DRF框架知识点总结
web开发的两种模式:前后端不分离和前后端分离
RestFul API接口设计风格:前后端分离被广泛采用
使用Django基础自定义Rest API接口
DRF框架: 提高开发Rest API接口的效率
web开发的两种模式
前后端不分离:前端看到的效果是由后端进行控制的
缺点:只适用于纯网页的应用。
优点:有利于网站的SEO优化。
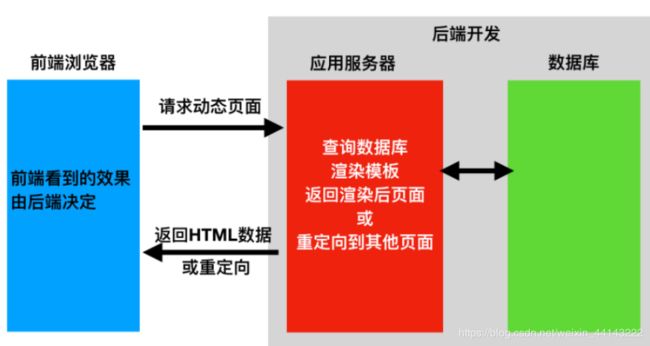
前后端分离:后端只返回前端所需的数据,至于数据怎么进行展示,由前端自己控制。
优点:可以对接不同类型的客户端。
缺点:不利于SEO优化

RestFul API接口设计风格介绍
统一接口设计风格:
1.URL地址尽量使用名词,不要出现动词
2.使用不同的请求方式,代表要执行不同的操作
(GET)获取 POST(新增) PUT(修改)DELETE(删除)
不常用:PATCH(修改) HEAD(只返回请求头没有请求体) OPTIONS(获取信息)
3.访问URL地址时,如果有一些过滤的参数,参数可以放到查询字符串中
4.响应数据:
GET /books/:返回所有的图书数据
GET /books/1/:返回id为1的图书数据
POST /books/:将新增的图书数据返回
PUT /books/1/:将修改的图书数据返回
DELETE /books/1:返回空文档
获取|修改:200
新增:201
删除:204
参数有误:400
服务器出错:500
5.响应数据的格式:json
了解:1.域名:使用专有域名
2.版本:将版本信息放在url地址
3.错误:将错误信息返回
4.在访问api接口时,将和接口相关的其他API接口的地址也在响应数据中返回
Django自定义RestAPI
需求:
设计一套符合RestAPI风格的接口,提供以下5个接口:
1. 获取所有图书数据:GET /books/
2. 新增一本图书数据:POST /books/
3. 获取指定的图书数据(根据id):GET /books/(?P\d+)/
4. 修改指定的图书数据(根据id):PUT /books/(?P\d+)/
5. 删除指定的图书数据(根据id):DELETE /books/(?P\d+)/
# 2个类视图
class BookListView(View):
# GET /books/
def get(self, request):
"""
获取所有图书数据:
1. 查询所有图书的数据
2. 将图书的数据进行返回
数据格式:json 状态码:200
"""
# 1. 查询所有图书的数据
books = BookInfo.objects.all() # QuerySet
# 组织数据
books_li = []
for book in books:
book_dict = {
'id': book.id,
'btitle': book.btitle,
'bpub_date': book.bpub_date,
'bread': book.bread,
'bcomment': book.bcomment,
'image': book.image.url if book.image else ''
}
books_li.append(book_dict)
# 2. 将图书的数据进行返回
# 注意点:将list转换为json数据时,需要将safe设置False
return JsonResponse(books_li, safe=False)
# POST /books/
# 参数:客户端传递 btitle,bpub_date,通过json传递
def post(self, request):
"""
新增一本图书数据:
1. 获取参数并进行校验:request.body->decode->json.loads
2. 创建图书并添加到数据库
3. 将新增的图书数据进行返回
数据格式:json 状态码:200
"""
pass
class BookDetailView(View):
# GET /books/(?P\d+)/
def get(self, request, pk):
"""获取指定的图书数据(根据id)"""
pass
# PUT /books/(?P\d+)/
def put(self, request, pk):
"""修改指定的图书数据(根据id)"""
pass
# DELETE /books/(?P\d+)/
def delete(self, request, pk):
"""删除指定的图书数据(根据id)"""
pass
DRF框架-RestAPI接口的核心工作
序列化:将模型对象转换为字典或者json的过程,叫做序列化的过程。
反序列化:将客户端传递的数据保存转化到模型对象的过程,叫做反序列化的过程。
核心:
1. 将数据库数据序列化为前端所需要的格式,并返回;
2. 将前端发送的数据反序列化为模型类对象,并保存到数据库中。
Django RestFrameWork 简介/安装
作用:提高RestAPI接口开发的效率
关键功能:
序列化器:序列化和反序列化
类视图,MiXin扩展类:简化视图代码的编写
安装: pip install djangorestframework
在settings.py的INSTALLED_APPS中添加’rest_framework’。
INSTALLED_APPS = [
...
'rest_framework', # 添加
]
DRF框架功能演示
序列化器Serializer-功能&知识点说明
功能:进行数据的序列化和反序列化
使用:首先定义序列化器类
序列化功能:将对象转换字典。
1.序列化单个对象
2.序列化多个对象
3.关联对象的嵌套序列化
反序列化功能:
数据校验:
1.基本验证
2.补充验证
数据保存
1.数据新增create
2.数据更新update
序列化器Serializer-定义&基本使用
定义模型类:
class 模型类(modles.Model):
模型字段 = models.字段类型(选项参数)
定义序列化器类:
from rest_framework import serializers
class 序列化器类(serializers.Serializer):
序列化器字段= serializers.字段类型(选项参数)
序列化器类(instance=None,data={},**kwargs)
1.进行序列化操作,将对象传递给instance
2.进行反序列化操作,将数据传递给data
在tests.py文件中进行演示:
import os
import django
from django.test import TestCase
# Create your tests here.
if not os.environ.get("DJANGO_SETTINGS_MODULE"):
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "drf_demo.settings")
# 让django进行一次初始化
import django
django.setup()
from rest_framework import serializers
class User(object):
"""用户类"""
def __init__(self, name, age):
self.name = name
self.age = age
class UserSerializer(serializers.Serializer):
name = serializers.CharField()
age = serializers.IntegerField()
# 序列化基本使用
# if __name__ == '__main__':
# # 用户对象
# user = User(name="Monkey", age=18)
# res = UserSerializer(user)
# dict = res.data
# print(dict)
# 反序列化-基本使用-数据校验
if __name__ == '__main__':
# 假如现在客户端给服务器传递了两个参数:那name,age,利用这两个数据创建一个用户的对象,但是需要先进行数据校验
req_data = {
'name':"Moneky",
# "age":24
}
# 反序列化-数据校验
serializer = UserSerializer(data=req_data)
res = serializer.is_valid()
print(res)
# 获取校验出错的信息
print(serializer.errors)
# 获取校验之后的数据
print(serializer.validated_data)
字段类型&选项参数说明
在定义序列化器类的字段时,write_only和read_only默认值为False,说明这个字段既在序列化时使用,也在反序列化时使用。
通用选项参数:
write_only: 设置为True,该字段只在序列化时使用,反序列化操作时不使用
read_only: 设置为True,该字段只在序列化时使用,反序列化时不使用
default:设置序列化和反序列化时所使用的默认值
requird:默认值是True,指明在进行反序化时此字段是否必须传入
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器
error_messages 包含错误编号与错误信息的字典
label 用于HTML展示API页面时,显示的字段名称
help_text 用于HTML展示API页面时,显示的字段帮助提示信息
序列化操作-序列化单个对象和多个对象
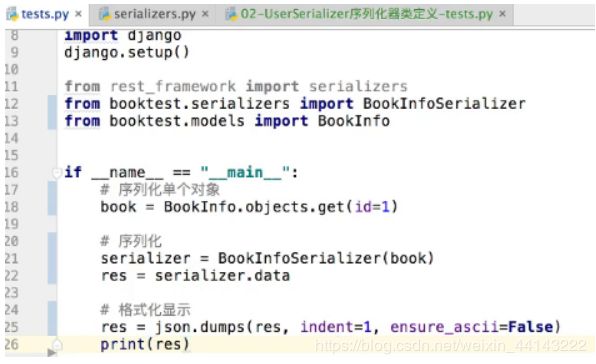
序列化单个对象:
book = BookInfoSerializer(id=1)
serializer = BookInfoSerializer(book)
serializer.data
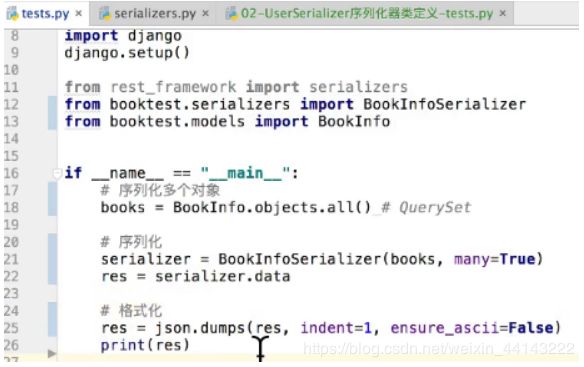
序列化多个对象:
books = BookInfo.objects.all() # QuerySet
serializer = BookInfoSerializer(books, many=True)
serializer.data
序列化单个对象:
序列化多个对象:
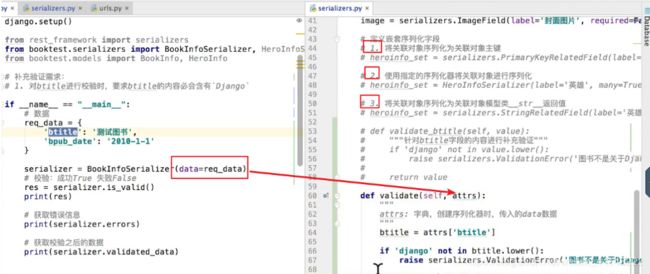
序列化操作-关联对象嵌套序列化
hero = HeroInfo.objects.get(id=1)
# 获取和英雄关联图书对象
hero.hbook
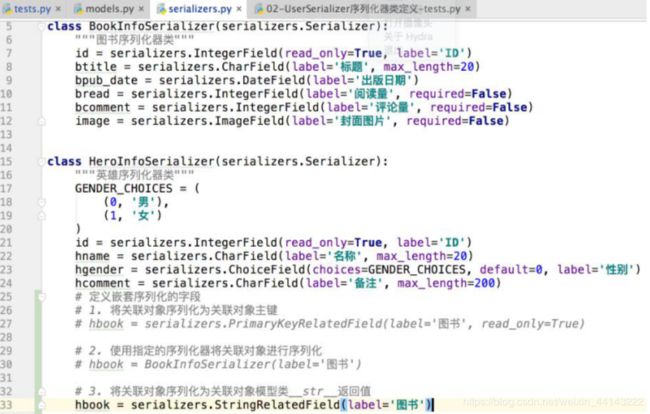
# 1. 将关联对象序列化为关联对象主键 PrimaryKeyRelatedField
{
"id": 1,
"hname": "孙悟空",
"hgender": 0,
"hcomment": "七十二变",
"hbook": ""
}
# 2. 使用指定的序列化器将关联对象进行序列化
{
"id": 1,
"hname": "孙悟空",
"hgender": 0,
"hcomment": "七十二变",
"hbook": {
"id": "图书id",
"btitle": "图书标题",
"bpub_date": "出版日期",
"bread": "阅读量",
"bcomment": "评论量",
"image": "封面图片"
}
}
# 3. 将关联对象序列化为关联对象模型类__str__返回值 StringRelatedField
{
"id": 1,
"hname": "孙悟空",
"hgender": 0,
"hcomment": "七十二变",
"hbook": "<图书名称>"
}
# 注意:如果和对象关联的对象有多个,在定义嵌套序列化的字段时,需要指明many=True
book = BookInfo.objects.get(id=1)
# 获取和book对象关联英雄数据
book.heroinfo_set.all()
{
"id": 1,
"btitle": "西游记-2",
"bpub_date": "1998-10-10",
"bread": 10,
"bcomment": 0,
"image": null,
"heroinfo_set": [
'<英雄id>',
...
]
}
{
"id": 1,
"btitle": "西游记-2",
"bpub_date": "1998-10-10",
"bread": 10,
"bcomment": 0,
"image": null,
"heroinfo_set": [
{
'id': '<英雄id>',
'hname': '<英雄名称>',
'hgender': '<英雄性别>'
'hcomment': '<英雄备注>'
},
...
]
}
{
"id": 1,
"btitle": "西游记-2",
"bpub_date": "1998-10-10",
"bread": 10,
"bcomment": 0,
"image": null,
"heroinfo_set": [
'<英雄名称>',
...
]
}
反序列化操作
数据校验&补充验证
req_data = {
'btitle': '测试图书',
'bpub_date': '2010-1-1'
}
serializer = BookInfoSerializer(data=req_data)
# 校验
res = serializer.is_valid()
# 获取错误信息
serializer.errors
# 获取校验之后的数据
serializer.validated_data
补充验证3种方法:
1. 指定特定字段选项参数`validators`来指明补充验证函数
2. 在序列化器类中定义特定的方法`validate_<fieldname>`来针对特定字段进行补充验证
3. 定义validate方法进行补充验证:可以结合多个字段内容进行补充验证
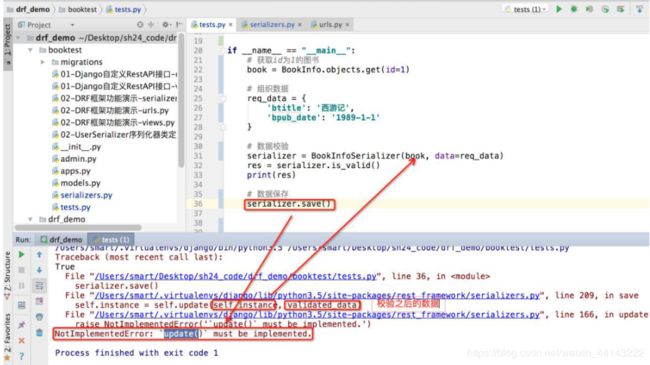
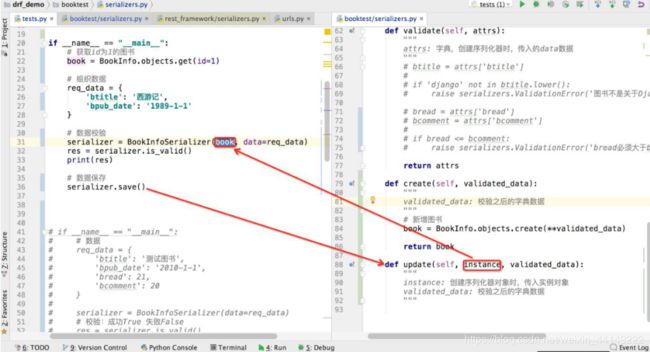
反序列化操作-数据保存(新增&更新)
# 注意:进行数据保存之前必须通过反序化数据验证
# 数据保存
serializer.save()
调用序列化器save方法时,save方法内部可能会调用序列化器类的create方法和update方法,我们可以在create方法中实现数据新增,在update方法中实现数据更新。
serializer = BookInfoSerializer(data=req_data)
serializer.is_valid()
serializer.save() # 调用序列化器类中的create
serializer = BookInfoSerializer(book, data=req_data)
serializer.is_valid()
serializer.save() # 调用序列化器类中的update
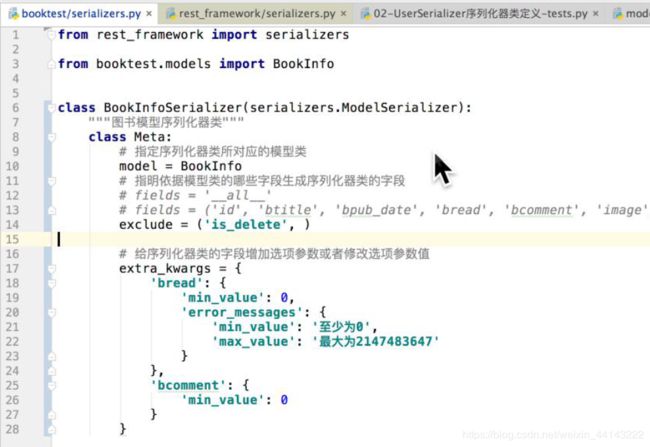
Serializer-ModelSerializer序列化器类的使用
from rest_framework import serializers
serializers.ModelSerializer:
是Serizalizer类的子类,在定义序列化器类时,如果序列化器类针对的是某个模型类,可以直接继承于ModelSerializer。
好处:
1.序列化器类字段可以依据模型类字段自动生成。
2.ModelSerializer里面已经实现create和update方法。
DRF类视图-APIView
APIView视图基类:
Django框架View类的子类,在View类的基础上封装了一些功能。
功能如下:
1. 视图request参数变成了Request类的对象,不再是Django原始HttpRequest类的对象;
request.data: 保存解析之后的请求体中数据,已经解析为了字典或类字典(QueryDict)。request.POST|request.body|request.FILES
request.query_params: 保存解析之后的查询字符串。request.GET
2. 响应时可以统一返回Response类的对象,DRF框架会根据客户端请求头的`Accept`将响应数据转换为对应数据格式进行返回,默认返回json,仅支持html或json;
`Accept: text/html`:将响应数据转换为html进行返回
`Accept: applicaiton/json`:将响应数据转换为json进行返回
return Response(响应数据)
3. 异常处理:如果视图出现了未处理的异常,DRF框架会对异常进行处理,并将处理的错误响应返回给客户端;
4. 认证&权限&限流
-
案例-继承APIView改写RestAPI接口
-
类视图-GenericAPIView视图基类的功能&使用
GenericAPIView视图基类: 继承自APIView,在APIView类的基础上封装了一些功能。 功能如下: 1. 封装了操作序列化器的属性和方法: 属性: serializer_class:指明视图所使用的序列化器类; 方法: get_serializer_class:获取视图所使用的序列化器类; get_serializer:创建一个视图所使用的序列化器类的对象; class 类视图(GenericAPIView): serializer_class = <序列化器类> 2. 封装了查询数据库的属性和方法: 属性: query_set:指明视图所使用的查询集 方法: get_queryset:获取视图所使用的查询集 get_object:从视图所使用的查询集中查询指定的对象(默认根据pk主键进行查询) class 类视图(GenericAPIView): queryset = <查询集> 3. 过滤&分页 -
类视图-GenericAPIView视图基类的源码说明
补充说明: 定义类视图之后,类视图对象有一个属性kwargs:是一个字典,保存从url地址中提取的所有命名参数; # /books/(?P\d+)/ class 类视图(View|APIView|GenericAPIView): def 方法(self): # self.kwargs['pk'] def get(self, request, pk): """ self.kwargs: 是一个字典,保存从url地址中提取的所有命名参数; """ pass -
类视图-Mixin扩展类的功能&使用
继承自GenericAPIView之后,使用GenericAPIView中提供的操作序列化器的函数和数据库查询的函数写出的代码变成了通用代码,这些通用代码抽取之后,就是DRF框架提供的5个Mixin扩展类。 Mixin扩展类: ListModelMixin:list,封装了获取一组数据通用流程。 CreateModelMixin:create,封装了新增一条数据通用流程。 RetrieveModelMixin:retrieve,封装了获取指定数据通用流程。 UpdateModelMixin:update,封装了更新指定数据通用流程。 DestroyModelMixin:destroy,封装了删除指定数据通用流程。 GenericAPIView通常配合Mixin扩展类进行使用。 -
类视图-子类视图类的功能&使用说明
9个子类视图类: 同时继承了GenericAPIView和对应Mixin扩展类,同时在子类视图中提供了对应的请求处理函数。 from rest_framework import generics class ListAPIView(ListModelMixin, GenericAPIView): def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) class CreateAPIView(CreateModelMixin, GenericAPIView): def post(self, request, *args, **kwargs): return self.create(request, *args, **kwargs) -
视图集-ViewSet视图集的功能&使用
视图集:将操作同一组资源的处理函数放在同一个类中,这个类就是视图集。 视图集和类视图的区别? 答:实现同一组接口时,如果使用类视图可能需要多个类视图,而使用视图集时只需要一个视图集。 比如:实现图书管理的5个接口时,使用类视图用了2个类视图:BookListVIew和BookDetailView,如果使用视图集只需要一个即可。 基本使用: 1. 继承自ViewSet(继承自ViewSetMixin和APIView) 2. 视图集中的处理函数不再以请求方式(比如:get,post等)命名,而是以对应的action操作命名,常见操作如下: list:获取一组数据 create:创建一条数据 retrieve:获取指定数据 update:修改指定数据 destroy:删除指定数据 3. 在urls.py进行url地址配置时需要明确指明某种请求方式请求某个地址对应的是视图集中的哪个处理函数。 -
视图集-视图集父类GenericViewSet使用
继承自ViewSetMixin和GenericAPIView,可以配合Mixin扩展类提供对应的处理函数 -
视图集-视图集父类ModelViewSet和ReadOnlyModelViewSet使用
ModelViewSet:继承了5个Mixin扩展类,同时继承了GenericViewSet ReadOnlyModelViewSet:继承了ListModelMixin, RetireveModelMixin,同时继承了GenericViewSet 需求: 写一个视图集,提供一下2个API接口: 1. 获取所有的图书 GET /books/ -> list 2. 获取指定的图书 GET /books/(?P\d+)/ -> retrieve class BookInfoViewSet(ReadOnlyModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoSerializer 1)ModelSerializer
Serializer和ModelSerializer区别?
答:ModelSerializer是Serializer类子类,如果序列化器类针对是某个模型类时,可以直接继承于ModelSerializer。
好处:
1. 字段自动生成
2. create和update已经实现
2)APIView视图基类
APIView和View区别?
答:APIView是View子类。
功能:
-
request请求对象->Request
request.data:保存解析之后的请求体数据。
request.query_params:保存解析之后的查询字符串数据。
2. 响应对象:返回Responsereturn Response(响应数据)
3. 异常处理 4. 认证&权限&限流3)GenericAPIView视图基类
GenericAPIView和APIView区别?
答:GenericAPIView是APIView类的子类,在APIView基础上封装操作序列化器和数据库查询的相关属性和方法。
序列化操作:
属性:serializer_class
方法:
get_serializer_class
get_serializer
数据库操作:
属性:queryset
方法:
get_queryset
get_object
4)5个Mixin扩展类
Mixin扩展类需要配合GenericAPIView进行使用
ListModelMixin
CreateModelMixin
RetrieveModelMixin
UpdateModelMixin
DestroyModelMixin
5)9个子类视图类
继承GenericAPIVIew和对应的Mixin扩展,而且提供了对应的请求处理方法。
6)视图集
类视图和视图集区别?
答:实现同一组接口时,如果使用类视图可能需要多个类视图,而使用视图集时只需要一个视图集。
# 需求1:写一个类视图,提供以下1个接口
1. 获取所有的图书数据 get /books/
# 1. APIView
class BookListView(APIView):
def get(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
# 2. GenericAPIView
class BookListView(GenericAPIView):
# 指定视图所使用的序列化器类
serializer_class = BookInfoSerializer
# 指定视图所使用的查询集
queryset = BookInfo.objects.all()
def get(self, request):
qs = self.get_queryset()
serializer = self.get_serializer(qs, many=True)
return Response(serializer.data)
# 3. Mixin扩展类
class ListModelMixin(object):
def list(self, request, *args, **kwargs):
qs = self.get_queryset()
serializer = self.get_serializer(qs, many=True)
return Response(serializer.data)
class BookListView(ListModelMixin, GenericAPIView):
# 指定视图所使用的序列化器类
serializer_class = BookInfoSerializer
# 指定视图所使用的查询集
queryset = BookInfo.objects.all()
def get(self, request):
return self.list(request)
# 4. 子类视图:ListAPIView
class ListAPIView(ListModelMixin, GenericAPIView):
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwrags)
class BookListView(ListAPIView):
# 指定视图所使用的序列化器类
serializer_class = BookInfoSerializer
# 指定视图所使用的查询集
queryset = BookInfo.objects.all()
# 需求2:写一个类视图,提供以下2个接口
1. 获取指定的图书数据 get /books/(?P<pk>\d+)/
2. 修改指定的图书数据 put /books/(?P<pk>\d+)/
# 1. APIView
class BookDetailView(APIView):
def get(self, request, pk):
try:
book = BookInfo.objects.get(pk=pk)
except BookInfo.DoesNotExist:
raise Http404
serializer = BookInfoSerializer(book)
return Response(serializer.data)
def put(self, request, pk):
try:
book = BookInfo.objects.get(pk=pk)
except BookInfo.DoesNotExist:
raise Http404
# 反序列化-数据校验
serializer = BookInfoSerializer(book, data=request.data)
serializer.is_valid(raise_exception=True)
# 反序列化-数据保存(update)
serializer.save()
return Response(serializer.data)
# 2. GenericAPIView
class BookDetailView(GenericAPIView):
serializer_class = BookInfoSerializer
queryset = BookInfo.objects.all()
def get(self, request, pk):
book = self.get_object()
serializer = self.get_serializer(book)
return Response(serializer.data)
def put(self, request, pk):
book = self.get_object()
# 反序列化-数据校验
serializer = self.get_serializer(book, data=request.data)
serializer.is_valid(raise_exception=True)
# 反序列化-数据保存(update)
serializer.save()
return Response(serializer.data)
# 3. Mixin扩展类
class BookDetailView(RetrieveModelMixin, UpdateModelMixin, GenericAPIView):
serializer_class = BookInfoSerializer
queryset = BookInfo.objects.all()
def get(self, request, pk):
return self.retrieve(request, pk)
def put(self, request, pk):
return self.update(request, pk)
# 4. 子类视图:RetrieveUpdateAPIView
class BookDetailView(RetrieveUpdateAPIView):
serializer_class = BookInfoSerializer
queryset = BookInfo.objects.all()
APIView->GenericAPIView->Mixin扩展类->子类视图
视图集中添加额外的action处理方法
注意:命名不要冲突
需求:在BookInfoViewSet视图集中再添加2个API
1.获取id最新的图书信息
2.修改指定图书的阅读量
视图集对象action属性的作用与应用说明
视图集对象.action:获取所有执行的操作
应用场景:
视图集中多个API接口中使用的序列化器类和查询集不一样。
可以重写get_serializer_class和get_queryset,根据不同的操作返回不同的序列化器和查询集。
路由Router
路由Router-路由Router的作用和使用
作用:动态生成视图集中处理函数的url配置项。
使用:
1. 创建Router类的对象
from rest_framework.routers import SimpleRouter, DefaultRouter
router = SimpleRouter()
2. 注册视图集
router.register(, , )
例如:router.register('books', views.BookInfoViewSet, base_name='books')
3. 将动态生成的配置项列表添加到urlpatterns中
urlpatterns += router.urls
视图集中额外添加处理函数配置项生成
需要给额外添加处理函数添加action装饰器:
from rest_framework.decorators import action
# detail指明生成配置项时,是否需要从地址提取参数,需要True,不需要就是False
@action(methods=['<请求方式>'], detail=False|True):
def <额外处理函数>(...):
...
SimpleRouter路由生成的规则说明
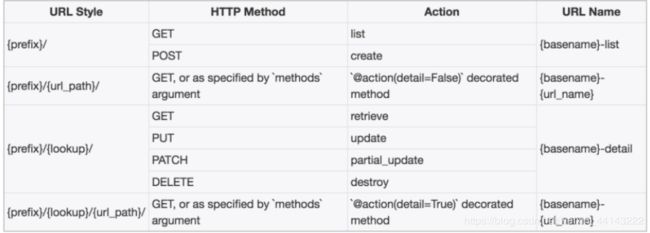
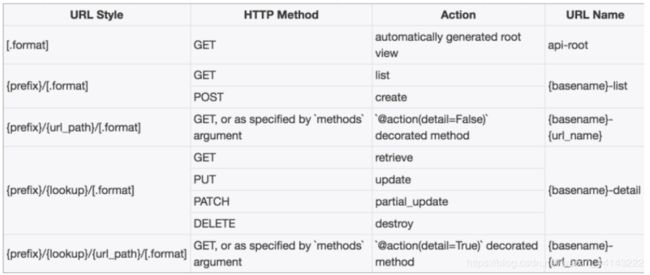
DefaultRouter的使用和说明
DRF框架其他功能
-
-认证&权限
认证:判断访问的用户是谁? 默认全局认证方式:session认证和基本认证 修改全局认证方式 修改指定视图认证方式 权限:判断访问的用户是否能够访问某个API接口? 默认全局权限控制:AllowAny 修改全局权限控制 修改指定视图权限控制 -
DRF框架其他功能-自定义权限控制类
如需自定义权限,需继承rest_framework.permissions.BasePermission父类,并实现以下两个任何一个方法或全部
-
.has_permission(self, request, view)是否可以访问视图, view表示当前视图对象
-
.has_object_permission(self, request, view, obj)是否可以访问数据对象, view表示当前视图, obj为数据对象
例如:
class MyPermission(BasePermission): def has_permission(self, request, view): """判断对使用此权限类的视图是否有访问权限""" # 任何用户对使用此权限类的视图都没有访问权限 return True def has_object_permission(self, request, view, obj): """判断对使用此权限类视图某个数据对象是否有访问权限""" # 需求: 对id为1,3的数据对象有访问权限 if obj.id in (1, 3): return True return False class BookInfoViewSet(ReadOnlyModelViewSet): # 指定当前视图所使用的查询集 queryset = BookInfo.objects.all() # 指定当前视图所使用的序列化器类 serializer_class = BookInfoSerializer # 指定当前视图所使用的认证类 authentication_classes = [SessionAuthentication] # 使用自定义的权限控制类 permission_classes = [MyPermission] -
-
DRF框架其他功能-限流
限流:控制用户访问API接口频次。 DRF框架默认没有进行限流设置。 进行权限限流设置: 1. 针对匿名用户和认证用户分别进行限流 2. 针对匿名用户和认证用户统一进行限流 -
DRF框架其他功能-过滤&排序
需求:
写一个类视图,提供一个API接口
1. 获取所有的图书 GET /books/
5.DRF框架其他功能-分页&自定义分页
1) PageNumberPagination
前端访问网址形式:
GET http://api.example.org/books/?page=4
可以在子类中定义的属性:
- page_size 每页数目
- page_query_param 前端发送的页数关键字名,默认为"page"
- page_size_query_param 前端发送的每页数目关键字名,默认为None
- max_page_size 前端最多能设置的每页数量
2)LimitOffsetPagination
前端访问网址形式:
GET http://api.example.org/books/?limit=100&offset=400
可以在子类中定义的属性:
- default_limit 默认限制,默认值与
PAGE_SIZE设置一直 - limit_query_param limit参数名,默认’limit’
- offset_query_param offset参数名,默认’offset’
- max_limit 最大limit限制,默认None
注意:如果在视图内关闭分页功能,只需在视图内设置
pagination_class = None
自定义分页类
也可通过自定义Pagination类,来为视图添加不同分页行为。在视图中通过pagination_clas属性来指明。
class StandardResultPagination(PageNumberPagination):
page_size = 3
page_size_query_param = 'page_size'
max_page_size = 5
class BookListView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
# 指定当前视图所使用的分页类
pagination_class = StandardResultPagination
通过 http://api.example.org/books/?page=<页码>&page_size=<页容量> 进行访问。
-
DRF框架其他功能-异常处理
自定义DRF框架异常处理: 1. 自定义异常处理函数 2. 修改EXCEPTION_HANDLER配置项 -
DRF框架其他功能-自动生成接口文档