H.266/VVC技术学习53:Affine相关
文章目录
- 1 简介
- 1.1 计算方法
- 1.2 子块大小
- 2 Affine merge
- 2.1 继承Affine merge候选
- 2.2 构造Affine merge候选
- 2.3 零MV候选
- 3 Affine AMVP
- 3.1 继承Affine AMVP候选
- 3.2 构造Affine AMVP候选
- 3.3 相邻块的MV候选
- 3.4 零MV候选
- 4 Affine运动信息存储
- 5 PROF
- 5.1 步骤
- 5.2 限制
- 5.3 快速算法
1 简介
Affine表示仿射(Affine motion compensated prediction)。
在HEVC中,仅将平移运动模型应用于运动补偿预测(MCP)。但是在现实世界中,有多种运动,例如放大/缩小,旋转,透视运动和其他不规则运动。
在VVC中,为应对上述运动,应用了基于块的仿射变换运动补偿预测。
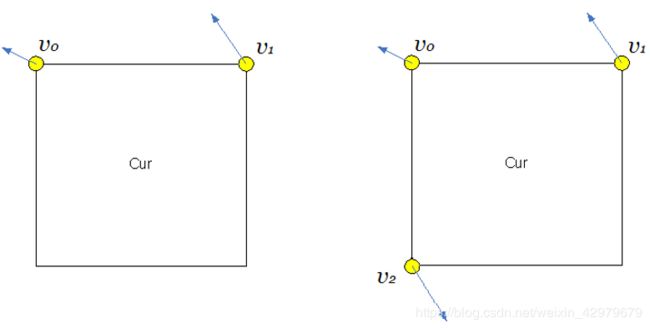
如下图所示,该块的仿射运动场由两个控制点(4参数)或三个控制点运动矢量(6参数)的运动信息描述。
1.1 计算方法
4参数模型下,在(x,y)点的小块的Mv计算如下:
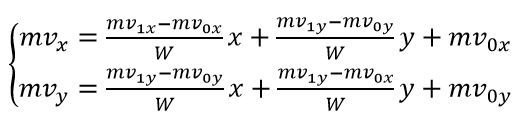
6参数模型下,在(x,y)点的小块的Mv计算如下:
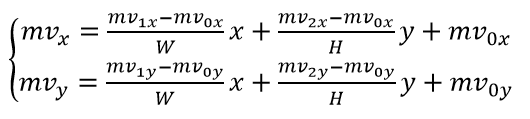
其中(mv0x,mv0y)是左上角控制点MV, (mv1x, mv1y) 是右上角控制点MV,(mv2x, mv2y) 左下角控制点MV。
1.2 子块大小
为了简化运动补偿预测,应用了基于块的仿射变换预测。
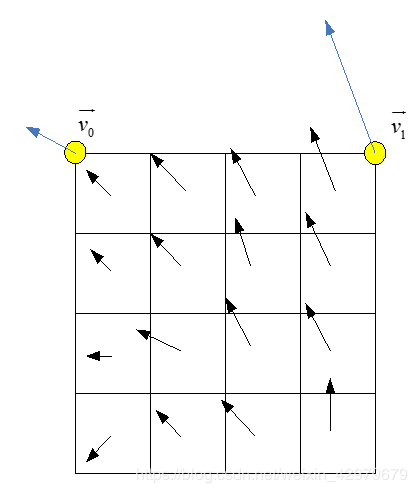
1、为了导出每个4×4亮度子块的运动矢量,根据上述等式计算每个子块的中心样本的运动矢量,如下图所示,并四舍五入为1/16像素精度。然后,将运动补偿插值滤波器应用于生成具有导出运动矢量的每个子块的预测。
2、色度分量的子块大小也设置为4×4。将4×4色度子块的MV计算为四个对应的4×4亮度子块的MV的平均值。
与平移运动帧间预测一样,仿射运动帧间预测模式也有两种:仿射AMVP模式和仿射merge模式。
两者的区别:对于仿射merge方式无需传输一些额外的索引值,只需传输索引即可,而仿射AMVP要传MVD等内容。
**术语:
CPMV:Affine的MV。
继承:当前CU的相邻CU是由affine得到的,那么把相邻CU的控制点的MV,直接作用到当前CU上。
构造:当前CU的相邻CU的MV
**
2 Affine merge
Affine merge模式可应用于宽度和高度均大于或等于8的CU。
在此模式下,当前CU的CPMV基于空间相邻CU的运动信息生成。
Affine merge模式里面需要构造一个属于自己的,存有5个值(五个值是指五组MV集合,每一组有2个或3个MV)的列表。这5个进行竞争,找到最好的并发信号以指示将用于当前CU的索引。这5个值的列表构造方法如下:
以下三种CPVM候选类型用于形成Affine merge候选列表:
1)使用相邻CU的CPMV,推断出的继承的仿射merge候选(最多2个);
2)使用相邻CU的MV,构造出的仿射merge候选者CPMVP(共6种组合,尽量填到5个);
3)零MV(如不足5个时使用)。
2.1 继承Affine merge候选
在VVC中,最多有两个继承的Affine候选,它们是从相邻块的仿射运动模型导出的,一个来自左相邻CU,一个来自上相邻CU。候选块如下图所示。
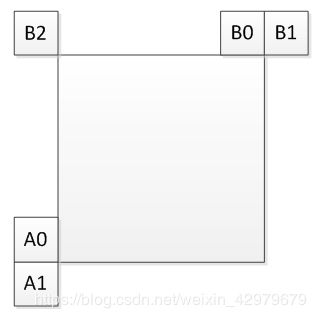
1、对于左预测变量,扫描顺序为A0到 A1;
2、对于上预测变量,扫描顺序为B0到B1再到B2。
3、仅选择来自双方的第一个候选(一般A0和B0)。在两个候选之间不执行冗余检查。
当识别出相邻的仿射CU时,其控制点MV被用于导出当前CU的仿射merge列表中的CPMVP候选。
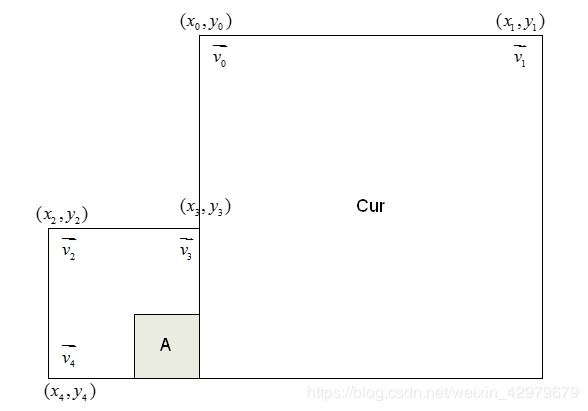
如图所示,如果以仿射模式对相邻的左下块A进行编码,则获得包含块A的CU的左上角,右上角和左下角的运动矢量v2,v3和v4。
1、如果块A使用4参数仿射模型时,将根据v2和v3计算当前CU的CPMV1和CPMV2;
2、如果块A使用6参数仿射模型时,则根据v2,v3和v4计算当前CU的CPMV1、CPMV2和CPMV3。
构成的一组列表候选种这2或3个CPMV直接作用到Cur(当前CU)上,进行仿射旋转。
2.2 构造Affine merge候选
构造Affine候选是指通过组合每个控制点的相邻平移运动信息来构造候选。控制点的运动信息是从下图的指定空间相邻获得的:
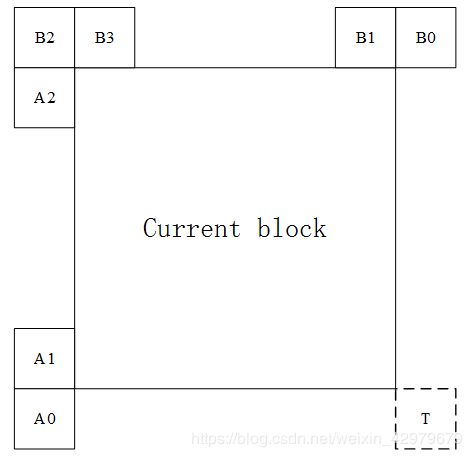
CPMVk(k = 1,2,3,4)表示第k个控制点。
1、对于CPMV1,检查B2-> B3-> A2块,并使用第一个可用块的MV;
2、对于CPMV2,检查B1-> B0块;
3、对于CPMV3,检查A1-> A0块;
4、对于CPMV4,检查TMVP是否可用。
在获得四个控制点的MV之后,基于这些运动信息构造Affine merge候选。控制点MV的以下组合用于按顺序构建:
1、{CPMV1,CPMV2,CPMV3}
2、{CPMV1,CPMV2,CPMV4}
3、{CPMV1,CPMV3,CPMV4}
4、{CPMV2,CPMV3,CPMV4}
5、{CPMV1,CPMV2}
6、{CPMV1,CPMV3}
3个MV可以构成6参数的仿射merge候选,2个MV可以构成4参数仿射merge候选。为了避免运动缩放过程,如果控制点的参考索引不同,则将丢弃控制点MV的相关组合。
2.3 零MV候选
在检查继承的仿射merge候选和构造的仿射meger候选之后,如果列表仍然不完整,则将零MV插入到列表的末尾。
3 Affine AMVP
Affine AMVP模式可应用于宽度和高度均大于或等于16的CU。限制:同一参考帧。
在比特流中发信号通知CU级别的仿射标志以指示是否使用仿射AMVP模式,然后发信号通知另一个标志以指示是否4参数仿射或6参数仿射。
在这种模式下,当前CU的CPMV和其预测变量CPMVP的差MVD在比特流中用信号发送。
仿射AVMP候选列表大小为2,它是通过使用以下四种方式找到CPMV候选,从而顺序生成的:
1)来自相邻CU的CPMV推断的继承的仿射AMVP候选
2)来自相邻CU的导出MV获取的仿射AMVP候选CPMVP
3)来自相邻CU的MV
4)零MV候选
3.1 继承Affine AMVP候选
继承的仿射AMVP候选的检查顺序与继承的仿射merge候选者的检查顺序相同,下面回顾一下:
1、对于左预测变量,扫描顺序为A0到 A1;
2、对于上预测变量,扫描顺序为B0到B1再到B2。
唯一的区别是,对于AVMP候选,仅考虑具有与当前块中相同的参考帧的仿射CU。将继承的仿射运动预测变量插入候选列表时,不应用冗余检测过程。
3.2 构造Affine AMVP候选
构造的AMVP候选依然从相邻块中派生。同样使用Affine merge候选构造中相同的检查顺序。下面我们再次回顾一下:
CPMVk(k = 1,2,3,4)表示第k个控制点。
1、对于CPMV1,检查B2-> B3-> A2块,并使用第一个可用块的MV;
2、对于CPMV2,检查B1-> B0块;
3、对于CPMV3,检查A1-> A0块;
4、对于CPMV4,检查TMVP是否可用。
另外,还检查相邻块的参考帧索引。使用检查顺序中的第一个块,该块进行了帧间编码并具有与当前CU中相同的参考帧。
不同于Affine merge,它得到的MV并不是排列组成作为候选,而是直接应用。
1、当使用4参数仿射模式对当前CU进行编码,并且两个CPMV都是可用的时,它们被添加为仿射AMVP列表中的一个候选对象。
2、当使用6参数仿射模式对当前CU进行编码,并且所有三个CPMV均可用时,它们被添加为仿射AMVP列表中的一个候选对象。
3、以上两个条件不成立时,构造Affine AMVP候选不可用。
3.3 相邻块的MV候选
如果在检查继承的仿射AMVP候选者和构造AMVP候选者之后,仿射AMVP列表候选者仍小于2,则将按顺序添加mv0,mv1和mv2(当这些MV可用时),作为平移MV来预测当前CU的所有控制点MV。
3.4 零MV候选
最后,如果仿射AMVP列表仍不满,则使用零MV来填充。
4 Affine运动信息存储
在VVC中,仿射CU的CPMV存储在单独的缓冲区中。
1、存储的CPMV仅用于为最近编码的CU以仿射merge模式和仿射AMVP模式生成继承的CPMVP。
2、从CPMV派生的子块MV用于运动补偿,MV派生,合并MV /平移MV的AMVP列表和去方块滤波。
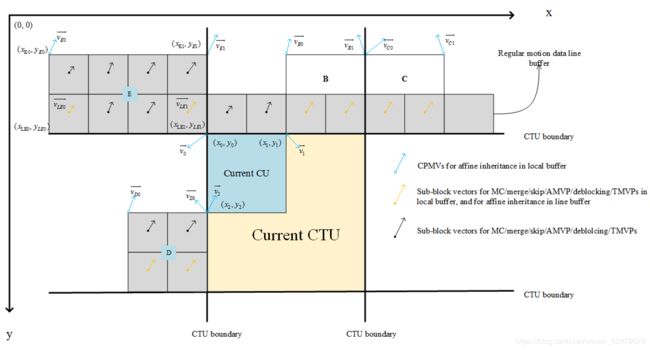
为了避免额外CPMV的图片行缓冲区,对来自上方CTU的CU的仿射运动数据继承与来自正常相邻CU的继承进行区别对待。
1、如果用于仿射运动数据继承的候选CU在上面CTU行中,则将行缓冲区中的左下和右下子块MV而不是CPMV用于仿射MVP推导。这样,CPMV仅存储在本地缓冲区中。
2、如果候选CU被6参数仿射编码,则仿射模型降级为4参数模型。如下图所示,沿着顶部CTU边界,CU的左下和右下子块运动矢量用于仿射继承底部CTU中的CU。
5 PROF
PROF是指使用Affine模式的光流进行预测细化。
与基于像素的运动补偿相比,基于子块的仿射运动补偿可以节省内存访问带宽并降低计算复杂度,但会降低预测精度。为实现更精细的运动补偿粒度,使用光流预测细化(PROF)来细化基于子块的仿射运动补偿预测,而无需增加用于运动补偿的内存访问带宽;在VVC中,在执行基于子块的仿射运动补偿后,通过添加由光流方程得出的差。
5.1 步骤
PROF描述为以下四个步骤:
步骤1)执行基于子块的仿射运动补偿以生成子块预测I(i,j)。
步骤2)使用3抽头滤波器[-1,0,1]在每个样本位置计算子块预测的空间梯度gx (i,j) 和 gy (i,j)。梯度计算与BDOF中的梯度计算完全相同。算式中shift1用于控制渐变的精度。将子块(即4x4)预测在每侧扩展一个样本以进行梯度计算。为避免额外的内存带宽和额外的插值计算,从参考图片中最近的整数像素位置复制了扩展边界上的那些扩展样本。
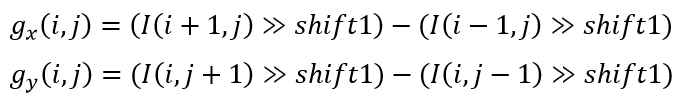
步骤3)通过以下光流方程计算亮度预测细化,下列算式中其中,Δv(i,j) 是为样本位置(i,j)计算的样本MV(用v(i,j)表示)与样本(i,j)所属的子块的子块MV之差,如下图所示。其中Δv(i,j)以1/32 像素精度为单位进行量化。


由于仿射模型参数和相对于子块中心的样本位置不会在子块之间更改,因此可以为第一个子块计算Δv(i,j),并在同一CU中将其重新用于其他子块。令 dx(i,j) and dy(i,j) 是从样本位置(i,j) 到子块(xsB,ysB) 的中心的水平和垂直偏移,Δv(x,y)可以通过以下公式得出:

为了保持准确性,子块的输入(x_SB,y_SB )计算为((WSB-1)/2, (HSB-1)/2),其中WSB和HSB分别是子块的宽度和高度。
对于4参数affine模型:

对于6参数affine模型:
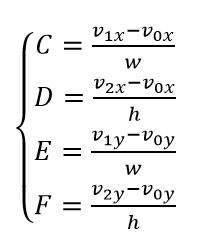
步骤4)最后,将亮度预测细化ΔI(i,j)添加到子块预测I(i,j)。最终预测I’生成为以下等式:

5.2 限制
对于仿射编码CU,在两种情况下不应用PROF:
1)所有控制点MV都相同,这表明CU仅具有平移运动;
2)仿射运动参数大于指定的限制,因为基于子块的仿射MC降级为基于CU的MC,以避免对大内存访问带宽的需求。
5.3 快速算法
一种快速编码方法被应用于降低使用PROF进行仿射运动估计的编码复杂度。
在以下两种情况下,仿射运动估计阶段未应用PROF:
1)如果此CU不是最大块,并且其父块未选择Affine模式作为其最佳模式,则不应用PROF,因为当前CU可能选择仿射模式,因为最佳模式并不好;
2)如果四个仿射参数(C,D,E,F)的大小均小于预定义阈值,并且当前图片不是低延迟图片,则不应用PROF因为对于这种情况,因为PROF引入的改进很小。这样,可以加速使用PROF的仿射运动估计。