58同城宝实时数仓建设实践
背景
作为国内领先的覆盖生活全领域的服务平台,58同城业务覆盖招聘、房产、汽车、金融等生活领域的各个方面。58同城宝是针对生活服务信息做广告推广的平台,依托58同城海量的商户和每天更新的生活数据,58同城宝可以为媒体方提供最丰富最真实的生活信息,同时,媒体方也能从信息推广中获得丰厚的分成收益。本文主要介绍58同城宝团队在实时数仓建设中的一些实践经验。
实时数仓的演进
早期的数据仓库是将业务数据集中进行存储,以固定的计算逻辑定时进行ETL计算产出报表,用于支持企业管理人员的决策。伴随着互联网的快速发展,以及互联网在线服务的特性,快速获得数据反馈,并及时做出决策对企业而言越来越重要。
在此背景下,产品和业务人员对实时数据的需求也越来越多,实时处理从次要部分变成了主要部分,在离线数据仓库的基础上,逐渐出现了以实时事件处理为核心的实时数仓。
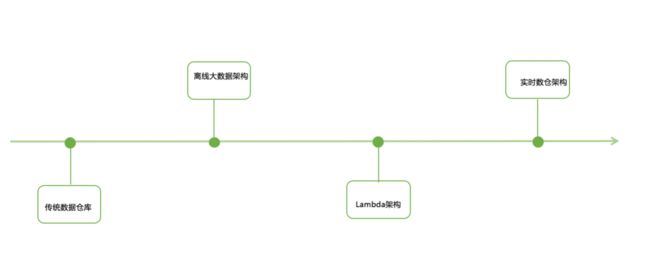
图1 展示了实时数仓的演进过程
同城宝团队实时数仓的实践
1、同城宝的业务和数据规模
同城宝依托于58同城的千万商家,百万在线广告主,专注生活服务领域,涵盖7大模块400多类别,推广内容与用户生活息息相关,对用户来说广告即内容,具备强大的流量变现能力。
目前同城宝的合作媒体包括今日头条、腾讯、vivo、快手、搜狗、360、科大讯飞、趣头条等,流量来源多元化,变现能力强大,日增数据规模在160亿条左右。
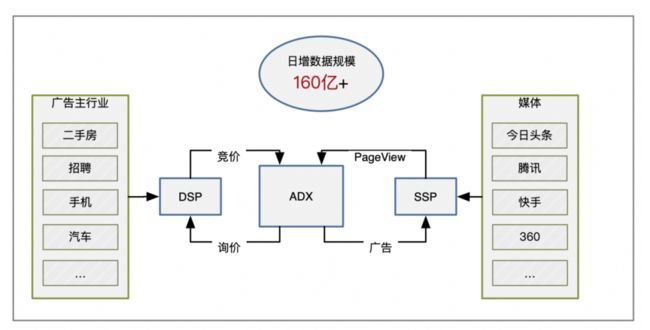
图2 展示了同城宝的业务构成和数据规模
2、实时数仓1.0
2.1 整体设计
在实时数据建设早期,由于对实时数据的需求比较琐碎,并没有形成完整的数据体系。1.0时期的实时数仓基于Spark Streaming 构建,通过实时订阅Kafka消息队列,根据维度和指标进行ETL计算,产出数据推送到下游的Druid中。
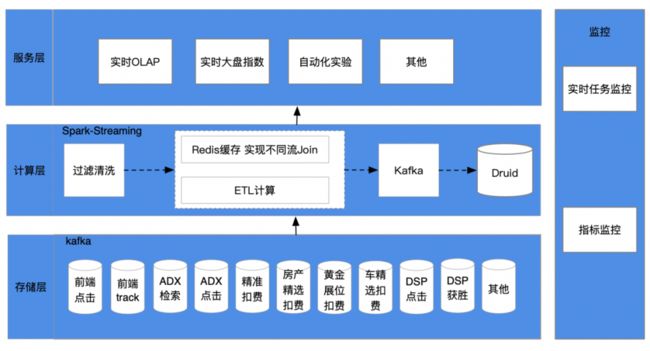
图3 展示了实时数仓1.0时期的架构图
在该架构下,实时数仓分为三层:
存储层:日志通过Flume采集至消息队列kafka中存储。
计算层:spark-streaming 订阅每个Topic,通过日志消息中的流量id作为key,缓存到Redis,或者从Redis 获取其他数据流的日志,完成数据拼接,计算维度和指标,写入下游Kakfa,并同步至终端 Druid。
服务层:通过实时查询Druid数据,满足数据分析的实时需求。
2.2 面临的问题
随着公司业务的快速发展,实时数仓需求不断增加,1.0时期的实时数据仓库体系架构已经逐渐无法支撑现有业务的更新迭代,开发和维护的成本与日俱增,主要面临的问题如下:
Spark Streaming 底层基于微批次处理的计算引擎,无法满足业务对数据秒级更新的需求。
通过Redis缓存一方数据流完成数据拼接时,使用的是Process Time ,存在数据丢失,拼接失效的问题。
实时任务数目繁多,一条实时流对应一个实时任务,不同流之间存在依赖,维护开发成本高。
目前的数仓分层体系,无法高效的支撑业务的快速迭代。
通过Redis无法解决两条流中的消息乱序的问题。
3、实时数仓2.0
为了解决1.0时期存在的问题,我们借鉴离线数仓的建设经验,引入Flink 代替Spark-Streaming ,同时通过对实时数仓进行层级划分、按主题域建模等方法,重新设计了实时数仓的架构体系。
3.1 整体架构
实时数仓2.0 的整体架构如下图所示。

图4 展示了实时数仓2.0的架构图
通过对实时数仓业务的梳理,我们将实时数仓划分为ODS层(原始数据层)、DWD层(明细数据层)、DWS层(汇总数据层)、APP层(服务层),并根据主题域进行数据划分、数据流合并。
ODS层:各业务通过Flume采集工具,将流量数据接入Kafka 的实时数据。
DWD层:业务主题建模,通过Flink 双流join ,将一个主题下的多条实时流进行 Join 计算,生成明细数据,写入下游Kafka存储。
DWS层:根据业务需求,按照一个或者多个维度,选择一定粒度对DWD层明细数据进行汇总计算,写入下游Kafka中存储。
APP层:APP层的数据来自DWD(明细数据层)和DWS(汇总数据层),可用于实时多维分析、实时大盘等。
3.2 数据质量管理
在实时数仓中,缺乏有效的数据质量监控管理,将会导致脏数据、冗余数据、不一致数据的产生,从而会引起数据无法整合、可用性差、计算性能低下等问题。对实时数仓而言,数据质量的评估维度主要是指完整性、一致性、实时性、准确性。
| 数据质量维度 |
描述 |
| 完整性 |
业务需求的数据集完备 |
| 一致性 |
数据流转中,数据的逻辑意义保持一致,不存在冲突 |
| 实时性 |
数据全生命周期流转的实时性 |
| 准确性 |
可以表达真实准确的业务指标 |
在实时数仓2.0中,我们增加了对数据质量全生命周期的监控管理,即从数据的流入、加工处理、数据的落地等一系列流程中的每个环节都通过监控告警来及时反馈数据中可能出现的问题,如下图所示。
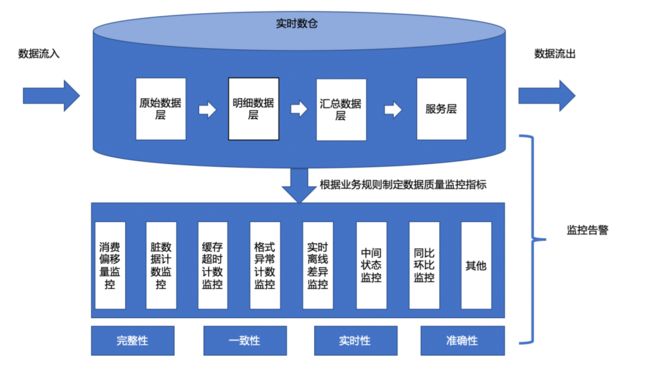
图5 展示了实时数仓2.0的数据质量保障体系
3.3 Flink在实时数仓2.0中的实践
在利用Flink 构建实时数仓的过程中,按照主题域合并数据流,每个主题下的所有数据流汇总到一个实时任务中 ,通过双流 join的方式 ,大幅减少了实时任务数,同时提升了数据的准确性。通过数据分层、主题域的划分,使数据开发的链路更清晰,减少了代码的冗余和耦合。数据实时性提升至秒级别,clk1、clk0、cash等关键指标的准确性达到99%以上。
同城宝ADX实时数仓上线后的实时和离线数据差异对比,如下图所示。
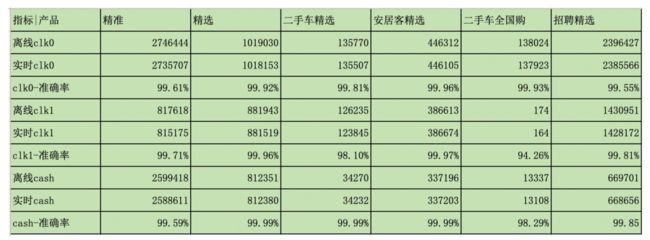
图6 展示了同城宝ADX在实时数仓2.0中的数据准确率
如下图所示,同城宝adx 进行 interval Join 的Flink 实时任务。
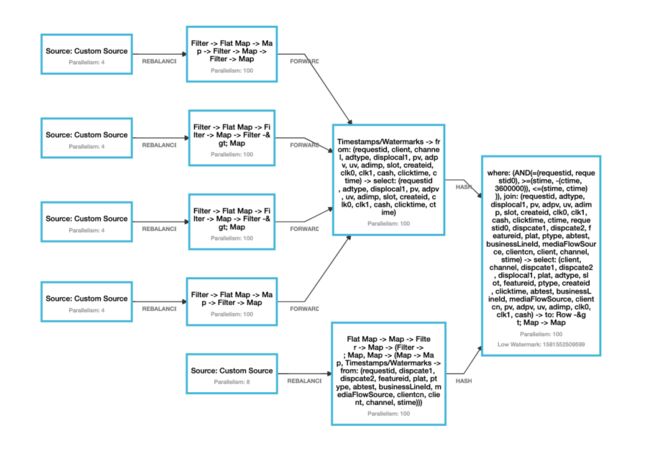
图7 展示了同城宝ADX下的所有实时流基于flink 流 join 生成的chain执行图
3.4 Flink interval join 介绍
A、双流join原理
在Flink双流join场景中,数据流会根据ON 中的关联条件key进行Shuffle重分区,从而确保两个实时流中具有相同key的数据会分配到同一个Task节点进行处理。由于数据流速不同,join的过程中会左右分别开辟LState 和RState 状态空间,缓存两边的流数据至状态中。

图8 展示了flink 双流join 的原理
常见的流关联方式如下。
inner join : 双流JOIN两边事件都会存储到State里面,直到符合join条件才会输出。
left outer join:无论右流是否有符合join的事件,左流都会流入下流节点。当右流没有可以join的事件,右边的事件信息补NULL,直到右流有可以join的事件时,撤回NULL的事件,并下发JOIN完整(带有右边事件列)的事件到下游。
right outer join :无论左流是否有符合join的事件,右流都会流入下流节点。当左流没有可以join的事件,左边的事件信息补NULL,直到左流有可以join的事件时,撤回NULL的事件,并下发JOIN完整(带有左边事件列)的事件到下游。
B、Interval Join 原理
Interval Join没有window的概念,由于数据流的无界性以及消息乱序的影响,关联上的消息可能进入处理系统的时间有较大差异,一条流中的消息,可能需要和另一条流的多条消息关联,因此两条流的数据会缓存在内部 State 中,任意一方数据到达,会获取另一方数据流相应时间范围内的数据,执行 Join 操作。

图9 展示了flink interval join 的原理
总结和展望
实时数仓2.0目前正在建设中,已经完成了大部分主题域的建设,大幅提升了数据的实时性和准确性。后续我们将继续探索和优化实时数仓的构建,完善并提升实时数仓的相关能力,继续推动Flink以及其他新技术在实时数仓中的应用实践,不断提高业务数据化、数据智能化的能力建设。
参考文献
美团点评基于 Flink 的实时数仓建设实践:
https://tech.meituan.com/2018/10/18/meishi-data-flink.html
作者简介
祁更为,商业产品技术部大数据资深工程师,主要负责58同城宝的数据智能化建设,对数据安全、数据平台建设方面有一定的了解。
猜你喜欢
1、刚刚晋升为 Apache 顶级项目的 Hudi 如何在数据湖上玩转增量处理
2、Apache Spark 在eBay 的优化
3、Elasticsearch如何做到亿级数据查询毫秒级返回?
4、大数据平台架构设计没思路?来看这篇就知道了!

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】