id DICT_HDR_MIX_ID_LOW 4 DICT_HDR_TABLES 4 SYS_TABLES系统表的聚集索引root page DICT_HDR_TABLE_IDS 4 SYS_TABLE_IDS索引的root page DICT_HDR_COLUMNS 4 SYS_COLUMNS系统表的聚集索引root page DICT_HDR_INDEXES 4 SYS_INDEXES系统表的聚集索引root page DICT_HDR_FIELDS 4 SYS_FIELDS系统表的聚集索引root page
dict_hdr页的创建参阅函数 dict_hdr_create
double write buffer
InnoDB使用double write buffer来防止数据页的部分写问题,在写一个数据页之前,总是先写double write buffer,再写数据文件。当崩溃恢复时,如果数据文件中page损坏,会尝试从dblwr中恢复。
double write buffer存储在ibdata中,你可以从事务系统页(ibdata的第6个page)获取dblwr所在的位置。总共128个page,划分为两个block。由于dblwr在安装实例时已经初始化好了,这两个block在Ibdata中具有固定的位置,Page64 ~127 划属第一个block,Page 128 ~191划属第二个block。
在这128个page中,前120个page用于batch flush时的脏页回写,另外8个page用于SINGLE PAGE FLUSH时的脏页回写。
外部存储页
对于大字段,在满足一定条件时InnoDB使用外部页进行存储。外部存储页有三种类型:
-
FIL_PAGE_TYPE_BLOB:表示非压缩的外部存储页,结构如下图所示:
-
FIL_PAGE_TYPE_ZBLOB:压缩的外部存储页,如果存在多个blob page,则表示第一个 FIL_PAGE_TYPE_ZBLOB2:如果存在多个压缩的blob page,则表示blob链随后的page; 结构如下图所示:
而在记录内只存储了20个字节的指针以指向外部存储页,指针描述如下:
MySQL5.7新数据页:加密页及R-TREE页
MySQL 5.7版本引入了新的数据页以支持表空间加密及对空间数据类型建立R-TREE索引。本文对这种数据页不做深入讨论,仅仅简单描述下,后面我们会单独开两篇文章分别进行介绍。
数据加密页
从MySQL5.7.11开始InnoDB支持对单表进行加密,因此引入了新的Page类型来支持这一特性,主要加了三种Page类型:
-
FIL_PAGE_ENCRYPTED:加密的普通数据页
-
FIL_PAGE_COMPRESSED_AND_ENCRYPTED:数据页为压缩页(transparent page compression) 并且被加密(先压缩,再加密)
-
FIL_PAGE_ENCRYPTED_RTREE:GIS索引R-TREE的数据页并被加密
对于加密页,除了数据部分被替换成加密数据外,其他部分和大多数表都是一样的结构。
加解密的逻辑和Transparent Compression类似,在写入文件前加密(os_file_encrypt_page --> Encryption::encrypt),在读出文件时解密数据(os_file_io_complete --> Encryption::decrypt)
秘钥信息存储在ibd文件的第一个page中(fsp_header_init --> fsp_header_fill_encryption_info),当执行SQLALTER INSTANCE ROTATE INNODB MASTER KEY时,会更新每个ibd存储的秘钥信息(fsp_header_rotate_encryption)
默认安装时,一个新的插件keyring_file被安装并且默认Active,在安装目录下,会产生一个新的文件来存储秘钥,位置在$MYSQL_INSTALL_DIR/keyring/keyring,你可以通过参数keyring_file_data来指定秘钥的存放位置和文件命名。 当你安装多实例时,需要为不同的实例指定keyring文件。
开启表加密的语法很简单,在CREATE TABLE或ALTER TABLE时指定选项ENCRYPTION=‘Y’来开启,或者ENCRYPTION=‘N’来关闭加密。
关于InnoDB表空间加密特性,参阅该commit及官方文档
R-TREE索引页
在MySQL 5.7中引入了新的索引类型R-TREE来描述空间数据类型的多维数据结构,这类索引的数据页类型为FIL_PAGE_RTREE。
R-TREE的相关设计参阅官方WL#6968, WL#6609, WL#6745
临时表空间ibtmp
MySQL5.7引入了临时表专用的表空间,默认命名为ibtmp1,创建的非压缩临时表都存储在该表空间中。系统重启后,ibtmp1会被重新初始化到默认12MB。你可以通过设置参数innodb_temp_data_file_path来修改ibtmp1的默认初始大小,以及是否允许autoExtent。默认值为 ”ibtmp1:12M:autoExtent“
除了用户定义的非压缩临时表外,第1~32个临时表专用的回滚段也存放在该文件中(0号回滚段总是存放在ibdata中)(trx_sys_create_noredo_rsegs),
日志文件ib_logfile
关于日志文件的格式,网上已经有很多的讨论,在之前的系列文章中我也有专门介绍过,本小节主要介绍下MySQL5.7新的修改。
首先是checksum算法的改变,当前版本的MySQL5.7可以通过参数innodb_log_checksums来开启或关闭redo checksum,但目前唯一支持的checksum算法是CRC32。而在之前老版本中只支持效率较低的InnoDB本身的checksum算法。
第二个改变是为Redo log引入了版本信息(WL#8845),存储在ib_logfile的头部,从文件头开始,描述如下
每次切换到下一个iblogfile时,都会更新该文件头信息(log_group_file_header_flush)
新的版本支持兼容老版本(recv_find_max_checkpoint_0),但升级到新版本后,就无法在异常状态下in-place降级到旧版本了(除非做一次clean的shutdown,并清理掉iblogfile)。
具体实现参阅该commit
IO子系统
本小节我们介绍下磁盘文件与内存数据的中枢,即IO子系统。InnoDB对page的磁盘操作分为读操作和写操作。
对于读操作,在将数据读入磁盘前,总是为其先预先分配好一个block,然后再去磁盘读取一个新的page,在使用这个page之前,还需要检查是否有change buffer项,并根据change buffer进行数据变更。读操作分为两种场景:普通的读page及预读操作,前者为同步读,后者为异步读
数据写操作也分为两种,一种是batch write,一种是single page write。写page默认受double write buffer保护,因此对double write buffer的写磁盘为同步写,而对数据文件的写入为异步写。
同步读写操作通常由用户线程来完成,而异步读写操作则需要后台线程的协同。
举个简单的例子,假设我们向磁盘批量写数据,首先先写到double write buffer,当dblwr满了之后,一次性将dblwr中的数据同步刷到Ibdata,在确保sync到dblwr后,再将这些page分别异步写到各自的文件中。注意这时候dblwr依旧未被清空,新的写Page请求会进入等待。当异步写page完成后,io helper线程会调用buf_flush_write_complete,将写入的Page从flush list上移除。当dblwr中的page完全写完后,在函数buf_dblwr_update里将dblwr清空。这时候才允许新的写请求进dblwr。
同样的,对于异步写操作,也需要IO Helper线程来检查page是否完好、merge change buffer等一系列操作。
除了数据页的写入,还包括日志异步写入线程、及ibuf后台线程。
IO后台线程
InnoDB的IO后台线程主要包括如下几类:
-
IO READ 线程: 后台读线程,线程数目通过参数innodb_read_io_threads配置,主要处理INNODB 数据文件异步读请求,任务队列为
AIO::s_reads,任务队列包含slot数为线程数 * 256(linux 平台),也就是说,每个read线程最多可以pend 256个任务; -
IO WRITE 线程: 后台写线程数,线程数目通过参数innodb_write_io_threads配置。主要处理INNODB 数据文件异步写请求,任务队列为
AIO::s_writes,任务队列包含slot数为线程数 * 256(linux 平台),也就是说,每个read线程最多可以pend 256个任务; -
LOG 线程:写日志线程。只有在写checkpoint信息时才会发出一次异步写请求。任务队列为
AIO::s_log,共1个segment,包含256个slot; -
IBUF 线程:负责读入change buffer页的后台线程,任务队列为
AIO::s_ibuf,共1个segment,包含256个slot
所有的同步写操作都是由用户线程或其他后台线程执行。上述IO线程只负责异步操作。
发起IO请求
入口函数:os_aio_func
首先对于同步读写请求(OS_AIO_SYNC),发起请求的线程直接调用os_file_read_func 或者os_file_write_func 去读写文件 ,然后返回。
对于异步请求,用户线程从对应操作类型的任务队列(AIO::select_slot_array)中选取一个slot,将需要读写的信息存储于其中(AIO::reserve_slot):
-
首先在任务队列数组中选择一个segment;这里根据偏移量来算segment,因此可以尽可能的将相邻的读写请求放到一起,这有利于在IO层的合并操作
local_seg = (offset >> (UNIV_PAGE_SIZE_SHIFT + 6)) % m_n_segments;
-
从该segment范围内选择一个空闲的slot,如果没有则等待;
-
将对应的文件读写请求信息赋值到slot中,例如写入的目标文件,偏移量,数据等;
-
如果这是一次IO写入操作,且使用native aio时,如果表开启了transparent compression,则对要写入的数据页先进行压缩并punch hole;如果设置了表空间加密,再对数据页进行加密;
对于Native AIO (使用linux自带的LIBAIO库),调用函数AIO::linux_dispatch,将IO请求分发给kernel层。
如果没有开启Native AIO,且没有设置wakeup later 标记,则会去唤醒io线程(AIO::wake_simulated_handler_thread),这是早期libaio还不成熟时,InnoDB在内部模拟aio实现的逻辑。
Tips:编译Native AIO需要安装libaio-dev包,并打开选项srv_use_native_aio
处理异步AIO请求
IO线程入口函数为io_handler_thread --> fil_aio_wait
首先调用os_aio_handler来获取请求:
-
对于Native AIO,调用函数os_aio_linux_handle 获取读写请求。 IO线程会反复以500ms(
OS_AIO_REAP_TIMEOUT)的超时时间通过io_getevents确认是否有任务已经完成了(LinuxAIOHandler::collect()),如果有读写任务完成,找到已完成任务的slot后,释放对应的槽位。 -
对于simulated aio,调用函数
os_aio_simulated_handler处理读写请求,这里相比NATIVE AIO要复杂很多-
如果这是异步读队列,并且
os_aio_recommend_sleep_for_read_threads被设置,则暂时不处理,而是等待一会,让其他线程有机会将更过的IO请求发送过来。目前linear readhaed 会使用到该功能。这样可以得到更好的IO合并效果。(SimulatedAIOHandler::check_pending) -
已经完成的slot需要及时被处理(
SimulatedAIOHandler::check_completed,可能由上次的io合并操作完成) -
如果有超过2秒未被调度的请求(
SimulatedAIOHandler::select_oldest),则优先选择最老的slot,防止饿死,否则,找一个文件读写偏移量最小的位置的slot(SimulatedAIOHandler::select()) -
没有任何请求时进入等待状态
-
当找到一个未完成的slot时,会尝试merge相邻的IO请求(
SimulatedAIOHandler::merge()),并将对应的slot加入到SimulatedAIOHandler::m_slots数组中,最多不超过64个slot -
然而在5.7版本里,合并操作已经被禁止了,全部改成了一个个slot进行读写,升级到5.7的用户一定要注意这个改变,或者改为使用更好的Native AIO方式
-
完成io后,释放slot; 并选择第一个处理完的slot作为随后优先完成的请求。
-
从上一步获得完成IO的slot后,调用函数fil_node_complete_io, 递减node->n_pending。 对于文件写操作,需要加入到fil_system->unflushed_spaces链表上,表示这个文件修改过了,后续需要被sync到磁盘。
如果设置为O_DIRECT_NO_FSYNC的文件IO模式,则数据文件无需加入到fil_system_t::unflushed_spaces链表上。通常我们即时使用O_DIRECT的方式操作文件,也需要做一次sync,来保证文件元数据的持久化,但在某些文件系统下则没有这个必要,通常只要文件的大小这些关键元数据没发生变化,可以省略一次fsync。
最后在IO完成后,调用buf_page_io_complete,做page corruption检查、change buffer merge等操作;对于写操作,需要从flush list上移除block并更新double write buffer;对于LRU FLUSH产生的写操作,还会将其对应的block释放到free list上;
对于日志文件操作,调用log_io_complete执行一次fil_flush,并更新内存内的checkpoint信息(log_complete_checkpoint)
IO 并发控制
由于文件底层使用pwrite/pread来进行文件I/O,因此用户线程对文件普通的并发I/O操作无需加锁。但在windows平台下,则需要加锁进行读写。
对相同文件的IO操作通过大量的counter/flag来进行并发控制。
当文件处于扩展阶段时(fil_space_extend),将fil_node_t::being_extended设置为true,避免产生并发Extent,或其他关闭文件或者rename操作等
当正在删除一个表时,会检查是否有pending的操作(fil_check_pending_operations)
-
将fil_space_t::stop_new_ops设置为true;
-
检查是否有Pending的change buffer merge (fil_space_t::n_pending_ops);有则等待
-
检查是否有pending的IO(fil_node_t::n_pending) 或者pending的文件flush操作(
fil_node_t::n_pending_flushes);有则等待
当truncate一张表时,和drop table类似,也会调用函数fil_check_pending_operations,检查表上是否有pending的操作,并将fil_space_t::is_being_truncated设置为true
当rename一张表时(fil_rename_tablespace),将文件的stop_ios标记设置为true,阻止其他线程所有的I/O操作
当进行文件读写操作时,如果是异步读操作,发现stop_new_ops或者被设置了但is_being_truncated未被设置,会返回报错;但依然允许同步读或异步写操作(fil_io)
当进行文件flush操作时,如果发现fil_space_t::stop_new_ops或者fil_space_t::is_being_truncated被设置了,则忽略该文件的flush操作 (fil_flush_file_spaces)
文件预读
文件预读是一项在SSD普及前普通磁盘上比较常见的技术,通过预读的方式进行连续IO而非带价高昂的随机IO。InnoDB有两种预读方式:随机预读及线性预读; Facebook另外还实现了一种逻辑预读的方式
随机预读
入口函数:buf_read_ahead_random
以64个Page为单位(这也是一个Extent的大小),当前读入的page no所在的64个pagno 区域[ (page_no/64)*64, (page_no/64) *64 + 64],如果最近被访问的Page数超过BUF_READ_AHEAD_RANDOM_THRESHOLD(通常值为13),则将其他Page也读进内存。这里采取异步读。
随机预读受参数innodb_random_read_ahead控制
线性预读
入口函数:buf_read_ahead_linear
所谓线性预读,就是在读入一个新的page时,和随机预读类似的64个连续page范围内,默认从低到高Page no,如果最近连续被访问的page数超过innodb_read_ahead_threshold,则将该Extent之后的其他page也读取进来。
逻辑预读
由于表可能存在碎片空间,因此很可能对于诸如全表扫描这样的场景,连续读取的page并不是物理连续的,线性预读不能解决这样的问题,另外一次读取一个Extent对于需要全表扫描的负载并不足够。因此facebook引入了逻辑预读。
其大致思路为,扫描聚集索引,搜集叶子节点号,然后根据叶子节点的page no (可以从非叶子节点获取)顺序异步读入一定量的page。
由于Innodb aio一次只支持提交一个page读请求,虽然Kernel层本身会做读请求合并,但那显然效率不够高。他们对此做了修改,使INNODB可以支持一次提交(io_submit)多个aio请求。
入口函数:row_search_for_mysql --> row_read_ahead_logical
具体参阅这篇博文
或者webscalesql上的几个commit:
日志填充写入
由于现代磁盘通常的block size都是大于512字节的,例如一般是4096字节,为了避免 “read-on-write” 问题,在5.7版本里添加了一个参数innodb_log_write_ahead_size,你可以通过配置该参数,在写入redo log时,将写入区域配置到block size对齐的字节数。
在代码里的实现,就是在写入redo log 文件之前,为尾部字节填充0,(参考函数log_write_up_to)
Tips:所谓READ-ON-WRITE问题,就是当修改的字节不足一个block时,需要将整个block读进内存,修改对应的位置,然后再写进去;如果我们以block为单位来写入的话,直接完整覆盖写入即可。
buffer pool内存管理
InnoDB buffer pool从5.6到5.7版本发生了很大的变化。首先是分配方式上不同,其次实现了更好的刷脏效率。对buffer pool上的各个链表的管理也更加高效。
buffer pool初始化
在5.7之前的版本中,一个buffer pool instance拥有一个chunk,每个chunk的大小为buffer pool size / instance个数。
而到了5.7版本中,每个instance可能划分成多个chunk,每个chunk的大小是可定义的,默认为127MB。因此一个buffer pool instance可能包含多个chunk内存块。这么做的目的是为了实现在线调整buffer pool大小(WL#6117),buffer pool增加或减少必须以chunk为基本单位进行。
在5.7里有个问题值得关注,即buffer pool size会根据instances * chunk size向上对齐,举个简单的例子,假设你配置了64个instance, chunk size为默认128MB,就需要以8GB进行对齐,这意味着如果你配置了9GB的buffer pool,实际使用的会是16GB。所以**尽量不要配置太多的buffer pool instance**
buffer pool链表及管理对象
出于不同的目的,每个buffer pool instance上都维持了多个链表,可以根据space id及page no找到对应的instance(buf_pool_get)。
一些关键的结构对象及描述如下表所示:
buffer pool并发控制
除了不同的用户线程会并发操作buffer pool外,还有后台线程也会对buffer pool进行操作。InnoDB通过读写锁,buf fix计数,io fix标记来进行并发控制。
读写并发控制
通常当我们读取到一个page时,会对其加block S锁,并递增buf_page_t::buf_fix_count,直到mtr commit时才会恢复。而如果读page的目的是为了进行修改,则会加X锁
当一个page准备flush到磁盘时(buf_flush_page),如果当前Page正在被访问,其buf_fix_count不为0时,就忽略flush该page,以减少获取block上SX Lock的昂贵代价。
并发读控制
当多个线程请求相同的page时,如果page不在内存,是否可能引发对同一个page的文件IO ?答案是不会。
从函数buf_page_init_for_read我们可以看到,在准备读入一个page前,会做如下工作:
-
分配一个空闲block
-
buf_pool_mutex_enter
-
持有page_hash x lock
-
检查page_hash中是否已被读入,如果是,表示另外一个线程已经完成了io,则忽略本次io请求,退出
-
持有block->mutex,对block进行初始化,并加入到page hash中
-
设置IO FIX为BUF_IO_READ
-
释放hash lock
-
将block加入到LRU上
-
持有block s lock
-
完成IO后,释放s lock
当另外一个线程也想请求相同page时,首先如果看到page hash中已经有对应的block了,说明page已经或正在被读入buffer pool,如果io_fix为BUF_IO_READ,说明正在进行IO,就通过加X锁的方式做一次sync(buf_wait_for_read),确保IO完成。
请求Page通常还需要加S或X锁,而IO期间也是持有block x锁的,如果成功获取了锁,说明IO肯定完成了。
Page驱逐及刷脏
当buffer pool中的free list不足时,为了获取一个空闲block,通常会触发page驱逐操作(buf_LRU_free_from_unzip_LRU_list)
首先由于压缩页在内存中可能存在两份拷贝:压缩页和解压页;InnoDB根据最近的IO情况和数据解压技术来判定实例是处于IO-BOUND还是CPU-BOUND(buf_LRU_evict_from_unzip_LRU)。如果是IO-BOUND的话,就尝试从unzip_lru上释放一个block出来(buf_LRU_free_from_unzip_LRU_list),而压缩页依旧保存在内存中。
其次再考虑从buf_pool_t::LRU链表上释放block,如果有可替换的page(buf_flush_ready_for_replace)时,则将其释放掉,并加入到free list上;对于压缩表,压缩页和解压页在这里都会被同时驱逐。
当无法从LRU上获得一个可替换的Page时,说明当前Buffer pool可能存在大量脏页,这时候会触发single page flush(buf_flush_single_page_from_LRU),即用户线程主动去刷一个脏页并替换掉。这是个慢操作,尤其是如果并发很高的时候,可能观察到系统的性能急剧下降。在RDS MySQL中,我们开启了一个后台线程, 能够自动根据当前Free List的长度来主动做flush,避免用户线程陷入其中。
除了single page flush外,在MySQL 5.7版本里还引入了多个page cleaner线程,根据一定的启发式算法,可以定期且高效的的做page flush操作。