词汇表征 word representation
在上一周我们提到了通常的一个词汇表征的方法是通过建立一个包含全部独立单词的词汇表,对于其中的每一个单词在对应的索引位置上建立 One-hot 编码。例如如果词汇表的长度是 10,000,那么对于索引位置为 9527 的一个单词,其编码后的向量为一个长度为 10,000,索引位置 9527 处为 1 其他位置全 0 的向量,这里也可以知道对于词汇表进行 One-hot 编码的到的也是一个大型的稀疏矩阵。
这一编码方式的一个重要的缺点是它无法有效的对于学到的知识进行泛化,例如如果通过训练使得网络了解到 orange juice 这两个词同时出现概率非常高,仍然无法有效的使的 apple juice 也获得同样类似的知识,其中的一个原因就是任意两个 one-hot 编码向量的内积为 0。
另一种表征方式就是通过学习使得网络对于词汇基于属性或特征进行表征,与在 CNN 中网络所提取的特征变得十分抽象类似,在实际情形中 RNN 学习到的特征不一定直观的等同于我们日常对于词汇属性的归类方式,但这不妨碍其可以通过这种方式准确的将知识进行泛化。
Embeddings are important for input to machine learning. Classifiers, and neural networks more generally, work on vectors of real numbers. They train best on dense vectors, where all values contribute to define an object. However, many important inputs to machine learning, such as words of text, do not have a natural vector representation. Embedding functions are the standard and effective way to transform such discrete input objects into useful continuous vectors.
例如在下图中网络对于 apple 和 orange 进行特征表征时,二者很多类似属性部分就会出现相近的概率值。

在网络通过学习对于词汇进行表征时,也可以通过一定的方式来将这些表征可视化,其中一个重要的可视化方式就是 t-sne embeddings,这种方法可以将高维的分类投影在二维平面,并且会保留类似词汇的临近状态。
word embeddings
在课程中 Andrew 讲到 word embeddings 一词,我一直找不到合适的翻译方式。其核心是通过一定的方法将词汇向量化的过程,理解这个概念的更好的方式是将其与 One-hot enconding 对比:
在 One-hot encoding 中,向量的维数和词汇表的长度相同,并且每一个单词被任意的赋予一个索引位置,这使得不同的词汇之间没有任何的相似性和关联性,表征词汇的矩阵是稀疏的
word embedding 想要实现的是构建以特征为基础的,参数密集的低维的向量来对词汇进行表征,并且具有相同语义的词汇的向量之间具有较大的相似性
Word embeddings are a type of (vectorized) word representation that allows words with similar meaning to have a similar representation ... Each word is represented by a real-valued vector, often tens or hundreds of dimensions. This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding ... The distributed representation is learned based on the usage of words. This allows words that are used in similar ways to result in having similar representations, naturally capturing their meaning. - Jason Brownlee
在我看来这个概念和 CNN 中的 bottleneck features 类似,word embeddings 是通过借用巨大的语料库训练得到的特征来对词汇进行向量化的标记,并且一旦通过大量的语料库完成标记,在实际应用中可以使用较少的训练词汇来通过迁移学习的方式获得高质量的训练结果。
使用基于特征标记的 word embeddings 的另外一个优点是可以通过对比具有类似特征的向量来进行类比,例如如果将基于 embeddings 得到的对应 man, women, king, queen 的词汇向量 word vector 做比较可以发现 eman - ewoman ≈ eking - equeen,这种近似关系也就等同于自然语言中的类比。

在算法实现中,为了让算法可以获知上述的相似关系,可以定义一个相似函数 sim( ) 使得对于任意词汇向量 ew,令其等于 argmax(sim(ew, eking - eman + ewoman))。最基本的相似函数可以是余弦距离,也即 sim(u, v) = cosθ = dot(u.T, V) / ||u||2||v||2,为了理解这个余弦距离也可以将其与 相关系数 进行类比。
Embedding matrix
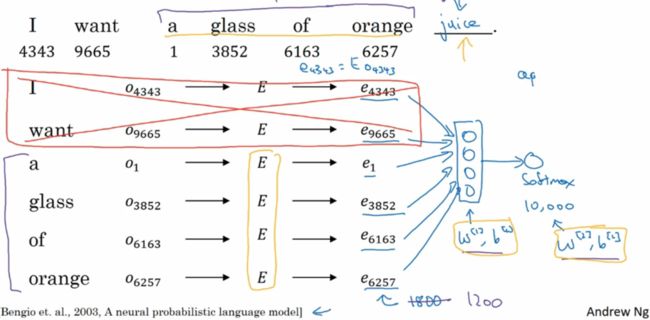
假设我们需要网络学习的 Embedding matrix 有 300 个特征,并且词汇表中有 10,000 个单词,那么这个 embedding matrix 将是一个 300 x 10,000 的矩阵,记做 E,此时如果我们将这个矩阵与任意个 One-hot encoding 得到的维数为 10,000 x 1 的词汇向量 Ow 做乘法的结果是一个维数为 300 x 1 的向量,且等同于提取 E 中的第 w 列,即 E⋅Ow = ew。在实际模型构建中,我们会随机初始化 E,然后通过梯度下降不断更新 E 中的数值。在 Andrew 的课堂中他依然采用的是权重参数在前的矩阵乘法形式,因此维数上需要格外注意。
Word embedding 的相关算法
在自然语言中,词汇与词汇之间的相关关系是不等的,也即有些词汇与另外一些词汇同时出现的概率更高,这就启发我们在网络训练时希望网络可以获知词汇之间的关联关系,也即可以在将语句拆分成单词的基础上,构建词语之间的关联关系。并且 Andrew 提到在自然语言处理研究领域的一个趋势是用于 word embedding 的算法随着时间的推移有更加简洁的趋势,因此后面介绍的几个算法其实现的复杂性逐渐降低,但令人意外的是效果保持不变或更好。
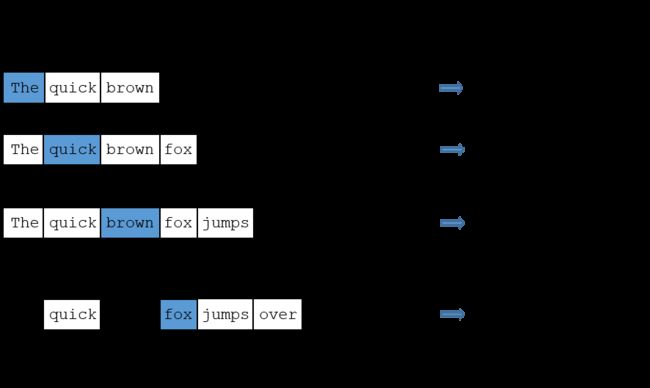
在构建 word embedding 时,一个比较重要的超参数是给予预测部分提供的语境信息的多少,一般如果在做语言建模时,都会选择紧邻被预测词汇的前几个单词,而如果是希望通过模型训练来构建 word embedding 时,则可以选择被预测词汇左右两侧的几个单词、紧邻被预测词汇的 1 个单词或者被预测词汇附近的某一个单词。
词汇-向量模型 Word2Vec model
论文的原作者在构建 Word2Vec 这个语言模型的时候提出了基于连续词袋模
continuous bag-of-words model 和基于连续 skip-grams 模型两种方式。其中
skip-grams 是与 n-grams 对应的,后者指的是一个语句中 n 个连续的词汇构成的序列,而 skip-grams 与其采用预测词汇附近的固定 n 个单词作为语境信息,我们可以将采样窗口设置成一个超参数来构建语境-目标对 context-target pair:首先通过随机选取一个词汇作为语境 context 信息,在其附近某预先设定的范围如 ±5 个词汇长度内随机提取另一个词汇作为目标 target 信息,在用语料库中所有的 context-target 对来对网络进行训练,从而使得网络获知当输入为某个单词时,输出语料库中全部单词对应作为目标的概率。
The network is going to learn the statistics from the number of times each pairing shows up. So, for example, the network is probably going to get many more training samples of (“Soviet”, “Union”) than it is of (“Soviet”, “Sasquatch”). When the training is finished, if you give it the word “Soviet” as input, then it will output a much higher probability for “Union” or “Russia” than it will for “Sasquatch”. - Chris Mccormick
比较令人惊讶的是这个看起来非常复杂和抽象的任务竟然可以通过只包含一个隐藏层的神经网络来实现,依然采用前面 Andrew 使用的 Embedding Matrix 的维数,如果输入为 1 x10,000 的 one-hot encoding 向量,我们想创建包含 300 个特征的 Embedding Matrix,那么在网络的隐藏层就需要包含 300 个单元,并且隐藏层不做任何的激活,再将隐藏层的输出传递给由 10,000 个单元构成的 softmax 回归分类:P(t | c) = eθtTec / ΣeθjTec,j = 1, 2, 3, ... , 10,000 ,通过梯度下降使得网络的输出逐渐的逼近给定的目标值,既可以实现网络的学习。
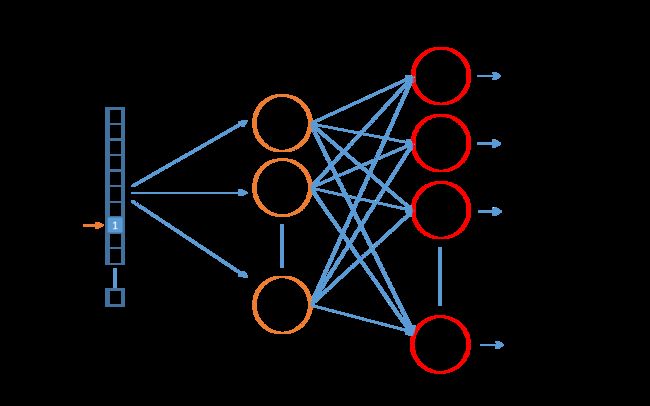
对于这个隐藏层,由于输入的维数是 10,000,在此基础上如果设定 Embedding matrix 的特征数量为 300,则这个矩阵中的参数有 300 x 10,000 = 3,000,000 个参数,因此这个算法实现起来真正的难度在于其庞大的计算量。Google 的几位作者为了减少计算量,算法实现的时候采用的是基于二分法原理的 Hierarchical softmax,并且对于常用的词汇会被放置在分叉树的起始层级,以便其被更快的找到。
上述示例运算中由于输入是 one-hot encoding 的 1 x 1000 向量,且只有索引位置所在处为 1,其余元素全为 0,因此在实际计算中对应的 Embedding matrix 的每一行就是对应相应输入词汇的词汇向量 word vector。
GloVe
参考阅读
What are word embeddings
Vector representation of words
Word2Vec concept explanation - The Skip-Gram Model
Word2Vec implementation with TensorFlow