常用的分布式组件 session共享 分布式ID生成器 分布式锁
分布式问题和解决方案
- 应用多例部署导致的session不一致
- session共享
- Web服务器插件实现session共享
- spring session实现session共享
- 引入spring session依赖
- application.yml配置
- 启用springboot redis http session管理
- 码代码准备一点东西放到session里
- 查看效果
- 程序并发导致的数据不一致
- 分布式锁
- 基于redis的分布式锁组件
- 分库分表引起的数据编号冲突
- 分布式全局唯一ID
- 百度UidGenerator
分布式是把双刃剑,当决定要将项目拆分时,首先要思考项目是不是将大到必须拆分,拆分的可行性和之后的好处,团队的技术储备是不是已经可以顺利过渡,同时控制好粒度并且提前做好服务治理的规划,盲目的服务拆分之后产生的程序迭代、维护成本会大大增加。
对于分布式应用的一些技术细节问题需要提前知晓。
下面是使用的比较顺手的对应分布式场景的组件,在这里分享出来,希望能给你带来一些帮助。
应用多例部署导致的session不一致
一般的话部署项目时候为了避免单点问题我们会将前台项目部署多份,而当我们在多个服务器上部署一个应用的多个实例时,会导致客户端在负载均衡下访问不同的实例的会话不是同一个,这是多实例下的会话不一致问题。
针对这个问题使用比较多的方案是通过一个数据库存储客户端session,因为多个服务器使用的一个session数据库所以就避免了session不一致的问题。
当然,如果你是用的Weblogic的话就不会有这样的问题,Weblogic集群本身内置session集群的方案。
session共享
session共享的理念是将多个实例下的session放到一个地方去管理,这样当客户端用一个在A实例上的SESSIONID去访问B实例的接口时对于服务器来说是同一个会话(SESSION),而不会再去新建一个会话。
Web服务器插件实现session共享
Tomcat8.5下的Session共享
web服务器session管理插件实现session共享
如果你是tomcat下部署的话可以使用tomcat-session-redissession-manager插件,将多个tomcat实例的session存储到同一个redis上面。
netty也有自己的session共享插件,跟tomcat的使用操作差不多,这里就不过多介绍了。
spring session实现session共享
spring session实现session共享
springboot的话jar包部署使用上面tomcat插件的方案就不太好用了,就用spring session就可以很方便的实现session共享,而且不用考虑使用的web服务器类型之间的差异,比如tomcat或者netty使用的是不一样的插件。
引入spring session依赖
spring session 支出的存储介质类型:
jdbc
redis
mongodb
hazelcast
这里我们使用redis做存储给大家做演示
// https://mvnrepository.com/artifact/org.springframework.data/spring-data-redis
compile group: 'org.springframework.data', name: 'spring-data-redis', version: '2.1.2.RELEASE'
// https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis
compile group: 'org.springframework.boot', name: 'spring-boot-starter-data-redis', version: '2.1.2.RELEASE'
// https://mvnrepository.com/artifact/org.springframework.session/spring-session-data-redis
compile group: 'org.springframework.session', name: 'spring-session-data-redis', version: '2.1.2.RELEASE'

application.yml配置
spring:
session:
store-type: redis
redis:
flush-mode: on_save
namespace: spring:session
redis:
host: 119.xxx.xxx.xxx
password: '@@@####'
port: 6379
database: 6
启用springboot redis http session管理
@EnableRedisHttpSession
@SpringBootApplication
public class ComponentApplication {
码代码准备一点东西放到session里
@ResponseBody
@RequestMapping("testss")
public JSONObject tetete(HttpServletRequest request) {
JSONObject result = new JSONObject();
request.getSession().setAttribute("springsessoin","can you watch me ?");
result.put("nowtime", new Date());
return result;
}
查看效果
访问testss
查看redis里的session
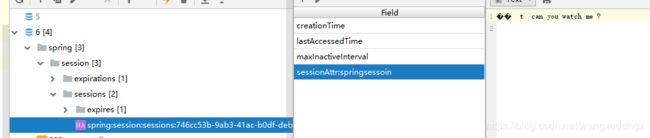
程序并发导致的数据不一致
对于并发所导致的问题是比较典型的,主键冲突,重复数据,死锁以及库存和自动任务并发执行等等问题。
当我们是一个单机应用的使用我们可以使用java中的锁来解决并发问题,但是java中的各种实现锁的机制是无法跨进程使用的,跨进程的并发也是我们做分布式应用时比较早会碰到的问题。
分布式锁
对于分布式的并发,业内也有针对性的解决方案:分布式锁。
现在用的最广泛的三种实现分布式锁的方法是:
数据库锁
redis锁
zookeeper实现分布式锁
基于redis的分布式锁组件
spring-boot-klock-starter
基于redis的分布式锁spring-boot starter组件,使得项目拥有分布式锁能力变得异常简单,支持spring boot,和spirng mvc等spring相关项目
spring-boot-klock-starter项目仓库
分库分表引起的数据编号冲突
当我们需要在整个系统中使用一个唯一ID的时候;比如数据多到需要分库分表,为了避免ID冲突,我们可选的方案可能是,数据库自增ID,UUID,专门使用一个表来做自增的编号。这些方案都是只能解决全局唯一ID的部分需求:
全局唯一,递增,占用空间小,效率高。
唯一性:确保生成的ID是全网唯一的。
有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
高可用性:确保任何时候都能正确的生成ID。
带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
- UUID
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。
优点:本地生成,生成简单,性能好,没有高可用风险
缺点:长度过长,存储冗余,且无序不可读,查询效率低
- 数据库自增ID
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。
优点:数据库生成的ID绝对有序,高可用实现方式简单
缺点:需要独立部署数据库实例,成本高,有性能瓶颈
- 批量生成ID
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。
优点:避免了每次生成ID都要访问数据库并带来压力,提高性能
缺点:属于本地生成策略,存在单点故障,服务重启造成ID不连续
- Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
分布式全局唯一ID
百度UidGenerator
UidGenerator 由百度开发,是Java实现的, 基于 Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于 docker等虚拟化环境下实例自动重启、漂移等场景。
UidGenerator暂时没有稳定可靠的maven或者gradle依赖
The unique id has 64bits (long),
- ±-----±---------------------±---------------±----------+
- | sign | delta seconds | worker node id | sequence |
- ±-----±---------------------±---------------±----------+
- 1bit 28bits 22bits 13bits
UidGenerator给大家提供了两个id生成器类
DefaultUidGenerator:如果你的项目JDK版本低于1.8那你只能用这个类(效率已经很高了)
CacheUidGenerator:比默认的id生成器速度更快
UidGenerator项目仓库