NoSQL数据库之:HBase
一、NoSQL的基础、常见的NoSQL数据库
1、not only sql
2、回顾:关系型数据库: Oracle、MySQL等等 -----> 面向行:适合insert update delete
3、常见的NoSQL数据库
(*)基于Key-Value模型:Redis(内存)-----> 前身:MemCached(不足:不支持持久化)
(*)面向列的模型:HBase、Cassandra------> 适合 select
(*)基于文档型:MongoDB -----> 文档:BSON文档 是json的二进制
举例:设计一个数据库,保存电影的信息

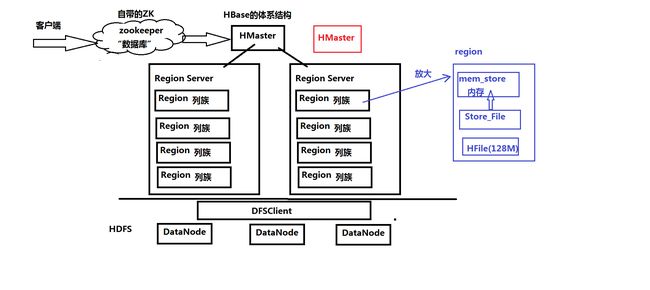
二、HBase的表结构和体系结构
三、搭建HBase环境
tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training/
设置环境变量 vi ~/.bash_profile
HBASE_HOME=/root/training/hbase-1.3.1
export HBASE_HOME
PATH=$HBASE_HOME/bin:$PATH
export PATH
source ~/.bash_profile
1、本地模式: 不需要HDFS,保存在Linux的文件系统
bigdata111配置
建个目录: mkdir data
修改文件:hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
核心配置文件: conf/hbase-site.xml
hbase.rootdir
file:///root/training/hbase-1.3.1/data
启动HBase:start-hbase.sh
starting master, logging to /root/training/hbase-1.3.1/logs/hbase-root-master-bigdata111.out
只有HMaster
2、伪分布模式(bigdata111)
修改文件:hbase-env.sh
HBASE_MANAGES_ZK true ---> 使用HBase自带的ZK
核心配置文件: conf/hbase-site.xml
hbase.rootdir
hdfs://192.168.157.111:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
192.168.157.111
dfs.replication
1
文件regionservers:配置从节点地址
192.168.157.111
3、全分布模式:bigdata112 bigdata113 bigdata114
修改文件:hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
HBASE_MANAGES_ZK true ---> 使用HBase自带的ZK
核心配置文件: conf/hbase-site.xml
hbase.rootdir
hdfs://192.168.157.112:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
192.168.157.112
dfs.replication
2
hbase.master.maxclockskew
180000
文件regionservers:配置从节点地址
192.168.157.113
192.168.157.114
复制到其他节点上
scp -r hbase-1.3.1/ root@bigdata113:/root/training
scp -r hbase-1.3.1/ root@bigdata114:/root/training
四、HBase在ZK中保存的数据和HA
1、HBase在ZK中保存的数据

2、在bigdata113再手动启动一个HMaster
hbase-daemon.sh start master
五、操作HBase
1、命令行
创建表: create 'student','info','grade'
插入数据: put 'student','stu001','info:name','Tom'
put 'student','stu001','info:age','24'
put 'student','stu001','info:gender','Male'
put 'student','stu001','grade:math','80'
put 'student','stu002','info:name','Mike'
查询:scan 'student'
get格式: get '表名','行键'
get 'student','stu001'
删除表:disable 'student'
3、Web Console: 端口 16010
六、数据保存的过程(重要:一定要注意Region分裂)
准备测试数据:emp表 员工表
1、列值过滤器
2、列名前缀过滤器
3、多个列名前缀过滤器
4、Rowkey过滤器
5、在查询的时候,可以组合多个过滤器
八、HBase上的MapReduce
测试数据:WordCount
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
结果: create 'result','content'
设置环境变量
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH
1、not only sql
2、回顾:关系型数据库: Oracle、MySQL等等 -----> 面向行:适合insert update delete
3、常见的NoSQL数据库
(*)基于Key-Value模型:Redis(内存)-----> 前身:MemCached(不足:不支持持久化)
(*)面向列的模型:HBase、Cassandra------> 适合 select
(*)基于文档型:MongoDB -----> 文档:BSON文档 是json的二进制
举例:设计一个数据库,保存电影的信息
二、HBase的表结构和体系结构
三、搭建HBase环境
tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training/
设置环境变量 vi ~/.bash_profile
HBASE_HOME=/root/training/hbase-1.3.1
export HBASE_HOME
PATH=$HBASE_HOME/bin:$PATH
export PATH
source ~/.bash_profile
1、本地模式: 不需要HDFS,保存在Linux的文件系统
bigdata111配置
建个目录: mkdir data
修改文件:hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
核心配置文件: conf/hbase-site.xml
启动HBase:start-hbase.sh
starting master, logging to /root/training/hbase-1.3.1/logs/hbase-root-master-bigdata111.out
只有HMaster
2、伪分布模式(bigdata111)
修改文件:hbase-env.sh
HBASE_MANAGES_ZK true ---> 使用HBase自带的ZK
核心配置文件: conf/hbase-site.xml
文件regionservers:配置从节点地址
192.168.157.111
3、全分布模式:bigdata112 bigdata113 bigdata114
修改文件:hbase-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
HBASE_MANAGES_ZK true ---> 使用HBase自带的ZK
核心配置文件: conf/hbase-site.xml
文件regionservers:配置从节点地址
192.168.157.113
192.168.157.114
复制到其他节点上
scp -r hbase-1.3.1/ root@bigdata113:/root/training
scp -r hbase-1.3.1/ root@bigdata114:/root/training
四、HBase在ZK中保存的数据和HA
1、HBase在ZK中保存的数据
2、在bigdata113再手动启动一个HMaster
hbase-daemon.sh start master
五、操作HBase
1、命令行
创建表: create 'student','info','grade'
插入数据: put 'student','stu001','info:name','Tom'
put 'student','stu001','info:age','24'
put 'student','stu001','info:gender','Male'
put 'student','stu001','grade:math','80'
put 'student','stu002','info:name','Mike'
查询:scan 'student'
get格式: get '表名','行键'
get 'student','stu001'
删除表:disable 'student'
drop 'student'

3、Web Console: 端口 16010
六、数据保存的过程(重要:一定要注意Region分裂)


准备测试数据:emp表 员工表
1、列值过滤器
2、列名前缀过滤器
3、多个列名前缀过滤器
4、Rowkey过滤器
5、在查询的时候,可以组合多个过滤器
八、HBase上的MapReduce
测试数据:WordCount
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
结果: create 'result','content'
设置环境变量
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH