MySQL的并行复制策略
文章目录
- 按表分发策略
- 按行分发策略
- MySQL5.6 的并行复制
- MariaDB 的并行复制
- MySQL5.7 的并行复制
- MySQL5.7.22 的并行复制
前面介绍的MySQL 的主从复制流程如下所示:
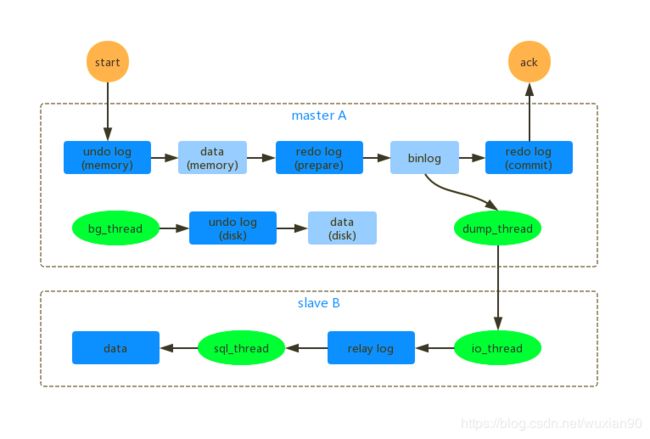
主备延迟的主要原因在于,master A 上产生 binlog 的速度大于slave B 处理 binlog 的速度。数据的积压就在于 sql_thread 处理的速度。在 MySQL 5.6 版本之前,只支持单线程复制。单线程的 binlog 复制,在高并发的场景下会出现严重的主从不一致。要解决这个问题,就需要将上面的 sql_thread 拆解成为多个线程处理。
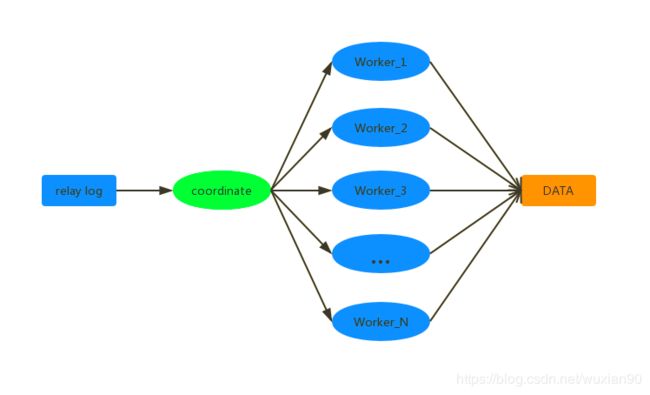
上图中的 coordinate 就是本文开始的 sql_thread,具体执行 binlog 复制的是 Worker。生产上,Worker 的个数设置为 8-16 个比较合适(32核CPU),因为从库还需要可能还需要处理读的请求。
对于 coordinate 的分发策略,并不能是随机的,因为这样对于SQL 执行不同的顺序,可能会产生不同的结果。此时对于 coordinate 的分发策略要求如下:
-
不能造成更新覆盖,同一行的更新必须被分发到同一个Worker 中;
-
同一个事务不能被拆开,必须被分配到同一个Worker 中。
按表分发策略
按表分发的基本思路是,如果两个事务更新不同的表,就可以并行处理。此时因为在不同 Worker 处理时,也不会更新到同一行的数据。如果有跨表的事务,则需要 2 张表都需要考虑了。

从上图可以看出,每个 Worker 都对应一个 hash 表,用于保存当前 Worker 执行的 binlog 涉及的表。hash 表的 key 是 “库名+表名”,value 表示 Worker 中有多少个事务操作这个表。当事务执行完成后,其所涉及的表的计数会从hash 表中移除。上面 Worker_1 中的hash 表中 db1.t1:4 ,表示:Worker_1 中修改 db1.t1 表的事务数有 4 个。
假设 coordinate 读取一个事务 T (涉及 t1 和 t3的改动),此时分配规则如下:
-
Worker_1 中有事务在处理 t1 的改动,此时和 Worker_1 是冲突的,对于Worker_2 有在处理 t3 的改动,此时和Worker_2 也是冲突的;
-
当事务 T 和多于 1 个Worker 冲突时,coordinate 就进入等待状态;
-
此时如果 Worker_2 中执行完事务后,对应 t3 的计数就会减 1,此时事务 T 就只和 Worker_1 冲突了,此时就会将其加入到 Worker_1 的队列中;
-
coordinate 读取新事务 T2 继续执行 步骤 1 。
总结以上,coordinate 在分发事务的时候,会考虑以下冲突情况:
-
当没有 Worker 冲突的时候,会将其加入到空间的Worker 中去;
-
当有只有 1 个Worker 冲突的时候,会将其加入到冲突的Worker 中去;
-
当有多于 1 个Worker 冲突的时候,coordinate 会进入等待状态,直到冲突数 <= 1。
按行分发策略
按行分发的策略和按表分发的策略类似,但是在考虑Worker 冲突的时候对应的hash key 就是“库名+表名+唯一键的值”,原理类似,这里就不做过多的介绍了。这里需要注意的点是,按行进行冲突检测,其消耗的计算量还是比较大的。
MySQL5.6 的并行复制
MySQL 从 5.6 版本开始支持按库级别的并行复制。对于一个应用来说,如果我们按照业务分库,从应用的层面上面讲是提高了 binlog 的复制能力的。按库级别的并行相比按表和按行级别的,有以下 2 个优势:
-
构造 Worker 的 hash 表很快,因为库的个数不会太多,而且计算量也会减少;
-
不需要要求 binlog 的格式。
MariaDB 的并行复制
在之前介绍的 redo log 组提交时,有以下特点:
1、在一个组里提交的事务,一定不会修改同一行;
2、主库上面可以并行的事务,在从库上面也是可以并行的。
MariaDB 并行复制的实现上,操作流程如下:
-
在一个组里面提交的事务有一个相同的 commit_id,下一个组就是 commit_id + 1;
-
commit_id 直接写到 binlog 里面;
-
传到备库的时候,相同 commit_id 的事务会被分发到不同的 Worker 中执行;
-
这一组执行完成后,再去取下一组重复以上步骤。
从上面流程可以看出,下一个组提交的执行依赖上一个组提交的执行完成。此时如果上一个组提交中有大事务,就会影响下一个组提交的执行,容易造成阻塞。
MySQL5.7 的并行复制
MariaDB 在实现了并行复制能力之后,MySQL 也提供了类似的功能。由 slave-parallel-type 参数来控制并行复制的策略:
-
配置为 DATABASE,表示使用 MySQL 5.6 开始提供的按库并行复制的策略;
-
配置为 LOGICAL_CLICK,表示就是使用类似于 MariaDB 并行复制策略。
对于 LOGICAL_CLICK 这种策略,MySQL 5.7 对其做了优化。说优化之前,我们先看一下之前提到的“事务两阶段提交的细化流程”。
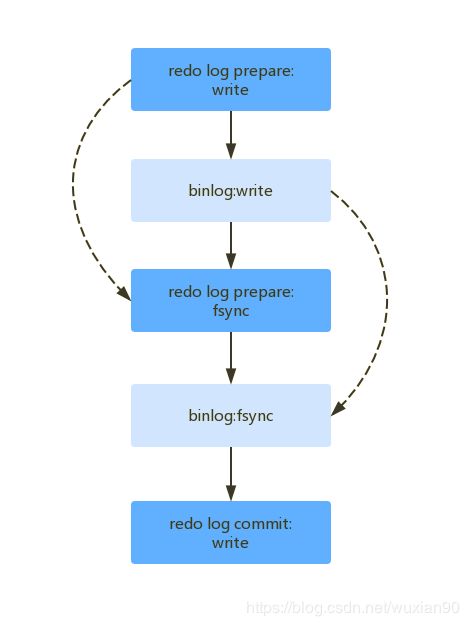
上面提到的 MariaDB 并行复制的核心是:一个组内,已经提交的事务是可以并行的。但是从上面流程可以看出,只要 redo log prepare (第一步)完成之后,事务之间就已经完成冲突检测了。因此 MySQL 5.7 的优化思想如下:
-
同时处于 prepare 阶段的事务是可以并行执行的;
-
处于 prepare 阶段的事务与处于 commit 状态的事务之间,也是可以并行执行的。
前面在 binlog 组提交的时候,介绍了下面 2 个参数:
-
binlog_group_commit_sync_delay 参数:表示延迟多少个微妙之后,再执行 fsync;
-
binlog_group_commit_sync_no_delay_count 参数:表示累计多少次之后,再执行 fsync。
上面 2 个参数是提高组提交里面的事务批量,简单的理解可以是:减慢主库的 binlog 写入,让备库能赶得上。
MySQL5.7.22 的并行复制
在 2018年4月发布的 5.7.22 版本里面,新增了基于 writeset 的并行复制。新增了 binlog-transaction-dependency-tracking,用来控制是否启用这个新策略,这个参数有以下 3 个可选值:
-
COMMIT_ORDER:就是前面提到的处于 prepare 和 commit 状态的 binlog 都可以被分发到 Worker 上面处理;
-
WRITESET:对于事务更新的每一行,都计算出一个 hash 值,组成集合 writeset。如果两个事务的 writeset 没有交集,说明事务没有操作相同的行,事务之间是可以并行的;
-
WRITESET_SESSION:是在 WRITESET 的基础上新增了一个约束,就是在主库上面同一个线程执行的 2 个事务的执行顺序,在从库上面也需要保证顺序性。
可以看出,MySQL 5.7.22 提出的并行复制策略和之前说的按表、按行的并行复制原理类似。另外其还有一些优化点:
-
writeset 是在主库上面生成后直接写到 binlog 里面的,这样在备库执行时,就需要解析 binlog 的内容,节省了很多计算量;
-
不需要把整个事务的 binlog 都扫描一遍后,才决定分发到哪个 Worker,更节省内存;
-
由于备库的分发策略不依赖于 binlog 的内容,因此对 binlog 的格式没有要求。
当然上面所说的并行复制的前提都是,没有外键约束,所有表都有主键的场景。如果不满足,则会退化成单线程的模式。
参考:《极客时间:MySQL实战》、《高性能MySQL》
链接:http://moguhu.com/article/detail?articleId=129