1. 线性回归:根据出生率来预测平均寿命
相信大家对线性回归很熟悉了,在这里不介绍了。我们将简单地构建一个神经网络,只包含一层,用来预测自变量X与因变量Y之间的线性关系。
- 问题描述
下面图片是关于出生率和平均寿命关系的可视化图片,数据来自全世界不同的国家。你会发现一个有趣的结论:对于一个地区,儿童越多,平均寿命就越短。详细请见.
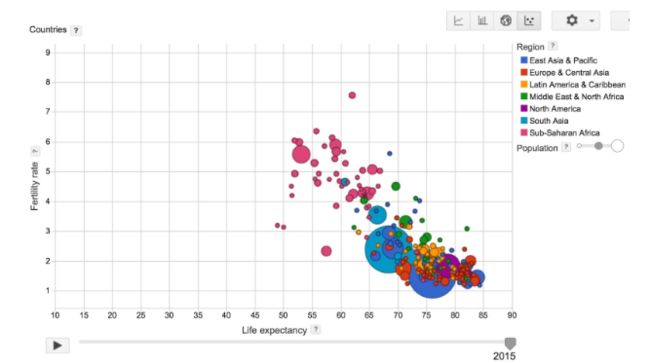
问题是我们可以量化X与Y之间的关系吗?换句话说,如果一个国家的出生率是X,平均寿命是Y,我们能够找到线性函数吗,例如Y=f(X)?如果我们量化这种关系,给出一个国家的出生率,我们就能预测这个国家的平均寿命。
完整数据集:https://datacatalog.worldbank.org/dataset/world-development-indicators
为了简便,我们仅适用2010年的数据集:https://github.com/chiphuyen/stanford-tensorflow-tutorials/blob/master/examples/data/birth_life_2010.txt - 数据描述
Name: Birth rate - life expectancy in 2010 X = birth rate. Type: float. Y = life expectancy. Type: foat. Number of datapoints: 190 - 方法
首先,我们假设出生率和寿命的关系是线性的,这就意味着我们可以找到类似Y=wX+b这种方程。
为了计算出w和b,我们将在一层神经网络使用反向传播算法。对于损失函数,使用均方差,在训练每一轮之后,我们计算出实际值与预测值Y之间的均方差。
03_linreg_starter.py
# -*- coding: utf-8 -*-
# @Author: yanqiang
# @Date: 2018-05-10 22:31:37
# @Last Modified by: yanqiang
# @Last Modified time: 2018-05-10 23:05:47
import tensorflow as tf
import utils
import matplotlib.pyplot as plt
DATA_FILE = 'data/birth_life_2010.txt'
# Step 1: read in data from the .txt file
# data is a numpy array of shape (190, 2), each row is a datapoint
data, n_samples = utils.read_birth_life_data(DATA_FILE)
# Step 2: create placeholders for X (birth rate) and Y (life expectancy)
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
# Step 3: create weight and bias, initialized to 0
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: construct model to predict Y (life expectancy from birth rate)
Y_predicted = w * X + b
# Step 5: use the square error as the loss function
loss = tf.square(Y - Y_predicted, name='loss')
# Step 6: using gradient descent with learning rate of 0.01 to minimize loss
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=0.001).minimize(loss)
with tf.Session() as sess:
# Step 7: initialize the necessary variables, in this case, w and b
sess.run(tf.global_variables_initializer())
# Step 8: train the model
for i in range(100): # run 100 epochs
for x, y in data:
# Session runs train_op to minimize loss
sess.run(optimizer, feed_dict={X: x, Y: y})
# Step 9: output the values of w and b
w_out, b_out = sess.run([w, b])
# uncomment the following lines to see the plot
plt.plot(data[:, 0], data[:, 1], 'bo', label='Real data')
plt.plot(data[:, 0], data[:, 0] * w_out + b_out, 'r', label='Predicted data')
plt.legend()
plt.show()
[utils.py以及以后其他代码都在github](https://github.com/chiphuyen/stanford-tensorflow-tutorials)
预测结果:
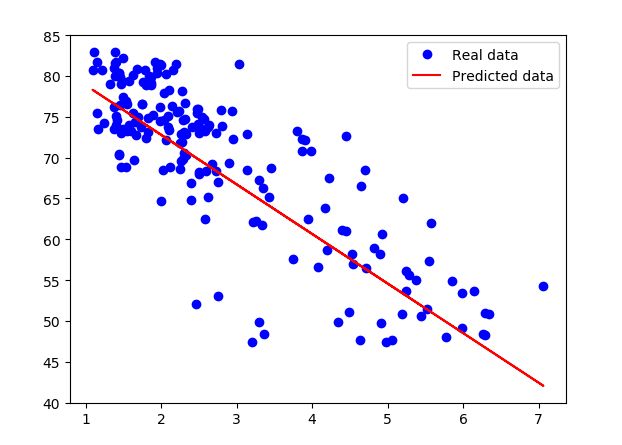
- tf.data
这部分主要介绍了tf.data以及用法,相比tf.placeholder和feed_dict提高了运算性能。使用tf.data实现上述线性回归耗时为6.12285947 ,placeholder耗时9.05271519 ,提高了大约30%的性能。
""" Solution for simple linear regression example using tf.data
Created by Chip Huyen ([email protected])
CS20: "TensorFlow for Deep Learning Research"
cs20.stanford.edu
Lecture 03
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import utils
DATA_FILE = 'data/birth_life_2010.txt'
# Step 1: read in the data
data, n_samples = utils.read_birth_life_data(DATA_FILE)
# Step 2: create Dataset and iterator
dataset = tf.data.Dataset.from_tensor_slices((data[:,0], data[:,1]))
iterator = dataset.make_initializable_iterator()
X, Y = iterator.get_next()
# Step 3: create weight and bias, initialized to 0
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: build model to predict Y
Y_predicted = X * w + b
# Step 5: use the square error as the loss function
loss = tf.square(Y - Y_predicted, name='loss')
# loss = utils.huber_loss(Y, Y_predicted)
# Step 6: using gradient descent with learning rate of 0.001 to minimize loss
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
start = time.time()
with tf.Session() as sess:
# Step 7: initialize the necessary variables, in this case, w and b
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('./graphs/linear_reg', sess.graph)
# Step 8: train the model for 100 epochs
for i in range(100):
sess.run(iterator.initializer) # initialize the iterator
total_loss = 0
try:
while True:
_, l = sess.run([optimizer, loss])
total_loss += l
except tf.errors.OutOfRangeError:
pass
print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
# close the writer when you're done using it
writer.close()
# Step 9: output the values of w and b
w_out, b_out = sess.run([w, b])
print('w: %f, b: %f' %(w_out, b_out))
print('Took: %f seconds' %(time.time() - start))
# plot the results
plt.plot(data[:,0], data[:,1], 'bo', label='Real data')
plt.plot(data[:,0], data[:,0] * w_out + b_out, 'r', label='Predicted data with squared error')
# plt.plot(data[:,0], data[:,0] * (-5.883589) + 85.124306, 'g', label='Predicted data with Huber loss')
plt.legend()
plt.show()
- Optimizers(优化器)
到这,我们还有两行代码没有解释:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
sess.run([optimizer])
认识下run函数:
run( fetches, feed_dict=None, options=None, run_metadata=None)
思考下面两个问题:
- optimizer 为什么会在fetches中?
- TensorFlow怎么知道要更新哪些变量?
optimizer的任务就是最小化损失loss。为了执行optimizer这个op,我们需要将它传给tf.Session().run()函数的参数fetches.到TensorFlow执行optimizer的时候,它将会执行optimizer所依赖的运算。在这个例子中,optimizer依赖于loss,loss依赖于X和Y,以及weights和bias.
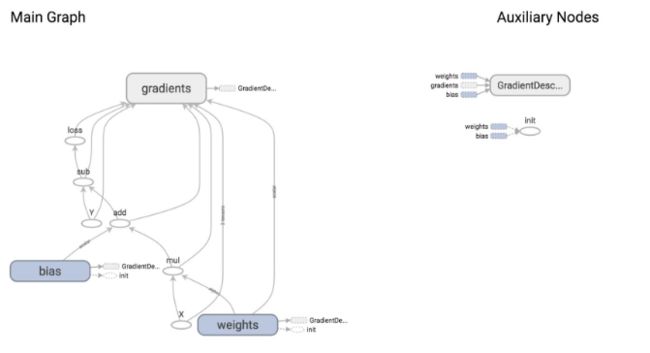
从上面这个图片,我们可以看到GradientDescentOptimizer取决于三部分:eights, bias, and gradient.
GradientDescentOptimizer 意思就是我们更新原则梯度下降,TensorFlow自动帮我们求导,然后更新w和b,以使得loss最小化。
更多关于optimizer请见官方文档优化器列表:
- tf.train.Optimizer
- tf.train.GradientDescentOptimizer
- tf.train.AdadeltaOptimizer
- tf.train.AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer
- tf.train.AdamOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
2. 逻辑归回:MNIST手写字体分类
这部分作者自己重写代码将mnist数据击下载下来,然后进行处理

代码:
""" Solution for simple logistic regression model for MNIST
with tf.data module
MNIST dataset: yann.lecun.com/exdb/mnist/
Created by Chip Huyen ([email protected])
CS20: "TensorFlow for Deep Learning Research"
cs20.stanford.edu
Lecture 03
"""
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import numpy as np
import tensorflow as tf
import time
import utils
# Define paramaters for the model
learning_rate = 0.01
batch_size = 128
n_epochs = 30
n_train = 60000
n_test = 10000
# Step 1: Read in data
mnist_folder = 'data/mnist'
utils.download_mnist(mnist_folder)
train, val, test = utils.read_mnist(mnist_folder, flatten=True)
# Step 2: Create datasets and iterator
train_data = tf.data.Dataset.from_tensor_slices(train)
train_data = train_data.shuffle(10000) # if you want to shuffle your data
train_data = train_data.batch(batch_size)
test_data = tf.data.Dataset.from_tensor_slices(test)
test_data = test_data.batch(batch_size)
iterator = tf.data.Iterator.from_structure(train_data.output_types,
train_data.output_shapes)
img, label = iterator.get_next()
train_init = iterator.make_initializer(train_data) # initializer for train_data
test_init = iterator.make_initializer(test_data) # initializer for train_data
# Step 3: create weights and bias
# w is initialized to random variables with mean of 0, stddev of 0.01
# b is initialized to 0
# shape of w depends on the dimension of X and Y so that Y = tf.matmul(X, w)
# shape of b depends on Y
w = tf.get_variable(name='weights', shape=(784, 10), initializer=tf.random_normal_initializer(0, 0.01))
b = tf.get_variable(name='bias', shape=(1, 10), initializer=tf.zeros_initializer())
# Step 4: build model
# the model that returns the logits.
# this logits will be later passed through softmax layer
logits = tf.matmul(img, w) + b
# Step 5: define loss function
# use cross entropy of softmax of logits as the loss function
entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=label, name='entropy')
loss = tf.reduce_mean(entropy, name='loss') # computes the mean over all the examples in the batch
# Step 6: define training op
# using gradient descent with learning rate of 0.01 to minimize loss
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
# Step 7: calculate accuracy with test set
preds = tf.nn.softmax(logits)
correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(label, 1))
accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32))
writer = tf.summary.FileWriter('./graphs/logreg', tf.get_default_graph())
with tf.Session() as sess:
start_time = time.time()
sess.run(tf.global_variables_initializer())
# train the model n_epochs times
for i in range(n_epochs):
sess.run(train_init) # drawing samples from train_data
total_loss = 0
n_batches = 0
try:
while True:
_, l = sess.run([optimizer, loss])
total_loss += l
n_batches += 1
except tf.errors.OutOfRangeError:
pass
print('Average loss epoch {0}: {1}'.format(i, total_loss/n_batches))
print('Total time: {0} seconds'.format(time.time() - start_time))
# test the model
sess.run(test_init) # drawing samples from test_data
total_correct_preds = 0
try:
while True:
accuracy_batch = sess.run(accuracy)
total_correct_preds += accuracy_batch
except tf.errors.OutOfRangeError:
pass
print('Accuracy {0}'.format(total_correct_preds/n_test))
writer.close()
结果:训练30epochs,准确率为91.34%
3 相关阅读
- TensorFlow学习--tf.session.run() - CSDN博客
- Tensorflow中的fetch与feed - CSDN博客