环境安装
Mac系统默认安装了Python2,如果想安装Python3,执行以下命令:
brew install python3
brew link python3
这样就可以通过python访问python2版本,python3访问python3版本了
$ python3 --version
Python 3.6.3
$ python --version
Python 2.7.10
包安装
接下来安装抓包分析Html的利器
pip install beautifulsoup4
虽然用正则表达式也可以分析html,但是这个效率更高,也能避免去思考很多复杂的正则。这里Beautiful Soup 文档有关于这个工具的详细用法,下面我们用一个例子来简单介绍一下。
一个例子
下面以链家网的房屋列表页面为例,进行抓取分析:
以这个页面为例:https://bj.lianjia.com/zufang/pg/

我们需要抓取的是这个房屋列表信息,首先用chrome的检查工具找到这个列表的父容器:
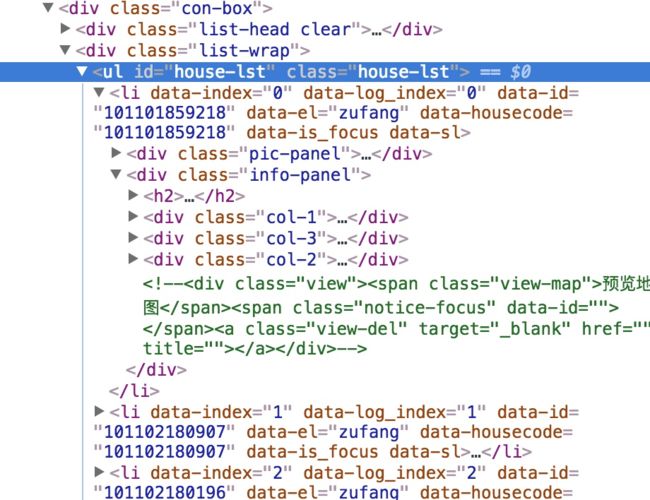
所有的房屋信息列表都在这个ul里面了。
首选创建一个python文件,在顶部导入BeautifulSoup包:
#coding=utf-8
import urllib2
from bs4 import BeautifulSoup
然后是获取html地址中的文件内容方法:
def getHtml(url):
page = urllib2.urlopen(url)
html = page.read().decode('utf-8')
return html
接下来我们编写一个getList方法来筛出html内容中的房屋列表信息:
def getList(page):
list = []
html = getHtml("https://bj.lianjia.com/zufang/pg" + str(page) + "/")
这里html就是网页的内容了,方法接收一个page参数,可以抓取不同的页面。
接下来需要调用BeautifulSoup方法,把html文本转换成一个对象:
soup = BeautifulSoup(html, 'html.parser')
根据刚才对html的分析,我们需要的列表藏在一个ul中,ul具有id是house-lst,class是house-lst的特征,ul下面的每个li都是一个房屋信息,我们首选获取到房屋信息的数组items:
items = soup.find(attrs={"id":"house-lst","class":"house-lst"}).children
然后遍历items,里面的每个元素就都是一个li了
for item in items:
接下来我们再具体对每个li进行分析

房屋的Id在li的data-id属性中:
hid = item["data-id"]

图片在li->div(pic-pannel)->a->img->data-img属性中:
pic = item.find(attrs={"class":"pic-panel"}).a.img["data-img”]
接下来的信息都藏在info-panel的div下,我们先定义出这个容器对象:
infoPanel = item.find(attrs={"class":"info-panel"})
然后再依照上面的方法,一个个取出来:
title = infoPanel.h2.a.string
url = infoPanel.h2.a["href"]
region = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"where"}).find(attrs={"class":"region"}).string.rstrip()
zone = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"where"}).find(attrs={"class":"zone"}).span.string.rstrip()
meters = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"where"}).find(attrs={"class":"meters"}).string.rstrip()
direction = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"where"}).contents[-1].string
area = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"other"}).find(attrs={"class":"con"}).a.string
floor = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"other"}).find(attrs={"class":"con"}).contents[2]
history = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"other"}).find(attrs={"class":"con"}).contents[4]
subway = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"chanquan"}).find(attrs={"class":"fang-subway-ex"})
subway = subway.span.string if subway else ""
hasKey = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"chanquan"}).find(attrs={"class":"haskey-ex"})
hasKey = hasKey.span.string if hasKey else ""
decoration = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"chanquan"}).find(attrs={"class":"decoration-ex"})
decoration = decoration.span.string if decoration else ""
heating = infoPanel.find(attrs={"class":"col-1"}).find(attrs={"class":"chanquan"}).find(attrs={"class":"heating-ex"})
heating = heating.span.string if heating else ""
price = infoPanel.find(attrs={"class":"col-3"}).find(attrs={"class":"price"}).find(attrs={"class":"num"}).string
priceUnit = infoPanel.find(attrs={"class":"col-3"}).find(attrs={"class":"price"}).contents[-1]
updateTime = infoPanel.find(attrs={"class":"col-3"}).find(attrs={"class":"price-pre"}).contents[0]
visited = infoPanel.find(attrs={"class":"col-2"}).find(attrs={"class":"square"}).find(attrs={"class":"num"}).string
visitedAction = infoPanel.find(attrs={"class":"col-2"}).find(attrs={"class":"square"}).find(attrs={"class":"col-look"}).string
上面的代码中增加了一些if判断,因为有的html节点不一定存在,有可能为空,所以需要判断一下再取值。最终形成我们想要的对象就是:
{
"hid": hid,
"image": pic,
"title": title,
"url": url,
"region": region,
"zone": zone,
"meters": meters,
"direction": direction,
"area": area,
"floor": floor,
"history": history,
"subway": subway,
"hasKey": hasKey,
"decoration": decoration,
"heating": heating,
"price": price,
"priceUnit": priceUnit,
"updateTime": updateTime,
"visited": visited,
"visitedAction": visitedAction
}
执行一下:
print getList(1)
就能看到我们想要的结果了

接下来的工作就是把这个数据持久化存储起来。