伏羲—阿里云分布式调度系统
今天,大数据已经从概念发展到在很多行业落地生根。广泛用在电商、金融、企业等行业,帮助行业分析数据、挖掘数据的价值。即使在传统的医疗、安全、交通等领域也越来越多的应用大数据的技术。数据、价值二者之间的联系是计算,计算是大数据中最核心的部分。大数据计算就是将原来一台台的服务器通过网络连接起来成为一个整体,对外提供体验一致的计算功能,即分布式计算。
点击查看回顾视频
伏羲系统架构
分布式调度系统需要解决两个问题:
任务调度:如何将海量数据分片,并在几千上万台机器上并行处理,最终汇聚成用户需要的结果?当并行任务中个别失败了如何处理?不同任务之间的数据如何传递?
资源调度:分布式计算天生就是面向多用户、多任务的,如何让多个用户能够共享集群资源?如何在多个任务之间调配资源以使得每个任务公平的得到资源?
业界几种调度系统的比较
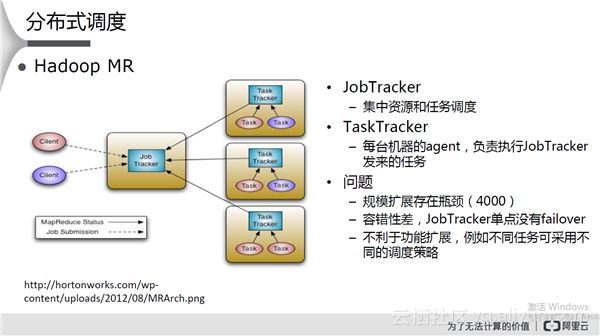
Hadoop MR
由一个JobTracker和若干个TaskTracker组成,client可以提交多个任务执行。其特点和存在问题如下图所示:
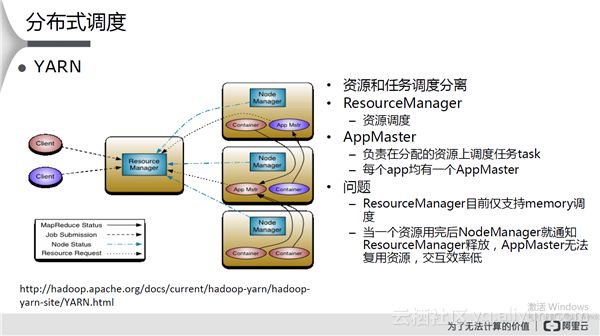
YARN
其特点和存在问题如下图所示:
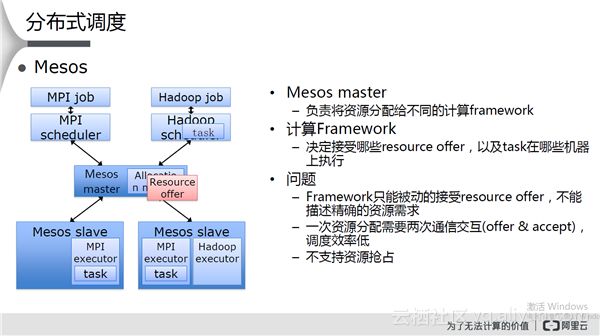
Mesos
该系统与YARN类似,其特点和存在问题如下图所示:
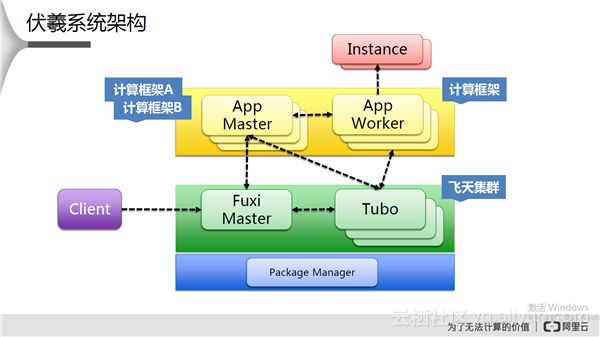
伏羲系统架构
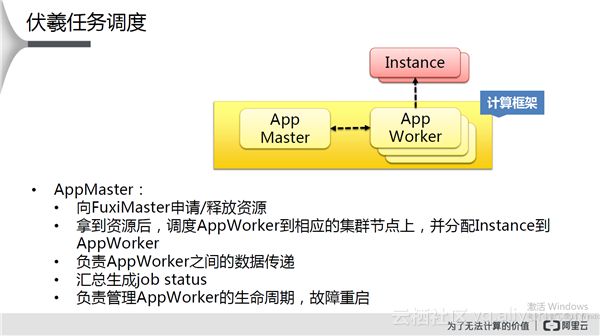
当飞天集群部署完毕后,主控为Fuxi Master,Package Manager为代码包。Fuxi Master和Tubo之间彼此有心跳通信,当用户通过Fuxi Master向系统提交任务时,Fuxi Master会通过调度选择一台Tubo启动App Master。App Master启动后会联系Fuxi Master将其需求发送给Fuxi Master触发调度,Fuxi Master经过资源调度并将结果返回给App Master,App Master与先相关资源上的Tubo联系,启动App Worker。App Worker也会上报到App Master准备开始执行任务。App Master将分片后的任务发送给App Worker开始执行,每个分片称为Instance。App Master和App Worker一起称之为计算框架。伏羲系统是多任务系统,可以同时运行多个计算框架。
伏羲架构也是资源调度和任务调度分离,两层架构。其优势在于:
规模:易于横向扩展,资源管理和调度模块仅负责资源的整体分配,不负责具体任务调度,可以轻松扩展集群节点规模;
容错:某个任务运行失败不会影响其他任务的执行;同时资源调度失败也不影响任务调度;
扩展性:不同的任务可以采用不同的参数配置和调度策略,支持资源抢占;
效率:计算framework决定资源的生命周期,可以复用资源,提高资源交互效率。
App Master和App Worker解决了任务调度,Fuxi Master和Tubo解决了资源调度。总体来说,伏羲架构:两层架构设计,分解问题;FuxiMaster扩展性强;支持多种计算框架,包括离线批处理、在线服务、实时计算、Streaming;容错性好,任意角色的故障不影响任务执行,支持多角色failover。
任务调度
海量数据如何并行处理?PC时代的多线程、多进程解决不了问题的时候,MapReduce通过化整为零、数据切片、分解、聚合解决了上述问题。传统的MapReduce模型是Map任务紧接着Reduce任务,模式相对固定。但是实际过程中问题的处理涉及多个步骤,难以用一个MapReduce模型描述。伏羲将MapReduce扩展到更广阔的DAG有向无环图。伏羲任务调度过程如下图所示:
App Master 的主要任务如上图所示。App Worker的任务是:接收App Master发来的Instance,并执行用户计算逻辑;向App Master报告执行进度等运行状态;读取输入数据、将计算结果写到输出文件。
数据Locality
App Worker处理数据时,尽量从本地磁盘读取,输出也尽量写本地磁盘,避免远程读写。这样就对调度的要求,尽量让Instance(数据分片)数据最多的节点上的App Worker来处理该Instance。
数据Shuffle
Map和Reduce之间数据的传递取决于实际问题的逻辑,可能存在3种形式(1:1,1:N,M:N)。伏羲将数据shuffle过程封装成streamline lib,用户不用关心shuffle细节。
Instance PVC重试
在任务运行期间,App Master会监控Instance的运行进度,如果失败,会将Instance调度分配到其他App Worker上重新运行。造成Instance进程失败的原因有:进程重启、机器故障等。重跑是最直接最常见的容错方式,但是还存在数据读取失败,比如磁盘故障、文件丢失,伏羲采用PVC(pipe version controle)进行重试。
Backup instance
App Master还会监控Instance的运行速度,如果运行慢,容易造成长尾,App Master会在另外的App Worker上同时运行该Instance,取最先结束的那一份。判断依据是:运行时间超过其他Instance的平均运行时间;数据处理速度低于其他Instance平均值;已完成的Instance比例。
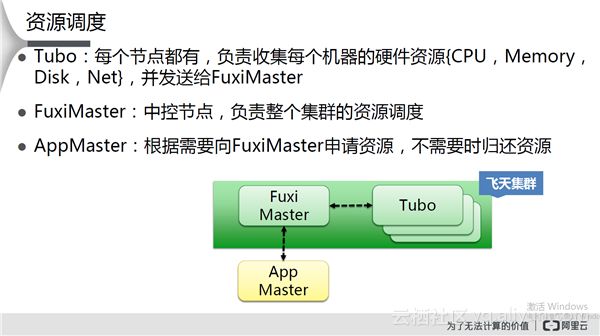
资源调度
资源调度解决的问题是如何将集群的CPU、Memory资源在多个任务之间调度?目标是:集群资源利用率最大化;每个任务的资源等待时间最小化;能分组控制资源配额;能支持临时紧急任务。其操作是当有空闲资源时,从等待队列中选取一个任务进行调度。
伏羲的资源调度方法如下图所示:
优先级和抢占策略
每个job在提交时会带一个priority值,一个整数值,越小优先级越高(可以理解为排队在前面)。相同优先级按提交时间,先提交的优先级高。FuxiMaster在调度时,资源优先分配给高优先级的job,剩余的资源继续分配给次高优先级job。如果临时有高优先级的紧急任务加入,FuxiMaster会从当前正在运行的任务中,从最低优先级任务开始强制收回资源,以分配给紧急任务,此过程称为“抢占”。抢占递归进行,直到被抢任务优先级不高于紧急任务(换句话,不能抢比自己优先级高的任务)。
公平调度策略
当有资源时,Fuxi Master依次轮询的将部分资源分配给各个job,并按优先级分组,同一优先级组内平均分配,有剩余资源再去下一优先级组分配。
配额策略
多个任务组成一个group,通常按不同业务区分。集群管理员设定每个group资源上限,称为Quota。每个group的job所分配的资源总和不会超过该group的Quota。某个group没用完的Quota可以共享给其他group(按Quota比例)。
容错机制
在分布式集群中,故障是常态,所以分布式调度中需要容错机制。好的容错机制要求:正在运行的任务不受影响,对用户透明,自动故障恢复,高可用。
任务调度failover
App Master进程重启后如何进行恢复?App Master具有Snapshot机制,将Instance的运行进度保存下来,当App Master重启后加载snapshot后继续运行instance。App Master进程failover,当App Master重启后,从App Worker汇报的状态中重建出之前的调度结果,继续运行Instance。
资源调度failover
Fuxi Master进程重启后恢复状态需要两种信息来源:Hard State,包括application的配置信息,来自snapshot;Soft State,来自各个Tubo和App Master的新消息中恢复,包括机器列表、每个App Master的资源请求、资源调度结果等。

上图是Fuxi Master重启恢复的示意图。Fuxi Master重启后会通知Tubo,上报在该Tubo上分配的情况。
规模挑战
分布式系统设计主要目标之一就是横向扩展,也叫水平扩展。
多线程异步

以通信模块为例,使用线程池高效处理海量的通信消息,不同的节点之间互不阻塞,独立”泳道”解决队头阻塞(HoL)问题。比如,App Master除了与Fuxi Master有通信外,还与大量Tubo有通信,通常采用线程池处理进来的RPC消息。但是,如果App Master将Fuxi Master与Tubo的消息混在一个队列中,那么Fuxi Master的消息会被大量的Tubo消息阻塞。实际上,Fuxi Master的消息更为重要些。因此,好的做法事为Fuxi Master准备一个单独的队列防止阻塞。
增量资源调度
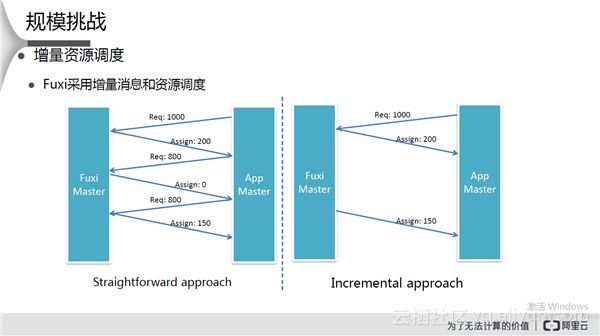
Fuxi采用增量消息和资源调度。比如通常的做法,App Master申请1000个单位,Fuxi Master只有200个空闲资源,App Master接着申请剩余的800,此时Fuxi Master没有空闲资源。然后接着申请,这种协议消息比较繁琐,App Master需要多次申请才能拿到需要的资源。而在伏羲里,App Master只申请一次,Fuxi Master一旦有资源就分配给App Master,效率比较高。
安全与性能隔离
伏羲系统中定义了可信区域边界,并且提供了全链路的访问控制,比如:Client端不可信区域访问伏羲系统,伏羲系统内部RPC通信,系统访问外部存储等资源。伏羲安全访问验证精细到每个RPC,在Tubo上运行代码时,伏羲提供进程级别沙箱(Sandbox)隔离。系统设计时要求节点上多个进程间性能隔离,不能互相干扰。