数据库设计六大范式
关系数据库中的关系必须满足一定的要求。满足不同程度要求的为不同范式。
normal form 还是normal format?
数据库的设计范式是数据库设计所需要满足的规范。
只有理解数据库的设计范式,才能设计出高效率、优雅的数据库,否则可能会设计出错误的数据库.
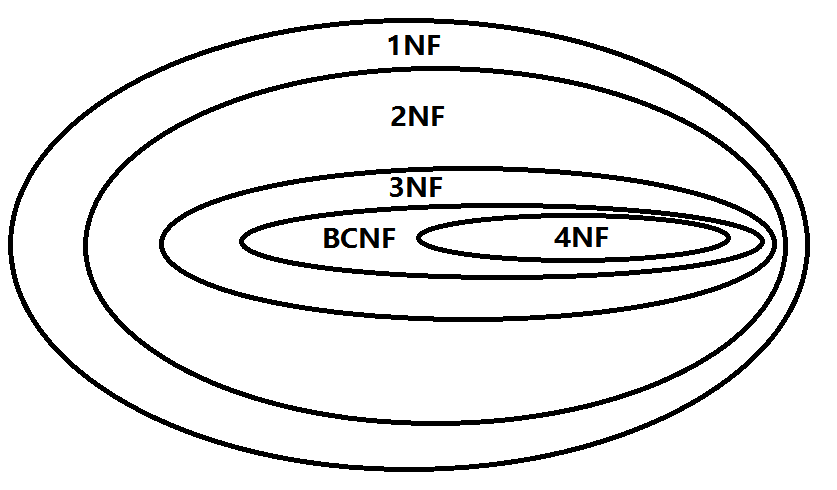
目前,主要有六种范式:第一范式、第二范式、第三范式、BC范式(巴斯-科德范式、修正的第三范式)、第四范式和第五范式(完美范式)。
满足最低要求的叫第一范式,简称1NF。在第一范式基础上进一步满足一些要求的为第二范式,简称2NF。其余依此类推。
范式可以避免数据冗余,减少数据库的空间,减轻维护数据完整性的麻烦,但是操作困难,因为需要联系多个表才能得到所需要数据,而且范式越高性能就会越差。
要权衡是否使用更高范式是比较麻烦的,一般在项目中,用得最多的也就是第三范式,我认为使用到第三范式也就足够了,性能好而且方便管理数据。
首先,明确几个概念:
函数依赖:如果一个表中某一个字段Y的值是由另外一个字段或一组字段X的值来确定的,就称为Y函数依赖于X。
主键:又称主关键字或主码。
候选码:若关系中的某一属性组的值能唯一的标识一个元组,而其任何真子集都不能再标识,则称该属性组为候选码。候选码不唯一,主码是其中一个而已。
主属性:包含在任一候选关键字中的属性称主属性。
第一范式(1NF):--(数据单元不可分、无重复的列)
定义:如果关系模式R的每个关系r的属性都是不可分的数据项,或者说数据库表中的字段都是单一属性的,不可再分,那么就称R是第一范式的模式。
简单的说,每一个属性都是原子项,不可分割。
1NF是关系模式应具备的最起码的条件,如果数据库设计不能满足第一范式,就不称为关系型数据库。关系数据库设计研究的关系规范化是在1NF之上进行的。
例如:
(学生信息表):
| 学生编号 | 姓名 | 性别 | 联系方式 |
| 20080901 | 张三 | 男 | email:[email protected],phone:88886666 |
| 20080902 | 李四 | 女 | email:[email protected],phone:66668888 |
以上的表就不符合,第一范式:联系方式字段可以再分,所以变更为正确的是:
| 学生编号 |
姓名 | 性别 | 电子邮件 | 电话 |
| 20080901 | 张三 | 男 | [email protected] | 88886666 |
| 20080902 | 李四 | 女 | [email protected] | 66668888 |
第二范式(2NF):--(无部分依赖,更结构化、有主键)
定义:如果关系模式R是1NF,且每个非主属性完全函数依赖于候选键,那么就称R是第二范式。
简单的说,第二范式要满足以下的条件:首先要满足第一范式,其次每个非主属性要完全函数依赖与候选键,或者是主键。也就是说,每个非主属性是由整个主键函数决定的,而不能由主键的一部分来决定。
例如:
(学生选课表):
| 学生 |
课程 | 教师 | 教师职称 | 教材 | 教室 | 上课时间 |
| 李四 | Spring | 张老师 | java讲师 | 《Spring深入浅出》 | 301 | 08:00 |
| 张三 | Struts | 杨老师 | java讲师 | 《Struts in Action》 | 302 | 13:30 |
这里通过(学生,课程)可以确定教师、教师职称,教材,教室和上课时间,所以可以把(学生,课程)作为主键。但是,教材并不完全依赖于(学生,课程),只拿出课程就可以确定教材,因为一个课程,一定指定了某个教材。这就叫不完全依赖,或者部分依赖。出现这种情况,就不满足第二范式。
修改后,选课表:
| 学生 |
课程 | 教师 | 教师职称 | 教室 | 上课时间 |
| 李四 | Spring | 张老师 | java讲师 | 301 | 08:00 |
| 张三 | Struts | 杨老师 | java讲师 | 302 | 13:30 |
课程表:
| 课程 |
教材 |
| Spring | 《Spring深入浅出》 |
| Struts | 《Struts in Action》 |
所以,第二范式可以说是消除部分依赖。第二范式可以减少插入异常,删除异常和修改异常。
第三范式(3NF):--(无传递函数依赖、所有表内没有重复字段)
所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系。则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系: 非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况
定义:如果关系模式R是2NF,且关系模式R(U,F)中的所有非主属性对任何候选关键字都不存在传递依赖,则称关系R是属于第三范式。
简单的说,第三范式要满足以下的条件:
首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。(中间人)
注:由于满足了第二范式,表示每个非主属性都函数依赖于主键。如果非主属性之间存在了函数依赖,就会存在传递依赖,这样就不满足第三范式。
上例中修改后的选课表中,一个教师能确定一个教师职称。这样,教师依赖于(学生,课程),而教师职称又依赖于教师,这叫传递依赖。第三范式就是要消除传递依赖。
修改后,选课表:
| 学生 |
课程 | 教师 | 教室 | 上课时间 |
| 李四 | Spring | 张老师 | 301 | 08:00 |
| 张三 | Struts | 杨老师 | 302 | 13:30 |
教师表:
| 教师 |
教师职称 |
| 张老师 | java讲师 |
| 杨老师 | java讲师 |
这样,新教师的职称在没被选课的时候也有地方存了,没人选这个教师的课的时候教师的职称也不至于被删除,修改教师职称时只修改教师表就可以了。
再举个例子:
| OrderID (主键) | OrderDate | CustomerID | CustomerName | CustomerAddr | CustomerCity |
| 01 | 2018-1-12 | 0992 | 张三 | 广东 | 广州天河 |
| 02 | 2017-4-5 | 0993 | 李四 | 福建 | 福州 |
其中OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity
等非主键列都完全依赖于主键(OrderID),所以符合 2NF。
不过问题是CustomerName,CustomerAddr,CustomerCity 直接依赖的是
CustomerID(非主键列)而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。
通过拆分Order为Order(OrderID,OrderDate,CustomerID)和Customer(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到 3NF。
修改后:order表
| OrderID (主键) |
OrderDate | CustomerID |
| 01 | 2018-1-12 | 0992 |
| 02 | 2017-4-5 | 0993 |
Oustomer表
| CustomerID | CustomerName | CustomerAddr | CustomerCity |
| 0992 | 张三 | 广东 | 广州天河 |
| 0993 | 李四 | 福建 | 福州 |
简单的说,
第一范式就是原子性,字段不可再分割;
第二范式就是完全依赖,没有部分依赖;
第三范式就是没有传递依赖。
鲍依斯-科得范式(BCNF):--(修正的第三范式)
定义:在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合BCNF范式。
或者指在第三范式的基础上进一步消除主属性对于码的部分函数依赖和传递依赖。
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 物品数量),且一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 物品数量)
(管理员ID, 存储物品ID) → (仓库ID, 物品数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为物品数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"物品数量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 物品数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异常和更新异常。
第四范式(4NF):--()
定义:设R是一个关系模型,D是R上的多值依赖集合。如果D中存在凡多值依赖X->Y时,X必是R的超键,那么称R是第四范式的模式。
必须先满足第三范式。简单来说就是将表中的多值属性拆分出来,分别建表。
也就是说,当一个表中的非主属性互相独立时(3NF),这些非主属性不应该有多值。若有多值就违反了第四范式。
例如1:
有这样一个用户联系方式表TELEPHONE(CUSTOMERID,PHONE,CELL)。CUSTOMERID为用户ID,PHONE为用户的固定电话,CELL为用户的移动电话。
本来,这是一个非常简单的第3范式表。主键为CUSTOMERID,不存在传递依赖。但在某些情况下,这样的表还是不合理的。比如说,用户有两个固定电话,两个移动电话。这时,表的具体表示如下:
| CUSTOMERID |
PHONE |
CELL |
| 1000 |
8828-1234 |
149088888888 |
| 1000 |
8838-1234 |
149099999999 |
由于PHONE和CELL是互相独立的,而有些用户又有两个和多个值。这时此表就违反第四范式。
在这种情况下,此表的设计就会带来很多维护上的麻烦。例如,如果用户放弃第一行的固定电话和第二行的移动电话,那么这两行会合并吗?等等
解决问题的方法为,设计一个新表NEW_PHONE(CUSTOMERID,NUMBER,TYPE).这样就可以对每个用户处理不同类型的多个电话号码,而不会违反第四范式。
显然,第四范式的应用范围比较小,因为只有在某些特殊情况下,要考虑将表规范到第四范式。所以在实际应用中,一般不要求表满足第四范式。
比如在用户表中有一个非主键字段“电话号码”,某一行实例的“电话号码”内容可能是手机号码,可能是座机号码,也可能是多个内容的直接组合(如“电影”属性中填“动作,喜剧,科幻”), 这就是多值属性。
例如2:
用户表包含一个多值字段“爱好”,某个实例内容可能为:
用户id 姓名 爱好
1 John 足球、游泳、植物大战僵尸
这种情况可以再单独拆出一个爱好表,如下:
字段: 用户id 爱好
实例: 1 足球
实例: 1 游泳
实例: 1 植物大战僵尸
实例: 2 乒乓球
实例: 3 野外求生
第五范式(5NF):--()
是最终范式。消除了4NF中的连接依赖。
定义:
第五范式有以下要求:
(1)必须满足第四范式
(2)表必须可以分解为较小的表,除非那些表在逻辑上拥有与原始表相同的主键。
第五范式是在第四范式的基础上做的进一步规范化。第四范式处理的是相互独立的多值情况,而第五范式则处理相互依赖的多值情况。
例如:
有一个销售信息表SALES(SALEPERSON,VENDOR,PRODUCT)。
SALEPERSON代表销售人员,VENDOR代表供和商,PRODUCT则代表产品。
在某些情况下,这个表中会产生一些冗余。
可以将表分解为
PERSON_VENDOR表(SALEPERSON,VENDOR);
PERSON_PRODUCT表(SALEPERSON,PRODUCT);
VENDOR_PRODICT表(VENDOR,PRODUCT)
结论:
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。
这并意味着不符合范式要求的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
在我们设计数据库的时候,一定要时刻考虑范式的要求。
本文原地址并参考:https://zyl.me/m/2073