编译spark源码的方法,及编译、案例测试问题总结
一、编译spark方法
1.编译环境
首先,需要安装jdk、maven,相关安装教程请参考:http://blog.csdn.net/u012829611/article/details/77651855
http://blog.csdn.net/u012829611/article/details/77678609
笔者安装的jdk1.7、maven3.3.9.
然后,在官网下载spark源码(http://spark.apache.org/downloads.html),我这里选择的版本是spark-1.6.2.tgz
把源码包解压:
[root@localhost soft-cy]# tar -zxvf spark-1.6.2.tgz
[root@localhost soft-cy]# cd spark-1.6.22.两种编译方法
①用build/mvn 来编译(采用)
[root@localhost spark-1.6.2]# build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package(-Pyarn 提供yarn支持 ,—Phadoop-2.7 提供Hadoop支持,并且指定hadoop的版本2.7.3)

编译完成后,你会发现在assembly/target/scala-2.10目录下面有一个spark-assembly-1.6.2-hadoop2.7.3.jar包,这个就是编译的结果。
②用make-distributed 脚本来编译
[root@localhost spark-1.6.2]# ./make-distribution.sh --name spark-1.6.2 --skip-java-test --tgz -Pyarn -Dhadoop.version=2.7.3 -Phive -Phive-thriftserver编译完源代码后,虽然直接用编译后的目录再加以配置就可以运行spark,但是这时目录很庞大,部署起来很不方便,所以需要生成部署包。生成在部署包位于根目录下,文件名类似于 spark–bin-spark-1.6.2.tgz 。
二、编译遇到问题总结
1.依赖包下载不下来的问题
如下图,显示一些相关依赖包下载不下来,即downloading过程中停止

【解决方法】:手动下载相关依赖包,并放到指定目录下即可。
以上图中第一个依赖包为例Downloading:https://repo1.maven.org/maven2/org/apache/curator/curator-test/2.4.0/curator-test-2.4.0.jar
具体下载方法如下:从上面下载链接中可以看出依赖包存放的目录(/root/.m2/repository/org/apache/curator/curator-test/2.4.0),上面链接中加粗的部分。因此,直接cd到相应目录,wget即可。
[root@localhost ~]# cd /root/.m2/repository/org/apache/curator/curator-test/2.4.0
[root@localhost 2.4.0]# wget https://repo1.maven.org/maven2/org/apache/curator/curator-test/2.4.0/curator-test-2.4.0.jar注:用maven进行编译时,下载的相关依赖包都放在maven库中,maven库的目录为:/root/.m2/repository
2.通过编辑pom.xml文件,注释相应的module,可以编译时跳过相应的Project,这样可以方便调试。

3.使用第二种方法编译时,会报如下错:

解决方法:编辑make-distribution.sh文件,注释掉下图中阴影部分,保存即可。

参考文档:
http://blog.csdn.net/yanran1991326/article/details/46506595
http://blog.csdn.net/ouyangyanlan/article/details/52355350
三、案例测试问题
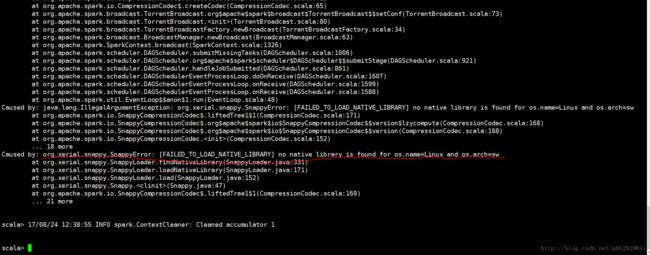
spark编译成功后,cd到 spark1.6.2/bin 目录下,运行 spark-shell 命令启动spark,进入scala命令模式。运行案例测试,输入 sc.parallelize(1 to 1000).count() 命令,会报下图中错误:
[root@node1 spark-1.6.2]# cd bin/
[root@localhost bin]# spark-shell
scala> sc.parallelize(1 to 1000).count()错误信息:“org.xerial.snappy.SnappyError: [FAILED_TO_LOAD_NATIVE_LIBRARY] no native library is found for os.name=Linux and os.arch=sw”。表示:snappy不支持Linux-sw操作系统。
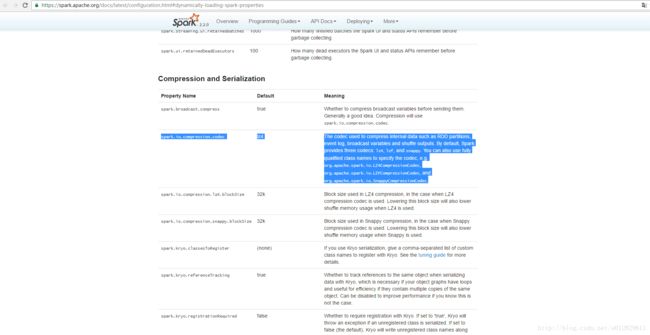
解决方法:spark默认的解压缩工具为snappy,查看官网及github上,发现spark可选解压缩工具有三种lz4、lzf、snappy,于是可将spark默认的解压缩工具改为lzf。
官网:https://spark.apache.org/docs/latest/configuration.html#dynamically-loading-spark-properties
github:https://github.com/xerial/snappy-java/issues/178
具体执行过程:
[root@node1 spark-1.6.2]# cd conf/
[root@node1 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@node1 conf]# vim spark-defaults.conf在最后添加命令 spark.io.compression.codec lzf

添加命令后,保存退出,重新启动spark,运行案例测试,结果显示成功。
案例1:统计整数个数
[root@localhost bin]# spark-shell
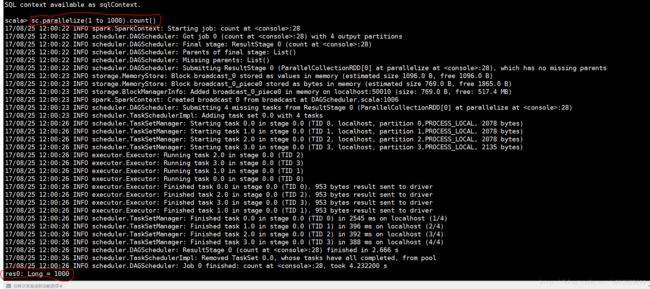
scala> sc.parallelize(1 to 1000).count()运行可以看到,结果显示 res0: Long = 1000 表示成功!
案例2:计算pi的值
[root@localhost bin]# run-example SparkPi
运行可以看到,结果显示 Pi is roughly 3.14552 表示成功!

参考文档:https://github.com/xerial/snappy-java/issues/178