solr学习笔记 -- day08 solr集群
一、SolrCloud介绍
1、什么是solrCloud
SolrCloud(solr云)是Solr提供的分布式搜索方案。
Solr在4.0版本之后才提供solrcloud集群方案,在此之前,solr有master-slave方案.
Solr的master-slave集群功能是具有高可用及读写分离特性。读写分离指的是master负责写操作,而slave负责读操作,并且备份master中的索引信息.master-slave机制不支持负载均衡。
Solrcloud没有读写分离,但是solrcloud中,可以进行负载均衡及高可用的配置.
2、应用场景
当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。
当索引量很大,搜索请求并发很高时,同样需要使用solrCloud来满足这些需求。
不过当一个系统的索引数据量少的时候是不需要使用SolrCloud的。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案。它的主要思想是:使用Zookeeper作为SolrCloud集群的配置信息中心,统一管理solrcloud的配置,比如solrconfig.xml和schema.xml。
3、功能特色
(1)、集中式的配置信息
(2)、自动容错
(3)、近实时搜索
(4)、查询时自动负载均衡
二、solrCloud的结构
1、solrcloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard分片,每个分片由多台服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
2、solrcloud是基于solr 和 zookeeper部署,zookeeper是一个集群管理软件,solrCloud需要由多台solr服务器组成,然后由zookeeper来进行协调管理。
3、solrCloud应用图例: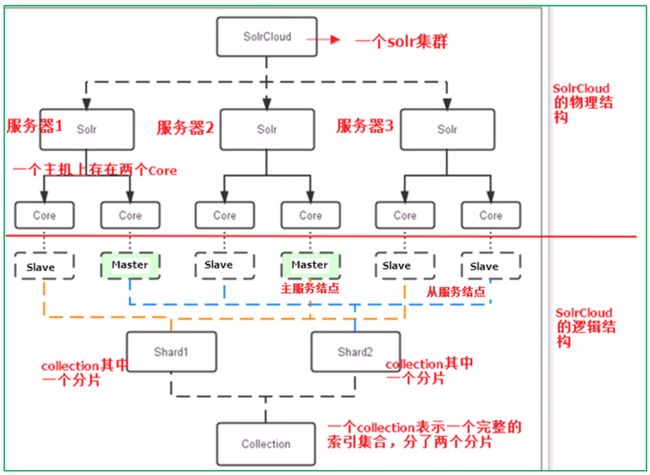
图例总结:solrcloud的架构分为逻辑结构和物理结构。
物理结构:(需要进行安装)
Solrcloud集群是由多台安装solr服务的Linux服务器组成.每台solr服务器中可以安装多个solr服务(也就是core,一个solr服务对应一个solrcore,对应一个solrhome,对应一个tomcat)。
从物理结构来看,solrcloud需要三台solr服务器,每台服务器包括两个solrcore实例,共同组成一个solrcloud。
逻辑结构:(需要配置)
Solrcloud集群从逻辑上可以看成是一个collection(solrcloud的完整索引集合)。由于solrcloud是分布式的,所以collection从逻辑上需要被分成多个部分(shard)。每个shard中包含多个solr服务(core),同一个shard中多个solr服务之间是有不同角色的,分别是一主多从。
同一个shard中有多个solr服务的好处:负载均衡\高可用。
不同shard中包含不同的solr服务,它的好处: 可以比较好的进行扩容
从逻辑结构来说,整个solrcloud就看成一个大的solrcore,也就是一个collection。而一个collection被分成两个shard分片(shard1和shard2)。shard1和shard2又分别由三个solrcore组成,其中一个Leader两个Replication。Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
Collection:
Collection在Solrcloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个shard分片,这些shard分片使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。collection=shard1+shard2+....+shardX
Shard:
Shard是Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
Core:
每个Core都是Solr中一个独立运行单位,提供索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成,一个shard由多个core组成,所以也可以说collection一般由多个core组成。
Master 或 Slave:
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
三、solrCloud搭建说明
1、注意:
(1)、solrcloud是通过zookeeper统一管理配置文件(solrconfig.xml、schema.xml等),所以搭建solrcloud之前,需要先搭建zookeeper。
(2)、由于solrcloud一般都是解决大数据量、大并发的搜索服务,所以搭建solrcloud,对zookeeper也需要搭建集群。
本教程的 solrcloud 是搭建在一台机器中,指定不同的端口。而真实生产环境搭建solrcloud时,只需要修改ip地址即可。
2、Solrcloud示例结构图:

四、zookeeper集群搭建
1、环境说明:
需要三台zookeeper、分别是zk1、zk2、zk3,对应的端口分别为2281、2282、2283
2、安装java环境
安装jdk,zookeeper是使用java开发的。
3、创建solrCloud目录,上传zookeeper压缩包并解压

4、修改解压后的文件夹名称为zk1

5、进入zk1下的conf,修改配置文件名称及集群配置
注意:客户端端口、通信端口、选举端口,在同一台机器搭建集群时,需要与集群中其他zookeeper服务的端口区分。
[root@localhost conf]# mv zoo_sample.cfg zoo.cfg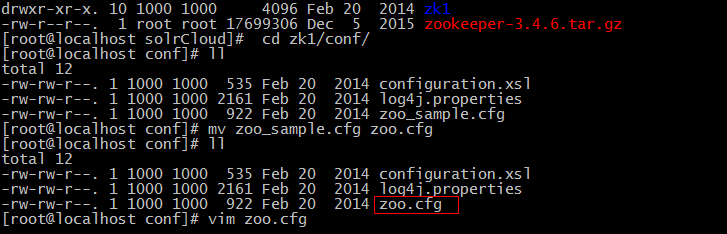
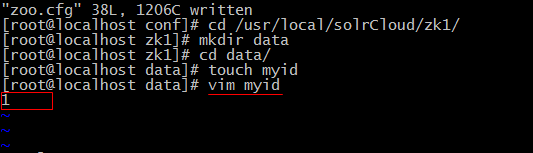
数据目录需要手动创建出来
# 配置数据目录
dataDir=/usr/local/solrCloud/zk1/data
# the port at which the clients will connect
# 配置zookeeper的端口号,默认端口号是2181,可以修改
clientPort=2281
#集群中每台机器都是以下配置
#2881系列端口是zookeeper通信端口
#3881系列端口是zookeeper投票选举端口
server.1=192.168.200.134:2881:3881
server.2=192.168.200.134:2882:3882
server.3=192.168.200.134:2883:3883
6、配置每台机器的身份识别号
7、复制zk1为zk2和zk3
[root@localhost solrCloud]# cp zk1 zk2 -r
[root@localhost solrCloud]# cp zk1 zk3 -r
8、分别修改zk2和zk3中的zoo.cfg配置以及myid中的配置


9、编写脚本,启动zookeeper集群
[root@localhost solrCloud]# vim start-zk.sh
/usr/local/solrCloud/zk1/bin/zkServer.sh restart
/usr/local/solrCloud/zk2/bin/zkServer.sh restart
/usr/local/solrCloud/zk3/bin/zkServer.sh restart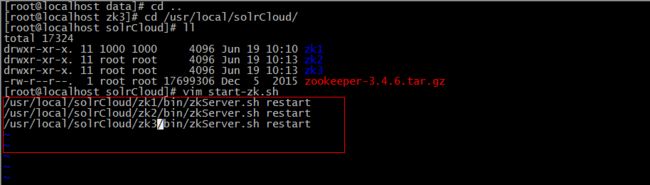
[root@localhost solrCloud]# chmod u+x start-zk.sh 
10、查看三台zookeeper主从关系

五、solrCloud集群搭建
1、环境说明:
solrcloud由zookeeper统一管理solr的配置文件(主要是schema.xml、solrconfig.xml),solrcloud各个solrcore节点都使用zookeeper管理的统一配置文件。
注意:solrcloud启动之前,需要先启动zookeeper集群。
2、复制4个单机版的solrHome到solrCloud目录下,分别命名为8280~8580
[root@localhost solrCloud]# cp ../solr/solrHome/ ./solrHome8280 -r
[root@localhost solrCloud]# cp ../solr/solrHome/ ./solrHome8380 -r
[root@localhost solrCloud]# cp ../solr/solrHome/ ./solrHome8480 -r
[root@localhost solrCloud]# cp ../solr/solrHome/ ./solrHome8580 -r 
3、分别复制单机版的tomcat到solrCloud目录下,命名规则为8280~8580
[root@localhost solrCloud]# cp ../solr/apache-tomcat-7.0.47 ./tomcat8280 -r
[root@localhost solrCloud]# cp ../solr/apache-tomcat-7.0.47 ./tomcat8380 -r
[root@localhost solrCloud]# cp ../solr/apache-tomcat-7.0.47 ./tomcat8480 -r
[root@localhost solrCloud]# cp ../solr/apache-tomcat-7.0.47 ./tomcat8580 -r
4、分别修改4个tomcat的端口号为8280~8580
5、分别修改4个tomcat对应的solrHome,8280~8580

6、分别修改每个solrHome的solr.xml,指定对应的solr中对应的tomcat的ip和端口信息
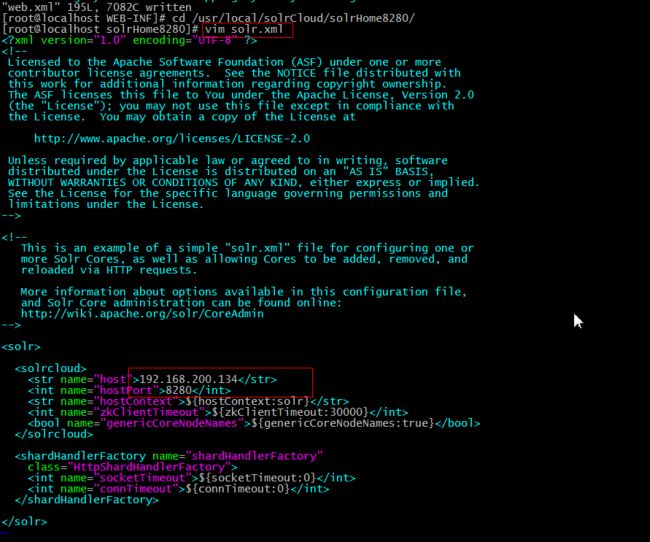
7、分别设置4个tomcat的启动参数,修改每个tomcat的 catalina.sh,添加如下内容
JAVA_OPTS="-DzkHost=192.168.200.134:2281,192.168.200.134:2282,192.168.200.134:2283"
8、将solr的配置文件上传到zookeeper中,进行统一管理
使用/usr/local/solr-4.10.3/example/scripts/cloud-scripts下的zkcli.sh命令将/usr/local/solrcloud/solrhome8280/collection1/conf目录上传到zookeeper进行配置。
进入solr-4.10.3/example/scripts/cloud-scripts/目录下,执行以下命令
./zkcli.sh -zkhost 192.168.200.134:2281,192.168.200.134:2282,192.168.200.134:2283
-cmd upconfig -confdir /usr/local/solrCloud/solrHome8280/collection1/conf -confname myconf
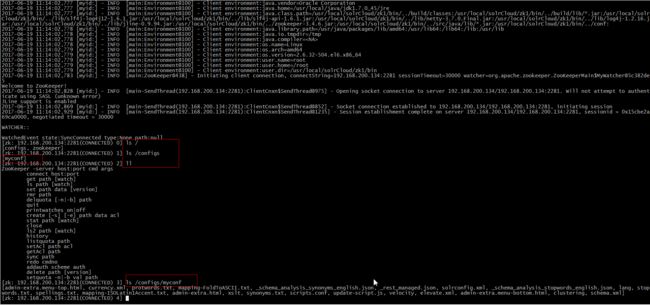
9、查看是否上传成功
使用zookeeper自带的zkCli.sh命令连接zookeeper集群,查看上传的配置文件。
[root@localhost bin]# ./zkCli.sh -server 192.168.200.134:2281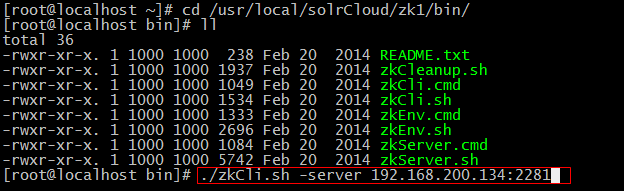
10、编写tomcat启动脚本

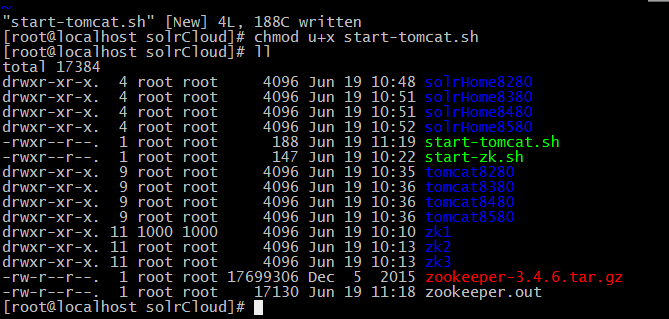
11、启动tomcat,进入浏览器查看
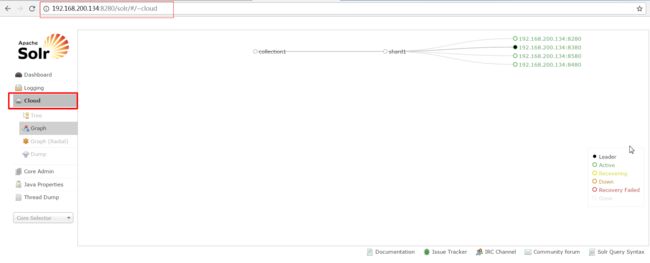
六、集群分片
1、创建collection
需求:创建新的集群,名称为collection2,集群中有四个solr节点,将集群分为两片,每片两个副本。
使用以下命令,在浏览器中执行
http://192.168.200.134:8280/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2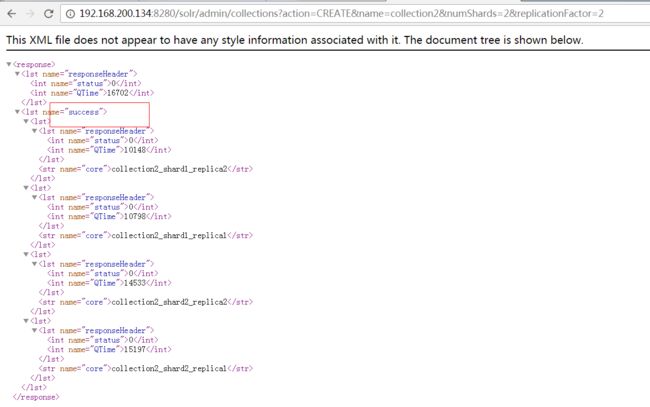
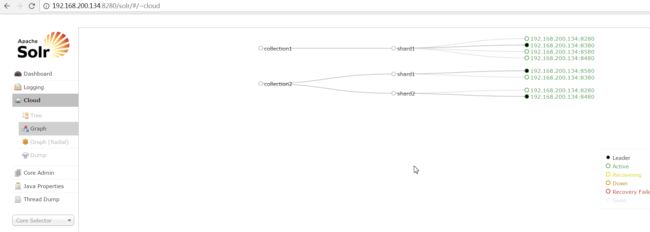
2、删除collection1
浏览器使用以下命令
http://192.168.200.134:8280/solr/admin/collections?action=DELETE&name=collection1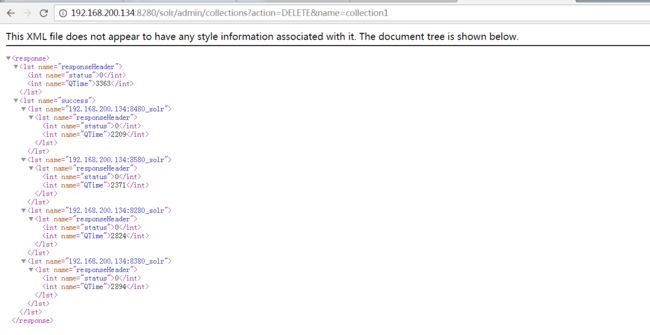

七、进行java代码测试
1、配置solr与spring整合的配置文件

2、测试代码
package test;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.CloudSolrServer;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class SolrTest {
@Test
public void testCloud() throws Exception {
String zkHost = "192.168.200.134:2281,192.168.200.134:2282,192.168.200.134:2283";
// 创建CloudSolrServer对象
CloudSolrServer solrServer = new CloudSolrServer(zkHost);
// 设置SolrServer的默认Collection名称
solrServer.setDefaultCollection("collection2");
// 调用solrServer的api方法完成索引库操作
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "c001");
doc.addField("name", "测试solr连接");
solrServer.add(doc);
solrServer.commit();
}
/**
* 与spring整合测试
*/
@Test
public void testSpringSolr() throws Exception {
// 获取solrServer对象
ApplicationContext app = new ClassPathXmlApplicationContext("classpath:spring/applicationContext-solr.xml");
SolrServer solrServer = app.getBean(SolrServer.class);
// 调用solrServer的api方法完成索引库操作
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "c003");
doc.addField("name", "测试solr连接3");
solrServer.add(doc);
solrServer.commit();
}
}