《深入理解计算机系统》之浅析程序性能优化
此文已由作者余笑天授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
本文主要是基于我之前学习《深入理解计算机系统》(以下简称CSAPP)这本书第五章优化程序性能内容的回顾以及总结。主要内容并没有从大而全的方面去阐述如何优化程序,而是从一些细节着手来看待优化代码质量这个大问题。由于我之前接触C/C++程序较多,因此示例代码都是用C++编写,但是我认为无论是什么语言,一些基本的优化原则是相通的。
1.程序优化原则
在CSAPP作者看来性能好的程序要有以下几种特点:
(1)合适的数据结构和算法,都说程序=算法+数据结构,因此这两方面的优化是程序优化的基石。
(2)尽量的写出编译器可以有效优化的代码,现代编译器都会对源代码进行优化,以提高程序的性能。比如Linux下的GCC编译器就能控制优化的等级,优化等级高,对应的程序性能好。如果你的程序编译器并不能确定是否能进行安全优化,那么对于一些的成熟的编译器而言,它并不会采用一些激进的优化方式,这部分内容在优化安全性会有具体介绍。
(3)对于处理运算量特别大的计算,可以将一个任务拆分为多个任务。甚至可以考虑到在多核和对处理器上进行并行计算,这部分内容在CSAPP中的12章会有详细叙述。
(4)在实现和维护代码的简单性和运行速度之间做出权衡,比如调用系统的排序算法可以满足日常大部分的排序需求,但是进行特殊的优化可能要针对排序的数据进行分析然后对应修改排序算法,这个过程耗费的时间和最后的优化结果以及优化后可能带来的可读性、模块性的降低需要作出权衡。
1.1优化的安全性
对于C/C++程序,大多数的编译器会指定优化级别,以GCC为例子:gcc -o指令就可以设置优化级别:
-o0:关闭所有优化
-o1:最基本的优化级别,编译器试图以较少的时间生成更快以及体积更小的代码。
-o2:推荐的优化级别,o1的进阶。
-o3:较危险的优化等级,这个等级会延长编译时间,编译后会产生更大的二进制文件,会带来一些无法预知的问题。
-os:优化代码体积,通常适用于磁盘空间紧张或者CPU缓存较小的机器。
所谓优化的安全性,我们不妨看以下一个栗子:

可以看出看上去以上两个函数实现的功能是一致的,都是将yp所指向的int值的两倍加到xp所指向的值。但是f2的性能要比f1更好一些,因为f2有3次引用,f1有6次引用(2次读xp,2次读yp,2次写xp)。我们期望编译器会帮我们进行以上优化,但是成熟的编译器不会这么做的,这是因为该程序存在内存别名使用(memory aliasing)的问题。就是说xp,yp可能指向同一位置:


可以看出当出现以上情况时,两个函数的行为并不一致,这类程序的编写就成为了编译器优化它的阻碍因素,对应到优化原则的第二条。
其次函数调用同样会阻碍编译器的优化,编译器是不会对函数内容作出假设,因此针对函数调用,编译器一般不会贸然进行优化,同样可以举出一个栗子:
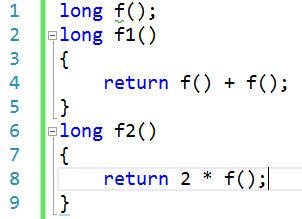
可以看出f1调用了f()两次,而f2()只调用了一次,函数的调用涉及到栈帧的操作这需要消耗一些系统资源,因此按理来说f2()的性能优于f1(),但是编译器针对这种情况同样不会进行优化,考虑到以下代码:


同样可以看出在这种情况下,两个函数行为同样会不一致。
2消除低效的循环
我们编写了一个循环累加的程序来测试在不同循环下,程序性能的开销,首先定义了这样一个数据结构:
typedef struct { long int len;
data_t *data;
}vec_rec, *vec_ptr;
vec_rec表示为data_t的数组,data_t表示为自定义的数据类型,len为该数组的长度。
原书中针对date_t进行了两种定义分别是:整数以及浮点数,并对各自的类型进行加法和乘法的操作,分别统计各自的性能情况,于此同时还定义了性能衡量标准CPE即每元素时钟周期,举个栗子:计算一个数组中所有元素之和,分别统计数组元素个数不同的情况下该程序所用的时钟周期,然后得出每加入一个元素平均多耗费的时钟周期,这个值就是CPE。下面是该书的作者统计的CPE值,这部分由于本人并没有做实验,因此只贴出作者的结果以供参考:

可以看出目前的CPU对于浮点操作的优化使其性能接近甚至略好于对整数的操作,同时对于程序至少进行o1级别的优化同样是有必要的。
下面贴出具体的循环调用代码:
#include"stdlib.h"#include"time.h"#include#ifndef _CLOCK_T_DEFINED
#define _CLOCK_T_DEFINED
#endif
typedef long clock_t;
using namespace std;
typedef int data_t;
typedef struct
{ long int len;
data_t *data;
}vec_rec, *vec_ptr;vec_ptr new_vec(long len){
vec_ptr res = (vec_ptr)malloc(sizeof(vec_rec));
data_t *data = NULL; if (!res) return NULL;
res->len = len; if (len > 0)
{
data = (data_t *)calloc(len, sizeof(data_t)); if (!data)
{
free((void*)res); return NULL;
}
}
res->data = data; return res;
}long vec_length(vec_ptr v){ return v->len;
}int get_vec_element(vec_ptr v,long index, data_t *dest){ if (index < 0 || index >= v->len) return 0;
*dest = v->data[index]; return 1;
}void combine1(vec_ptr v, data_t *dest) { long i;
*dest = 0; for (i = 0; i < vec_length(v); ++i)
{
data_t val;
get_vec_element(v, i, &val);
*dest = *dest + val;
}
}
该程序分别依次取数组元素的值然后加到dest所指的位置中去,这是一般的循环累加的写法,可以看到每次迭代求值都会对测试条件进行求值操作,另一方面针对这种情况,数组的长度并不会随着循环而更改,因此我们定义了combine2如下:
void combine2(vec_ptr v, data_t *dest){ long i; long len = vec_length(v);
*dest = 0; for (i = 0; i < len; ++i)
{
data_t val;
get_vec_element(v, i, &val);
*dest = *dest + val;
}
}
为了对比性能,我做了以下实验:
int main()
{
vec_ptr vec = new_vec(100000000); int* tmp = new int[100000000];
vec->data = (int *)tmp; int res = 0;
clock_t start, finish; double totaltime;
start = clock();
combine1(vec, &res);
finish = clock();
totaltime = (double)(finish - start) / CLOCKS_PER_SEC; cout << "\n此程序的运行时间为" << totaltime << "秒!" << endl;
start = clock();
combine2(vec, &res);
finish = clock();
totaltime = (double)(finish - start) / CLOCKS_PER_SEC; cout << "\n此程序的运行时间为" << totaltime << "秒!" << endl;
system("pause");
}
得到如下结果:

3减少过程调用
一个函数的调用基本过程大致如下:
1、调用者函数把被调函数所需要的参数按照与被调函数的形参顺序相反的顺序压入栈中
2、调用者函数使用call指令调用被调函数,并把call指令的下一条指令的地址当成返回地址压入栈中
3、在被调函数中,被调函数会先保存调用者函数的栈底地址(push ebp),然后再保存调用者函数的栈顶地址
4、在被调函数中,从ebp的位置处开始存放被调函数中的局部变量和临时变量,并且这些变量的地址按照定义时的顺序依次减小
可以看出在函数调用过程中,需要做一些压栈出栈操作,同时需要一些寄存器帮助保存和恢复环境,这些都将带来系统开销。因此减少一些函数调用将会提高程序性能。以上面的程序为例,可以看到combine函数在循环中调用了get_vec_element操作,这部分操作可以移到循环内部而不必调用函数,具体做法如下:
增加get_vec_start函数获取数组起始位置:
data_t *get_vec_start(vec_ptr v)
{ return v->data;
}
修改combine函数:
void combine3(vec_ptr v, data_t *dest){ long i; long len = vec_length(v);
data_t *data = get_vec_start(v);
*dest = 0; for (i = 0; i < len; ++i)
{
*dest = *dest + data[i];
}
}
修改后的程序性能对比如下:

4消除不必要的引用
combine3将计算后的值累加在dest指针后,一下贴出段代码的汇编结果:

从这段代码可以看出dest指针放在寄存器rax中,每次迭代,data指针加1。每次迭代后。累积的数值从内存中读出再写入到内存中,这样频繁的读写内存将会影响程序的性能。
这类频繁的内存读写是可以避免的,可以引入一个临时变量存储*dest的值,循环中只取变量的值,直至循环结束将结果写到dest指针所指的位置中。代码如下:
void combine4(vec_ptr v, data_t *dest){ long i; long len = vec_length(v);
data_t *data = get_vec_start(v); long acc = 0; //*dest = 0;
for (i = 0; i < len; ++i)
{
acc = acc + data[i];
}
*dest = acc;
}
这段代码的汇编结果如下:
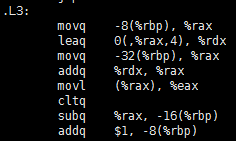
可以看出该部分汇编代码用rax保存累计值没有涉及到取内存的操作,因此在循环中的内存操作变成只有取data数组这一次。
以下贴出结果对比:

可以看出combine4在之前的基础上性能又稍有提高。
5循环展开
循环展开是一种程序变换,通过增加每次循环的计算量,减少循环次数从而改进程序性能。循环展开对程序性能的影响有两点,其一是它减少了循环中的辅助计算量例如循环索引和条件分支(该书5.7节详细介绍了条件分支对性能的影响)。第二它减少了关键路径的操作数量。下面给出循环展开的一个版本:
void combine5(vec_ptr v, data_t *dest){ long i=0; long len = vec_length(v); long limit = len - 1;
data_t *data = get_vec_start(v);
data_t acc = 0; for (int i = 0; i < limit; i += 3)
{
acc = (acc + data[i]) + data[i + 1];
} if (i < len)
{
acc = acc + data[i];
}
*dest = acc;
}
下面是循环展开后的程序性能:
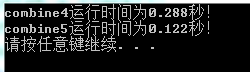
该版本的循环展开将原有的循环次数减少了一半,延续这个思想,可将循环按任意因子k展开,下面是作者将改程序循环展开后多次后性能表现情况:
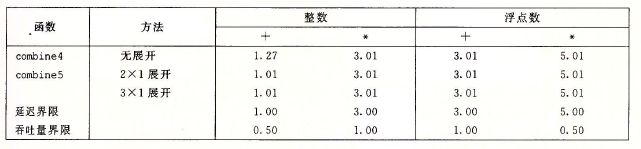
可以看出对于该优化不会超过延迟界限值,查看循环展开操作的汇编代码:

可以看到该操作会导致两条vmulsd操作,一条将data[i]加到acc上,第二条将data[i+1]加到acc上。每条vmulsd被翻译成两个操作:一个操作是从内存中加载一个数组元素,另一个是把这个值乘以已有的累计值。可以看到,循环的每次执行中,对寄存器%xmm0读和写两次。从中可以看到,迭代的次数减半了,但是每次迭代中还是有两个顺序的乘法操作。这个关键路径是循环没有展开代码的性能制约因素。具体汇编代码过程图示如下:

至此,完成了该程序的初步优化,关于循环展开部分,该书第五章后半段有进阶的内容,有兴趣的同学可以一起学习交流。
免费体验云安全(易盾)内容安全、验证码等服务
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 微服务化之无状态化与容器化
【推荐】 聊聊空状态设计