mapreduce 完整流程解析
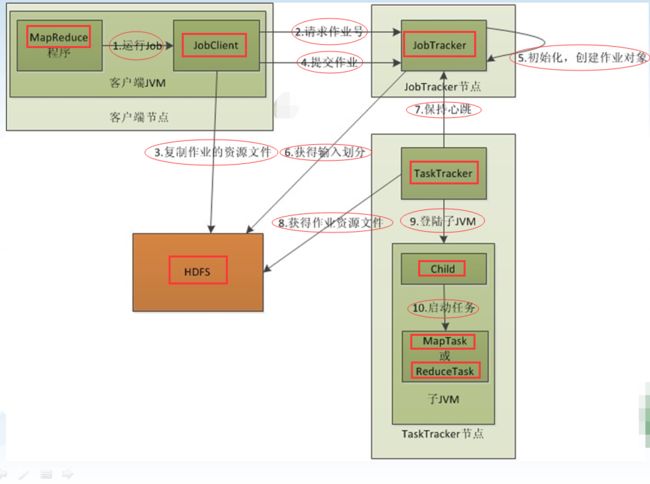
1. 在客户端启动一个 job;
hadoop jar share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar -files tmp/example1/mapper.py,tmp/example1/reducer.py -mapper 'python mapper.py' -reducer 'python reducer.py' -input /usr/mr/example1/input/* -output /usr/mr/example1/output10
2. 该 job 向 jobtrack 申请一个 job id;
3. 将运作该 job 所需的资源上传至 hdfs,包括:jar 文件、配置文件、客户端计算所得的计算划分信息;
jobtrack 为这些文件创建一个 文件夹,名字为 job id;
jar 文件默认为 10 个副本; 【由 mapred.submit.replication 属性控制】
输入划分信息 告诉 jobtrack 应该为这个 job 启动 多少个 map 任务;
4. jobtrack 收到 job 后,将其放入一个 消息队列;
5. 该 job 被 get 时,jobtrack 根据 输入划分信息 为其创建对应个 map 任务,并将 map 任务 分发给 tasktrack;
// 注意,在分发 map 任务时,需要把 map 任务 发送到 存有对应数据 block 的 tasktrack;
// 同时发送过去的还有 jar 包等文件;
// 这在 mr 中叫 运算移动,数据不移动;
6. tasktrack 定时向 jobtrack 发送心跳,证明自己还活着,并且告诉 jobtrack map进度 等多个信息;
7. jobtrack 收到 job 的 最后一个任务完成 信息时,将该作业标记为 完成,并给用户发送信息
map 流程解析
map 中有几个主要概念:
分区:partition,根据 key 进行分区,一般是 hash 方法
排序:sort,对 key 进行排序,排序在 hadoop 中起到核心作用
溢写:spill,把数据从内存写入磁盘
流程图-单个 map 任务
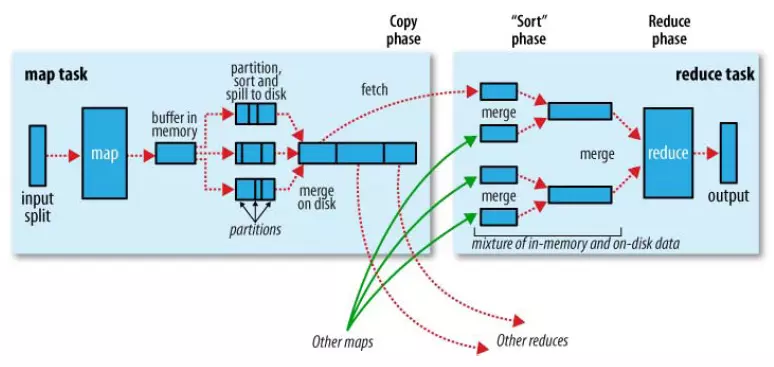
本次描述以 wordcount 为例进行阐述
1. input split 输入切片,其实就是一个 block,我们可以理解为一个 文件;
一个 split 对应一个 map;
默认情况下,一个 block 大小 为 64M,当然可以自定义;
aaa
bbb
aaa
aaa
ccc
aaa
ccc
2. map 的输出 存放在 缓存 中, 【缓冲区 默认 大小为 100M,由 io.sort.mb 属性控制】
当缓存快要溢出时, 【默认为 缓冲区 的 80%,由 io.sort.spill.percent 属性控制】
在本地创建一个临时文件,将 缓冲区的数据 写入 文件;
map 就是 逐个处理,比如 work 为 key,value 为 1,直接扔到 标准输出;
3. 在 完成 spill 之前,需要 partition 和 sort,这是 核心,为什么呢,看下图

如果 设置了 Combiner,会将 sort 的结果 combiner 后再 spill 到磁盘,以节省磁盘空间;
分区的数目 等于 reducer 任务的个数;
4. 如果 block 很大,需要 溢写 多个 文件,就行 上图中第四列所示;
5. map 完毕 有多个 溢写文件时,需要将这些 文件 根据 key 进行合并为一个带分区的文件;
合并的过程 也有 sort 和 combiner 操作;
为了减少 网络传输,这里还可以将 合并后的文件 压缩; 【只要将 mapred.compress.map.out 设置为true就可以】
6. 将分区中的数据 拷贝到 对应的 renducer 任务;
reducer 流程解析
这里放一张 中文图,其实和上图一样
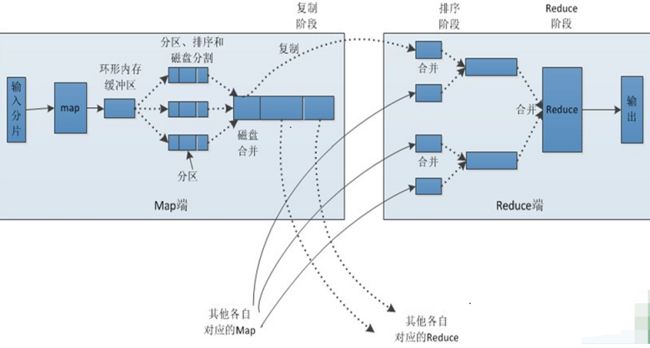
1. 将 多个 map 传过来的数据 进行 sort ,然后 合并;
2. reducer 处理;
3. 将结果输出到 hdfs;
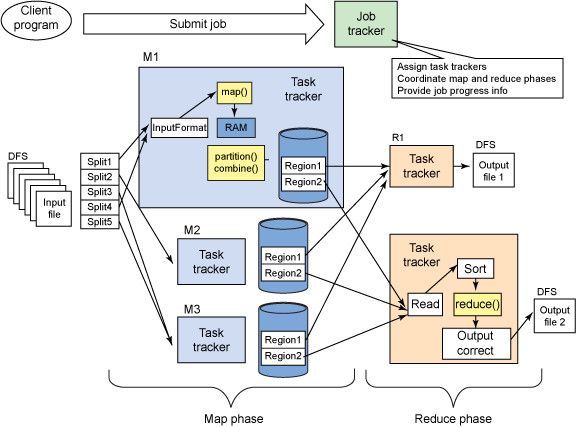
最后再来几张图,再看已是一目了然

参考资料:
https://www.cnblogs.com/laowangc/p/8961946.html#top
https://www.jianshu.com/p/461f86936972
https://www.cnblogs.com/52mm/p/p15.html