Python-鸢尾花数据集/月亮数据集的线性LDA、k-means和SVM算法二分类可视化分析
本博客是Jupyter Notebook的python3环境下运行的。
具体内容是对鸢尾花数据集和月亮数据集,分别采用线性LDA、k-means和SVM算法进行二分类可视化分析。简述SVM算法的优点。
目录
- 线性判别分析LDA
- 鸢尾花数据集
- 月亮数据集
- SVM(支持向量机)算法
- 支持向量机(SVM)的优点
- 鸢尾花数据集
- 月亮数据集
- k-means聚类分析
- 鸢尾花数据集
- 月亮数据集
线性判别分析LDA
LDA是一种有监督的数据降维方法。LDA在进行数据降维的时候是利用数据的类别标签提供的信息的。
将带有标签的数据降维,投影到低维空间同时满足三个条件:
1、尽可能多地保留数据样本的信息(即选择最大的特征是对应的特征向量所代表的的方向)。
2、寻找使样本尽可能好分的最佳投影方向。
3、投影后使得同类样本尽可能近,不同类样本尽可能远。
鸢尾花数据集
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_classification
class LDA():
def Train(self, X, y):
# X为训练数据集,y为训练label
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
# 求中心点
mju1 = np.mean(X1, axis=0) # mju1是ndrray类型
mju2 = np.mean(X2, axis=0)
# dot(a, b, out=None) 计算矩阵乘法
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2 = np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
# 计算w
w = np.dot(np.mat(Sw).I, (mju1 - mju2).reshape((len(mju1), 1)))
# 记录训练结果
self.mju1 = mju1 # 第1类的分类中心
self.cov1 = cov1
self.mju2 = mju2 # 第2类的分类中心
self.cov2 = cov2
self.Sw = Sw # 类内散度矩阵
self.w = w # 判别权重矩阵
def Test(self, X, y):
"""X为测试数据集,y为测试label"""
# 分类结果
y_new = np.dot((X), self.w)
# 计算fisher线性判别式
nums = len(y)
c1 = np.dot((self.mju1 - self.mju2).reshape(1, (len(self.mju1))), np.mat(self.Sw).I)
c2 = np.dot(c1, (self.mju1 + self.mju2).reshape((len(self.mju1), 1)))
c = 1/2 * c2 # 2个分类的中心
h = y_new - c
# 判别
y_hat = []
for i in range(nums):
if h[i] >= 0:
y_hat.append(0)
else:
y_hat.append(1)
# 计算分类精度
count = 0
for i in range(nums):
if y_hat[i] == y[i]:
count += 1
precise = count / nums
# 显示信息
print("测试样本数量:", nums)
print("预测正确样本的数量:", count)
print("测试准确度:", precise)
return precise
if '__main__' == __name__:
# 产生分类数据
n_samples = 500
X, y = make_classification(n_samples=n_samples, n_features=2, n_redundant=0, n_classes=2,n_informative=1, n_clusters_per_class=1, class_sep=0.5, random_state=10)
# LDA线性判别分析(二分类)
lda = LDA()
# 60% 用作训练,40%用作测试
Xtrain = X[:299, :]
Ytrain = y[:299]
Xtest = X[300:, :]
Ytest = y[300:]
lda.Train(Xtrain, Ytrain)
precise = lda.Test(Xtest, Ytest)
# 原始数据
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.xlabel("x1")
plt.ylabel("x2")
plt.title("Test precise:" + str(precise))
plt.show()
运行结果如下所示:

月亮数据集
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
class LDA():
def Train(self, X, y):
# X为训练数据集,y为训练label
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
# 求中心点
mju1 = np.mean(X1, axis=0) # mju1是ndrray类型
mju2 = np.mean(X2, axis=0)
# dot(a, b, out=None) 计算矩阵乘法
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2 = np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
# 计算w
w = np.dot(np.mat(Sw).I, (mju1 - mju2).reshape((len(mju1), 1)))
# 记录训练结果
self.mju1 = mju1 # 第1类的分类中心
self.cov1 = cov1
self.mju2 = mju2 # 第1类的分类中心
self.cov2 = cov2
self.Sw = Sw # 类内散度矩阵
self.w = w # 判别权重矩阵
def Test(self, X, y): #X为测试数据集,y为测试label
# 分类结果
y_new = np.dot((X), self.w)
# 计算fisher线性判别式
nums = len(y)
c1 = np.dot((self.mju1 - self.mju2).reshape(1, (len(self.mju1))), np.mat(self.Sw).I)
c2 = np.dot(c1, (self.mju1 + self.mju2).reshape((len(self.mju1), 1)))
c = 1/2 * c2 # 2个分类的中心
h = y_new - c
# 判别
y_hat = []
for i in range(nums):
if h[i] >= 0:
y_hat.append(0)
else:
y_hat.append(1)
# 计算分类精度
count = 0
for i in range(nums):
if y_hat[i] == y[i]:
count += 1
precise = count / (nums+0.000001)
# 显示信息
print("测试样本数量:", nums)
print("预测正确样本的数量:", count)
print("测试准确度:", precise)
return precise
if '__main__' == __name__:
# 产生分类数据
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
# LDA线性判别分析(二分类)
lda = LDA()
# 60% 用作训练,40%用作测试
Xtrain = X[:60, :]
Ytrain = y[:60]
Xtest = X[40:, :]
Ytest = y[40:]
lda.Train(Xtrain, Ytrain)
precise = lda.Test(Xtest, Ytest)
# 原始数据
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.xlabel("x1")
plt.ylabel("x2")
plt.title("Test precise:" + str(precise))
plt.show()
运行结果如下:
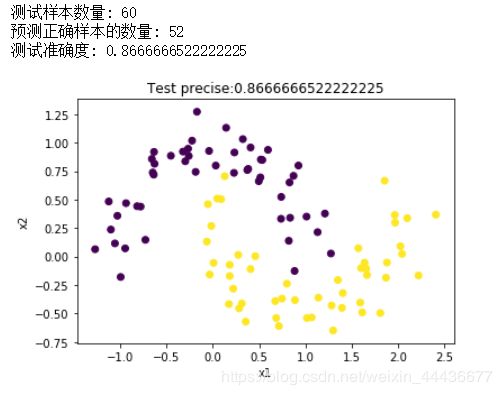
SVM(支持向量机)算法
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
支持向量机(SVM)的优点
SVM学习问题可以表示为凸优化问题,可利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
SVM是基于小样本统计理论的基础上的,这符合机器学习的目的。而且支持向量机比神经网络具有较好的泛化推广能力。
SVM使用非线性分类器具有较大的优势,而逻辑模式以及决策树模式都是使用了直线方法。
SVM理论提供了一种避开高维空间的复杂性,直接用此空间的内积函数(即核函数),再利用在线性可分的情况下的求解方法直接求解对应的高维空间的决策问题。当核函数已知,可以简化高维空间问题的求解难度。
鸢尾花数据集
代码如下:
from sklearn.svm import SVC
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # 花瓣长度与花瓣宽度 petal length, petal width
y = iris["target"]
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
# SVM Classifier model
svm_clf = SVC(kernel="linear", C=float("inf"))
svm_clf.fit(X, y)
def plot_svc_decision_boundary(svm_clf, xmin, xmax):
# 获取决策边界的w和b
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
# At the decision boundary, w0*x0 + w1*x1 + b = 0
# => x1 = -w0/w1 * x0 - b/w1
x0 = np.linspace(xmin, xmax, 200)
# 画中间的粗线
decision_boundary = -w[0]/w[1] * x0 - b/w[1]
# 计算间隔
margin = 1/w[1]
gutter_up = decision_boundary + margin
gutter_down = decision_boundary - margin
# 获取支持向量
svs = svm_clf.support_vectors_
plt.scatter(svs[:, 0], svs[:, 1], s=180, facecolors='#FFAAAA')
plt.plot(x0, decision_boundary, "k-", linewidth=2)
plt.plot(x0, gutter_up, "k--", linewidth=2)
plt.plot(x0, gutter_down, "k--", linewidth=2)
plt.title("大间隔分类", fontsize=16)
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plot_svc_decision_boundary(svm_clf, 0, 5.5)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.show()
运行结果如下:
实线代表SVM分类器的决策边界,这条线不仅分离了两个类别,并且尽可能远离了最近的训练实例。我们可以将SVM分类器视为在类别之间拟合可能的最宽的街道,平行的虚线所示。

月亮数据集
代码如下:
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
import numpy as np
import matplotlib as mpl
from sklearn.datasets import make_moons
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
# 为了显示中文
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "g^")
plt.axis(axes)
plt.grid(True, which='both')
plt.xlabel(r"$x_1$", fontsize=20)
plt.ylabel(r"$x_2$", fontsize=20, rotation=0)
plt.title("月亮数据",fontsize=20)
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
运行结果如下:

代码如下:
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline([
# 将源数据 映射到 3阶多项式
("poly_features", PolynomialFeatures(degree=3)),
# 标准化
("scaler", StandardScaler()),
# SVC线性分类器
("svm_clf", LinearSVC(C=10, loss="hinge", random_state=42))
])
polynomial_svm_clf.fit(X, y)
运行结果如下:
Pipeline(memory=None,
steps=[(‘poly_features’,
PolynomialFeatures(degree=3, include_bias=True,
interaction_only=False, order=‘C’)),
(‘scaler’,
StandardScaler(copy=True, with_mean=True, with_std=True)),
(‘svm_clf’,
LinearSVC(C=10, class_weight=None, dual=True,
fit_intercept=True, intercept_scaling=1,
loss=‘hinge’, max_iter=1000, multi_class=‘ovr’,
penalty=‘l2’, random_state=42, tol=0.0001,
verbose=0))],
verbose=False)
代码如下:
def plot_predictions(clf, axes):
# 打表
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
y_decision = clf.decision_function(X).reshape(x0.shape)
# print(y_pred)
# print(y_decision)
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1)
plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
运行结果如下:

代码如下:
from sklearn.svm import SVC
gamma1, gamma2 = 0.1, 5
C1, C2 = 0.001, 1000
hyperparams = (gamma1, C1), (gamma1, C2)
svm_clfs = []
for gamma, C in hyperparams:
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=gamma, C=C))
])
rbf_kernel_svm_clf.fit(X, y)
svm_clfs.append(rbf_kernel_svm_clf)
plt.figure(figsize=(11, 7))
for i, svm_clf in enumerate(svm_clfs):
plt.subplot(221 + i)
plot_predictions(svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
gamma, C = hyperparams[i]
plt.title(r"$\gamma = {}, C = {}$".format(gamma, C), fontsize=16)
plt.tight_layout()
plt.show()
运行结果如下:

k-means聚类分析
聚类算法是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法,这个方法要保证同一类的数据有相似的特征。
根据样本之间的距离或者说是相似性(亲疏性),把越相似、差异越小的样本聚成一类(簇),最后形成多个簇,使同一个簇内部的样本相似度高,不同簇之间差异性高。
鸢尾花数据集
代码如下:
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
#加载数据集
lris_df = datasets.load_iris()
#print(lris_df)
#挑选第2列,花瓣的长度
x_axis = lris_df.data[:,2]
#print(x_axis)
#挑选第三列,花瓣的宽度
y_axis = lris_df.data[:,3]
#print(y_axis)
#这里已经知道了分2类,其他分类这里的参数需要调试
model = KMeans(n_clusters=2)
#训练模型
model.fit(lris_df.data)
prddicted_label= model.predict([[6.3, 3.3, 6, 2.5]])
all_predictions = model.predict(lris_df.data)
#plt.plot(a, b, "bs")
plt.xlabel('花瓣的长度')
plt.ylabel('花瓣的宽度')
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
#打印出来对150条数据的聚类散点图
plt.scatter(x_axis, y_axis, c=all_predictions)
plt.show()
运行结果如下:

月亮数据集
代码如下:
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
#X是一个100X2维度的,分别选取两列的数据
X1=X[:,0]
X2=X[:,1]
#这里已经知道了分2类,其他分类这里的参数需要调试
model = KMeans(n_clusters=2)
#训练模型
model.fit(X)
#print(z[50])
#选取行标为50的那条数据,进行预测
prddicted_label= model.predict([[-0.22452786,1.01733299]])
#预测全部100条数据
all_predictions = model.predict(X)
#plt.plot(a, b, "bs")
#打印聚类散点图
plt.scatter(X1, X2, c=all_predictions)
plt.show()
运行结果如下:
