kube-batch源码梳理
目录
一、Cache
1.1 type SchedulerCache
1.2 newSchedulerCache方法
1.2.1 Pod
1.2.2 PodGroup
1.3 Run方法
1.4 Snapshot方法
1.5 Bind、Evict方法
二、Session
三、Plugin
0、plugin配置
1、drf
1.1 统计集群中所有node可分配资源总量
1.2 统计Job资源申请,计算资源占比
1.3 注册抢占函数
1.4 注册Job排序函数
1.5 调用ssn.AddEventHandler 注册事件处理函数
2、gang
2.1 注册job校验函数
2.2 注册抢占函数
2.3 注册job排序函数
2.4 注册JobReady函数
3、predicates
4、priority
4.1 注册task排序函数
4.2 注册job排序函数
4.3 注册抢占函数
四、Action
4.1 reclaim(回收)
4.2 Allocate(分配)
4.3 Backfill(回填)
4.4 Preempt(抢占)
一、Cache
“缓存与封装”,主要两个功能:
-
调用 K8s 的 sdk,watch集群中节点、容器的状态变化,将信息同步到自己的数据结构中。
-
封装了 API server 的接口。kube-batch 中,只有 cache 模块和 API Server 交互,其他模块只需要调用 Cache 模块接口即可。比如 Cache.Bind 接口,会调用 API Server 的 Bind 接口,将容器绑定到指定节点上。
以下代码分析主要在pkg/scheduler/cache/cache.go
1.1 type SchedulerCache

主要由以下组件组成:
-
sync.Mutex锁,解决snapshot一致性问题
-
K8S clients,访问apiserver
-
Informers,ListWatch REST
-
Jobs/Nodes/Queues,缓存REST
1.2 newSchedulerCache方法
pkg/scheduler/cache/cache.go newSchedulerCache方法
主要负责各个Informer的事件注册
1.2.1 Pod
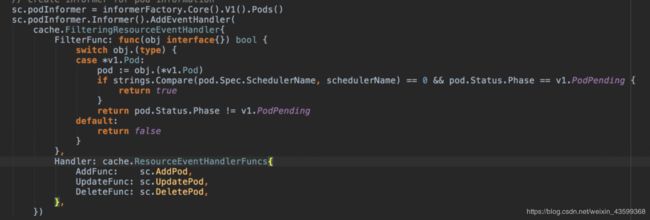
可以发现,kube-batch只关心需要自己调度,并且Pending的Pod;
下面看下注册的函数,AddPod
(kube-batch\pkg\scheduler\cache\event_handlers.go)

只有一把锁,可能是性能瓶颈。
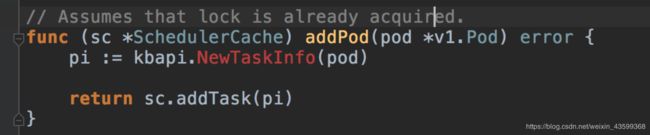
从addPod可以看出,kube-batch会将Pod转换成TaskInfo缓存起来。
1.2.2 PodGroup

下面看下注册的函数,AddPodGroupAlpha1
(kube-batch\pkg\scheduler\cache\event_handlers.go)
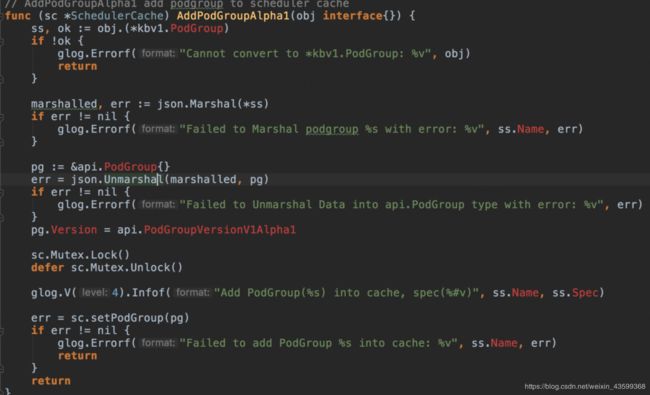
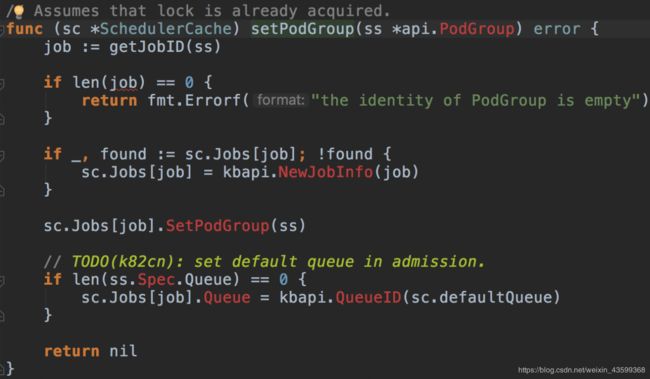
可以看到Job就是PodGroup
1.3 Run方法
入口是pkg/scheduler/scheduler.go
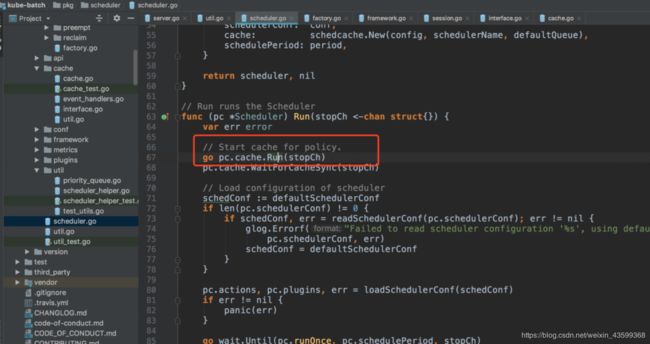

run方法比较简单,主要负责:
-
开始各个REST的ListWatch,其中包括PDB\pod\node\podGroup\pv\pvc\sc等,其中PodGroup是kube-batch定义的CRDs,是实现批量调度的核心。
-
根据processResyncTask队列,重新同步Pod状态
-
根据processCleanupJob队列,清理缓存
1.4 Snapshot方法

主要利用Deep Clone
1.5 Bind、Evict方法
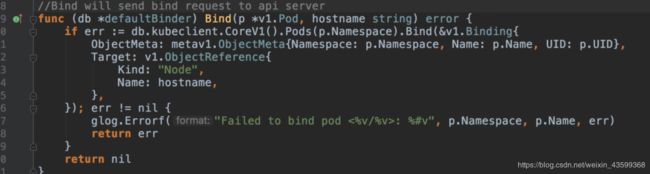
正如注释所说,Bind will send bind request to api server(Bind方法会给kapiserver发送Bind请求)
类似的还有Evict方法

Evict will send delete pod request to api server
二、Session
“会话”,顾名思义,session主要是是用来存储一次调度过程的信息,用来将其他三个模块关联起来。
Kube-batch 在每个调度周期开始时,都会新建一个 Session 对象
/pkg/scheduler/scheduler.go
 /pkg/scheduler/framework/framework.go
/pkg/scheduler/framework/framework.go

session初始化时会做两件事:
-
调用 Cache.Snapshot ,将 Cache 中节点、任务和队列信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。
/pkg/scheduler/framework/session.go
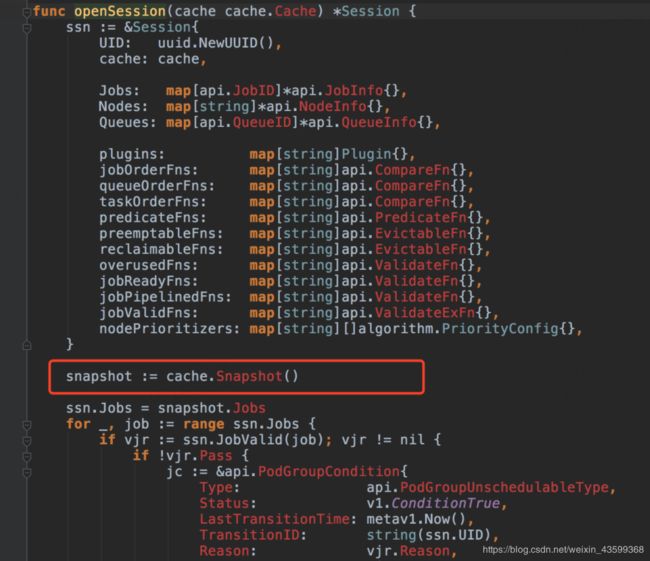
-
将配置中的各个 plugin 初始化,然后调用 plugin 的 OnSessionOpen 接口。plugin 在 OnSessionOpen 中,会初始化自己需要的数据,并将一些回调函数注册到 session 中。
/pkg/scheduler/framework/framework.go

初始化成功后,Kube-batch 会依次调用不同的 Action 的 Execute 方法,并将 Session 对象作为参数传入。
/pkg/scheduler/scheduler.go
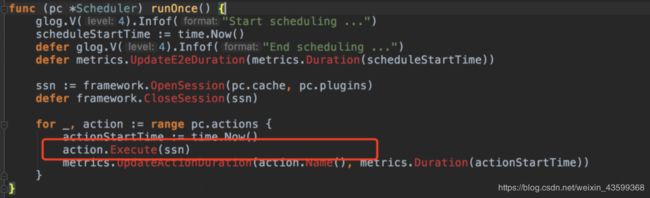
三、Plugin
Plugin 模块提供了一种可插拔的方式,向调度提供不同的策略的实现。
0、plugin配置
默认情况下的配置参考,如果需要修改可以直接编辑文件
pkg/scheduler.utils
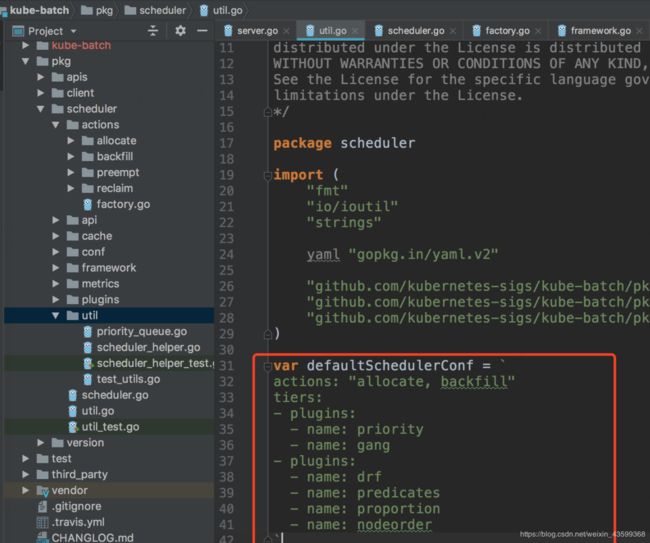
在session初始化时,会执行plugins的OnSessionOpen方法,下面介绍及格比较常用的Plugin的OnSessionOpen方法:
1、drf
/pkg/scheduler/plugins/drf/drf.go
1.1 统计集群中所有node可分配资源总量
for _, n := range ssn.Nodes {
drf.totalResource.Add(n.Allocatable)
}1.2 统计Job资源申请,计算资源占比
(资源申请/资源总量)
for _, job := range ssn.Jobs {
attr := &drfAttr{
allocated: api.EmptyResource(),
}
for status, tasks := range job.TaskStatusIndex {
if api.AllocatedStatus(status) {
for _, t := range tasks {
attr.allocated.Add(t.Resreq)
}
}
}
// Calculate the init share of Job
drf.updateShare(attr)
drf.jobOpts[job.UID] = attr
}1.3 注册抢占函数
preemptableFn
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) []*api.TaskInfo {
var victims []*api.TaskInfo
latt := drf.jobOpts[preemptor.Job]
lalloc := latt.allocated.Clone().Add(preemptor.Resreq)
ls := drf.calculateShare(lalloc, drf.totalResource)
allocations := map[api.JobID]*api.Resource{}
for _, preemptee := range preemptees {
if _, found := allocations[preemptee.Job]; !found {
ratt := drf.jobOpts[preemptee.Job]
allocations[preemptee.Job] = ratt.allocated.Clone()
}
ralloc := allocations[preemptee.Job].Sub(preemptee.Resreq)
rs := drf.calculateShare(ralloc, drf.totalResource)
if ls < rs || math.Abs(ls-rs) <= shareDelta {
victims = append(victims, preemptee)
}
}
glog.V(4).Infof("Victims from DRF plugins are %+v", victims)
return victims
}
ssn.AddPreemptableFn(drf.Name(), preemptableFn)1.4 注册Job排序函数
jobOrderFn
根据资源占比进行排序,主要资源占比越低job优先级越高
jobOrderFn := func(l interface{}, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
glog.V(4).Infof("DRF JobOrderFn: <%v/%v> share state: %d, <%v/%v> share state: %d",
lv.Namespace, lv.Name, drf.jobOpts[lv.UID].share, rv.Namespace, rv.Name, drf.jobOpts[rv.UID].share)
if drf.jobOpts[lv.UID].share == drf.jobOpts[rv.UID].share {
return 0
}
if drf.jobOpts[lv.UID].share < drf.jobOpts[rv.UID].share {
return -1
}
return 1
}
ssn.AddJobOrderFn(drf.Name(), jobOrderFn)1.5 调用ssn.AddEventHandler 注册事件处理函数
包括分配函数(AllocateFunc)以及归还函数(DeallocateFunc)
函数实现比较简单,就是当task发生变化时,增加(分配)/减少(归还)Job资源申请总量,并且更新资源占比。
ssn.AddEventHandler(&framework.EventHandler{
AllocateFunc: func(event *framework.Event) {
attr := drf.jobOpts[event.Task.Job]
attr.allocated.Add(event.Task.Resreq)
drf.updateShare(attr)
glog.V(4).Infof("DRF AllocateFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
DeallocateFunc: func(event *framework.Event) {
attr := drf.jobOpts[event.Task.Job]
attr.allocated.Sub(event.Task.Resreq)
drf.updateShare(attr)
glog.V(4).Infof("DRF EvictFunc: task <%v/%v>, resreq <%v>, share <%v>",
event.Task.Namespace, event.Task.Name, event.Task.Resreq, attr.share)
},
})2、gang
/pkg/scheduler/plugins/gang/gang.go
2.1 注册job校验函数
validJobFn
检查Job的task(Pod)数量,是否满足要求。如果不满足数量要求,就返回校验失败,不调度job
validJobFn := func(obj interface{}) *api.ValidateResult {
job, ok := obj.(*api.JobInfo)
if !ok {
return &api.ValidateResult{
Pass: false,
Message: fmt.Sprintf("Failed to convert <%v> to *JobInfo", obj),
}
}
vtn := job.ValidTaskNum()
if vtn < job.MinAvailable {
return &api.ValidateResult{
Pass: false,
Reason: v1alpha1.NotEnoughPodsReason,
Message: fmt.Sprintf("Not enough valid tasks for gang-scheduling, valid: %d, min: %d",
vtn, job.MinAvailable),
}
}
return nil
}
ssn.AddJobValidFn(gp.Name(), validJobFn)2.2 注册抢占函数
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) []*api.TaskInfo {
var victims []*api.TaskInfo
for _, preemptee := range preemptees {
job := ssn.Jobs[preemptee.Job]
occupid := job.ReadyTaskNum()
preemptable := job.MinAvailable <= occupid-1 || job.MinAvailable == 1
if !preemptable {
glog.V(4).Infof("Can not preempt task <%v/%v> because of gang-scheduling",
preemptee.Namespace, preemptee.Name)
} else {
victims = append(victims, preemptee)
}
}
glog.V(4).Infof("Victims from Gang plugins are %+v", victims)
return victims
}
// TODO(k82cn): Support preempt/reclaim batch job.
ssn.AddReclaimableFn(gp.Name(), preemptableFn)
ssn.AddPreemptableFn(gp.Name(), preemptableFn)2.3 注册job排序函数
根据Job是否ready排序,ready的大
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
lReady := lv.Ready()
rReady := rv.Ready()
glog.V(4).Infof("Gang JobOrderFn: <%v/%v> is ready: %t, <%v/%v> is ready: %t",
lv.Namespace, lv.Name, lReady, rv.Namespace, rv.Name, rReady)
if lReady && rReady {
return 0
}
if lReady {
return 1
}
if rReady {
return -1
}
return 0
}
ssn.AddJobOrderFn(gp.Name(), jobOrderFn)2.4 注册JobReady函数
非pending,即已经调度的task数量大于等于要求数量
ssn.AddJobReadyFn(gp.Name(), func(obj interface{}) bool {
ji := obj.(*api.JobInfo)
return ji.Ready()
})
ssn.AddJobPipelinedFn(gp.Name(), func(obj interface{}) bool {
ji := obj.(*api.JobInfo)
return ji.Pipelined()
})3、predicates
/pkg/scheduler/plugins/predicates/predicates.go
predicates唯一负责的事情就是注册预选函数,函数来自default scheduler。
可以看出顺序调用了以下方法:
-
CheckNodeConditionPredicate
-
CheckNodeUnschedulablePredicate
-
PodMatchNodeSelector
-
PodFitsHostPorts
-
PodToleratesNodeTaints
-
CheckNodeMemoryPressurePredicate
-
CheckNodeDiskPressurePredicate
-
CheckNodePIDPressurePredicate
-
NewPodAffinityPredicate
ssn.AddPredicateFn(pp.Name(), func(task *api.TaskInfo, node *api.NodeInfo) error {
nodeInfo := cache.NewNodeInfo(node.Pods()...)
nodeInfo.SetNode(node.Node)
if node.Allocatable.MaxTaskNum <= len(nodeInfo.Pods()) {
return fmt.Errorf("node <%s> can not allow more task running on it", node.Name)
}
// CheckNodeCondition Predicate
fit, reasons, err := predicates.CheckNodeConditionPredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("CheckNodeCondition predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> are not available to schedule task <%s/%s>: %s",
node.Name, task.Namespace, task.Name, formatReason(reasons))
}
// CheckNodeUnschedulable Predicate
fit, _, err = predicates.CheckNodeUnschedulablePredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("CheckNodeUnschedulable Predicate Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("task <%s/%s> node <%s> set to unschedulable",
task.Namespace, task.Name, node.Name)
}
// NodeSelector Predicate
fit, _, err = predicates.PodMatchNodeSelector(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("NodeSelect predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> didn't match task <%s/%s> node selector",
node.Name, task.Namespace, task.Name)
}
// HostPorts Predicate
fit, _, err = predicates.PodFitsHostPorts(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("HostPorts predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> didn't have available host ports for task <%s/%s>",
node.Name, task.Namespace, task.Name)
}
// Toleration/Taint Predicate
fit, _, err = predicates.PodToleratesNodeTaints(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("Toleration/Taint predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("task <%s/%s> does not tolerate node <%s> taints",
task.Namespace, task.Name, node.Name)
}
if predicate.memoryPressureEnable {
// CheckNodeMemoryPressurePredicate
fit, _, err = predicates.CheckNodeMemoryPressurePredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("CheckNodeMemoryPressure predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> are not available to schedule task <%s/%s> due to Memory Pressure",
node.Name, task.Namespace, task.Name)
}
}
if predicate.diskPressureEnable {
// CheckNodeDiskPressurePredicate
fit, _, err = predicates.CheckNodeDiskPressurePredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("CheckNodeDiskPressure predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> are not available to schedule task <%s/%s> due to Disk Pressure",
node.Name, task.Namespace, task.Name)
}
}
if predicate.pidPressureEnable {
// CheckNodePIDPressurePredicate
fit, _, err = predicates.CheckNodePIDPressurePredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("CheckNodePIDPressurePredicate predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("node <%s> are not available to schedule task <%s/%s> due to PID Pressure",
node.Name, task.Namespace, task.Name)
}
}
// Pod Affinity/Anti-Affinity Predicate
podAffinityPredicate := predicates.NewPodAffinityPredicate(ni, pl)
fit, _, err = podAffinityPredicate(task.Pod, nil, nodeInfo)
if err != nil {
return err
}
glog.V(4).Infof("Pod Affinity/Anti-Affinity predicates Task <%s/%s> on Node <%s>: fit %t, err %v",
task.Namespace, task.Name, node.Name, fit, err)
if !fit {
return fmt.Errorf("task <%s/%s> affinity/anti-affinity failed on node <%s>",
node.Name, task.Namespace, task.Name)
}
return nil
}4、priority
/pkg/scheduler/plugins/priority/priority.go
4.1 注册task排序函数
根据pod优先级排序
taskOrderFn := func(l interface{}, r interface{}) int {
lv := l.(*api.TaskInfo)
rv := r.(*api.TaskInfo)
glog.V(4).Infof("Priority TaskOrder: <%v/%v> priority is %v, <%v/%v> priority is %v",
lv.Namespace, lv.Name, lv.Priority, rv.Namespace, rv.Name, rv.Priority)
if lv.Priority == rv.Priority {
return 0
}
if lv.Priority > rv.Priority {
return -1
}
return 1
}
// Add Task Order function
ssn.AddTaskOrderFn(pp.Name(), taskOrderFn)4.2 注册job排序函数
根据job优先级排序
jobOrderFn := func(l, r interface{}) int {
lv := l.(*api.JobInfo)
rv := r.(*api.JobInfo)
glog.V(4).Infof("Priority JobOrderFn: <%v/%v> priority: %d, <%v/%v> priority: %d",
lv.Namespace, lv.Name, lv.Priority, rv.Namespace, rv.Name, rv.Priority)
if lv.Priority > rv.Priority {
return -1
}
if lv.Priority < rv.Priority {
return 1
}
return 0
}
ssn.AddJobOrderFn(pp.Name(), jobOrderFn)4.3 注册抢占函数
preemptableFn := func(preemptor *api.TaskInfo, preemptees []*api.TaskInfo) []*api.TaskInfo {
preemptorJob := ssn.Jobs[preemptor.Job]
var victims []*api.TaskInfo
for _, preemptee := range preemptees {
preempteeJob := ssn.Jobs[preemptee.Job]
if preempteeJob.Priority >= preemptorJob.Priority {
glog.V(4).Infof("Can not preempt task <%v/%v> because "+
"preemptee has greater or equal job priority (%d) than preemptor (%d)",
preemptee.Namespace, preemptee.Name, preempteeJob.Priority, preemptorJob.Priority)
} else {
victims = append(victims, preemptee)
}
}
glog.V(4).Infof("Victims from Priority plugins are %+v", victims)
return victims
}
ssn.AddPreemptableFn(pp.Name(), preemptableFn)四、Action
Action 实现了调度机制(mechanism),Plugin 实现了调度的不同策略(policy)。
-
Reclaim: 这个 Action 负责将任务中满足回收条件的容器删除。
-
Allocate: 这个 Action 负责将还未调度的设置了资源限制(request、Limit)的容器调度到节点上。
-
Backfill: 这个 Action 负责将还未调度的的没设置资源限制的容器调度到节点上。
-
Preempt: 这个 Action 负责将任务中满足条件的容器抢占。
重点关注execute方法
4.1 reclaim(回收)
kube-batch\pkg\scheduler\actions\reclaim\reclaim.go
-
根据优先级排序queue
-
将待调度的task保存为抢占者
queues := util.NewPriorityQueue(ssn.QueueOrderFn)
queueMap := map[api.QueueID]*api.QueueInfo{}
preemptorsMap := map[api.QueueID]*util.PriorityQueue{}
preemptorTasks := map[api.JobID]*util.PriorityQueue{}
glog.V(3).Infof("There are <%d> Jobs and <%d> Queues in total for scheduling.",
len(ssn.Jobs), len(ssn.Queues))
var underRequest []*api.JobInfo
for _, job := range ssn.Jobs {
if queue, found := ssn.Queues[job.Queue]; !found {
glog.Errorf("Failed to find Queue <%s> for Job <%s/%s>",
job.Queue, job.Namespace, job.Name)
continue
} else {
if _, existed := queueMap[queue.UID]; !existed {
glog.V(4).Infof("Added Queue <%s> for Job <%s/%s>",
queue.Name, job.Namespace, job.Name)
queueMap[queue.UID] = queue
queues.Push(queue)
}
}
if len(job.TaskStatusIndex[api.Pending]) != 0 {
if _, found := preemptorsMap[job.Queue]; !found {
preemptorsMap[job.Queue] = util.NewPriorityQueue(ssn.JobOrderFn)
}
preemptorsMap[job.Queue].Push(job)
underRequest = append(underRequest, job)
preemptorTasks[job.UID] = util.NewPriorityQueue(ssn.TaskOrderFn)
for _, task := range job.TaskStatusIndex[api.Pending] {
preemptorTasks[job.UID].Push(task)
}
}
}找到优先级最高的queue,job,task
for {
// If no queues, break
if queues.Empty() {
break
}
var job *api.JobInfo
var task *api.TaskInfo
queue := queues.Pop().(*api.QueueInfo)
if ssn.Overused(queue) {
glog.V(3).Infof("Queue <%s> is overused, ignore it.", queue.Name)
continue
}
// Found "high" priority job
if jobs, found := preemptorsMap[queue.UID]; !found || jobs.Empty() {
continue
} else {
job = jobs.Pop().(*api.JobInfo)
}
// Found "high" priority task to reclaim others
if tasks, found := preemptorTasks[job.UID]; !found || tasks.Empty() {
continue
} else {
task = tasks.Pop().(*api.TaskInfo)
}
遍历node {
执行预选函数PredicateFn
找到node上正在运行的pod
找到受害者
如果受害者资源总量小于pod申请资源总量,就跳过
驱逐受害者,调用删除接口
如果释放足够的资源,就跳出驱逐
}
assigned := false
for _, n := range ssn.Nodes {
// If predicates failed, next node.
if err := ssn.PredicateFn(task, n); err != nil {
continue
}
resreq := task.InitResreq.Clone()
reclaimed := api.EmptyResource()
glog.V(3).Infof("Considering Task <%s/%s> on Node <%s>.",
task.Namespace, task.Name, n.Name)
var reclaimees []*api.TaskInfo
for _, task := range n.Tasks {
// Ignore non running task.
if task.Status != api.Running {
continue
}
if j, found := ssn.Jobs[task.Job]; !found {
continue
} else if j.Queue != job.Queue {
// Clone task to avoid modify Task's status on node.
reclaimees = append(reclaimees, task.Clone())
}
}
victims := ssn.Reclaimable(task, reclaimees)
if len(victims) == 0 {
glog.V(3).Infof("No victims on Node <%s>.", n.Name)
continue
}
// If not enough resource, continue
allRes := api.EmptyResource()
for _, v := range victims {
allRes.Add(v.Resreq)
}
if !resreq.LessEqual(allRes) {
glog.V(3).Infof("Not enough resource from victims on Node <%s>.", n.Name)
continue
}
// Reclaim victims for tasks.
for _, reclaimee := range victims {
glog.Errorf("Try to reclaim Task <%s/%s> for Tasks <%s/%s>",
reclaimee.Namespace, reclaimee.Name, task.Namespace, task.Name)
if err := ssn.Evict(reclaimee, "reclaim"); err != nil {
glog.Errorf("Failed to reclaim Task <%s/%s> for Tasks <%s/%s>: %v",
reclaimee.Namespace, reclaimee.Name, task.Namespace, task.Name, err)
continue
}
reclaimed.Add(reclaimee.Resreq)
// If reclaimed enough resources, break loop to avoid Sub panic.
if resreq.LessEqual(reclaimed) {
break
}
}
glog.V(3).Infof("Reclaimed <%v> for task <%s/%s> requested <%v>.",
reclaimed, task.Namespace, task.Name, task.InitResreq)
if task.InitResreq.LessEqual(reclaimed) {
if err := ssn.Pipeline(task, n.Name); err != nil {
glog.Errorf("Failed to pipeline Task <%s/%s> on Node <%s>",
task.Namespace, task.Name, n.Name)
}
// Ignore error of pipeline, will be corrected in next scheduling loop.
assigned = true
break
}
}
if assigned {
queues.Push(queue)
}
}4.2 Allocate(分配)
kube-batch\pkg\scheduler\actions\Allocate\Allocate.go
整体过程比较简单:
遍历node {
执行预选函数PredicateFn
比较pod资源申请和node空闲资源
bind
}
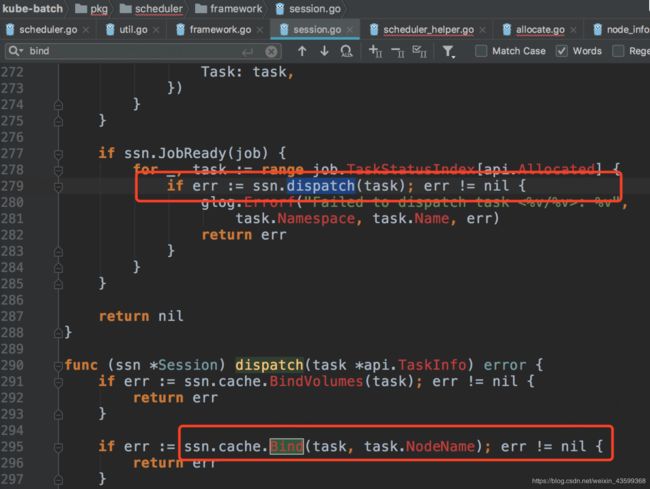
Allocate action中筛选出bestNode之后,调用session.Allocate(task, node.Name)
在session的allocate方法中,会调用cache.bind方法向kube-apiserver发送bind请求
4.3 Backfill(回填)
kube-batch\pkg\scheduler\actions\Backfill\Backfill.go
4.4 Preempt(抢占)
kube-batch\pkg\scheduler\actions\Preempt\Preempt.go