【NLP CS224N笔记】Lecture 13 - Contextual Word Representations and Pretraining
本次梳理基于Datawhale 第12期组队学习 -CS224n-预训练模块
详细课程内容参考(2019)斯坦福CS224n深度学习自然语言处理课程
1. 写在前面
自然语言处理( NLP )是信息时代最重要的技术之一,也是人工智能的重要组成部分。NLP的应用无处不在,因为人们几乎用语言交流一切:网络搜索、广告、电子邮件、客户服务、语言翻译、医疗报告等。近年来,深度学习方法在许多不同的NLP任务中获得了非常高的性能,使用了不需要传统的、任务特定的特征工程的单个端到端神经模型。 而【NLP CS224N】是入门NLP的经典课程, 所以这次借着Datawhale组织的NLP学习的机会学习这门课程, 并从细节层面重新梳理NLP的知识。
今天是组队学习的第四篇文章, 主要内容是基于上下文的词向量表示及一些预训练的模型, 这次会整理2018年以后的一些新的模型, 比如ELMO,Transformer, GPT, BERT等, 这些模型在NLP领域是非常重要的, 虽然NLP领域的模型迭代更新速度很快,但是通过这四篇文章,已经基本上能把模型发展的这个脉络梳理清楚, 这篇文章会主要介绍ELMO, Transformer, GPT, BERT这四个模型的原理, 但是在这之前, 还是想结合前面的三篇文章再做一个梳理,这样就能把知识串起来, 也能看清楚这些模型为什么会出现? 究竟要解决什么样的问题?
因为这块我也是刚接触, 加上这两天有些事情, 所以也没有花太多时间去仔细研究每个模型,所以这里只能先整理个大概, 后期随着对模型的使用再进行补充哈.
大纲如下:
- 开始之前,我们先简单梳理
- ELMO模型
- Transformer
- GPT
- BERT
Ok, let’s go!
2. 开始之前,先简单梳理
到目前为止我们已经学习了一些模型, 也见过了一些很常见的名词, 像什么One-Hot, Word2Vec, Skip-gram, CBOW, Hierarchical softmax,Negative Sample, Count-Based Model, SVD,Glove, Character-level Model, Subwords Model(BPE), Hybrid Mode, FastText。
什么? 有点上头? 好吧, 为了能愉快的学习今天的内容, 下面简单的梳理一下上面的逻辑, 学习语言处理嘛, 自然开始的时候我们就是想让计算机更好的理解单词或者是句子, 这样才能帮助我们去分析, 那么如何才能让计算机更好的理解单词或者句子呢? 于是我们开始就需要对单词进行表示, 最开始的时候用的就是One-Hot编码, 一个1其余全是0, 1表示的是某个单词在词典里面的位置, 但是这种编码方式显然看不出词与词之间的相关性鸭, 于是乎就有了词向量的一些模型, 把单词表示成固定的词向量。 三大词向量表征技术就是Word2Vec, Glove, FastText。 Word2Vec是一种求单词词向量的技术之一, 思想是通过中心词和上下文词的关系去求取词向量, 这样的话寻思着就能表示词与词之间的关系了嘛。 于是乎基于Word2vec, 出现了两种能够实现的这种技术的方式, 也就是Skip-gram和CBOW, 前者是通过中心词去预测上下文, 后者是通过上下文去预测中心词。 但是这两个算法存在计算量很大的问题,因为在做一个Softmax多分类的问题, 而类别竟然是词库的大小,这就不行了, 所以基于这俩模型后面又提出了两种高级的训练方式,那就是Hierarchical softmax和Negative Sample, 前者是引入了哈夫曼树去学习隐藏层到输出的映射关系,把计算量降下来, 而后者是把中心词和上下文词进行配对把多分类转换成K个二分类问题,从而减少计算量,这样Word2Vec这里的关系就是这些了。
既然是学习词向量, 肯定不止是Word2Vec这一种方式, 还有一种方式是直接基于统计, 认为一般越相关的单词在一次出现的频率就会越高, 那么就数数呗, 统计一下每个单词之间的共现频率, 用这个作为词向量, 于是乎就出现了Count-Based模型, 而SVD模型就是这里面的代表, 这个是利用了共现矩阵和SVD降维技术去得到词向量, 但是这种方法的一个弊端就是无法学习到词语背后的含义, 好处是利用了统计信息, Word2Vec是学习到词语背后的含义, 但是统计信息, 那么把它俩的思想结合一下会怎样? 这就是Glove了,在word-word co-occurrence count的基础上学习到词语背后的含义。 到这里, 就把基于词学习词向量的方法梳理了一下。
上面讨论的表征词的这些算法和模型都是基于单词作为基本单位的, 也就是我们会先事先计算出每个单词的词向量表示, 但是这种以单词为单位的模型不能很好的解决out-of-vocabulary(不在词库)的单词。且对于单词的一些词法上的修饰处理的也不是很好。 所以后面的想法就是能够利用比word更细粒度为单位来建立模型,以更好的解决这些问题。一种思路就是字符作为基本的单位, 建立Character-level model, 后来又感觉这个太细了,于是就有了从字符和单词之间找一个折中, 就是subwords Model, 而后来的混合模型是词级模型和字符级模型的一个组合, 这个采用的思路是大多数情况下还是采用word level模型,而只在遇到OOV的情况才采用character level模型, 后来就出现了FastText,这个和CBOW相似,只不过综合了上面的一些好思路, 训练的时候既有词也有子词。
上面就是我们之前的词向量表征技术, 具体的可以参考前面的几篇笔记。这些技术是静态训练词向量的方法, 也就是在数据集上训练好一个语言模型之后,每一个词的词向量就固定下来了。后续使用词向量时,无论输入的句子是什么,词向量都是一样的 。 但是, 这样有什么问题呢? 就是无法表示一词多义的问题, 我们知道一个单词可能有多个含义,比如“apple”, 有苹果的意思, 有公司的意思, 那么我们前面训练的词向量中apple会只有一个含义,这样就不能很好的表示一词多义,因为这种单词具体什么意义应该具体看上下文才能知道。 于是乎, 后面就出现了动态训练词向量的方法, 这种方法是在训练语言模型, 而单词的词向量是在输入句子实时获得的,因此词向量与上下文信息密切相关,可以较好地区分歧义。比较典型的ELMO, GPT, BERT。下面就是看看这几个模型了。
3. ELMO模型
ELMO是“Embedding from Language Models"简称。本质思想是:事先用一个语言模型去学习单词的word embedding, 当我在使用时,单词已经具备了特定的上下文,这时候可以根据上下文的语义去调整单词的word embedding, 这样经过调整的word embedding更能表达这个上下文中具体的含义,也就解决了一词多义问题,故ELMO本质就是根据当前上下文对Word Embedding进行动态调整的过程。
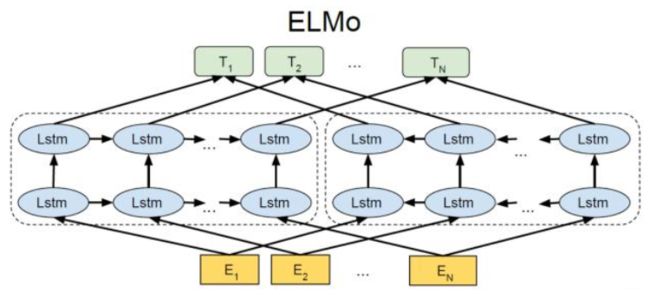
Elmo采用典型的两阶段过程:第一阶段使用预训练语言模型进行训练,第二阶段当做具体的下游任务时,从预训练的网络中提取对应的词的Word Embedding作为特征补充到下游任务中。
-
第一阶段,预训练:采用双层双向LSTM对上下文进行编码,上下文使用静态的word embedding, 对每层LSTM,将上文向量与下文向量进行拼接作为当前向量,利用大量的预料训练这个网络。对于一个新的句子,可以有三种表示,最底层的word embedding, 第一层的双向LSTM层的输出,这一层能学习到更多句法特征,第二层的双向LSTM的输出,这一层能学习到更多词义特征。经过elmo训练,不仅能够得到word embedding, 又能学习到一个双层双向的神经网络。
-
第二阶段,下游任务使用:将一个新的句子作为elmo预训练网络的输入,这样该句子在elmo网络中能获得三个embedding, 可以将三个embedding加权作为word embedding, 并将此作为下游任务的输入,这被称为“Feature-based Pre-Training"。
上面就是ELMO模型的宏观工作原理, 下面开始微观解释, 要想弄明白ELMO, 需要需要RNN和LSTM的基础, 这个我已经准备好了, 点击链接就能走进RNN的世界。下面再说点前向lstm语言模型基础, 给定一串长度为N的词条 ( t 1 , t 2 , … , t N ) (t_1,t_2,…,t_N) (t1,t2,…,tN),前向语言模型通过对给定历史 ( t 1 , … t k − 1 ) (t_1,…t_{k−1}) (t1,…tk−1)预测 t k t_k tk进行建模:
p ( t 1 , t 2 , . . . t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . t k − 1 ) p(t_1, t_2, ...t_N) = \prod_{k=1}^{N} p(t_k|t_1, t_2, ...t_{k-1}) p(t1,t2,...tN)=k=1∏Np(tk∣t1,t2,...tk−1)
下面举个栗子看看前向传播的微观细节:

以“the cat sat on the mat”这句话为例。在某一个时刻 k k k时,输入为the,输出cat的概率。过程是这里面包含了几步
- 将the转换成word embedding。也就是 n ∗ 1 n*1 n∗1维的列向量,
- 将上一时刻的输出 h k − 1 h_{k−1} hk−1及第一步中的word embedding一并送入lstm,并得到输出当前隐状态 h k h_k hk。这是一个 m ∗ 1 m*1 m∗1维的列向量。 m m m是LSTM隐藏单元的个数。这个 h k h_k hk与后面的elmo向量有着直接的关系
- 将lstm的输出 h k h_k hk,与上下文矩阵 W ′ W' W′相乘,即 W ′ ∗ h k W'*h_k W′∗hk得到一个列向量,再将该列向量经过softmax归一化。其中,假定数据集有 V V V个单词, W ′ W' W′是 ∣ V ∣ ∗ m |V|*m ∣V∣∗m的矩阵, h k h_k hk是 m ∗ 1 m*1 m∗1的列向量,于是最终结果是 ∣ V ∣ ∗ 1 |V|*1 ∣V∣∗1的归一化后向量,即从输入单词得到的针对每个单词的概率。我们是想让它输出cat的概率最大, 所以就会有损失, 然后就可以更新参数。 差不多。
这就是前向lstm语言模型的工作流程了。其实很多神经网络语言模型都很类似。而ELMO在这个基础上做了一点改进, 第一个改进就是用了多层的LSTM, 第二个改进是增加了后向的LSTM, 也就是每一层改成了双向的LSTM。后向LSTM的计算公式:
p ( t 1 , t 2 , . . . t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . t N ) p(t_1, t_2, ...t_N) = \prod_{k=1}^{N} p(t_k|t_{k+1}, t_{k+2}, ...t_{N}) p(t1,t2,...tN)=k=1∏Np(tk∣tk+1,tk+2,...tN)
而bidirectional LSTM就是将两者结合起来,其目标是最大化:

前向传播过程与上面单向的类似, 无非这个地方换成了双向的LSTM。对于 k k k位置的标记,ELMO模型用 2 L + 1 2L+1 2L+1个向量来表示,其中1个是不依赖于上下文的表示,而是当前输入单词的词向量 x k L M x_k^{LM} xkLM。 L L L层forward LSTM每层会产生一个依赖于上文的表示 h ⃗ k L M \vec{h}_k^{LM} hkLM ,同样的,L层backward LSTM每层会产生一个依赖于下文的表示 h k L M ← \mathop{h_k^{LM}} \limits ^{\leftarrow} hkLM←,我们可以将他们一起简计为
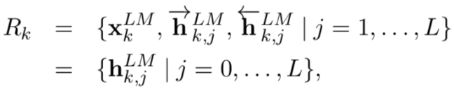
得到每层的embedding后,对于每个下游的任务,我们可以计算其加权的表示:
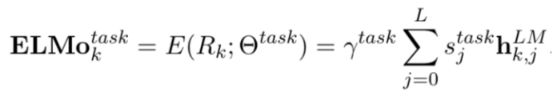
这里的 s j t a s k s_j^{task} sjtask是每一层的softmax归一化的权重, γ t a s k \gamma^{task} γtask是引入的可调控的scale parameter。最后单词的词向量是这个ELMO向量和单词的词向量的拼接 [ x k ; E L M o k t a s k ] [x_k;ELMo_k^{task}] [xk;ELMoktask]
具体的前向传播过程(先放张图片, 后期再改格式):

4. GPT
GPT是Generative Pre-Training的简称。与ELMO相似,采用两阶段的模式:利用语言模型进行预训练,通过fine-tuning模式应用到下游任务。
说到这里, 想先解释一下什么是预训练, 所谓预训练,就是先在某个任务(训练集A或者B)进行预先训练,即先在这个任务(训练集A或者B)学习网络参数,然后存起来以备后用。当我们在面临第三个任务时,网络可以采取相同的结构,在较浅的几层,网络参数可以直接加载训练集A或者B训练好的参数,其他高层仍然随机初始化。底层参数有两种方式:frozen,即预训练的参数固定不变,fine-tuning,即根据现在的任务调整预训练的参数。
与elmo不同的是,GPT使用transformer进行提取特征,并且是单向的transformer,只是根据上文来预测某个词。

其他的计算过程, 基本上和ELMO一致了, 关键就是在这个Transformer。
5. Transformer
Transformer的结构长下面这样:

这种结构呢,是完全依赖注意力机制来刻画输入和输出之间的全局依赖关系,而不使用递归运算的RNN网络了。这样的好处就是第一可以有效的防止RNN存在的梯度消失的问题,第二是允许所有的字全部同时训练(RNN的训练是迭代的,一个接一个的来,当前这个字过完,才可以进下一个字),即训练并行,大大加快了计算效率。并且Transformer使用了位置嵌入来理解语言的顺序,使用了多头注意力机制和全连接层等进行计算。 关于Transformer, 这里就不详细说了, 同样的准备了很详细的文章自然语言处理之Attention大详解(Attention is all you need).
6. BERT
BERT原理与GPT有相似之处,不过它利用了双向的信息,因而其全称是Bidirectional Encoder Representations from Transformers。

BERT创新: Masked语言模型和Next Sentence Prediction。
- Masked语言模型, 即随机选择一部分单词进行mask,然后预测这些单词,其方式和CBOW类似,为了解决fine-tuning阶段不需要mask,所以bert中只选择15%作为mask的候选,在这15%中80%用mask处理,10%保持原来的词,10%进行随机替换【不太理解为什么成立】
- next sentence prediction:之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。
BERT的输入: 输入的部分是个线性序列,两个句子之间使用sep进行分割,在开头和结尾分别加一个特殊字符。对于每一个字符都是由三种embedding组成,位置信息embedding, 单词embedding和句子embdding,三种embedding叠加便是bert的输入。
下面是一个小总结:

7. 总结
这篇文章简单总结一下,就是介绍了最近出现的一些模型了, 比如ELMO, GPT还有BERT, 当然这次由于时间原因, 后面几个没有好好的写, 其实BERT这块还有很多的细节, 后期会补上, BERT这块还是应该好好整理的, 这次确实手头有些要紧的事情, 所以还是先打卡。 后期再补吧。
参考
- ELMo原理解析及简单上手使用
- 动态词向量算法 — ELMo
- 预训练中Word2vec,ELMO,GPT与BERT对比
- CS224N笔记(十三):ELMO, GPT与BERT
- CS224N(13)-词向量的上下文表征及预训练\
- 13 Modeling contexts of use Contextual Representations and Pretraining
- BERT详解