2018年第九届蓝桥杯省赛试题及详解(Java本科B组)
蓝桥杯历年真题题目及题解目录汇总
- 结果填空 (满分5分)
- 结果填空 (满分7分)
- 结果填空 (满分13分)
- 结果填空 (满分17分)
- 代码填空 (满分9分)
- 程序设计(满分11分)
- 程序设计(满分19分)
- 程序设计(满分21分)
- 程序设计(满分23分)
- 程序设计(满分25分)
1、标题:第几天
2000年的1月1日,是那一年的第1天。
那么,2000年的5月4日,是那一年的第几天?
注意:需要提交的是一个整数,不要填写任何多余内容。
打开电脑日历数:125
2、标题:方格计数
如图p1.png所示,在二维平面上有无数个1x1的小方格。
我们以某个小方格的一个顶点为圆心画一个半径为1000的圆。
你能计算出这个圆里有多少个完整的小方格吗?
注意:需要提交的是一个整数,不要填写任何多余内容。
根据圆的对此性,我们其实只要对1/4的正半轴圆进行暴力枚举每个方格,这里我们可以转换下关注点,用右上角的点代表一个方格,因为它是最远点,距离公式,答案:3137548,做法其实还有很多,不过填空题这样最快最稳
public class _02方格计数1 {
public static void main(String[] args) {
int d=1000,ans=0;
for(int i=1;i<=d;i++)
for(int j=1;j<=d;j++)
if(i*i+j*j<=d*d)
ans++;
System.out.println(ans*4);
}
}
3、标题:复数幂
设i为虚数单位。对于任意正整数n,(2+3i)^n 的实部和虚部都是整数。
求 (2+3i)^123456 等于多少? 即(2+3i)的123456次幂,这个数字很大,要求精确表示。
答案写成 "实部±虚部i" 的形式,实部和虚部都是整数(不能用科学计数法表示),中间任何地方都不加空格,实部为正时前面不加正号。(2+3i)^2 写成: -5+12i,
(2+3i)^5 的写成: 122-597i
注意:需要提交的是一个很庞大的复数,不要填写任何多余内容。
答案太长了贴不了,因为a和b都是负数所以不用加+号,ctrl+A复制到记事本或者输出到文件里
import java.io.File;
import java.io.FileNotFoundException;
import java.io.PrintStream;
import java.math.BigInteger;
public class _03_复数幂 {
public static void main(String[] args) throws FileNotFoundException {
BigInteger c = BigInteger.valueOf(2);
BigInteger d = BigInteger.valueOf(3);
BigInteger a = BigInteger.valueOf(2);
BigInteger b = BigInteger.valueOf(3);
//(a+bi)*(c+di) = (a*c - b*d) + (a*d + b*c)i
for(int i=1;i<123456;i++) {
BigInteger A = a.multiply(c).subtract(b.multiply(d));
BigInteger B = a.multiply(d).add(b.multiply(c));
a=A;//如果不设置临时变量,后面b的值会出错
b=B;
}
PrintStream out = System.out;
PrintStream ps = new PrintStream(new File("ans.txt"));//默认在项目的路径
System.setOut(ps);//输出在ans.txt里
System.out.println(a.toString()+b.toString()+"i");
System.setOut(out);//注释了下面就不会输入到控制台里
System.out.println(a.toString()+b.toString()+"i");
}
}
4、标题:测试次数
x星球的居民脾气不太好,但好在他们生气的时候唯一的异常举动是:摔手机。
各大厂商也就纷纷推出各种耐摔型手机。x星球的质监局规定了手机必须经过耐摔测试,并且评定出一个耐摔指数来,之后才允许上市流通。
x星球有很多高耸入云的高塔,刚好可以用来做耐摔测试。塔的每一层高度都是一样的,与地球上稍有不同的是,他们的第一层不是地面,而是相当于我们的2楼。
如果手机从第7层扔下去没摔坏,但第8层摔坏了,则手机耐摔指数=7。
特别地,如果手机从第1层扔下去就坏了,则耐摔指数=0。
如果到了塔的最高层第n层扔没摔坏,则耐摔指数=n
为了减少测试次数,从每个厂家抽样3部手机参加测试。
某次测试的塔高为1000层,如果我们总是采用最佳策略,在最坏的运气下最多需要测试多少次才能确定手机的耐摔指数呢?
请填写这个最多测试次数。
注意:需要填写的是一个整数,不要填写任何多余内容。
答案:19,leetcode原题887. 鸡蛋掉落
dp,个人熟悉记忆搜索多些,贴个记忆搜索代码,复杂度都差不多,况且还是填空
public class _04_测试次数 {
public static void main(String[] args) {
for(int i=0;i<10;i++)
for(int j=0;j<10000;j++)
memo[i][j] = 99999999;//找最小,初始化INF
System.out.println(f(3,1000));
}
static int[][] memo = new int[10][10005];
static int f(int n,int m) {
if(n==1)
return m;
if(m==1 || m==2)
return 1;
if(memo[n][m]!=99999999)
return memo[n][m];
for(int i=1;i<=m;i++) {
memo[n][m] = Math.min(memo[n][m], 1+Math.max(f(n,m-i),f(n-1,i)));
}
return memo[n][m];
}
}
5、标题:快速排序
以下代码可以从数组a[]中找出第k小的元素。
它使用了类似快速排序中的分治算法,期望时间复杂度是O(N)的。
请仔细阅读分析源码,填写划线部分缺失的内容。
import java.util.Random;
public class Main{
public static int quickSelect(int a[], int l, int r, int k) {
Random rand = new Random();
int p = rand.nextInt(r - l + 1) + l;
int x = a[p];
int tmp = a[p]; a[p] = a[r]; a[r] = tmp;
int i = l, j = r;
while(i < j) {
while(i < j && a[i] < x) i++;
if(i < j) {
a[j] = a[i];
j--;
}
while(i < j && a[j] > x) j--;
if(i < j) {
a[i] = a[j];
i++;
}
}
a[i] = x;
p = i;
if(i - l + 1 == k) return a[i];
if(i - l + 1 < k) return quickSelect( _________________________________ ); //填空
else return quickSelect(a, l, i - 1, k);
}
public static void main(String args[]) {
int [] a = {1, 4, 2, 8, 5, 7};
System.out.println(quickSelect(a, 0, 5, 4));
}
}
注意:只提交划线部分缺少的代码,不要抄写任何已经存在的代码或符号。
答案:quickSelect(a,i+1,r,k-i+l-1),随机快排思想
6、标题:递增三元组
给定三个整数数组
A = [A1, A2, ... AN],
B = [B1, B2, ... BN],
C = [C1, C2, ... CN],
请你统计有多少个三元组(i, j, k) 满足:
1. 1 <= i, j, k <= N
2. Ai < Bj < Ck
【输入格式】
第一行包含一个整数N。
第二行包含N个整数A1, A2, ... AN。
第三行包含N个整数B1, B2, ... BN。
第四行包含N个整数C1, C2, ... CN。
对于30%的数据,1 <= N <= 100
对于60%的数据,1 <= N <= 1000
对于100%的数据,1 <= N <= 100000 0 <= Ai, Bi, Ci <= 100000
【输出格式】
一个整数表示答案
【输入样例】
3
1 1 1
2 2 2
3 3 3
【输出样例】
27
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
不要使用package语句。不要使用jdk1.7及以上版本的特性。
主类的名字必须是:Main,否则按无效代码处理。
10W的数据规模,3个for的暴力解法O(n^3)肯定超时,不过拿60%已经挺不错了,优化下,最后一层for改为二分,这样的复杂度O(n^2logn)还是太高,可以再优化一次,把A和B,B和C分开统计,现在在B中二分查找比A[i]大的个数,同理在C中二分查找比B[i]大的个数,最后所有的这2个数相乘的累加就是ans,复杂度O(nlogn)
import java.util.Arrays;
import java.util.Scanner;
public class _06递增三元组 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] A = new int[n];
int[] B = new int[n];
int[] C = new int[n];
for(int i=0;iB[j]) r= m-1;
else l = m +1;
}
// System.out.println(i+" "+j+" "+l);
ans+=n-l;
}
// System.out.println();
}
System.out.println(ans);
}
}
O(nlogn)代码,花里胡哨的,想拿满分不容易,别忘了用long,其实这题分值那么小暴力应该能拿80%以上把,数据规模可能是虚的吧,优化浪费的时间有点多
可以测下10W的最坏情况1,2,3有没溢出,提醒粗心的自己org
//第六题:
//
//标题:递增三元组
//给定三个整数数组
//A = [A1, A2, ... AN],
//B = [B1, B2, ... BN],
//C = [C1, C2, ... CN],
//请你统计有多少个三元组(i, j, k) 满足:
//1. 1 <= i, j, k <= N
//2. Ai < Bj < Ck
//
//【输入格式】
//第一行包含一个整数N。
//第二行包含N个整数A1, A2, ... AN。
//第三行包含N个整数B1, B2, ... BN。
//第四行包含N个整数C1, C2, ... CN。
//对于30%的数据,1 <= N <= 100
//对于60%的数据,1 <= N <= 1000
//对于100%的数据,1 <= N <= 100000 0 <= Ai, Bi, Ci <= 100000
//【输出格式】
//一个整数表示答案
//
//
//【输入样例】
//3
//1 1 1
//2 2 2
//3 3 3
//
//【输出样例】
//27
//
//资源约定:
//峰值内存消耗(含虚拟机) < 256M
//CPU消耗 < 1000ms
//请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
import java.util.Arrays;
import java.util.Scanner;
public class _06递增三元组2 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] A = new int[n];
int[] B = new int[n];
int[] C = new int[n];
for(int i=0;ij->k,但其实n-v[i]就可以找到B里面那个刚好比A[i]大的下标
long ans=0;
for(int i=0;iA[i])
r= mid-1;
else
l = mid +1;
}
v[i] = n-l;
// p[i] = l;
}
for(int i=0;iB[i])
r= mid-1;
else
l = mid +1;//11+11+3+1
}
w[i] = n-l;
}
for(int i=0;i
7、标题:螺旋折线
如图p1.pgn所示的螺旋折线经过平面上所有整点恰好一次。
对于整点(X, Y),我们定义它到原点的距离dis(X, Y)是从原点到(X, Y)的螺旋折线段的长度。 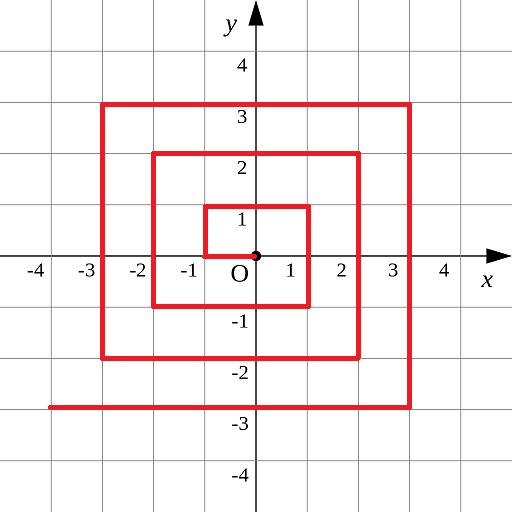
例如dis(0, 1)=3, dis(-2, -1)=9
给出整点坐标(X, Y),你能计算出dis(X, Y)吗?
【输入格式】
X和Y
对于40%的数据,-1000 <= X, Y <= 1000
对于70%的数据,-100000 <= X, Y <= 100000
对于100%的数据, -1000000000 <= X, Y <= 1000000000
【输出格式】
输出dis(X, Y)
【输入样例】
0 1
【输出样例】
3
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
不要使用package语句。不要使用jdk1.7及以上版本的特性。
主类的名字必须是:Main,否则按无效代码处理。
数据规模10^9,应该要推出一条O(1)的数学公式才能AC,对于完全没有头绪的可以模拟螺旋轨迹拿30%也挺不错的
import java.util.Scanner;
public class G {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
long X = in.nextLong();
long Y = in.nextLong();
// 判断所在点所在的正方形
long n = Math.max(Math.abs(X) , Math.abs(Y));
// 1. 之前正方形的长度和
long Sn = 4*(n-1)*n;
// 2. 计算点(-n, -n) 到点(X, Y)的距离, 考虑清楚情况
long sum = 0;
long px = -n, py = -n;
long d1 = X-px, d2 = Y-py;
if (Y > X) {
sum += (d1+d2);
} else {
sum += (8*n-d1-d2);
}
System.out.println(sum + Sn);
}
}
8、标题:日志统计
小明维护着一个程序员论坛。现在他收集了一份"点赞"日志,日志共有N行。其中每一行的格式是:
ts id
表示在ts时刻编号id的帖子收到一个"赞"。
现在小明想统计有哪些帖子曾经是"热帖"。如果一个帖子曾在任意一个长度为D的时间段内收到不少于K个赞,小明就认为这个帖子曾是"热帖"。
具体来说,如果存在某个时刻T满足该帖在[T, T+D)这段时间内(注意是左闭右开区间)收到不少于K个赞,该帖就曾是"热帖"。
给定日志,请你帮助小明统计出所有曾是"热帖"的帖子编号。
【输入格式】
第一行包含三个整数N、D和K。
以下N行每行一条日志,包含两个整数ts和id。
对于50%的数据,1 <= K <= N <= 1000
对于100%的数据,1 <= K <= N <= 100000 0 <= ts <= 100000 0 <= id <= 100000
【输出格式】
按从小到大的顺序输出热帖id。每个id一行。
【输入样例】
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
【输出样例】
1
3
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
不要使用package语句。不要使用jdk1.7及以上版本的特性。
主类的名字必须是:Main,否则按无效代码处理。
双指针+Map+HashSet,模拟点赞过程排重O(n),但排序要O(nlogn),所以总的复杂度为O(nlogn)
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Scanner;
//标题:日志统计
//小明维护着一个程序员论坛。现在他收集了一份"点赞"日志,日志共有N行。其中每一行的格式是:
//ts id
//表示在ts时刻编号id的帖子收到一个"赞"。
//现在小明想统计有哪些帖子曾经是"热帖"。如果一个帖子曾在任意一个长度为D的时间段内收到不少于K个赞,小明就认为这个帖子曾是"热帖"。
//具体来说,如果存在某个时刻T满足该帖在[T, T+D)这段时间内(注意是左闭右开区间)收到不少于K个赞,该帖就曾是"热帖"。
//给定日志,请你帮助小明统计出所有曾是"热帖"的帖子编号。
//
//
//
//【输入格式】
//
//第一行包含三个整数N、D和K。
//以下N行每行一条日志,包含两个整数ts和id。
//
//对于50%的数据,1 <= K <= N <= 1000
//对于100%的数据,1 <= K <= N <= 100000 0 <= ts <= 100000 0 <= id <= 100000
//
//【输出格式】
//按从小到大的顺序输出热帖id。每个id一行。
//
//
//【输入样例】
//
//7 10 2
//0 1
//0 10
//10 10
//10 1
//9 1
//100 3
//100 3
//
//【输出样例】
//1
//3
//资源约定:
//峰值内存消耗(含虚拟机) < 256M
//CPU消耗 < 1000ms
//请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
public class 日志统计 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int d = in.nextInt();
int k = in.nextInt();
ArrayList list = new ArrayList<>();//曾经为热帖
HashSet set = new HashSet<>();//排重
HashMap map = new HashMap<>();//为什么用map,因为其实10W个id并没有全用上
for(int i=0;i=10){
Node v = list.get(i);
map.put(v.id, map.get(v.id)-1);
i++;
min = list.get(i).t;
}
if(map.get(u.id)>=k)
set.add(u.id);
j++;
}
ArrayList ans = new ArrayList<>();
for(int x:set)
ans.add(x);
Collections.sort(ans);
for(int x:ans)
System.out.println(x);
}
static class Node implements Comparable{
int t,id;
public Node(int t,int id) {
this.t= t;
this.id = id;
}
@Override
public int compareTo(Node o) {
return this.t - o.t;
}
}
}
9、标题:全球变暖
你有一张某海域NxN像素的照片,"."表示海洋、"#"表示陆地,如下所示:
.......
.##....
.##....
....##.
..####.
...###.
.......
其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有2座岛屿。
由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
例如上图中的海域未来会变成如下样子:
.......
.......
.......
.......
....#..
.......
.......
请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
【输入格式】
第一行包含一个整数N。 (1 <= N <= 1000)
以下N行N列代表一张海域照片。
照片保证第1行、第1列、第N行、第N列的像素都是海洋。
【输出格式】
一个整数表示答案。
【输入样例】
7
.......
.##....
.##....
....##.
..####.
...###.
.......
【输出样例】
1
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
不要使用package语句。不要使用jdk1.7及以上版本的特性。
主类的名字必须是:Main,否则按无效代码处理。
简单的求联通块题,先预处理,把有连接海洋的小岛用区别于其他字母的东东替换,接着就是dfs+联通块
//第九题
//
//标题:全球变暖
//
//你有一张某海域NxN像素的照片,"."表示海洋、"#"表示陆地,如下所示:
//.......
//.##....
//.##....
//....##.
//..####.
//...###.
//.......
//其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有2座岛屿。
//由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
//例如上图中的海域未来会变成如下样子:
//.......
//.......
//.......
//.......
//....#..
//.......
//.......
//请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
//【输入格式】
//
//第一行包含一个整数N。 (1 <= N <= 1000)
//
//以下N行N列代表一张海域照片。
//
//照片保证第1行、第1列、第N行、第N列的像素都是海洋。
//【输出格式】
//一个整数表示答案。
//【输入样例】
//7
//.......
//.##....
//.##....
//....##.
//..####.
//...###.
//.......
//【输出样例】
//1
//资源约定:
//峰值内存消耗(含虚拟机) < 256M
//CPU消耗 < 1000ms
//请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
import java.util.Scanner;
public class _09全球变暖_ {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
n = in.nextInt();
ch = new char[n][n];
vis = new int[n][n];
for(int i=0;i=0 && x+dx[i]=0 && y+dy[i]=0 && x+dx[i]=0 && y+dy[i]
10、标题:堆的计数
我们知道包含N个元素的堆可以看成是一棵包含N个节点的完全二叉树。
每个节点有一个权值。对于小根堆来说,父节点的权值一定小于其子节点的权值。
假设N个节点的权值分别是1~N,你能求出一共有多少种不同的小根堆吗?
例如对于N=4有如下3种:
1
/ \
2 3
/
4
1
/ \
3 2
/
4
1
/ \
2 4
/
3
由于数量可能超过整型范围,你只需要输出结果除以1000000009的余数。
【输入格式】
一个整数N。
对于40%的数据,1 <= N <= 1000
对于70%的数据,1 <= N <= 10000
对于100%的数据,1 <= N <= 100000
【输出格式】
一个整数表示答案。
【输入样例】
4
【输出样例】
3
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入...” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
不要使用package语句。不要使用jdk1.7及以上版本的特性。
主类的名字必须是:Main,否则按无效代码处理。
这题先来个阶乘逆元求组合数复杂度O(nlogn),不过最快的还是Lucas定理,动态规划复杂度O(n),所以整体复杂度O(nlogn),10W的数据规模可行
阶乘逆元模板
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
n = in.nextInt();
f = new long[n+5];
inv = new long[n+5];
f[0]=1;
for(int i=1;i>=1;
}
return ans;
} AC代码,矩阵幂_快速幂_矩阵乘法_模板
import java.util.Scanner;
public class _10_堆的计数1 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
n = in.nextInt();
f = new long[n+5];
inv = new long[n+5];
s= new int[n+5];
dp = new long[n+5];
f[0]=1;
for(int i=1;i=1;i--) //类似堆的找孩子
s[i] = 1 + (2*i<=n?s[2*i]:0)+(2*i+1<=n?s[2*i+1]:0);//c[i]<=n所以不用取余
for(int i=1;i=1;i--)
if(2*i+1<=n)
dp[i] = dp[2*i]*dp[2*i+1]%mod*C(s[i]-1,s[i*2+1])%mod;//C(s[i]-1,s[i*2+1])和C(s[i]-1,s[i*2])都一样,组合对称
System.out.println(dp[1]);
}
static int n;
static long mod = 1000000009;
static long[] f;
static long[] inv;
static int[] s;//记录该点的孩子节点+自身的总数
static long[] dp;
static long C(int n,int m) {
return f[n]*inv[m]%mod*inv[n-m]%mod;
}
static long mpow(long a,long n) {//快速幂
if(n==0 || a==1)
return 1;
long ans=1;
while(n!=0) {
if(n%2==1)
ans = a*ans%mod;
a=a*a%mod;
n>>=1;
}
return ans;
}
}