KMP算法 --- 在文本中寻找目标字符串
很多时候,为了在大文本中寻找到自己需要的内容,往往需要搜索关键字。这其中就牵涉到字符串匹配的算法,通过接受文本和关键词参数来返回关键词在文本出现的位置。一般人在初次接触的时候,可能会写出这样的代码:
/* 返回字符串substr在str中首次出现的位置索引,
* 若不存在,返回-1。
*/
int strStr(string str, string substr) {
int i, j;
if (str.empty() && substr.empty())
return 0;
for (i = 0; i < str.length(); ++i)
{
for (j = 0; i + j < str.length() && j < substr.length(); ++j)
if (str[i + j] != substr[j])
break;
if (j == substr.length())
return i;
}
return -1;
}
这种算法的大致流程如下:
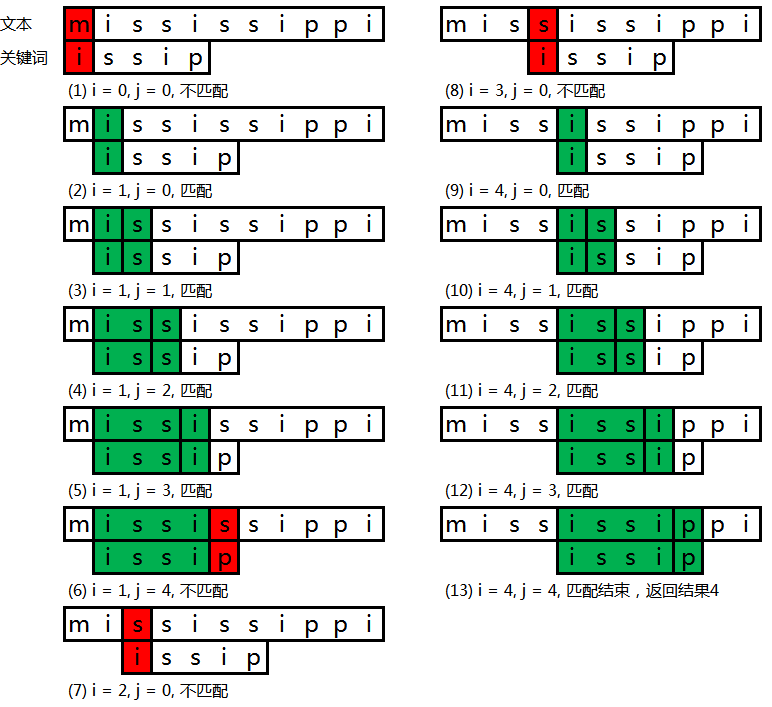
若文本的长度为m,关键词的长度为n,则该算法的复杂度为O(mn)。这会引起某些情况下搜索效果会变得非常差,比如文本 000000...00001(在1的前面有10000个0),我们需要搜索的是关键词00...001(在1的前面有1000个0),找到关键词需要执行的步数将大致为 10000 * 1000 ,所以我们需要一个搜索效率更高的算法,即KMP算法。
KMP算法全称为The Knuth-Morris-Pratt Algorithm,是由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现。它是通过利用匹配失败后的信息,尽可能减少文本与关键词的匹配次数从而达到快速匹配的目的。我们需要通过O(n)的函数来构造一个next数组,用于储存关键词的局部匹配信息,然后通过O(m)的遍历来寻找目标关键词。因此总的时间复杂度可以达到O(m+n)。
如果使用KMP算法的话,流程可以简化为下图:
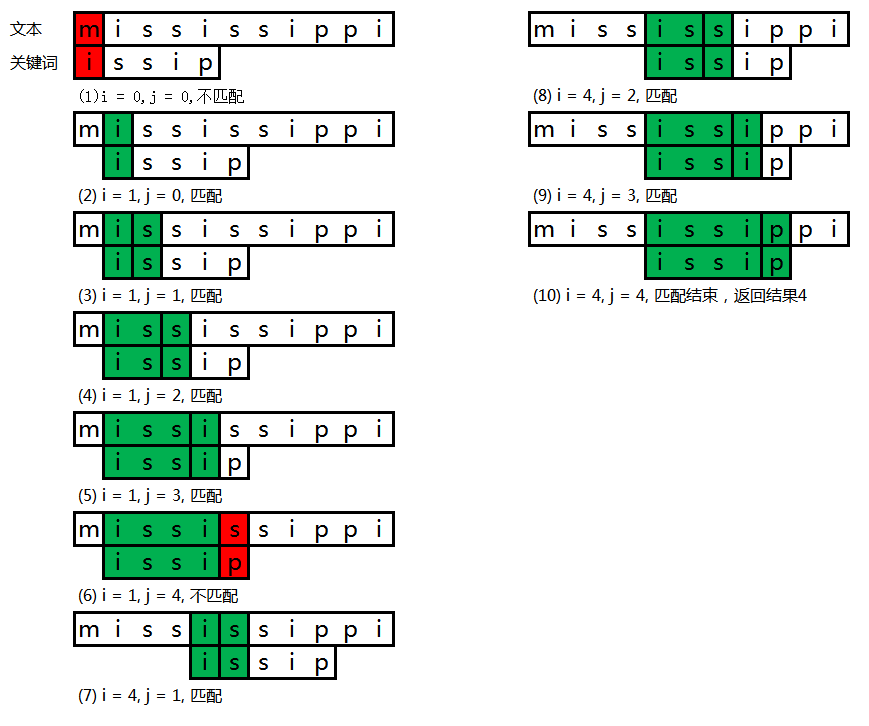
可以看到(6)到(7)跳过了中间的两个字符,这也是因为我们知道这中间的两个字符不可能和关键词的第一个字符匹配,可以直接跳过。这样的话我们需要寻找下一个符合关键词前缀的位置,这个前缀可以是 i ,is等。当然只是这样的话对于上述的极端情况似乎没有效果,接下来开始深入探讨KMP算法。
1.在关键词中寻找其最长公共前后缀
现在有一关键词: abcabba。
我们可以从关键词的前1个字符构成的子串开始寻找最长公共前后缀,然后是前2个...一直到整个关键词的最长公共前后缀。
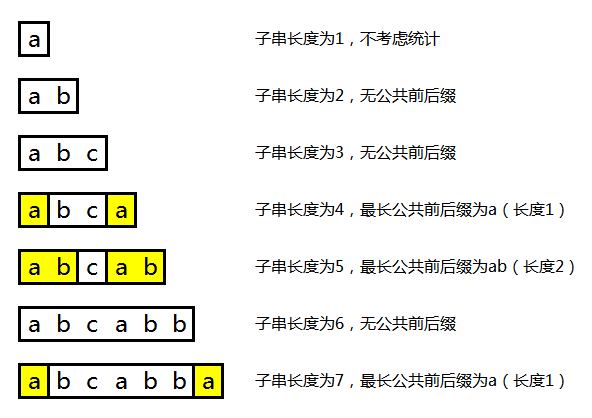
这样就有:
通过这些数据,我们就可以用来直接从前缀跳到后缀所在的位置,从而不需要逐个比对中间那些字符。
2.跳转数组的应用与构造
上面的那个数组还不是next数组。在构造next数组之前,我们先需要了解其用途。next数组的含义是:在匹配到关键词索引值为 j 的字符(注意:这里 j 是从 0 开始的)失败的时候,文本跳过 j - next[j] 个字符的位置,然后从关键词索引为 next[j] 的字符继续匹配。
i += j - next[j];
j = next[j];
与关键词第一个字符不匹配的情况(匹配失效)
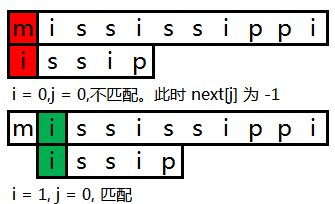
在这里我们需要标记 next[0] 为 -1,用以表示上述特殊情况。这样文本将来到下一个字符的位置(j - next[j]的值刚好就是1),然后继续和关键词索引为 0 的字符继续比较。
与关键词中间某个字符不匹配的情况
情况1 (匹配的部分没有公共前后缀)
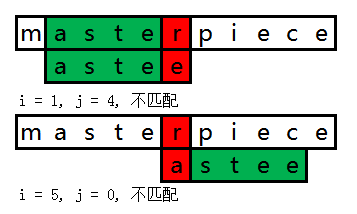
在这种情况下,由于已经匹配的部分没有公共前后缀,此时next[4]的值为0,所以原来已经匹配的部分可以全部跳过,然后重新与关键字索引next[4]的值比较。如果不匹配,就会回到匹配失效的情况。
情况2(匹配的部分有公共前后缀)
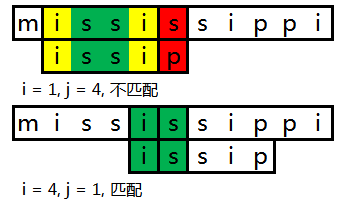
由于j = 4时,出现了 s 和 p 的不匹配,而已经匹配的部分包含公共前后缀 i ,这样在我们令索引 i 跳到下一个 字符 i 出现的位置。同时由于前缀 i 在原来的位置是已经匹配的, 那么跳转到后缀 i 位置的时候也肯定是匹配的。我们将 j 设为索引 next[4](这里 next[4] 的值为1)然后进行比较即可。
情况3(公共前后缀内部也含有公共前后缀)
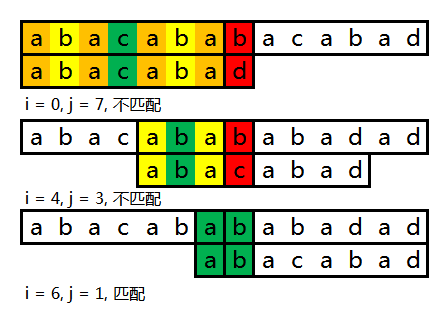
可以看到,已经匹配的部分含公共前后缀 aba ,而 aba 内部也含有一个公共前后缀 a 。因此我们需要先跳转到下一个公共前后缀 aba ,此时 next[j] 的值应为 3 ,所以从关键词索引 3 的字符继续比对。然而此时匹配依然失败,由于 aba 的公共前后缀是 a, 此时 next[j] 的值应为 1,因此跳转到下一个a,最终比对成功。
这样的话,如果一个公共前后缀内部仍含有公共前后缀,我们需要通过上面的两行代码继续跳转(这是一种递归操作),直到匹配成功、 没有子公共前后缀 或者 匹配失效 的情况。
情况4(关键字内匹配和不匹配的部分构成的子串含有公共前后缀 且 前缀第一个字符与后缀最后一个字符 相等)
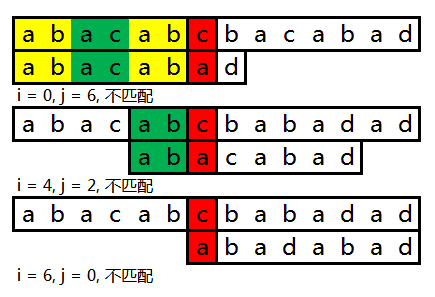
可以看到关键字子串 abacaba 内含公共前后缀 aba ,而如果在这里将 next[6] 设置为 2 的话,则在比对的时候又是拿 a 来与 c 比较。同样关键字子串 aba 的公共前后缀是 a,如果将 next[2] 设为 0,则同样还是拿 a 和 c 做比较。结果一定会是匹配失效的,也就是最终会令j 变为 -1。这样的话我们可以直接令 next[2] 和 next[6] 直接设置为 -1,以减少不必要的跳转。
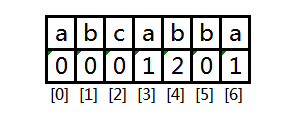
在构造next数组的时候还需要注意这种情况(关键词 aabaaac ,注意长度5和6的子串):
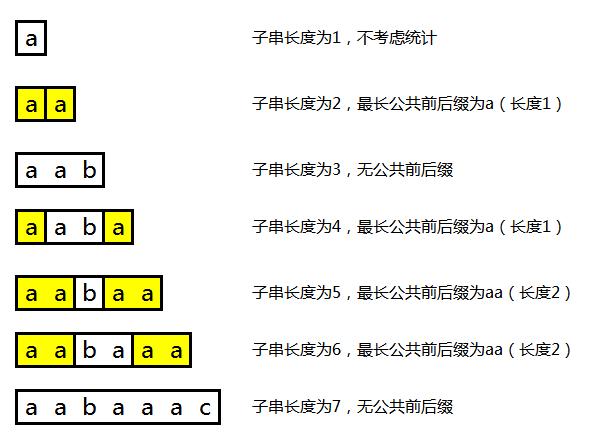
令 pos = next[pos] ,只要pos不为 -1,可以说明找到了长度更小的公共前后缀。
这是关键词 abacabad 的next数组:
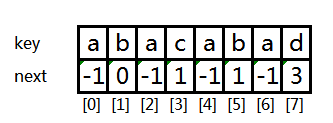
以下是next数组的构造函数的实现。代码比较简洁,需要结合上述情况理解:
vector construct_next(string key)
{
//关键词为空时,next数组也为空
if (key.empty())
return vector();
int pos = 0, sz = key.length();
vector next(sz); //next数组容量为sz
next[0] = -1;
for (int i = 1; i < sz - 1;)
{
//匹配失效 或 找到公共前后缀时
if (pos == -1 || key[i] == key[pos])
{
//情况4
if (key[i] == key[0])
next[i] = -1;
next[++i] = ++pos;
}
//不匹配时,寻找匹配子串的公共前后缀
else
pos = next[pos];
}
return next;
}
3.kmp函数的实现
有了next数组后,kmp函数的实现就会简单的多了。这里是kmp函数的实现:
int kmp(string text, string key)
{
vector next = construct_next(key);
int i = 0, j = 0, txtlen = text.length(), keylen = key.length();
while (i <= txtlen - keylen && j < keylen)
{
//匹配失效时,令j回归0;匹配成功时,给j加上1
if (j == -1 || text[i + j] == key[j])
++j;
else
{
//进行跳转
i += j - next[j];
j = next[j];
}
}
if (j == keylen)
return i;
else
return -1;
}