卷积神经网络中Attention注意力机制(CBAM)
论文:cbam
CBAM: Convolutional Block Attention Module
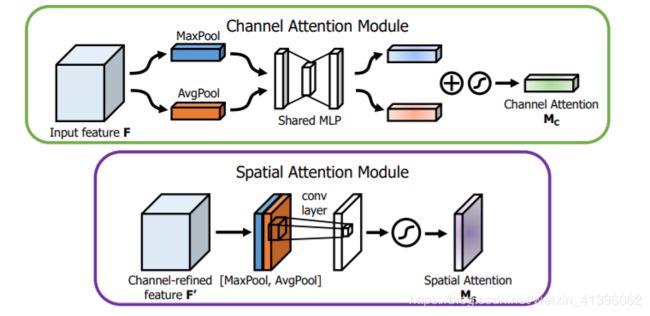
attention机制,简单说就是从特征中学习或者提取出权重分布,再拿这个权重分布施加在原来的特征之上,改变原有特征的分布,增强有效特征抑制无效的特征或者是噪音
attention可以作用在原图上,也可以作用在特征图上
可以在空间尺度上也可以在channel尺度上加权
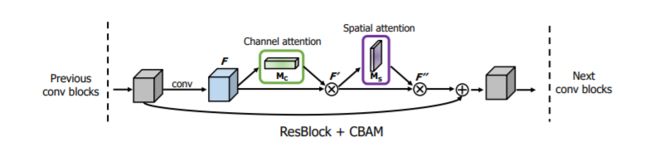
论文中将空间尺度和channe尺度的attention融合成一个模块,叫做cbam
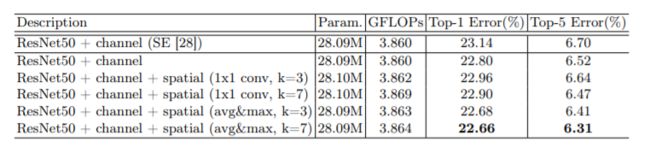
k为spatial attention时融合avg pool和max pool的信息时采用的卷积核大小
k=7有最好的效果
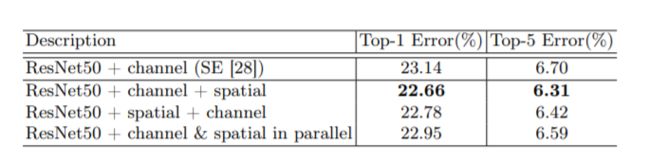
这一部分实验表明先进性channel attention再进行spatial attention效果更好
自己实际实验时发现,加入cbam模块后变慢了不少
而且在浅层网络中加入cbam和使用se基本没有区别
'''
channel attention + spatial attention
'''
# -*- coding: UTF-8 -*-
#!/usr/bin/python
from __future__ import absolute_import
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
slim = tf.contrib.slim
def combined_static_and_dynamic_shape(tensor):
"""Returns a list containing static and dynamic values for the dimensions.
Returns a list of static and dynamic values for shape dimensions. This is
useful to preserve static shapes when available in reshape operation.
Args:
tensor: A tensor of any type.
Returns:
A list of size tensor.shape.ndims containing integers or a scalar tensor.
"""
static_tensor_shape = tensor.shape.as_list()
dynamic_tensor_shape = tf.shape(tensor)
combined_shape = []
for index, dim in enumerate(static_tensor_shape):
if dim is not None:
combined_shape.append(dim)
else:
combined_shape.append(dynamic_tensor_shape[index])
return combined_shape
def convolutional_block_attention_module(feature_map, inner_units_ratio=0.5):
"""
CBAM: convolution block attention module, which is described in "CBAM: Convolutional Block Attention Module"
Architecture : "https://arxiv.org/pdf/1807.06521.pdf"
If you want to use this module, just plug this module into your network
:param feature_map : input feature map
:param index : the index of convolution block attention module
:param inner_units_ratio: output units number of fully connected layer: inner_units_ratio*feature_map_channel
:return:feature map with channel and spatial attention
"""
with tf.variable_scope("cbam"):
feature_map_shape = combined_static_and_dynamic_shape(feature_map)
# print('feature_map_shape:',feature_map_shape)
# channel attention
channel_avg_weights = tf.nn.avg_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_max_weights = tf.nn.max_pool(
value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID'
)
channel_avg_reshape = tf.reshape(channel_avg_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_max_reshape = tf.reshape(channel_max_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
# print('channel_max_reshape:',channel_max_reshape.get_shape().as_list())
channel_w_reshape = tf.concat([channel_avg_reshape, channel_max_reshape], axis=1)
# print('channel_w_reshape:',channel_w_reshape.get_shape().as_list())
fc_1 = tf.layers.dense(
inputs=channel_w_reshape,
units=feature_map_shape[3] * inner_units_ratio,
name="fc_1",
activation=tf.nn.relu
)
fc_2 = tf.layers.dense(
inputs=fc_1,
units=feature_map_shape[3],
name="fc_2",
activation=None
)
channel_attention = tf.reduce_sum(fc_2, axis=1, name="channel_attention_sum")
channel_attention = tf.nn.sigmoid(channel_attention, name="channel_attention_sum_sigmoid")
channel_attention = tf.reshape(channel_attention, shape=[feature_map_shape[0], 1, 1, feature_map_shape[3]])
feature_map_with_channel_attention = tf.multiply(feature_map, channel_attention)
# spatial attention
channel_wise_avg_pooling = tf.reduce_mean(feature_map_with_channel_attention, axis=3)
channel_wise_max_pooling = tf.reduce_max(feature_map_with_channel_attention, axis=3)
# print('channel_wise_avg_pooling:',channel_wise_avg_pooling.get_shape().as_list())
channel_wise_avg_pooling = tf.reshape(channel_wise_avg_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_max_pooling = tf.reshape(channel_wise_max_pooling,
shape=[feature_map_shape[0], feature_map_shape[1], feature_map_shape[2],
1])
channel_wise_pooling = tf.concat([channel_wise_avg_pooling, channel_wise_max_pooling], axis=3)
spatial_attention = slim.conv2d(
channel_wise_pooling,
1,
[7, 7],
padding='SAME',
activation_fn=tf.nn.sigmoid,
scope="spatial_attention_conv"
)
feature_map_with_attention = tf.multiply(feature_map_with_channel_attention, spatial_attention)
return feature_map_with_attention
#example
#feature_map = tf.constant(np.random.rand(50,8,8,32), dtype=tf.float16)
#feature_map_with_attention = convolutional_block_attention_module(feature_map, 1)
#
#with tf.Session() as sess:
# init = tf.global_variables_initializer()
# sess.run(init)
# result = sess.run(feature_map_with_attention)
# print(result.shape)
参考文章:https://www.jianshu.com/p/3e33ab049b4e