pandas使用个人理解,欢迎补充
一、pandas处理excel文件和csv文件
1、csv文件
csv以纯文本形式存储表格数据
pd.read_csv('文件名'),可添加参数engine='python',encoding='gbk'
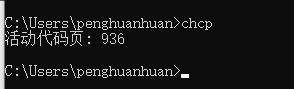
一般来说,windows系统的默认编码为gbk,可在cmd窗口通过chcp查看活动页代码,936即代表gb2312。
例如我的电脑默认编码时gb2312,pycharm默认是utf-8编码,csv内存在中文时会出现错误,可通过指定engine或编码格式解决。
2、excel文件
之前博客写过通过xlrd和xlwt读写xls文件、通过openpyxl读写xlsx文件,而pandas即可处理xls文件、也可处理xlsx文件。
pandas读取的excel结果为一个DataFrame对象,因此DataFrame的许多方法都会被用到,学习DataFrame https://www.cnblogs.com/Forever77/p/11209186.html。
pd.read_excel('文件名'),默认读取文件的第一个sheet页,并将第一行当作column,添加一行从0开始的整数作为index。
常用参数sheet_name='':表示读取文件的哪个sheet页,可以为sheet页名称,也可以使用数字,0表示第一个sheet页;None会读取所有有内容的sheet页。结果为一个字典,字典的key为sheet页名称,value为sheet页内容;默认读取第一个sheet页
index_col:将哪一列当作index列,默认添加一列从0开始的整数作为index,通过指定index_col='列名'指定索引列
header:将哪一行当作表头,即DataFrame的columns,默认将sheet页的第一行当作表头,header=1则将第二行当做表头
假设有一个excel表格内容如下图1,使用pandas读取结果分别如下。

-
import pandas as pd -
df = pd.read_excel('fruit.xlsx') -
print(df) -
print(df.values) -
print(df['名称']) -
print(df.loc[1]) -
print(df.loc[2,'单价/元'])





![]()
①df = pd.read_excel('fruit.xlsx'),表示通过pandas读取excel并加载为DataFrame,从图2可以看出如果读取时不设置索引,pandas会自动生成一列,该列值从0开始,表示行索引。
②图2中红框中的部分即为DataFrame的值,可通过df.values获取,结果如图3,类似列表的形式,数据类型为
③图2数据部分有三列,列的名字为第一行的内容,即列索引,可通过df[列名]获取某一列的内容,结果如图4所示;
④pandas自动生成的行索引从0开始,可通过pd.loc[n]获取索引值为n的行的内容,结果如图5所示;
⑤通过pd.loc[行索引,列索引]可获取具体单元格的内容,结果如图6所示。
可通过df.set_index(列名)自行设定索引,如下示例
-
import pandas as pd -
df = pd.read_excel('fruit.xlsx') #也可在读取时直接设置index_col='名称' -
df = df.set_index('名称') #设置名称列为行索引 -
print(df) -
print(df.values) -
print(df['库存/kg']) -
print(df.loc['草莓']) -
print(df.loc['香蕉','单价/元'])




![]()
将DataFrame格式的数据写入excel
第一步:writer = pd.ExcelWriter('文件路径和名称'),文件名称必须指定,默认保存在当前文件的相同目录,文件名称需包含后缀名且只能为xls或xlsx
第二步:df.to_excel(writer,'sheet页名称'),sheet页参数可不指定,默认为Sheet1
第三步:writer.save()
二、北京尚课堂-pandas处理excel文件方式:
读 excel 文件
安装 pandas pip install --no-index --find-links=包位置 -r requirements.txt
requirements.txt 中记录着所有需要的依赖包和版本号 验证是否成功python→import pandas 导入包
import pandas 获得数据
data=pandas.read_excel(“xls 文件名”,sheet_name=sheet 表编号或名称,names=[新 列名列表],dtype={“新列名”:类型},,skiprows=跳过数据行的行数,header=None 表示没有列名)
默认认为包含列名
默认从第一个sheet页开始读
获得全部数据,结果为 DataFrame(字典,列名为关键字) datalist=data.values.tolist() 返回列表
下面是代码:
import pandas
file=pandas.read_excel(“e:/cases.xsl”,skiprows=1,header=none,names=‘yhm’,‘mm’,‘yuqi’,dtype={‘yhm’:str,‘mm’:str,‘yuqi’:str})
data=file.values.tolist()
for line in data:
yhm=line[0]
mm=line[1]
yuqi=lin2[2]
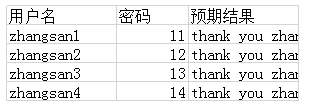
原始数据cases为:
pandas安装包见百度云
三、自学代码python2实现pandas+ddt参数化过程部分源码:
def readlists():
lists=[
['','',u'请您输入手机/邮箱/用户名'],
['admin','',u'请您输入密码'],
['','admin',u'请您输入手机/邮箱/用户名']]
return lists
import pandas
def readlists():
file=pandas.read_excel(‘e:/cases.xsl’) #
lists=file.values.tolist() #转换为了列表(list格式)
return lists
后面的参数化详看:https://blog.csdn.net/weixin_45433031/article/details/105000337,引入ddt