【Python实例第13讲】识别手写数字
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
这个例子显示怎样使用scikit-learn识别手写数字图像。关于手写数字数据集的详细介绍,请看《Python实例第3讲》。
实例详解
首先,加载matplotlib.pyplot绘图库和导入数据集、svm(支持向量机)分类器和分类测度模块。
import matplotlib.pyplot as plt
from sklearn import datasets, svm, metrics
导入数据集
digits数据集由 8 × 8 \small{8\times 8} 8×8 的手写数字图像组成,这些图像存储在数据集的images属性里。让我们看一看前4幅图像,每幅图像有相同的大小,它代表的实际数字在targets属性里。
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:4]):
plt.subplot(2, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Training: %i' % label)
plt.show()

为了在数据集上应用一个分类器,我们需要将图像“变平”,也就是,把一幅图像等价地转换成一个(样本,特征)矩阵。
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
分类学习
现在,产生一个svm分类器,并且在前一半的数据上训练该分类器。
classifier = svm.SVC(gamma=0.001)
classifier.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
然后,用训练好的分类器预测后一半数字,并计算预测精度矩阵。
expected = digits.target[n_samples // 2:]
predicted = classifier.predict(data[n_samples // 2:])
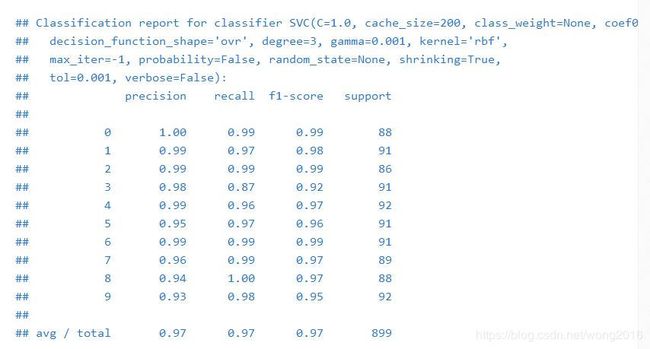
print("Classification report for classifier %s:\n%s\n"
% (classifier, metrics.classification_report(expected, predicted)))
print("Confusion matrix:\n%s" % metrics.confusion_matrix(expected, predicted))

最后,可视化预测结果。
images_and_predictions = list(zip(digits.images[n_samples // 2:], predicted))
for index, (image, prediction) in enumerate(images_and_predictions[:4]):
plt.subplot(2, 4, index + 5)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Prediction: %i' % prediction)
plt.show()

阅读更多精彩内容,请关注微信公众号:统计学习与大数据