腾讯大数据之新一代资源管理与调度平台
云计算、大数据经常意味着需要调动数据中心大量的资源,如何能够快速的匹配合适资源,需要一个聪明的“大脑”。数据平台部的TDW,是腾讯自主研发,支持百PB级的数据存储和计算,提供海量、高效、稳定的大数据平台支撑和决策支持,成为腾讯大数据处理的核心平台。更大规模的集群,更多新的分布式编程框架,更多不同的业务场景,都给这个大脑提出了挑战。
同时,我们也在思考一个并非只为TDW服务的通用资源管理系统。这些价值正是Google Borg十余年来作为secret weapon提供的强大能力,也是Mesos、Corona、Yarn都想追随Borg脚步的原因。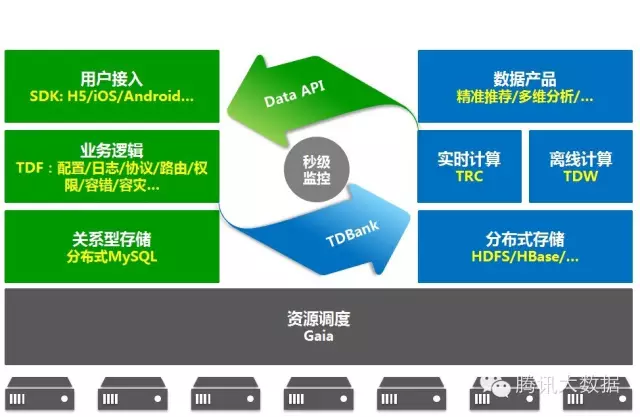
图1. 腾讯数据平台整体架构
大数据领域开源技术林立,Hadoop又在持续升温,开源已经悄悄在主宰世界。流行的资源系统的开源项目主要有Yarn、Corona以及Mesos,我们考虑到目前与公司项目的结合度以及未来的趋势,把结论落在了Yarn上。
业务支持上,它可以兼容tdw原来的MR、hive等任务,对于storm、spark等,Yarn也可以有较好支持;从Yarn自身看,虽然它出现最晚,目前也最不成熟,但是它的可扩展性的架构优势以及良好的兼容性,Container的资源管理方式等,都代表了未来资源管理系统的趋势;最后从社区的活跃度以及生态圈看,不但有MR On Yarn、Storm On Yarn,Hive On Yarn,Hbase On Yarn,而比较新兴的samza、spark等,也都在“On Yarn”。Corona和Mesos主要是facebook和twitter在使用,并且他们也同时使用Hadoop集群,这两个开源项目社区都远远不如Hadoop社区活跃,影响力也差很多。基于这些现实情况,我们最终选择了目前并不是很完善的Yarn。
然而,如前所述,Yarn还非常不完善。尤其是在腾讯的场景下,集群规模更大,作业并发度更高,业务场景更多,把开源Yarn直接拿过来使用,显然是不够的。因此,我们依托做过自研集群资源管理和调度系统的优势,开发了自研的调度器sfair,提升Yarn的调度能力以及集群的可扩展性,同时,在资源管理方面,优化了Yarn的内存资源管理,增加了网络带宽等维度的管理。因此,我们的集群资源管理和调度系统又不仅仅是Yarn。
Gaia(盖娅):希腊神话中的大地之神,是众神之母,所有神灵中最德高望重的显赫之神。Gaia以后可以承载各种编程框架、各种应用,是个统一的资源管理调度系统——各种业务都植根于“大地”之上。
我们为Gaia确立的项目目标是:打造腾讯的自研资源管理平台,提供高并发任务调度和资源管理,实现集群资源共享,提升可伸缩性和可靠性,不仅可以为MR等离线业务提供服务,还可以支持实时计算,甚至在线service业务。
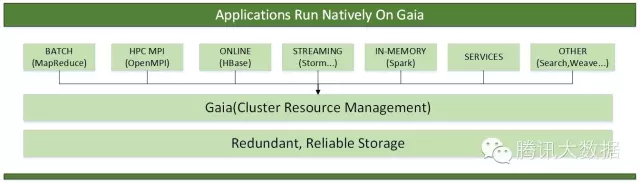
图2. Applications on Gaia
Gaia的系统目标
Yarn的官方主页上说“Yarn as Cluster Operating System”,在这一点上,Gaia和Yarn完全一致,目标都是实现一个通用的资源管理和调度平台,作为集群操作系统服务于上层各类应用。系统目标如下:
1.可扩展性
更大规模的集群意味着可以支持更大规模的应用,更大的并发度以及对底层资源更好的共享。而将Hadoop1.0 中的JobTracker扩展到4000个节点规模的集群被证明是极端困难的。新一代计算平台应该可以平滑地扩展至数万节点以及并发的应用,这就需要在架构上对系统做根本的调整。
2.可维护性
Gaia系统本身需要维护,会经常的进行版本升级,以及进行bug fix,需要保证Gaia系统自身的升级与用户应用程序完全解耦。
3.支持多租户
Gaia需要支持在同一个集群中多个租户并存,同时支持在多个租户之间细粒度的共享节点。
4.位置感知
Locality的特性可以大大减少数据移动,减少计算等待的时间,并且可以节省带宽资源。因此,Gaia应该支持位置感知——将计算移动到数据所在的位置。
5.高集群使用率
不管是从成本,还是提升并发度等方面来说,Gaia都需要实现底层物理资源的高使用率。在Gaia中,我们可以通过资源共享、业务错峰、buffer共享、资源类型互补等多种方式来提升集群的资源使用率,进而节省成本。
6.安全和可审计的操作
Gaia应该以安全的并且可审计的方式使用集群资源。
我们试图避免使用特权用户(比如root)运行NodeManager,以此来解决这个问题。NodeManager可以代表用户执行很多操作,使用特权用户运行会暴露出很多容易遭攻击的地方。任务使用的目录和文件同样需要合适的权限。很多目录和文件是NodeManager创建的,但是会被任务使用。少数是由用户代码写入但是被守护进程使用或者访问。基于安全的考量,权限的设置需要非常严格,只能被用户或者NodeManager读/写。
用户可以向一个或更多的集群提交作业,但他必须在作业提交之前通过Kerberos或者授权机制进行认证。用户在作业提交之后可以中断连接,然后通过同一认证机制重新连接获得作业状态。
需要一个机制来控制谁能向一个指定的队列提交作业。只有在用户被授权时,作业才被允许提交到这些队列。为此,管理员在集群初始化之前设置了Queue ACL。管理员可以在运行时动态地改变队列的ACL,从而允许一个用户或者一个组访问它。被称为集群管理员和队列管理员的特定的用户和组,可以管理队列的ACL,也可以访问或者修改队列中的任何作业。
7.可靠性和可用性
共享集群提升了利用率和本地化,它也使对可靠性和可用性的担忧成为大家关注的焦点。ResourceManager的失效会引发的中断,不仅仅是丢失单独的一个工作流,而是会丢失集群中所有的运行作业,并且要求用户手动重新提交并恢复他们的工作流。运营一个大规模、多租户的Hadoop集群并非易事的。容错性是一个核心设计原则。
8.对编程模型多样性的支持
虽然MapReduce的支持范围广泛的用例,它并不适用于所有大型计算的理想模式。例如,很多机器学习程序需要在同一数据集上的多次迭代来收敛得到结果。如果将这个流程使用一系列的MapReduce实现,调度的开销会导致结果的显著延迟。类似地,与使用在可容错的大规模MapReduce作业中很重的多对多通信相比,很多图形算法是使用整体同步并行计算模型(BSP),在边之间传递消息,会获得更好的表现。这种不匹配成为用户工作效率的一个阻碍,但是Hadoop中这种以MapReduce为中心的设计不允许使用其他编程模型。
9.灵活的资源模型
除了与新兴框架需求不匹配之外,Hadoop1.0上带类型的slot也伤害了利用率。在单个节点上(以至整个集群)map和reduce的隔离防止了跨任务类型的死锁,但是它也造成了资源瓶颈。
用户为每一个提交的作业对map和reduce的重叠情况进行了配置。较晚启动reduce任务可以增加集群的吞吐量,而在作业的执行中,较早启动它们可以降低延迟。Map和reduce的slot数量是由集群管理员配置的固定值,因此闲置的map资源无法启动reduce任务,反之亦然。因为这两种类型的任务可能(并且通常是)在不同的速率下完成,没有配置是永远完美的。当任何一种类型的slot被用尽时,尽管另一种类型还有可用的slot,但是JobTracker被迫对作业初始化施加压力。单个节点上资源的非静态定义使调度更加复杂,但是它也使得调度器可以更好的管理集群。
因此新的计算平台应该支持各个节点的动态资源配置以及灵活的资源模型。
Gaia系统架构
1. Hadoop 1.0架构
Hadoop1.0的架构中,主要有两个组成部分,分别是JobTracker和TaskTracker。
JobTracker负责worker节点(TaskTracker)的资源管理,跟踪资源使用率,管理作业的生命周期,如调度作业的各个任务,跟踪进度,以及为任务提供容灾服务。
TaskTracker的职责比较简单——根据JobTracker的命令启动/清除任务,并且周期性地向JobTracker提供任务的状态信息。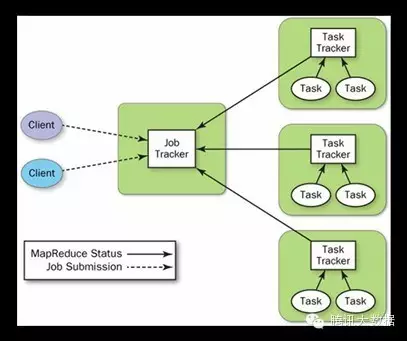
图3. Hadoop1.0 v.s. 2.0架构
2.Yarn的项目背景
Apache Hadoop MapReduce是当下最流行的开源MapReduce模型,但是2.0重写代码的勇气来自于哪里?是否真的有必要全部重构。本节主要讲下Yarn的背景。
按照我个人的理解,把Yarn的项目背景总结为下面两个主要方面:
解决Hadoop 1.0中已知的太多问题
首先承认,Hadoop 1.0是一个非常优秀非常成功的开源系统,但也逐渐的暴露了太多的问题,这里主要说明几个与资源管理调度相关的问题。
1)可靠性
作为底层系统,可靠性至为重要,但是Jobtracker确是hadoop中的单点,对生产环境中的业务是一个致命伤,这也是很多公司对hadoop做的第一个改造。
2)可扩展性
云计算常常伴随的是大数据,随着业务规模的扩大,hadoop集群的可扩展性问题越来越凸显,而在原来的架构下,hadoop 1.0的单cluster集群上限的官方数字是3000(yahoo),但是实际中已经有很多公司需要达到万台规模。
3)兼容性
Hadoop 1.0的兼容性经常被用户诟病,不同版本的Hadoop的不兼容,严重影响了用户的升级积极性。
4)资源使用率
Hadoop1.0以slot管理资源,而不是按照作业的使用资源需求,造成了很大的资源浪费,在资源使用率上是一大损失。
支持非Mapreduce的计算框架
3. Yarn架构
YARN的基本思想是将JobTracker的两大主要职能:资源管理、作业的调度/监控拆分为两个独立的进程:一个全局的ResourceManager和与每个application对应的ApplicationMaster(AM)。ResourceManager和每个节点上的NodeManager(NM)组成了全新的通用操作系统,以分布式的方式管理应用程序。
ResourceManager拥有为系统中所有应用的资源分配的决定权。对应于每个application的ApplicationMaster是框架相关的,负责与ResourceManager协商资源,以及与NodeManager协同工作来执行和监控各个任务。
ResourceManager有一个可插拔的调度器组件——scheduler,负责为运行中的各种应用分配资源,分配时会受到容量,队列及其他因素的制约。Scheduler是一个纯粹的调度器,不负责application的监控和状态跟踪,也不保证在application失败或者硬件失败的情况下对task的重启。Scheduler基于application的资源需求来执行其调度功能,使用了叫做资源 container的抽象概念,其中包括了多种资源维度,如内存,CPU,磁盘,以及网络。
NodeManager是与每台机器对应的slave进程,负责启动application的container,监控它们的资源使用情况(CPU,内存,磁盘和网络),并且报告给ResourceManager。
每个application的ApplicationMaster负责与Scheduler协商合适的container,跟踪application的状态,以及监控它们的进度。从系统的角度讲,ApplicationMaster也是以一个普通container的身份运行。
图4. Yarn架构
Gaia对Yarn的扩展
1. 自研高性能调度器sfair
Yarn调度器主要分为三个阶段:
1)选择一个队列:递归的对子队列进行排序,找到第一个可以assign的队列,从而找到叶子队列;
2)选择一个app:对本队列的所有app进行排序,然后遍历这些app,找到可以assign的那个app;
3)执行matchmaking。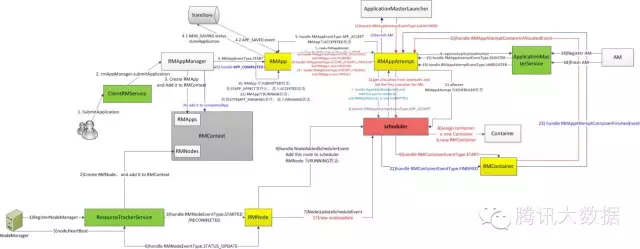
图5. scheduler
Gaia今年内的目标是,支持单cluster 8800节点的规模,而Yarn原生的调度器显然不满足要求,为此,我们开发了自研的调度器sfair(scalable fair scheduler),主要着力于提升可扩展性。在开发sfair调度器的过程中,我们通过减少sort次数、优化comparator、控制多线程的同步,以及仔细的profiling,找到关键路径。目前已经上线,并且大幅度的提升了调度吞吐,支持毫秒级的下发。同时,优化了作业优先级和抢占的策略,使调度更加公平。
具体的优化手段及内容,将在后续文章中详细介绍。
2. 更高要求的HA
目前,Yarn上的主流应用还是离线的MapReduce居多,也就是Yarn的第一个目标,兼容旧的Hadoop 1.0中的主要应用。而在腾讯的场景下,业务种类更加多样,规模也更大,尤其是我们要支持实时计算、service服务等类型的应用,对作为底层系统的Gaia能够提供的HA机制要求显然就要更高。
根据作业执行的各个环节,Gaia需要以下三个方面的HA:
1)NM HA;
2)RM HA;
3)AM HA
其中,NM的lost是Yarn可以自动发现和处理的。但是我们仍然可以进一步优化,比如在升级NM的时候,可以采用ISSU的机制,保证NM重启的过程中,上层的container不受到影响。
对于RM HA,社区的最新版本已经做了一部分工作,但是还远远不够,我们希望做到RM的fail对用户应用程序完全无感知。对于AM类似,2.2版本,Yarn的一个AM fail时,整个AppAttempt都会失败,所有对应的container将会被回收,代价非常高的。我们结合设计最新的版本思路,正在开发AM retain的特性,期待和上层应用结合,一起解决这个问题。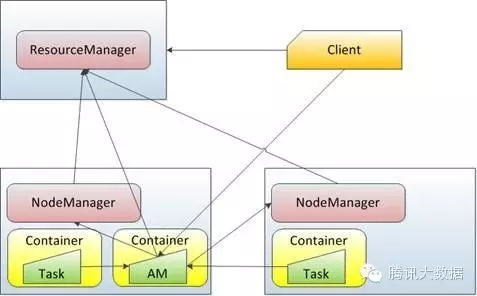
图6. Gaia HA需求
3. 资源管理
即使是最新的社区版本,也仅仅实现了cpu和memory的管理。Gaia在资源管理方面,积累了较多的经验。我们的计划是,一方面优化现有的资源管理机制,一方面增加资源管理维度。
现有版本的YARN通过Cgroups对CPU资源进行分配,通过启动监控线程对内存进行监控。通过Cgroups可以保证container使用的最小CPU占用率,可以满足我们的需要。而对内存的监控有如下问题:
(1)监控线程定时运行,不能达到实时监控的目的,很可能出现OOM现象而未检测到或造成严重后果。
(2)目前监控机制属于hardlimit,当系统有充足资源时杀掉超出使用内存的container并不是很合理的解决方式。
(3)无法充分利用整机资源,也就是说,container如果没有用到资源声明的资源需求,这部分内存资源就浪费掉了,不能share给其他所需要的container。
为此,我们引入了EMC(Elastic Memory Control)弹性内存管理机制,解决了上述问题,具体机制也请期待我们后续的文章。
在资源管理维度方面,我们正在开发Network IO控制,后续还将引入disk IO、disk space的控制。建立起一个全方位的资源管控网,使各种物理资源全部在Gaia的统一掌控下。
4. 丰富Gaia用户api
Yarn已经提供了很多基本的用户api,但是在实际应用中,我们发现,还远远不足,比如MR的开发同事就已经发现了某些场景下,MR内部的抢占无法很好的实施。对于service 作业,对灰度升级的支持也不是很好,有些甚至不必“劳烦”底层Gaia的调度,现在还不得不走调度的overhead。为此,我们会增加Reload/Update Container等接口。
5. 建立“on Gaia”生态圈
Gaia要支持storm、spark,甚至是腾讯的一些其他的service服务进程,并且spark、storm等应用都会上一定的规模,社区的xxx on yarn,有很多还属于“玩具”性质,无法满足业务生产环境的运营需求,为此,Gaia将会配合应用的需求,深入了解各种应用,与数据平台部的同事们一道,建立和完善Gaia应用生态圈。反过来,这些应用发现的很多问题,对Gaia的各种需求,也会反作用于底层系统,帮助底层的Gaia更加完善。
6. 多维运营
除了开发,对集群管理系统的运营也极其重要。我们扩充了很多metric,并且增加了多维度的报表,诊断系统、以及细化告警、辅助debug等方面,这里要特别感谢运维同事。将我们的系统真正运转起来。不但有对系统的监控和运营,在应用级别也有各种监控,常常可以发现很多系统级监控无法发现的问题,也可以提前帮助业务发现并端决问题。