linux系统参数调优
- 说明:以下内容是基于Centos7.x kernel版本为3.10进行测试的结果。
- 一 CPU 参数调优
- 1.1性能模式调整
- 1.2开启服务器超线程功能
- 1.3Numa参数调整
- 二 内存参数调优
- 2.1THP(Transparent HugePages)
- 2.2 ksm调整
- 2.3swappiness调整
- 2.4min_free_kbytes调整
- 2.5 dirtry_ratio
- 2.6 max_map_count
- 三 网络优化
- 3.1 jumbo frames巨型帧
- 3.2 调整网卡的 Rx/Tx传输接收队列大小
- 四 磁盘优化及配置
- 4.1磁盘cache优化及raid配置
- 4.2 块设备调度调整
- 4.3 nvme ssd优化lbaf配置
- 五 其他系统资源调整
说明:以下内容是基于Centos7.x kernel版本为3.10进行测试的结果。
一 CPU 参数调优
1.1性能模式调整
1.1.1作用及影响
调整cpu性能达到最大频率
1.1.2配置调整
可以使用cpupowerutils,默认centos7.x中会安装如果没有安装手动安装
yum install cpupowerutils
cpupower -c all frequency-info #查看cpu所有core的cpufreq信息
cpupower -c all frequency-set -g performance #修改所有core的governor为performance ,默认为powersave模式
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor #查看cpu性能模式
1.2开启服务器超线程功能
1.1.1作用及影响
注意开启超线程的效果是应用相关的,如果应用都是计算密集型的,那么超线程可能会 降低整体性能。
而对于存储来说,适合打开超线程(现在的服务器默认都会开启超线程功能的)
1.1.2配置调整
# cat /proc/cpuinfo | grep flags | tail -1 | grep ht #查看服务器是否开启超线程
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe ...dmidecode -t processor | grep HTT #查看服务器是否开启超线程
关闭或者打开超线程
# vi /etc/grub.conf
OR
# vi /boot/grub/menu.lst
找到以下行,在最后添加noht
kernel /boot/vmlinuz-2.6.8-2-686 root=/dev/hdb1 ro single noht
1.3Numa参数调整
1.3.1作用及影响
Numa是不均匀内存分配, Numa在开启状态下,会出现以下弊端:
当你的服务器还有内存的时候,发现它已经在开始使用 swap 了,甚至已经导致机器出现 停滞的现象,出现性能问题,所以在umstor的配置要求中需要关闭numa。
在os层numa关闭时,打开bios层的numa会影响性能,QPS会下降15-30%;
在bios层面numa关闭时,无论os层面的numa是否打开,都不会影响性能。
1.3.2配置调整
# grep -i numa /var/log/dmesg #检查 numa 是否可用(检测bios层面是否开启numa)
# numactl --hardware #查看 CPU 和 NUMA 配置,需要安装numactl工具(available: 1 nodes (0) #如果是2或多个nodes就说明numa没关掉)
# hwloc-ls #更详细的查看 CPU 拓扑和各级缓存以及共享的资源(包括磁盘)
1)在centos7.x中关闭numa编辑 /etc/default/grub 文件,如下图所示加上:numa=off
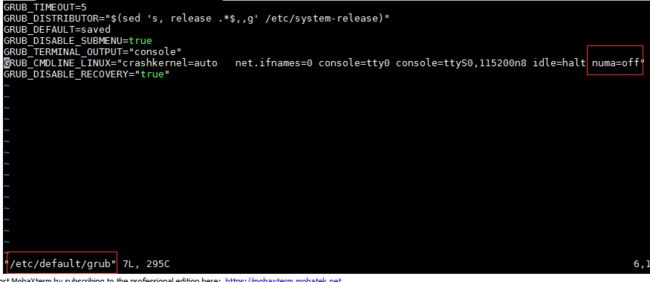
2)重新生成 /etc/grub2.cfg 配置文件:
grub2-mkconfig -o /etc/grub2.cfg
3)重启服务器后,cat /proc/cmdline查os层面禁用numa是否成功
命令行关闭numa.service服务# systemctl disable numa.service
#numactl --interleave=all #关闭numa的限制(临时修改)使用numa
如果要使用numa就需要将固定的osd绑定到对应的numa node上
设置绑定方法如下:方式一:
# numactl --cpunodebind=1 --membind=1 /home/yhg/work/pufa/build/bin/ceph-osd -i 0 -c /home/yhg/work/pufa/build/ceph.conf
查看是否生效:
# for i in $(pgrep ceph-osd) ; do taskset -pc $i ; done
pid 8855's current affinity list: 6-11,18-23
方式二:
修改 /usr/lib/systemd/system/[email protected] 文件,在 [Service] 部分增加如下内容:
CPUAffinity= 6 7 8 9 10 11 18 19 20 21 22 23
systemctl daemon-reload
systemctl restart ceph-osd@osd.$i总结:为避免numa对umstor集群的影响,要关闭numa功能,可以从BIOS,操作系统,启动进程时临时关闭这个特性,最彻底的关闭就是从bios中进行关闭。
二 内存参数调优
2.1THP(Transparent HugePages)
2.1.1作用及影响
对于有些场景 THP 会带来 10% 的性能提升,也带来了两个潜在的风险:
1)内存泄漏
2)大量的 merge/split 内存区域操作消耗大量 CPU,有些应用会有 30% 的性能损失。
Centos7 上默认开启 THP:
2.1.2配置调整
#cat /sys/kernel/mm/transparent_hugepage/defrag #查看THP的状态
# cat /sys/kernel/mm/transparent_hugepage/enabled #查看THP的状态
[always] madvise never #可以看到有三个选项,always是默认选项,nerver是关闭选项。
为了克服上面说到的弊端,可以使用 madvise 选项。该选项让支持 madvise 的程序 继续享受 THP 的好处,又让不支持 madvise 的程序不受影响。
修改成 madvise
修改THP状态的方式:
方式一:我们这个时候当然可以逐个修改上述两文件(defrag和enabled),来禁用THP
方式二:永久性修改
| 编辑rc.local文件: 保存退出,然后赋予rc.local文件执行权限: |
|---|
最后重启系统,以后再检查THP应该就是被禁用了
[root@localhost ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[root@localhost ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
2.2 ksm调整
2.2.1作用及影响
ksm对ceph的作用时反面的,对windows的kvm客户机环境有用,对于rhel的环境应该被disabled
2.2.1配置调整
# systemctl status ksm.service ksmtuned.service
# systemctl stop ksm.service ksmtuned.service
# systemctl disable ksm.service ksmtuned.service
2.3swappiness调整
2.3.1作用及影响
参数值可为 0-100,控制系统 swap 的程序。高数值可优先系统性能,在进程不活跃时 主动将其转换出物理内存。低数值可优先互动性并尽量避免将进程转换处物理内存, 并降低反应延迟。默认值为 60。
swappiness=0 的时候表示最大限度使用物理内存,然后才是 swap空间。
影响:物理内存还比较充足,vm.swappiness已经设置为0,但系统还是用了swap分区
原因:根因是虚拟机machine.slice和系统system.slices、user.slices等使用了swap空间,
通过sysctl -w设置vm.swappiness并不能改变cgroup中machine.slice、system.slices、user.slices等里面对应的memory.swappiness值,这些值继承/sys/fs/cgroup/memory下vm.swappiness的值,当创建子目录后,再创建子目录,此时vm.swappiness的值继承于父目录里对应的vm.swappiness值,因此,在系统运行时,只改变/sys/fs/cgroup/memory这个根目录的值,并不影响已创建子目录的vm.swappiness配置,所以如果需要更改,就要手动操作.
2.3.2配置调整
# sysctl -a |grep swappiness #查看当前值
临时修改
sysctl -w vm.swappiness=0
手动更改/sys/fs/cgroup/memory下子目录对应的memory.swappiness值
永久修改(重启生效,保证值都是新的)
# sysctl -w vm.swappiness=0 #修改swappiness值
echo vm.swappiness = 0 >> /etc/sysctl.conf #永久修改
2.4min_free_kbytes调整
2.4.1作用及影响
将min_free_kbytes设置得太低会阻止系统回收内存。这可能导致系统挂起并杀死多个进程。
但是,将此参数设置为过高的值(占系统总内存的5-10%)将导致系统立即内存不足。
默认为 90112KB。
建议值:
// For 64GB RAM, reserve 1GB.
vm.min_free_kbytes = 1048576
// For 128GB RAM, reserve 2GB.
vm.min_free_kbytes = 2097152
// For 256GB RAM, reserve 3GB.
vm.min_free_kbytes = 3145728
2.4.2配置及调整
# sysctl -a |grep min_free_kbytes #查看当前值
# sysctl -w vm.min_free_kbytes=1048576 #修改min_free_kbytes值
echo vm.min_free_kbytes = 1048576 >> /etc/sysctl.conf #永久修改
2.5 dirtry_ratio
2.5.1作用及影响
| # sysctl -a | grep dirty vm.dirty_background_bytes = 0 vm.dirty_background_ratio = 10 vm.dirty_bytes = 0 vm.dirty_expire_centisecs = 3000 vm.dirty_ratio = 20 vm.dirty_writeback_centisecs = 500 |
|---|
dirty_background_ratio: 是内存可以填充“脏数据”的百分比。这些“脏数据”在稍后是会写入磁盘的,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。举一个例子,我有32G内存,那么有3.2G的内存可以待着内存里,超过3.2G的话就会有后来进程来清理它。
dirty_ratio: 是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘。这是造成IO卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。
dirty_expire_centisecs: 指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 进行起来时,它会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。
dirty_writeback_centisecs: 指定多长时间 pdflush/flush/kdmflush 这些进程会起来一次。
举例:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 80
表示 "后台进行在脏数据达到5%时就开始异步清理,但在80%之前系统不会强制同步写磁盘。这样可以使IO变得更加平滑"
2.5.2配置调整
# sysctl -a |grep dirty_background_bytes #查看当前值
# sysctl -w vm.dirty_background_bytes = 0 #修改min_free_kbytes值
echo vm.dirty_background_bytes = 0 >> /etc/sysctl.conf #永久修改
2.6 max_map_count
2.6.1作用及影响
vm.max_map_count默认为 65530
2.6.2配置调整
# sysctl -a |grep vm.max_map_count #查看当前值
# sysctl -w vm.max_map_count = 65530 #修改min_free_kbytes值
echo vm.max_map_count = 65530>> /etc/sysctl.conf #永久修改
三 网络优化
3.1 jumbo frames巨型帧
3.1.1 作用及影响
根据IEEE 802.3,现在IEEE规定的Ethernet MTU是1500个字节。1500个字节在payload上用完,1500/1542 (1500+26+4+12=1544)= 97.28%是这个限制下最高的利用效率(假设使用802.1Q VLAN tagging )。随着网络的日渐发达,对性能的要求愈加苛刻,人们不满足于1500MTU,所以拥有9000字节payload的Jumbo Frame便应运而生。
使用上,比较重要的一点是,Jumbo Frame在一套系统中的应用,必须是end-to-end的。在网络传输中的每个帧传传输节点中,任何一个节点没能支持同一MTU的Jumbo Frame,那么那一个部分就可能成为整个系统的网络瓶颈——木桶原理,最慢的一环决定了整体的速度。
1)所以首先需要服务器的接入交换机支持jumbo frames(目前,主流交换机厂商的的设备基本都支持)
2)服务器网卡的jumbo frames配置
3.1.2配置调整
临时设置:
# ifconfig eth0 mtu 9000永久配置:
编辑网卡配置文件:vi /etc/sysconfig/network-script/ifcfg-xxx 中添加MTU 9000
重启网络服务:systemctl restart network
查看MTU配置是否生效:ip a |grep mtu
3.2 调整网卡的 Rx/Tx传输接收队列大小
查看当前的队列大小:
# ethtool -g enp131s0f1
Ring parameters for enp131s0f1:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 512
上面表明,硬件支持最多 4096 个 Rx/Tx 等待队列。当前使用了 512 个。
可以增加到 4096 个:
# ethtool -G enp131s0f1 rx 4096 tx 4096
# ethtool -g enp131s0f1
Ring parameters for enp131s0f1:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
调整完成后,大部分网卡驱动会将网卡先 down 掉再启动,该接口上的已有连接也会断掉。
四 磁盘优化及配置
4.1磁盘cache优化及raid配置
见http://idocs.umcloud.com:8090/pages/viewpage.action?pageId=8852959
4.2 块设备调度调整
4.2.1 queue参数
默认的 io 调度队列大小:
# cat /sys/block/sda/queue/nr_requests
128
# cat /sys/block/nvme0n1/queue/nr_requests
1023
调整为大点的值,能增加机械盘执行顺序io的比例,提升整体吞吐。
修改io调度队列大小
echo 1023 /sys/block/sda/queue/nr_requests
4.2.2 io调度器调整
对于 nvme 有:
# cat /sys/block/nvme0n1/queue/scheduler
[none] mq-deadline kyber
对于 hdd:
# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
sata ssd:
# cat /sys/block/sdi/queue/scheduler
noop [deadline] cfq
对于 nvme ssd 来说 mq-deadline 可能是个比较好的选项。
修改调度器:
echo deadline >/sys/block/sda/queue/scheduler
4.3 nvme ssd优化lbaf配置
1. 检查 lbaf 为最优模式
[root@um14 /]# nvme list-ns /dev/nvme0
[ 0]:0x1
[root@um14 /]# nvme id-ns /dev/nvme0 --namespace-id=0x1
NVME Identify Namespace 1:
nsze : 0x2e934856
ncap : 0x2e934856
nuse : 0x2e934856
nsfeat : 0
nlbaf : 3
flbas : 0x2
mc : 0x1
dpc : 0x17
dps : 0
nmic : 0
rescap : 0
fpi : 0
nawun : 0
nawupf : 0
nacwu : 0
nabsn : 0
nabo : 0
nabspf : 0
noiob : 0
nvmcap : 0
nguid : 00000000000000000000000000000000
eui64 : 000cca00611bcc01
lbaf 0 : ms:0 lbads:9 rp:0
lbaf 1 : ms:8 lbads:9 rp:0x2
lbaf 2 : ms:0 lbads:12 rp:0 (in use)
lbaf 3 : ms:8 lbads:12 rp:0x12. 修改 lbaf 示例
[root@um14 /]# nvme format -n 0x1 -l 1 -m 1 -i 1 -s 1 /dev/nvme0n1
Success formatting namespace:1
[root@um14 /]# nvme id-ns /dev/nvme0 --namespace-id=0x1
NVME Identify Namespace 1:
nsze : 0x1749a42b0
ncap : 0x1749a42b0
nuse : 0x1749a42b0
nsfeat : 0
nlbaf : 3
flbas : 0x11
mc : 0x1
dpc : 0x17
dps : 0x1
nmic : 0
rescap : 0
fpi : 0
nawun : 0
nawupf : 0
nacwu : 0
nabsn : 0
nabo : 0
nabspf : 0
noiob : 0
nvmcap : 0
nguid : 00000000000000000000000000000000
eui64 : 000cca00611bcc01
lbaf 0 : ms:0 lbads:9 rp:0
lbaf 1 : ms:8 lbads:9 rp:0x2 (in use)
lbaf 2 : ms:0 lbads:12 rp:0
lbaf 3 : ms:8 lbads:12 rp:0x1
五 其他系统资源调整
用sysctl -a 查看以下参数
最大进程描述符个数
// 默认为 32768
# sysctl -w kernel.pid_max=4194303
永久调整需要写到配置文件中echo kernel.pid_max=4194303>>/etc/sysctl.conf最大线程个数
# sysctl -w kernel.threads-max=2097152
永久调整需要写到配置文件中echo kernel.threads-max=2097152 >>/etc/sysctl.conf
系统异步 I/O 上下文中可允许的最多事件数
// 默认为 65535
# sysctl -w fs.aio-max-nr=1048576
永久调整需要写到配置文件中echo fs.aio-max-nr=1048576 >>/etc/sysctl.conf查看当前系统的 aio 请求个数
# cat /proc/sys/fs/aio-nr