实战篇之——利用【Python+Tensorflow】搭建ResNet,实现对Cifar10数据集的分类
利用【Python+Tensorflow】搭建ResNet,实现对Cifar10数据集的分类
具体数据集介绍及下载地址:https://blog.csdn.net/weixin_44402973/article/details/96028312
2015年微软亚洲研究院何凯明团队提出了ResNet,在网络结构上使用了跳连来防止梯度消失,一定程度上加深网络层数。引入跳连,可以一定程度也解决网络深度加深,网络难优化问题。
RestNet中提出了残差连接,解释为:
假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个y=x的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。假定某段神经网络的输入是x,期望输出是H(x),如果我们直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x) = H(x) - x。如图所示,这就是一个ResNet的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差,如图1。
- ResNet使用了一种连接方式叫做“shortcut connection”,也是论文中提到identity mapping,如下图1:
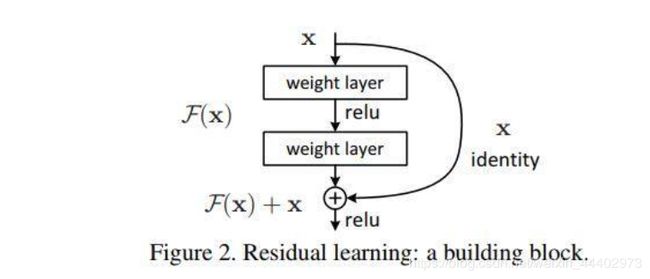
图1. Shortcut Connection
- 残差结构的两种设计,如下图2:

图2. 残差结构
由上图可知,实现残差块【上述残差结构】,可以使用上面两种结构:building block(左)和bottleneck block(右)。
A bottleneck building block提出为了目的是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积进行恢复,整体上用的参数数目:1*1*256*64+3*3*64*64+1*1*64*256 = 69632,如果不使用bottleneck结构的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,两者之间参数量相差了将近17倍。
A “bottleneck building” block提出为了目的是为了降低计算量,考虑两种结构的输入和输出feature map大小为M*N相等,使用bottleneck结构计算量为:M*N*1*1*256*64+M*N*3*3*64*64+M*N*1*1*64*256=69632*M*N;使用building block结构计算量为:M*N*3*3*256*256*2=1179648*M*N,可以得出使用“building block”计算量大致减少了16.94倍。
RestNet网络结构(来自论文)

图3.网络结构图
本次代码实现
1.文件组织形式:

2.本次代码文件res_net.py中实现了building block结构残差卷积网络:
# coding: utf-8
import tensorflow as tf
import os
import pickle
import numpy as np
CIFAR_DIR = "./cifar-10-batches-py"
print(os.listdir(CIFAR_DIR))
def load_data(filename):
"""read data from data file."""
with open(filename, 'rb') as f:
data = pickle.load(f, encoding='latin1')
return data['data'], data['labels']
class CifarData:
def __init__(self, filenames, need_shuffle):
all_data = []
all_labels = []
for filename in filenames:
data, labels = load_data(filename)
all_data.append(data)
all_labels.append(labels)
self._data = np.vstack(all_data)
self._data = self._data / 127.5 - 1
self._labels = np.hstack(all_labels)
print(self._data.shape)
print(self._labels.shape)
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
# [0,1,2,3,4,5] -> [5,3,2,4,0,1]
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
def size(self):
"""获取数据总量"""
return self._num_examples
def next_batch(self, batch_size):
"""return batch_size examples as a batch."""
if batch_size > self._num_examples:
raise Exception("batch size is larger than all examples")
end_indicator = self._indicator + batch_size
if self._indicator < self._num_examples-1 and end_indicator >self._num_examples:
end_indicator = self._num_examples
elif self._indicator >= self._num_examples-1:
self._indicator = 0
end_indicator = batch_size
batch_data = self._data[self._indicator: end_indicator]
batch_labels = self._labels[self._indicator: end_indicator]
self._indicator = end_indicator
return batch_data, batch_labels
def residual_block(x, output_channel):
"""
desc:定义残差块,每经过一个残差块图像大小减少一半,并且通道数加倍
Args:
@param x:残差块的输入
@param output_channel:输出通道数
"""
input_channel = x.get_shape().as_list()[-1]
if input_channel * 2 == output_channel:
increase_dim = True
strides = (2, 2)
elif input_channel == output_channel:
increase_dim = False
strides = (1, 1)
else:
raise Exception("input channel can't match output channel")
conv1 = tf.layers.conv2d(x,
output_channel,
(3,3),
strides = strides,
padding = 'same',
activation = tf.nn.relu,
name = 'conv1')
conv2 = tf.layers.conv2d(conv1,
output_channel,
(3, 3),
strides = (1, 1),
padding = 'same',
activation = None,
name = 'conv2')
if increase_dim:
# 由于输入和输出feature map不一致,对输入进行均值池化
pooled_x = tf.layers.average_pooling2d(x,
(2, 2),
(2, 2),
padding = 'valid')
# 对通道维度进行填充
padded_x = tf.pad(pooled_x,
[[0,0],
[0,0],
[0,0],
[input_channel // 2, input_channel // 2]])
else:
padded_x = x
output_x = tf.nn.relu(conv2 + padded_x)
return output_x
def res_net(num_residual_blocks, num_filter_base,class_num):
"""
定义带有残差块的网络结构模型
Args:
@param num_residual_blocks: eg: [3, 4, 6, 3]
@param num_filter_base:开始对原图像进行卷积操作中卷积核个数
@param class_num:类别数
"""
x = tf.placeholder(tf.float32, [None,3072])
y = tf.placeholder(tf.int64, [None])
# [None], eg: [0,5,6,3]
x_image = tf.reshape(x, [-1, 3, 32, 32])
# 32*32
x_new = tf.transpose(x_image, perm=[0, 2, 3, 1])
num_subsampling = len(num_residual_blocks)
layers = []
# x: [None, width, height, channel] -> [width, height, channel]
input_size = x_new.get_shape().as_list()[1:]
with tf.variable_scope('conv0'):
conv0 = tf.layers.conv2d(x_new,
num_filter_base,
(3, 3),
strides = (1, 1),
padding = 'same',
activation = tf.nn.relu,
name = 'conv0')
layers.append(conv0)
# eg:num_subsampling = 4, sample_id = [0,1,2,3]
for sample_id in range(num_subsampling):
for i in range(num_residual_blocks[sample_id]):
with tf.variable_scope("conv%d_%d" % (sample_id, i)):
conv = residual_block(
layers[-1],
num_filter_base * (2 ** sample_id))
layers.append(conv)
# 计算feature map下采样多少
multiplier = 2 ** (num_subsampling - 1)
# 判断经过残差层之后,维度是否正确
assert layers[-1].get_shape().as_list()[1:] == [input_size[0] / multiplier,
input_size[1] / multiplier,
num_filter_base * multiplier]
with tf.variable_scope('fc'):
# layer[-1].shape : [None, width, height, channel]
# kernal_size: image_width, image_height
global_pool = tf.reduce_mean(layers[-1], [1,2])
logits = tf.layers.dense(global_pool, class_num)
layers.append(logits)
y_ = layers[-1]
loss = tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)\
# indices
predict = tf.argmax(y_, 1)
# [1,0,1,1,1,0,0,0]
correct_prediction = tf.equal(predict, y)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
with tf.name_scope('train_op'):
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
return x,y,accuracy,loss,train_op
batch_size = 32
#训练轮数
num_epoch = 10
train_filenames = [os.path.join(CIFAR_DIR, 'data_batch_%d' % i) for i in range(1, 6)]
test_filenames = [os.path.join(CIFAR_DIR, 'test_batch')]
x,y,accuracy,loss,train_op = res_net([2,3,2], 32, 10)
best_test_acc = 0
with tf.Session() as sess:
init = tf.global_variables_initializer().run()
iters = 0
for epoch in range(num_epoch):
train_data = CifarData(train_filenames, True)
train_size = train_data.size()
# 获取每个epoch中batch个数
batch_num = np.ceil(train_size / batch_size)
for i in range(int(batch_num)):
batch_data, batch_labels = train_data.next_batch(batch_size)
loss_val, acc_val, _ = sess.run([loss, accuracy, train_op],feed_dict={x: batch_data,y: batch_labels})
if iters % 1000 == 0 and iters != 0:
print('Epoch:%d, [Train] Step: %d, [Train] loss: %4.5f, [Train] acc: %4.5f' % (epoch,iters, loss_val, acc_val))
iters += 1
# 每个epoch之后对数据评估
test_data = CifarData(test_filenames, False)
test_size = test_data.size()
test_all_acc = []
test_all_loss = []
test_batch_num = np.ceil(test_size / batch_size)
for j in range(int(test_batch_num)):
test_batch_data, test_batch_labels = test_data.next_batch(batch_size)
test_acc,test_loss= sess.run([accuracy,loss],feed_dict = {x:test_batch_data, y: test_batch_labels})
test_all_acc.append(test_acc)
test_all_loss.append(test_loss)
if best_test_acc < np.mean(test_all_acc):
best_test_acc = np.mean(test_all_acc)
print('[Test] loss: %4.5f, [Test] acc: %4.5f Flag:*' % (np.mean(test_all_loss), np.mean(test_all_acc)))
else:
print('[Test] loss: %4.5f, [Test] acc: %4.5f Flag:-' % (np.mean(test_all_loss), np.mean(test_all_acc)))
结果展示:
