操作系统(二):父子进程和共享内存(上)
操作系统(二):父子进程和共享内存(上)
一、杂七杂八的资料
1. printf,sprintf,fprintf:
在此之前先区分一下:printf,sprintf,fprintf。
-
printf就是标准输出,在屏幕上打印出一段字符串来。
-
sprintf就是把格式化的数据写入到某个字符串中。返回值字符串的长度。
-
fprintf是用于文件操作。
原型:int fprintf(FILE *stream,char *format,[argument]); 功能:fprintf()函数根据指定的format(格式)发送信息(参数)到由stream(流)指定的文件.因此fprintf()可以使得信息输出到指定的文件。
stdout, stdin, stderr 的中文名字分别是标准输出,标准输入和标准错误。
后面程序有用到 fprintf(stderr, “Fork failed”); 进行报错。
参考资料:https://blog.csdn.net/oppo62258801/article/details/69551223.
2. execlp():
从PATH 环境变量中查找文件并执行
参考资料:https://blog.csdn.net/21aspnet/article/details/7568067.
3. 编译C文件:
参考资料:https://blog.csdn.net/baidu_35692628/article/details/72299091.
4.*p=&a
*p=&a 是将a的地址赋给p指向的变量
p=&a 是将a的地址赋给p
但在变量定义语句中
int *p=&a;等价于int *p;p=&a;
5.Posix共享内存
POSIX共享内存的实现为内存映射文件,它将共享内存区域与文件相关联。
(1)首先进程通过调用 shm_open() 函数来创建共享内存对象,该函数返回一个描述符,在mmap函数第五个参数使用:
shm_fd = shm_open(name,oflag,mode);
name:指定共享内存对象的名称,为将要被打开或创建的共享内存对象,需要指定为/name的格式
oflag:
O_RDONLY(只读)
O_RDWR(读写)
O_CREAT(没有共享对象则创建)
O_EXCL(如果O_CREAT指定,但name不存在,就返回错误)
O_TRUNC(如果共享内存存在,长度就截断为0)
mode:设定共享内存对象的目录权限,在指定了O_CREAT的前提下使用,如果没有指定O_CREAT,mode可以指定为0.
/*例如*/
shm_fd = shm_open(name,O_CREAT | O_RDWR,0666);
当共享内存不存在时需要创建共享内存(O_CREAT);对象需要打开以便读写
(2)创建对象后,用 ftruncate() 配置对象的大小(以字节为单位),如下:
ftruncate(shm_fd,SIZE);
讲对象的大小设置为SIZE字节(例如:SIZE = 4096 即4096个字节)
(3)函数 mmap() 创建内存映射文件,以便包含共享内存对象。它返回一个指向内存映射文件的指针,以便用于访问共享内存对象。
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
start:映射区的开始地址
length:映射区的长度
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
fd:有效的文件描述词。如果MAP_ANONYMOUS被设定,为了兼容问题,其值应为-1
offset:被映射对象内容的起点
/*例如*/
ptr = mmap(0,SIZE,PROT_WRITE,MAP_SHARED,shm_fd,0);
PROT_WRITE表示映射的这一段可写
MAP_SHARED 对应射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
其余命令还有:PROT_NONE()表示映射的这一段不可访问)
MAP_PRIVATE
参考资料:https://www.cnblogs.com/huxiao-tee/p/4660352.html.
(4)最后,用完共享内存后,用 shm_unlink() 函数移除共享内存片段
shm_unlink(name);
二、作业一

(1)在本机编写Collatz1.c文件,并且发送到虚拟机的C2文件夹中(发送方法参考上一篇)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h> //为了wait()函数
int main(){
pid_t pid;
printf("\nWelcome\n");
int num = 0; //num为要输入的初始值
pid = fork(); //产生子进程
if(pid < 0){ /*出错*/
fprintf(stderr, "Fork failed");
return 1;
}
else if (pid == 0){ /*子进程*/
printf("Child is working...\n"); //2
printf("Please enter a number greater than 0 to run the Collatz Conjecture:\n");
scanf("%d", &num);
if(num == 1){
printf("1\n");
}
else{
printf("%d, ", num);
while(num != 1){
if(num%2 == 0){
num = num/2;
}
else{
num = 3*num + 1;
}
if(num != 1){
printf("%d, ", num);
}
else{
printf("1\n");
}
}
}
printf("Child process is done.\n"); //3
}
else{ /*父进程*/
printf("parents is waiting on child process...\n"); //顺序:1
wait(NULL);
printf("Parent process goes on again.\n"); //4
}
return 0;
}
(2)进入虚拟机的c2文件夹,编译.c文件
gcc Collatz1.c -o Collatz1 -lrt //编译Collatz1.c文件
./Collatz1 //运行Collatz1.c文件
(3)测试效果如下
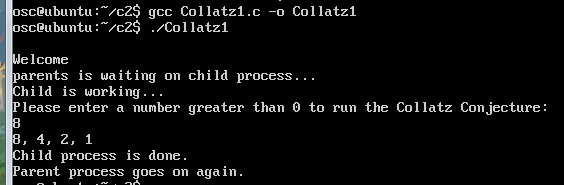
作业一 over~
三、作业二

思路:即在前一个作业的前提下用上共享内存,即可以将子程序中将数据存入共享内存里,然后父程序读取共享内存中的数据。
可以直接用int main(int argc, char **argv) 中的argv[1]做参数num,这样就不用scanf输入num值了。

argc 表示接收的命令个数
argv 传入的命令内容
argc == 1 就是说参数的个数为1(程序本身肯定为一个,后加参数则再加).
argv是字符串数组,存的是参数,定义为char**或者char* argv[]
【举例】
比如你编译好的程序为my.exe
(1)在命令行执行 my.exe
则:此时argc就是1,接受参数是1个,即参数argv[0]是”my.exe”
(2)在命令行执行 my.exe 1 2 3
则:此时argc就是4,接受参数是4个,
即参数argv[0]是”my.exe”,argv[1]是”1”,argv[2]是”2”,argv[3]是”3”;
...
(1)Collatz2.c如下
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h> /*For ftruncate*/
#include <wait.h> /*For wait*/
#include <sys/mman.h> /*For shm_open*/
#include <fcntl.h> /*For 0_* constant*/
#include <sys/stat.h>
#include <sys/types.h>
int main(int argc, char **argv){
/*First create a shared memory area.*/
const int SIZE = 4096;
const char *name ="OS"; //共享内存的名字
const int BUFFER_SIZE = 1024; //共享内存的大小
int shm_fd;
void *ptr;
/*创建一个共享对象
shm_fd = shm_open(name,O_CREAT | O_RDWR,0666);
第一个参数
*/
shm_fd = shm_open(name,O_CREAT | O_RDWR,0666);
ftruncate(shm_fd,SIZE);/*Truncate the file*/
/*ptr为指向内存映射文件的指针*/
ptr = mmap(0,SIZE,PROT_WRITE,MAP_SHARED,shm_fd,0);/* Map the file into memory*/
/*And now we create the process*/
pid_t pid;
pid = fork();
if (pid < 0){
fprintf(stderr,"Fork Failed\n");
shm_unlink(name);
return 1;
}
else if (pid ==0){
/*child process*/
char buffer[BUFFER_SIZE]; //创建buffer存所有字符串
memset(buffer,0,sizeof(char)*BUFFER_SIZE); //buffer为字符串,buffer[0]为字符串首字符
char *buffer_p = &buffer[0]; //将 buffer[0]即字符串首字符的地址赋给buffer_p
/*argc==1即只有程序本身没有传多余的参数,本程序只需要一个参数num,因此argc==2才行,否则报错*/
if (argc == 1 || argc > 2){
fprintf(stderr,"Pass invalid args!\n");
shm_unlink(name);
return 1;
}
/*传进来的参数都是字符串,因此要用atoi函数把字符串转换成整型数*/
int num = atoi(argv[1]);
/*
因为要写入具体的数字,而数字的长度虽然可以通过itoa+strlen求得,
但是每次都得这样求容易出错。我的做法是开一个buffer,
先在buffer里面写数据,再通过sprintf一次性将buffer的内容写入ptr,
这样也避免了ptr每次都要移动。通过移动一开始指向buffer首地址的指针,
比移动ptr我觉得要稍微安全那么一点。sprintf每次会返回写入的长度(不包括\0字符),
这也给我们移动指向buffer的指针带来了方便。
buffer_p为字符的地址,上面将其初始化为了字符串的首字符地址
*/
/*/num存入字符串 buffer_p[]中,并将buffer_p指针后移该字符长度,下同 */
buffer_p += sprintf(buffer_p,"%d,",num);
while (num != 1){
if (num % 2 == 0)/*Even*/{
num = num / 2;
if (num == 1){
buffer_p += sprintf(buffer_p,"%d\n",num);
}
else{
buffer_p += sprintf(buffer_p,"%d,",num);
}
}
else{
num = 3*num + 1;
buffer_p += sprintf(buffer_p,"%d,",num);
}
}
sprintf(ptr,"%s",buffer); //buffer的地址给共享内存的地址ptr
printf("The data to shared memory has written.\n");
}
else{
/*Parent process*/
wait(NULL);
printf("Reading the shared memory\n");
/*open the shared memory object*/
shm_fd = shm_open(name,O_RDONLY, 0666);
/*memory map the shared memory object*/
ptr = mmap(0,SIZE,PROT_READ,MAP_SHARED,shm_fd,0);
printf("%s",(char *)ptr);
shm_unlink(name); //移除共享内存段
}
return 0;
}
那么,怎么编译运行呢?如下~
gcc -o Collatz2.o Collatz2.c -lrt //编译
./Collatz2.o 24 //运行并且传入参数argv[1] = 24(即num = 24)
作业二 over~