Lambda表达式获取传入的方法引用的方法名
文章目录
- MyBatisPlus如何获取方法引用的方法名
- MyBatisPlus如何得到SerializedLambda
- 更简单的得到SerializedLambda的方法
- 总结
MyBatisPlus的lambdaQuery,可以在构造查询条件时传递方法的引用,MyBatis能够将方法引用解析成为要查询的DB字段名,如下
Wrappers.<Member>lambdaQuery().eq(Member::getMemberId, memberId);
// where member_id = #{memberId}
如何做到的?首先根据已有知识推测一下,MyBatisPlus是根据PO属性名转化为DB字段名的,这中间只要把变量的驼峰命名转为下划线命名即可,所以得到PO属性名就能得知DB字段名;而如果知道getMemberId这个方法名,就能够得知字段名memberId。所以猜测这里MyBatisPlus是得到了方法引用的方法名,然后推测出了字段名;
MyBatisPlus如何获取方法引用的方法名
然后跟踪lambdaQuery的eq方法调用链,如下:
在StringUtils.resolveFieldName可以看到如下代码,可以证明MyBatisPlus确实是得到了方法引用的方法名,然后将方法名转换为字段名:
public static String resolveFieldName(String getMethodName) {
if (getMethodName.startsWith("get")) {
getMethodName = getMethodName.substring(3);
} else if (getMethodName.startsWith(IS)) {
getMethodName = getMethodName.substring(2);
}
// 小写第一个字母
return StringUtils.firstToLowerCase(getMethodName);
}
同时在getColumn中可以看到,这里的方法名是通过SerializedLambda.getImplMethodName方法得到的。LambdaUtils.resolve(SFunction
// lambda表达式所在外部类的类对象
private final Class<?> capturingClass;
// lambda表达式代替的函数式接口
private final String functionalInterfaceClass;
// lambda表达式代替的函数
private final String functionalInterfaceMethodName;
// lambda表达式代替函数的签名,是这种形式:(Ljava/lang/Object;)V
private final String functionalInterfaceMethodSignature;
// lambda表达式执行时,实际执行的是一个方法,这个属性是实际执行方法所在类的类名,如:java/io/PrintStream
private final String implClass;
// lambda表达式执行时,执行的方法名称,如:println
private final String implMethodName;
// lambda表达式执行时,执行的方法的签名:如:(Ljava/lang/Object;)V
private final String implMethodSignature;
// lambda表达式执行时,动态调用通过MethodHandle实现,这里是MethodHandle在JVM层次引用的指令类型;具体见MethodHandleInfo;
private final int implMethodKind;
// lambda表达式代替的函数式接口如果存在泛型,则这个属性是泛型在lambda中实际应用的类型的签名,如:(Ljava/lang/Long;)V
private final String instantiatedMethodType;
// MethodHandle调用时的动态参数
private final Object[] capturedArgs;
字段较多,但目的是获取方法引用的方法名,所以只需要用到implMethodName一个字段就行;源码跟踪到现在,得到一个结论:得到SerializedLambda,就能得知Lambda表达式中方法引用的方法名。
MyBatisPlus如何得到SerializedLambda
既然得到了SerializedLambda就能得知引用的方法名,那么重点就转移到了如何获取SerializedLambda上。
继续跟踪MyBatisPlus源码,发现获取的方式在com.baomidou.mybatisplus.core.toolkit.support.SerializedLambda.resolve()中;这里有一个要注意的地方,我们前面跟踪代码的时候,使用到的是com.baomidou.mybatisplus.core.toolkit.support包下的SerializedLambda,同时在java.lang.invoke包下也有一个SerializedLambda,这两个类中的字段名一样,方法基本相同(都是些getter和setter),具体为什么MyBatisPlus要再写一个同名类,下面具体分析,先来分析代码:
public static SerializedLambda resolve(SFunction lambda) {
// isSynthetic返回值代表对象是否是一个自动生成的类,lambda、匿名内部类都属于自动生成的类;
if (!lambda.getClass().isSynthetic()) {
throw ExceptionUtils.mpe("该方法仅能传入 lambda 表达式产生的合成类");
}
// 这里将lambda表达式序列化写入ObjectInputStream,然后再反序列化回来,得到了SerializedLambda(readResolve)
try (ObjectInputStream objIn = new ObjectInputStream(new ByteArrayInputStream(SerializationUtils.serialize(lambda))) {
// 先说说这个方法的作用;resolveClass是在反序列化对象时,决定得到的对象的类型;
// 因为在序列化一个对象的时候,实际写到流中的对象数据,可能并不是被序列化的对象的类型,而是一个其他类型的对象;(writeReplace)
// 所以反序列化对象的时候,也需要根据对象流中的描述信息,来决定反序列化为一个什么类型的对象
@Override
protected Class<?> resolveClass(ObjectStreamClass objectStreamClass) throws IOException, ClassNotFoundException {
// ObjectStreamClass 是对象流中数据的描述信息
// 如果对象流中的数据是jdk的SerializedLambda类型,则将对象反序列化为MyBatisPlus声明的SerializedLambda;否则按照对象流中的类型反序列化;
Class<?> clazz = super.resolveClass(objectStreamClass);
return clazz == java.lang.invoke.SerializedLambda.class ? SerializedLambda.class : clazz;
}
}) {
return (SerializedLambda) objIn.readObject();
} catch (ClassNotFoundException | IOException e) {
throw ExceptionUtils.mpe("This is impossible to happen", e);
}
}
代码分析中有两个疑问:
- 为什么MyBatisPlus工具中,lambda序列化后,反序列化回来不是一个lambda表达式?
- 为什么序列化对象到对象流时,写入到流的对象类型和实际需要序列化的对象类型可能不同?
为了解决这两个疑问,需要简单的了解一下对象序列化中的 writeReplace 和 readResolve:
-
writeReplace:在将对象序列化之前,如果对象的类或父类中存在writeReplace方法,则使用writeReplace的返回值作为真实被序列化的对象;writeReplace在writeObject之前执行;
-
readResolve:在将对象反序列化之后,ObjectInputStream.readObject返回之前,如果从对象流中反序列化得到的对象所属类或父类中存在readResolve方法,则使用readResolve的返回值作为ObjectInputStream.readObject的返回值;readResolve在readObject之后执行;
函数式接口如果继承了Serializable,使用Lambda表达式来传递函数式接口时,编译器会为Lambda表达式生成一个writeReplace方法,这个生成的writeReplace方法会返回java.lang.invoke.SerializedLambda;可以从反射Lambda表达式的Class证明writeReplace的存在(具体操作与截图在后面);所以在序列化Lambda表达式时,实际上写入对象流中的是一个SerializedLambda对象,且这个对象包含了Lambda表达式的一些描述信息;
SerializedLambda类中有readResolve方法,这个readResolve方法中通过反射调用了Lambda表达式所在外部类中的**$deserializeLambda$**方法,这个方法是编译器自动生成的,可以通过反编译.class字节码证明(具体操作与截图在后面);$deserializeLambda$方法内部解析SerializedLambda,并调用LambdaMetafactory.altMetafactory或LambdaMetafactory.metafactory方法(引导方法)得到一个调用点(CallSite),CallSite会被动态指定为Lambda表达式代表的函数式接口类型,并作为Lambda表达式返回;所以在从对象流反序列化得到SerializedLambda对象之后,又被转换成原来的Lambda表达式,通过ObjectInputStream.readObject返回;
如此,可以解答上面的两个疑问:
- 为什么MyBatisPlus工具中,lambda序列化后,反序列化回来不是一个Lambda表达式?
正常的Lambda表达式序列化再反序列化,得到的还是一个Lambda表达式;
但在MyBatisPlus中,反序列化对象流之前,MyBatisPlus使用自己声明的com.baomidou.mybatisplus.core.toolkit.support.SerializedLambda来代替JDK中的java.lang.invoke.SerializedLambda;而MyBatisPlus声明的SerializedLambda中没有readResolve方法,所以readObject的返回值是代表了Lambda表达式信息的com.baomidou.mybatisplus.core.toolkit.support.SerializedLambda对象,而不是一个Lambda表达式;
MyBatisPlus使用自己声明的SerializedLambda来反序列化对象没有报错,是因为它与JDK中的SerializedLambda有相同的serialVersionUID和字段名,反序列化时会认为是正确的类,具体内容就不探讨了。 - 为什么序列化对象到对象流时,写入到流的对象类型和实际需要序列化的对象类型可能不同?
因为writeReplace机制的存在,序列化Lambda表达式时,实际写入对象流的,是含有Lambda表达式描述信息的SerializedLambda,而不是具体的Lambda表达式;
更简单的得到SerializedLambda的方法
我们的目的是得到SerializedLambda,看一下上面的流程,如果函数式接口实现了Serializable,在Lambda表达式编译时生成的writeReplace方法不就能直接得到SerializedLambda?上手测试一番:
首先声明函数式接口,因为函数式接口必须实现Serializable,所以没有用JDK自带的几个:
public interface SerializableConsumer<T> extends Serializable {
void accept(T t);
}
再写一个调用Lambda表达式的方法:
public class LambdaTest {
public static void main(String[] args) throws Exception {
doConsume(System.out::println);
}
private static void doConsume(SerializableConsumer<Long> consumer) throws Exception {
consumer.accept(123L);
// 直接调用writeReplace
Method writeReplace = consumer.getClass().getDeclaredMethod("writeReplace");
writeReplace.setAccessible(true);
Object sl = writeReplace.invoke(consumer);
SerializedLambda serializedLambda = (SerializedLambda) sl;
System.out.println(serializedLambda);
}
}
可以看到,使用方法引用声明的Lambda表达式,在编译后是存在writeReplace方法的,而且返回值确实是SerializedLambda类型:


确认可以直接反射调用writeReplace得到(肯定可以啊,JDK里都是这样用的),就不需要像MyBatisPlus中那样序列化再反序列化一次了。
另外还是再试一下序列化的方式,写一个测试方法:
public static void main(String[] args) throws Exception {
doConsumeWithSerialize(System.out::println);
}
private static void doConsumeWithSerialize(SerializableConsumer<Long> consumer) throws Exception {
consumer.accept(123L);
// 先序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(consumer);
// 再反序列化
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(baos.toByteArray()));
SerializableConsumer<Long> newConsumer = (SerializableConsumer<Long>) ois.readObject();
newConsumer.accept(234L);
}
上面这个测试方法在序列化时报错,因为传递的方法引用是System.out::println,是一个特定实例方法引用,实例方法引用在调用时需要知道实例对象,因此序列化时会将System.out放到SerializedLambda的capturedArgs中(MethodHandle调用时需要的动态参数)。而System.out是PrintStream类型,没有实现Serializable接口,所以序列化SerializedLambda时报错。
这里改一下代码,使用静态方法引用:
public static void printIt(Long l) {
System.out.println(l);
}
public static void main(String[] args) throws Exception {
doConsumeWithSerialize(LambdaTest::printIt);
}
private static void doConsumeWithSerialize(SerializableConsumer<Long> consumer) throws Exception {
consumer.accept(123L);
// 先序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(consumer);
// 再反序列化
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(baos.toByteArray()));
SerializableConsumer<Long> newConsumer = (SerializableConsumer<Long>) ois.readObject();
newConsumer.accept(234L);
}
反编译一下LambdaTest.class,看到确实有$deserializeLambda$方法;
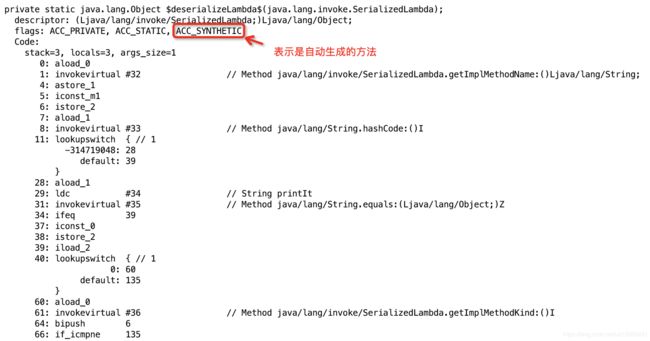
$deserializeLambda$方法内部是一系列switch和if判断,判断SerializedLambda中的信息是不是在LambdaTest类中使用到的可序列化的函数式接口,如果是就通过引导方法;在返回语句中,调用了引导方法#0,将调用点与SerializableConsumer接口绑定,返回一个SerializableConsumer类型的实例;

引导方法#0如下:

总结
- 要得到Lambda表达式中方法引用的方法名,目前已知的方式是通过SerializedLambda;
- SerializedLambda是对Lambda表达式进行描述的对象,在Lambda表达式可序列化的时候(函数式接口继承Serializable)才能得到;
- 函数式接口继承Serializable时,编译器在编译Lambda表达式时,生成了一个writeReplace方法,这个方法会返回SerializedLambda,可以反射调用这个方法;