实时计算框架之二:Storm之入门实例
预备、开火、瞄准……
1 总结与提升
自1月份来,可谓是浮浮荡荡,一波三折呀。
先是参加了公司组织的创意马拉松大赛,虽说24小时内完成了作品,但是自己感觉上效果很差,自然成绩也是不高。通过这24小时持续的奋斗以及后来的各种产品描述等环节,发现了开发上的许多缺点。首先,对我们的产品进行了深入的认识和了解,也在产品之上,发现了更多可以发展走向成功的点子,这是我觉得最棒的一点;其次,短时间内和队员进行协作交流,生成产品,这之间的沟通非常重要;第三,选择C++作为24小时创作的语言,开发效率相对而言是非常慢的,效果也很差;第四,美有准备,很难打赢一场艰难的斗争,尤其是敌人非常强大时;第五,描述能力太差,作品展示时,没有想到其中的亮点,展示太过失败。
然后刚忙完创意马拉松大赛,又开始负责年会弹幕项目,公司员工通过微信公众号,活取到弹幕发送页面,然后发送弹幕,显示在年会背景屏幕上,取得了非常棒的效果。
还有各种各样的硬件上的大赛,例如说IntelEdison的创意大赛等,还没来得及去研究开发,又过年了。
一直想抽出点时间来去思考总结一下,却发现这紧张的节奏,完全容不得你多想,就这么整装上阵了。不过在这忙碌的节奏里,越来越发现自己的各种不足,也发现在这互联网发展的潮流之中,越来越多的机遇和挑战。
成王败寇,我不是一个懦弱的人,更不是一个喜欢低调的人。要把这份机会抓在手中,总有一天,会让你们看见我们的作品,在每个人的手机上,电脑上,以及各种智能设备之上!
上次总结了一下实时计算框架Storm的搭建过程,经过这段时间,在这之上又有了更进一步的发展。期间遇到了许多难点,下面就一点一点介绍给大家,来看看一个实时的云计算框架的强大之处!
本篇文章开始的引用使用《程序员修炼之道:从小工到专家》中关于曳光弹这一章的引言。我一直喜欢使用这种方法,可以快速的生成一个可以执行的Dmeo,然后按照这个Demo进行不断的扩展修正等,直到正式完善,生成产品。介绍这种方法给大家,希望对大家的工作有所帮助!
2 Storm的基本组成部分
经过前一部分,我们可以搭建起Storm的执行环境,并可以通过浏览器打开对应的管理页面。如果已经成功的到达这一步,那么恭喜你,Storm的框架已经搭建成功,接下来就是Storm具体该如何应用了。首先,先来介绍一下Storm的核心模块,我们基本需要依赖这几个模块来对应进行开发。
2.1 拓扑 - Topology
我们需要向Storm中提交一个实时运行的应用程序,由Storm来执行这个应用程序。那么,这个应用程序称作一个拓扑(Topology)。
为什么叫做拓扑呢?拓扑在计算机网络中,是将计算机和通信设备抽象为一个点,将传输介质抽象为一条线,由点和线组成的几何图形就是计算机网路的拓扑结构。我们提交的一个应用程序,是执行在Storm的集群上的,这个应用程序在运行的状态如下图。
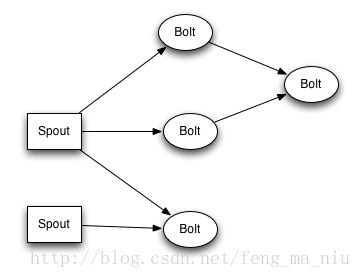
关于Spout和Bolt会在下面讲到,从图上直观来看,我们执行的应用程序就是一个拓扑。
2.2 喷口 - Spout
Spout是整个Topology的数据流来源,通常来说,Spout会从外部数据源中读取数据,然后转换为Topology内部的数据格式,再发送给Bolt进行计算处理。
Spout主要是有一个nextTuple函数,Topology会不断调用此函数,所以相关数据获取工作写在这个函数之内即可。
2.3 螺栓 – Bolt
在Topology中,所有的处理都在Bolt中完成,Bolt是Stream处理的节点。Bolt从Topology中获取数据,并进行处理。
Bolt主要有execute函数,在接收到数据后,会调用此函数,对接收的数据进行相关处理。
2.4 流 – Stream
Stream即一个无界的元组序列,一个接一个的序列,就构成了流。Spout和Bolt的处理数据即是流。
2.5 流分组 - Stream grouping
流分组定义了如何在Bolt的任务之间进行分发。就是说某个数据应该交由哪个固定的Worker来进行处理,这个在后面的实例中有个简单的例子,很容易理解。
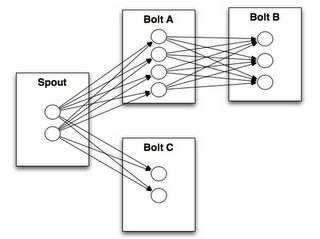
3 Storm实例
了解完上面几个部分,可能会有点不是很懂,现在接合一个具体的例子,来详细说明这几部分是如何接合及应用的。
3.1 需求描述
国外某地区,需要针对当地居民的名字做一个统计,即统计每个名字使用的次数。例如说,当地居民(假设为10人)有以下名字出现:
nathan
mike
jackson
jackson
mike
mike
golda
bertels
golda
bertels
那么,可以统计出以下结果信息:
nathan 1
mike 3
jackson 2
golda 2
bertels 2
另外,为了看到计算的结果,在处理每个名字时,为每个名字添加”!!!”,并进行打印输出。例如说nathan的打印结果为nathan!!!。
现在假设当前有N个人进行统计,名字假设还是只有这五种,那么在如何使用Storm来进行计算统计并打印结果呢?
3.2 Stream实现
由于现在作为数据进行传输的只有名字,所以当前Stream使用字符串既可。
3.3 Spout实现
根据上面需求的描述,Spout主要的任务是在名字数组String[] names = new String[]{"nathan", "mike","jackson", "golda", "bertels"};中随机活取N个名字,并发送到Bolt进行统计计算,并添加”!!!”后打印出来。所以具体实现如下。
package storm.spout;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class NamesSpout extends BaseRichSpout {
SpoutOutputCollector m_collector;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
m_collector = collector;
}
public void nextTuple() {
final String[] names = new String[]{"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String name = names[rand.nextInt(names.length)];
Utils.sleep(10);
m_collector.emit(new Values(name));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("name"));
}
}首先,自定义的Spout需要继承Storm的相关Spout的接口,例如BaseRichSpout或者IRichSpout等。
其次,在open函数中,实现资源的初始化等操作,这里没有特殊操作,只将流获取绑定到本身Collector上即可。
第三,声明输出流的格式,即 declareOutputFields函数。
最后,实现流的生成操作nextTuple函数,这里在人名中随机选择一个,并通过emit进行发送,Bolt接收到这个人名,并进行下一步的处理。
至此,一个简单的Spout就完成了。
3.4 Bolt实现
Bolt的操作分为两部分,第一部分是统计计算,第二部分是进行”!!!”的添加。其也需要继承Storm对应的类BaseRichBolt或者其他的接口。具体实现如下。
package storm.bolt;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class ExclamationBolt extends BaseRichBolt {
OutputCollector m_collector;
public Map NameCountMap = new HashMap();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
m_collector = collector;
}
public void execute(Tuple input) {
// 第一步,统计计算
Integer value = 0;
if (NameCountMap.containsKey(input.getString(0))) {
value = NameCountMap.get(input.getString(0));
}
NameCountMap.put(input.getString(0), ++value);
// 第二步,输出
System.out.println(input.getString(0) + "!!!");
System.out.println(value);
m_collector.ack(input);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("name"));
}
} 关于初始化的prepare函数和声明输出流的函数declareOutputFields不在重新说明,和Spout的相关函数类似。
这里定义了一个map,用来统计名字出现的次数,另外名字修改后会打印到控制台信息中。
统计计算部分都在execute接口中实现,较复杂的情况下,可以拆分为多个Bolt来分别执行不同的计算部分。
3.5 Topology实现
主要的两大部分都已实现完毕,那么该如何将Topology执行起来呢?Topology执行分两种模式,第一个是本地模式,即Debug模式;第二个是提交到Storm框架上,远程执行。
首先按照本地模式来讲解,远程模式可以增加一个执行参数来区分。具体实现如下。
package storm.topology;
import storm.bolt.ExclamationBolt;
import storm.spout.NamesSpout;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.utils.Utils;
public class ExclamationTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("name", new NamesSpout(), 5);
builder.setBolt("exclaim", new ExclamationBolt(), 5).shuffleGrouping("name");
Config conf = new Config();
conf.setDebug(false);
conf.put(Config.TOPOLOGY_DEBUG, false);
if (args != null && args.length > 0) {
conf.setNumWorkers(10);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}Topology中即实现主方法main,其中创建Topology,Topology要把Spout和Bolt的关系建立起来,建立关系的方法主要是通过名称建立。例如指定Spout输出流的处理Bolt时,通过设置shuffleGrouping中的名字即可,即将名字设置为Spout的名字”name”。
最后,载入配置,并执行。这里通过参数区分本地模式和远程模式,如果含有参数,则为远程模式,否则是本地模式。
完成这部分后,点击Eclipse的执行按钮,即可将Topology执行起来,输出窗口中也可以看到Bolt中打印的消息。
3.6 Stream grouping实现
接下来,是一个很有趣的部分。Stream grouping对Stream进行分组,具体是怎么用的呢?
先看一下上一次执行的结果,如下:
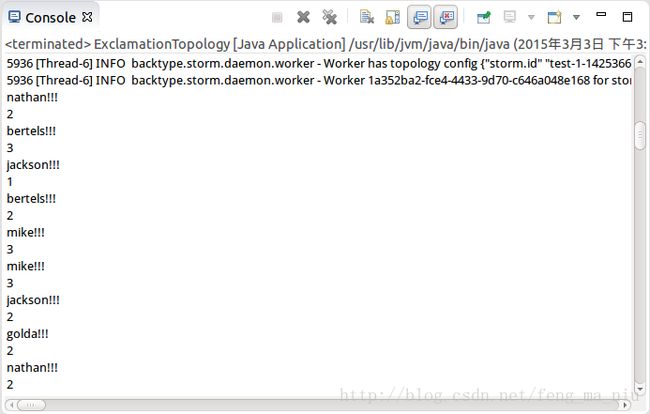
可以看到,mike两次结果都为3,这明显的是错误的,这是为什么呢?
回来看我们Topology部分的实现,有这一行代码:
builder.setBolt("exclaim", new ExclamationBolt(), 5).shuffleGrouping("name");可以看到后面有个shuffleGrouping,这个就是所谓的Stream grouping了。当前设置的是随机分组,那么map中的统计数目自然也就是错乱的了。我们将这行代码,换成以下形式:
builder.setBolt("exclaim", new ExclamationBolt(), 5).fieldsGrouping("name", new Fields("name"));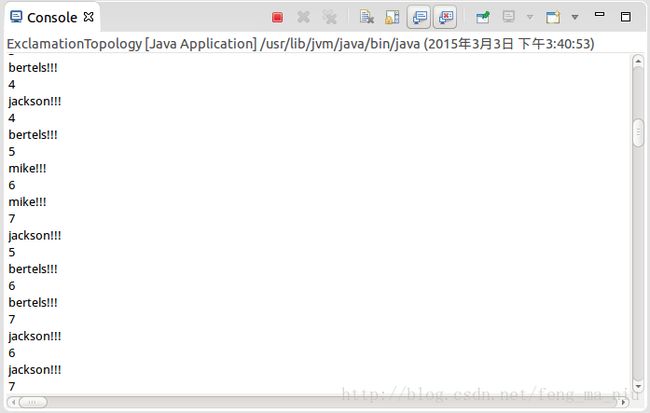
可以发现结果都是正确的,复合我们的计算要求。
Storm里面的Stream分组方式有7种,具体信息可以去官网查看文档,另外,也可以自己定义需要的分组方式。
4 打包与执行
如何创建一个Topology和Topology的执行部分都已经描述完毕,接下来就是如何将这个Topology提交到Storm框架里面来执行了。现在,需要用到我们之前下载安装的Maven工具来进行打包。
4.1 Maven打包
4.1.1 安装Eclipse的Maven插件
在Eclipse的菜单栏,选择【Help】中的【Install New Software】,如下图:
在【Workwith】中输入Maven的更新站点:
http://download.eclipse.org/technology/m2e/release
然后选择要安装的组件后,一直点击【Next】,等待安装完成后,重启Eclipse即可。
4.1.2 进行打包
在Eclipse中,右键点击要打包的Project,并在右键菜单中选择【Run as】中的【Maven build】,如下图所示。
增加参数:clean package,当在输出窗口中看到Success,则表示打包成功,否则根据错误提示进行修改并重新打包。
4.2 提交jar包到Storm上
打开控制台,进入到工程目录,并进入到工程目录下的target目录下,使用ls命令查看所有文件如下:
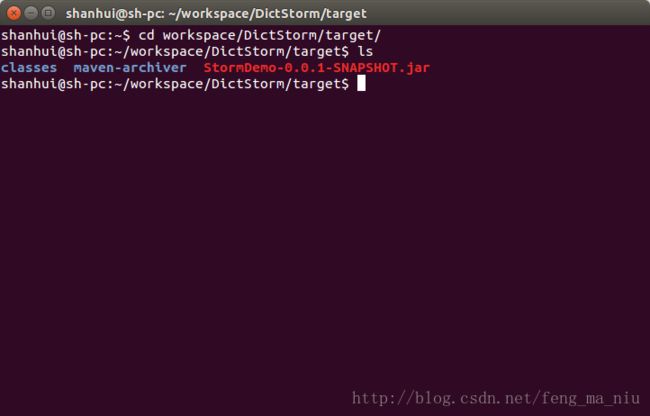
其中,StormDemo-0.0.1-SNAPSHOT.jar文件就是我们要提交到Storm上执行的jar包。使用以下命令进行jar包提交。
storm jar StormDemo-0.0.1-SNAPSHOT.jarstorm.topology.ExclamationTopology demo
其中,storm.topology.ExclamationTopology是jar包主入口所在位置,后面的demo为参数,前面我们提到过,使用该参数来区分本地模式和远程模式。
4.3 查看提交及执行结果
提交后,可以在Storm的网页上看到对应的执行情况。
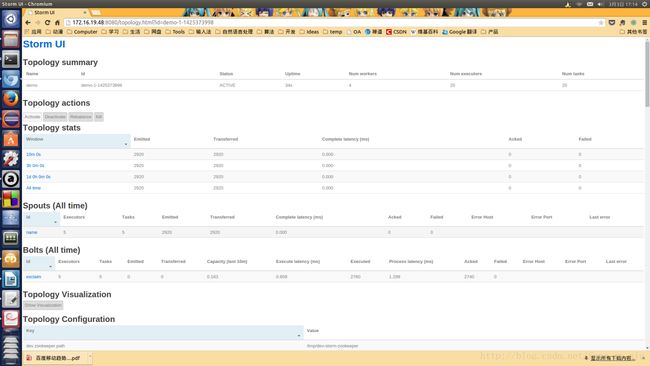
5 进一步思考
一直以来,基本全在C++这条不归路上奋斗着,随着这段时间来的各种突发感受,发现了更多以前见识还是太过短浅。“完美”固然是一个非常宏伟的目标,但是在这种快速开发迭代出产品的情况下,却应该收起这种心态。一直看着一些缺陷漏洞百出的产品,会产生一种越来越疲惫的心态吧?
试着去理解另外一种心态,以“曳光弹”出发,快速开发,快速迭代,逐步完善,向完美靠拢。
时代在改变,技术在爆发,走向未来吧!