Dubbo源码解析(十七)Dubbo 处理TCP粘包拆包
文章目录
- 什么是粘包拆包
- TCP 粘包/拆包 问题解析
- 发生的原因
- 粘包问题的解决策略
- dubbo是如何处理粘包和拆包的
- 解析消息头
- 解析消息体
- 拆包、粘包
- 相关文档
什么是粘包拆包
此章节出自《Netty权威指南第二版》
TCP是个“流”协议,所谓流,就是没有界限的一串数据。大家可以想想河里的流水,是连成一片的,其间并没有分界线。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
TCP 粘包/拆包 问题解析
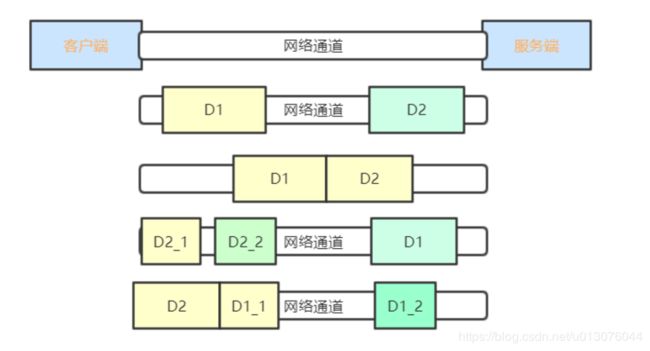
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到的字节数是不确定的,故可能存在以下4种情况。
(1)服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包;
(2)服务端一次接收到了两个数据包,D1和D2粘合在一起,被称为TCP粘包;
(3)服务端分两次读取到了两个数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这被称为TCP拆包;
(4)服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余内容D1_2和D2包的整包。
如果此时服务端TCP接收滑窗非常小,而数据包D1和D2比较大,很有可能会发生第五种可能,即服务端分多次才能将D1和D2包接收完全,期间发生多次拆包。
发生的原因
首先看一下应用向系统内核写入信息的整个流程
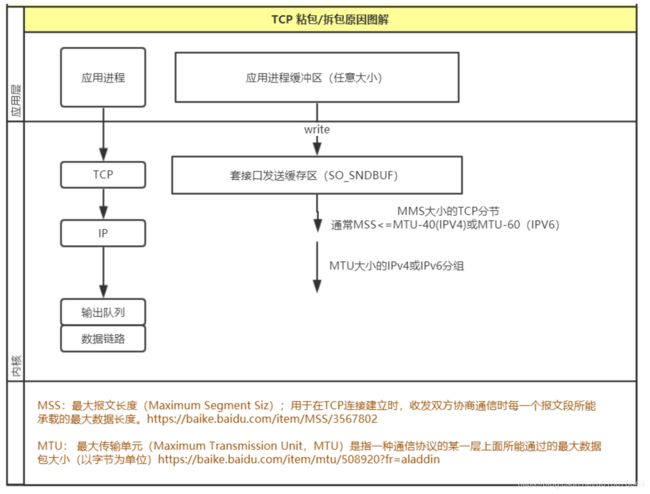
问题产生的原因大致有三个,分别如下:
(1)应用程序write写入的字节大小大于套接口发送缓冲区大小;
(2)进行MSS大小的TCP分段;
(3)以太网帧的payload大于MTU进行IP分片
这里举一个具体的例子说明IP包分片的原理。以太网的MTU值是1500 bytes,假设发送者的协议高层向IP层发送了长度为3008 bytes的数据报文,
则该报文在添加20 bytes的IP包头后IP包的总长度是 3028 bytes,因为3028 > 1500,所以该数据报文将被分片,
注意:分片时仅仅对上层的数据进行分片,不需要对原来的IP首部分片,所以要分片的数据长度只有3008,而不是3028. 这特别容易出错。
分片过程如下:
1. 首先计算最大的IP包中IP净荷的长度 =MTU-IP包头长度=1500-20= 1480 bytes。
2. 然后把3008 bytes按照1480 bytes的长度分片,将要分为3片,3008= 1480+1480+48。
3. 最后发送者将为3个分片分别添加IP包头,组成3个IP包后再发送,3个IP包的长度分别为1500 bytes、1500 bytes和 68 bytes。
从以上分片例子可以看出第一、二个分片包组成的IP包的长度都等于MTU即1500 bytes。
粘包问题的解决策略
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案,可以归纳如下。
(1)消息定长,例如每个报文的大小为固定长度200字节,如果不够,空位补空格;
(2)在包尾增加回车换行符进行分割,例如FTP协议;
(3)将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度)的字段,通常设计思路为消息头的第一个字段使用int32来表示消息的总长度;
(4)更复杂的应用层协议。
dubbo是如何处理粘包和拆包的
dubbo采用的是以上策略的第四种,通过规定应用层的协议来解决这个问题。那么dubbo的具体协议是什么样子呢?
可以参考这篇博文
点我查看 dubbo 协议探秘
通过dubbo协议的设计,我们可以知道dubbo分为消息头和消息体,消息头里面有整个消息体的大小。
在上一篇博客中,我们知道在dubbo中,默认是用netty作为tcp/ip服务器的,通过netty提供的客户端和服务端进行通信。在上一篇博客(https://blog.csdn.net/u013076044/article/details/89061592)可以看到是在进行初始化服务器的时候,把Encoder和 Decoder作为Handler设置进去的。
由于本篇文章是对服务器和客户端相互传输过程中的粘包拆包问题,所以这里只对Dubbo协议的decode过程进行解析。
在dubbo中,Exchanger扮演着把消息体解析为request和response的角色。
那么接下来我们一起看一下这个操作,Exchanger是如何完成的?
ExchangeCodec.java
// 入口方法
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
//
int readable = buffer.readableBytes();
//
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
buffer.readBytes(header);
return decode(channel, buffer, readable, header);
}
以上是在信息交换层接收到传输层接收的二进制流,从而开始进行解析的入口方法
- 首先先判断此次传输的信息包的大小
- 根据传输包的大小,确定本次传输的信息是否包含整个请求头,取与请求头固定长度比较最小值,然后读取相关信息到header中。如果此次信息包大于等于16字节,说明请求头是完整的。
解析消息头
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number.
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
// check length.
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length.
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
return decodeBody(channel, is, header);
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is);
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
}
这个方法主要是检查请求头的相关信息
- 检查魔法数,魔法数高位和低位各占1字节
- 检查当前请求头是否完整,如果不完整直接返回
- 获取此次请求体的长度。然后判断 请求头+消息体长度 是否 大于此次消息包的长度,如果大于的话,说明此次的消息不是完整的一个消息,也意味着进行拆包了,直接返回,等待其它信息
- 解析消息体
解析消息体
DubboCodec.java
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
Serialization s = CodecSupport.getSerialization(channel.getUrl(), proto);
ObjectInput in = s.deserialize(channel.getUrl(), is);
// get request id.
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// decode response.
Response res = new Response(id);
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(Response.HEARTBEAT_EVENT);
}
// get status.
byte status = header[3];
res.setStatus(status);
if (status == Response.OK) {
try {
Object data;
// 如果是心跳信息
if (res.isHeartbeat()) {
data = decodeHeartbeatData(channel, deserialize(s, channel.getUrl(), is));
} else if (res.isEvent()) {
// 如果是事件
data = decodeEventData(channel, deserialize(s, channel.getUrl(), is));
} else {
//
DecodeableRpcResult result;
// 是否直接在io线程进行解码
if (channel.getUrl().getParameter(
Constants.DECODE_IN_IO_THREAD_KEY,
Constants.DEFAULT_DECODE_IN_IO_THREAD)) {
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
// 解码
result.decode();
} else {
// 封装不解码,这样会下沉到Protocol层去解码。
result = new DecodeableRpcResult(channel, res,
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode response failed: " + t.getMessage(), t);
}
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
} else {
res.setErrorMessage(deserialize(s, channel.getUrl(), is).readUTF());
}
return res;
} else {
// decode request.
// 省略
}
}
这一步骤是解析request和response。以response为例
- 首先判断这一次是请求还是响应
- 根据消息解析出来的此次响应/请求的status,判断此次的消息是否正常
- 解析此次的消息使用的序列化方式,然后进行反序列化,这里会反序列化为一个Object,可以参照Hessian2ObjectInput
- 解析成功,返回response到上游方法
拆包、粘包
以上步骤只是针对正常的dubbo协议在Exchanger的解析,在解析消息头的时候,可以看到当消息不完整的时候,返回了一个DecodeResult.NEED_MORE_INPUT,那么上游方法是怎么处理的呢?
NettyCodecAdapter#InternalDecoder
public void messageReceived(ChannelHandlerContext ctx, MessageEvent event) throws Exception {
Object o = event.getMessage();
if (!(o instanceof ChannelBuffer)) {
ctx.sendUpstream(event);
return;
}
ChannelBuffer input = (ChannelBuffer) o;
int readable = input.readableBytes();
if (readable <= 0) {
return;
}
com.alibaba.dubbo.remoting.buffer.ChannelBuffer message;
// 将接收到的消息写入到buffer里面
if (buffer.readable()) {
if (buffer instanceof DynamicChannelBuffer) {
buffer.writeBytes(input.toByteBuffer());
message = buffer;
} else {
int size = buffer.readableBytes() + input.readableBytes();
message = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.dynamicBuffer(
size > bufferSize ? size : bufferSize);
message.writeBytes(buffer, buffer.readableBytes());
message.writeBytes(input.toByteBuffer());
}
} else {
message = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.wrappedBuffer(
input.toByteBuffer());
}
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.getChannel(), url, handler);
Object msg;
int saveReaderIndex;
try {
// decode object.
do {
// 解析object
saveReaderIndex = message.readerIndex();
try {
msg = codec.decode(channel, message);
} catch (IOException e) {
buffer = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.EMPTY_BUFFER;
throw e;
}
// 如果此次是不完整的消息
if (msg == Codec2.DecodeResult.NEED_MORE_INPUT) {
// 记录下次开始读取的位置
message.readerIndex(saveReaderIndex);
break;
} else {
// 如果此次解析完,消息的读指针没有变化
if (saveReaderIndex == message.readerIndex()) {
buffer = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.EMPTY_BUFFER;
throw new IOException("Decode without read data.");
}
if (msg != null) {
Channels.fireMessageReceived(ctx, msg, event.getRemoteAddress());
}
}
} while (message.readable());
} finally {
// 如果消息没有全部使用完,也就是存在粘包的状况下,保存此次消息状态
if (message.readable()) {
message.discardReadBytes();
buffer = message;
} else {
buffer = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.EMPTY_BUFFER;
}
NettyChannel.removeChannelIfDisconnected(ctx.getChannel());
}
}
首先把接收的message,写入到全局变量buffer里面,然后使用message指向buffer。通过message.readable()这个判断message是否完全处理完,从而进行循环处理。如果完全处理完了整个buffer,就清空,否则buffer等于剩下未处理的部分消息。
这样我们再把这个分析一波
第一种情况: 第一次接收到消息,首先message = D1 , 解析成功,:第二次接收到消息message = D2 , 解析成功,
第二种情况: 第一次接收到消息,首先message = D1D2 , 那么先解析出D1,但是message还处于可读状态,并且此时message=D2,然后再解析D2,
第三种情况: 第一次接收到消息message = D2_1先处理D2_1,返回DecodeResult.NEED_MORE_INPUT,buffer=D2_1, ;第二次接受到消息然后buffer = D2_1D2_2,正常解析,第三次接收到消息D1,正常处理
第四种情况: message=D2D1_1, 正常读取D2,然后 message = D1_1 返回NEED_MORE_INPUT,buffer = D1_1;第二次接收到消息 buffer = D1_1D1_2,正常解析。
相关文档
https://blog.csdn.net/u013076044/article/details/84575235 dubbo 协议探秘
https://blog.csdn.net/u013076044/article/details/78638381 原生NIO粘包拆包的一种解决方案