android 4.4 按键分析二
3. 框架介绍
在分析按键处理过程中,我们要先准一些基础知识,才能看懂事件处理流程。实际分析时,也可以先不用详细看这些知识,等需要时再回头分析。
3.1 Input子系统
3.1.1 基本介绍
Input子系统处理输入事务,任何输入设备的驱动程序都可以通过Input输入子系统提供的接口注册到内核,利用子系统提供的功能来与用户空间交互。输入设备一般包括键盘,鼠标,触摸屏等,在内核中都是以输入设备出现的。下面分析input输入子系统的结构,以及功能实现。
Input子系统是分层结构的,从下到上由三层实现总共分为三层: 硬件驱动层,子系统核心层(Input Core),事件处理层(Event Handler)。
(1)其中硬件驱动层负责操作具体的硬件设备,这层的代码是针对具体的驱动程序的,需要驱动程序的作者来编写,主要实现对硬件设备的读写访问,中断设置,并把硬件产生的事件转换为核心层定义的事件类型。
(2)子系统核心层是链接其他两个层之间的纽带与桥梁,向下提供驱动层的接口,向上提供事件处理层的接口,为设备驱动层提供了规范和接口。
(3)事件处理层负责与用户程序打交道,是用户编程的接口(设备节点),将下层传来的事件报告给用户程序。
其关系如下图所示:
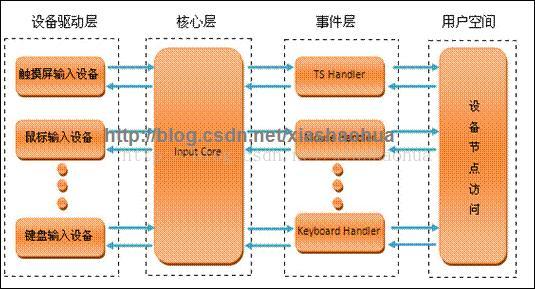
/dev/input目录下显示的是已经注册在内核中的设备编程接口,用户通过open这些设备文件来打开不同的输入设备进行硬件操作。在android系统中,我们后续会分析到,这里对应到frameworks/base/services/EventHub.cpp,属于用户空间的framework层代码。
事件处理层为不同硬件类型提供了用户访问及处理接口。例如当我们打开设备/dev/input/event0时,会调用到事件处理层的Keypad Handler来处理输入事件,这也使得设备驱动层无需关心设备文件的操作,因为Keypad Handler已经有了对应事件处理的方法。Linux中在用户空间将所有的设备都当初文件来处理,由于在一般的驱动程序中都有提供fops接口,以及在/dev下生成相应的设备文件nod,这些操作在输入子系统中由事件处理层完成。
输入子系统核心层由内核代码drivers/input/input.c构成,它的存在屏蔽了用户到设备驱动的交互细节,为设备驱动层和事件处理层提供了相互通信的统一界面。
下图从事件处理角度也解释了这个框架结构:
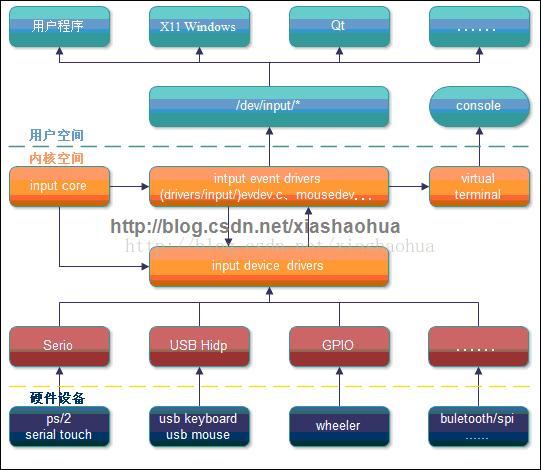
首先我们看驱动的设备,linux中input系统主设备号是13
次设备号:
0-31 joystick(游戏杆)
32-62 mouse(鼠标)
63 mice(鼠标)
64-95 事件(Event)设备
再看事件,设备所能表示的事件种类如下,一个设备可以选择一个或多个事件类型上报给输入子系统。所以,在驱动加载模块中,设置input设备支持的事件类型,
EV_SYN 0x00 同步事件
EV_KEY 0x01 按键事件
EV_REL 0x02 相对坐标(如:鼠标移动,报告相对最后一次位置的偏移)
EV_ABS 0x03 绝对坐标(如:触摸屏或操作杆,报告绝对的坐标位置)
EV_MSC 0x04 其它
EV_SW 0x05 开关
EV_LED 0x11 按键/设备灯
EV_SND 0x12 声音/警报
EV_REP 0x14 重复
EV_FF 0x15 力反馈
EV_PWR 0x16 电源
EV_FF_STATUS 0x17 力反馈状态
EV_MAX 0x1f 事件类型最大个数和提供位掩码支持
各层之间通信的基本单位就是事件,任何一个输入设备的动作都可以抽象成一种事件,如键盘的按下,触摸屏的按下,鼠标的移动等。事件有三种属性:类型(type),编码(code),值(value),Input子系统支持的所有事件都定义在input.h中,包括所有支持的类型,所属类型支持的编码等。
事件传送的方向是 硬件驱动层-->子系统核心-->事件处理层-->用户空间
设备有着自己特殊的按键键码,需要将物理按键比如0-9,X-Z等模拟成标准按键EY_0,KEY-Z等,所以需要用到按键转化,具体方法就是操作/dev/input/event1文件,向它写入个input_event结构体就可以模拟按键的输入了。
linux/input.h中有定义,这个文件还定义了标准按键的编码等
struct input_event {
struct timeval time; //按键时间
__u16 type; //类型,在下面有定义
__u16 code; //要模拟成什么按键
__s32 value;//是按下还是释放
};
code:事件的代码.如果事件的类型代码是EV_KEY,该代码code为设备键盘代码.代码植0~127为键盘上的按键代码,0x110~0x116 为鼠标上按键代码,其中0x110(BTN_ LEFT)为鼠标左键,0x111(BTN_RIGHT)为鼠标右键,0x112(BTN_ MIDDLE)为鼠标中键.其它代码含义请参看include/linux/input.h文件. 如果事件的类型代码是EV_REL,code值表示轨迹的类型.如指示鼠标的X轴方向REL_X(代码为0x00),指示鼠标的Y轴方向REL_Y(代码 为0x01),指示鼠标中轮子方向REL_WHEEL(代码为0x08).
value:事件的值.如果事件的类型代码是EV_KEY,当按键按下时值为1,松开时值为0;如果事件的类型代码是EV_ REL,value的正数值和负数值分别代表两个不同方向的值.
type: Event types,就是上面提到的事件类型。
Input子系统的三个重要结构体:
input_dev 是硬件驱动层,代表一个input设备
input_handle属于核心层,代表一个配对的input设备与input事件处理器
input_handler 是事件处理层,代表一个事件处理器
实现设备驱动主要工作是:向系统报告按键、触摸屏等输入事件(event,通过input_event结构描述),不再需要关心文件操作接口。驱动报告事件经过inputCore和Eventhandler到达用户空间。
在内核中,input_dev表示一个 input设备;input_handler来表示input设备的 interface。所有的input_dev用双向链表 input_dev_list连起来。在调用 int input_register_device(struct input_dev *dev)的时候,会将新的 input_dev加入到这个链表中。
所有的input_handler 用双向链表 input_handler_list连起来。在调用 int input_register_handler(struct input_handler *handler)的时候,会将新的 input_handler加入到这个链表中。每个input_dev和 input_handler是要关联上才能工作的,在注册 input_dev或者 input_handler的时候,就遍历上面的列表,找到相匹配的,然后调用 input_handler的 connect函数来将它们联系到一起。
通常在input_handler的 connect函数中,就会创建 input_handle, input_handle就是负责将 input_dev和input_handler联系在一起的.
对应input子系统的各层的具体分析我们暂不做介绍。因为android基于linux,所以我们依次了解android的大致框架,便于后面章节就android的分析有一个整体上的认识。。
3.1.2 Android按键处理框架
在详细介绍android键盘处理流程前,我们先借用后面分析的结论,给出按键流程的框架关系图,先有一个整体的认识:
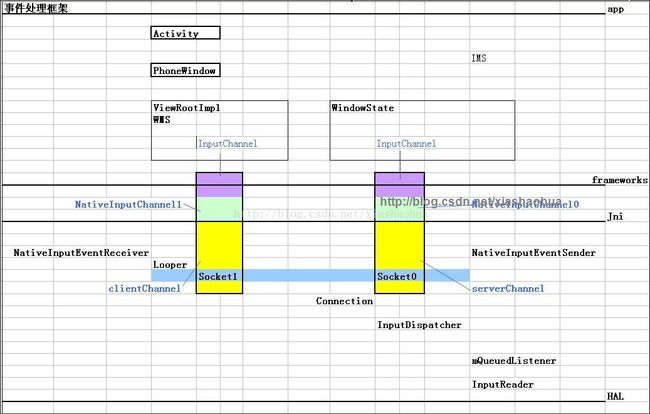
上面的图从Driver、HAL、Jni、Frameworks、app的角度列出了按键处理经历各层里面各个模块的关系,Driver部分暂不介绍,我们知道事件由那里起源即可。
之后在HAL层通过InputReader和InputDispatcher对应的两个线程,维护事件在HAL层的处理;
然后通过socket承载的管道,完成事件的跨进程,将事件通知到jni对应的进程,这里有NativeInputEventReceiver和NativeInputEventSender,完成事件在jni的处理,里面有其消息循环Looper和消息队列;
在通过Jni技术,将事件转化为Java事件,在Frameworks里面进行处理,这里的处理比较复杂,有较多的InputStage;
最后到应用程序界面对应的Activity。
另外,图中带颜色的色块表示两个虚拟通道,不同的颜色表示通道在不同层之间,蓝色的文字说明在这些层里面通道的相应名字。
紫色表示通道在Framework层,可以通过InputChannel来指示它或找到它;
粉绿表示通道在Jni层,可以通过NativeInputChannel来表示它;
黄色表示通道在HAL层,可以通过clientInputChannel或ServerInputChannel来表示它,并且黄色是基于socket承载的。
另外,不同层的通道是相互关联的,所以用不同颜色来虚拟成一个通道。
3.2 Epoll机制
随着2.6内核对epoll的完全支持,网络上很多的文章和示例代码都提供了这样一个信息:使用epoll代替传统的poll能给网络服务应用带来性能上的提升。但大多文章里关于性能提升的原因解释的较少,这里我将试分析一下内核(2.6.21.1)代码中poll与epoll的工作原理,然后再通过一些测试数据来对比具体效果。
POLL:
先说poll,poll或select为大部分Unix/Linux程序员所熟悉,这俩个东西原理类似,性能上也不存在明显差异,但select对所监控的文件描述符数量有限制,所以这里选用poll做说明。
poll是一个系统调用,其内核入口函数为sys_poll,sys_poll几乎不做任何处理直接调用do_sys_poll,do_sys_poll的执行过程可以分为三个部分:
1,将用户传入的pollfd数组拷贝到内核空间,因为拷贝操作和数组长度相关,时间上这是一个O(n)操作,这一步的代码在do_sys_poll中包括从函数开始到调用do_poll前的部分。
2,查询每个文件描述符对应设备的状态,如果该设备尚未就绪,则在该设备的等待队列中加入一项并继续查询下一设备的状态。查询完所有设备后如果没有一个设
备就绪,这时则需要挂起当前进程等待,直到设备就绪或者超时,挂起操作是通过调用schedule_timeout执行的。设备就绪后进程被通知继续运行,这时再次遍历所有设备,以查找就绪设备。这一步因为两次遍历所有设备,时间复杂度也是O(n),这里面不包括等待时间。相关代码在do_poll函数中。
3,将获得的数据传送到用户空间并执行释放内存和剥离等待队列等善后工作,向用户空间拷贝数据与剥离等待队列等操作的的时间复杂度同样是O(n),具体代码包括do_sys_poll函数中调用do_poll后到结束的部分。
EPOLL:
接下来分析epoll,与poll/select不同,epoll不再是一个单独的系统调用,而是由epoll_create/epoll_ctl/epoll_wait三个系统调用组成,后面将会看到这样做的好处。
先来看sys_epoll_create(epoll_create对应的内核函数),这个函数主要是做一些准备工作,比如创建数据结构,初始化数据并最终返回一个文件描述符(表示新创建的虚拟epoll文件),这个操作可以认为是一个固定时间的操作。
epoll是做为一个虚拟文件系统来实现的,这样做至少有以下两个好处:
1,可以在内核里维护一些信息,这些信息在多次epoll_wait间是保持的,比如所有受监控的文件描述符。
2, epoll本身也可以被poll/epoll;
具体epoll的虚拟文件系统的实现和性能分析无关,不再赘述。
在sys_epoll_create中还能看到一个细节,就是epoll_create的参数size在现阶段是没有意义的,只要大于零就行。
接着是sys_epoll_ctl(epoll_ctl对应的内核函数),需要明确的是每次调用sys_epoll_ctl只处理一个文件描述符,这里主
要描述当op为EPOLL_CTL_ADD时的执行过程,sys_epoll_ctl做一些安全性检查后进入ep_insert,ep_insert里将
ep_poll_callback做为回掉函数加入设备的等待队列(假定这时设备尚未就绪),由于每次poll_ctl只操作一个文件描述符,因此也可以
认为这是一个O(1)操作
ep_poll_callback函数很关键,它在所等待的设备就绪后被系统回掉,执行两个操作:
1,将就绪设备加入就绪队列,这一步避免了像poll那样在设备就绪后再次轮询所有设备找就绪者,降低了时间复杂度,由O(n)到O(1);
2,唤醒虚拟的epoll文件;最后是sys_epoll_wait,这里实际执行操作的是ep_poll函数。该函数等待将进程自身插入虚拟epoll文件的等待队列,直到被唤醒(见上面ep_poll_callback函数描述),最后执行ep_events_transfer将结果拷贝到用户空间。由于只拷贝就绪设备信息,所以这里的拷贝是一个O(1)操作。
还有一个让人关心的问题就是epoll对EPOLLET的处理,即边沿触发的处理,粗略看代码就是把一部分水平触发模式下内核做的工作交给用户来处理,直觉上不会对性能有太大影响,感兴趣的朋友欢迎讨论。
POLL/EPOLL对比:
表面上poll的过程可以看作是由一次epoll_create/若干次epoll_ctl/一次epoll_wait/一次close等系统调用构成,
实际上epoll将poll分成若干部分实现的原因正是因为服务器软件中使用poll的特点(比如Web服务器):
1,需要同时poll大量文件描述符;
2,每次poll完成后就绪的文件描述符只占所有被poll的描述符的很少一部分。
3,前后多次poll调用对文件描述符数组(ufds)的修改只是很小;
传统的poll函数相当于每次调用都重起炉灶,从用户空间完整读入ufds,完成后再次完全拷贝到用户空间,另外每次poll都需要对所有设备做至少做一次加入和删除等待队列操作,这些都是低效的原因。
epoll将以上情况都细化考虑,不需要每次都完整读入输出ufds,只需使用epoll_ctl调整其中一小部分,不需要每次epoll_wait都执
行一次加入删除等待队列操作,另外改进后的机制使的不必在某个设备就绪后搜索整个设备数组进行查找,这些都能提高效率。另外最明显的一点,从用户的使用来
说,使用epoll不必每次都轮询所有返回结果已找出其中的就绪部分,O(n)变O(1),对性能也提高不少。
此外这里还发现一点,是不是将epoll_ctl改成一次可以处理多个fd(像semctl那样)会提高些许性能呢?特别是在假设系统调用比较耗时的基础上。不过关于系统调用的耗时问题还会在以后分析
3.3 Pipe
在进程之间通信的最简单的方法是通过一个文件,其中有一个进程写文件,而另一个进程从文件中读,这种方法比较简单,其优点体现在:
只要进程对该文件具有访问权限,那么,两个进程间就可以进行通信。
进程之间传递的数据量可以非常大。
尽管如此,使用文件进行进程间通信也有两大缺点:
·空间的浪费。写进程只有确保把新数据加到文件的尾部,才能使读进程读到数据,对长时间存在的进程来说,这就可能使文件变得非常大。
·时间的浪费。如果读进程读数据比写进程写数据快,那么,就可能出现读进程不断地读文件尾部,使读进程做很多无用功。
要克服以上缺点而又使进程间的通信相对简单,管道是一种较好的选择。
所谓管道,是指用于连接一个读进程和一个写进程,以实现它们之间通信的共享文件,又称pipe文件。向管道(共享文件)提供输入的发送进程(即写进程),以字符流形式将大量的数据送入管道;而接受管道输出的接收进程(即读进程),可从管道中接收数据。由于发送进程和接收进程是利用管道进行通信的,故又称管道通信。这种方式首创于Unix系统,因它能传送大量的数据,且很有效,故很多操作系统都引入了这种通信方式,Linux也不例外。
为了协调双方的通信,管道通信机制必须提供以下三方面的协调能力:
·互斥。当一个进程正在对pipe进行读/写操作时,另一个进程必须等待。
·同步。当写(输入)进程把一定数量(如4KB)数据写入pipe后,便去睡眠等待,直到读(输出)进程取走数据后,再把它唤醒。当读进程读到一空pipe时,也应睡眠等待,直至写进程将数据写入管道后,才将它唤醒。
·对方是否存在。只有确定对方已存在时,方能进行通信。
在Linux中,管道是一种使用非常频繁的通信机制。从本质上说,管道也是一种文件,但它又和一般的文件有所不同,管道可以克服使用文件进行通信的两个问题,具体表现为:
·限制管道的大小。实际上,管道是一个固定大小的缓冲区。在Linux中,该缓冲区的大小为1页,即4K字节,使得它的大小不象文件那样不加检验地增长。使用单个固定缓冲区也会带来问题,比如在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据被读取,以便腾出足够的空间供write()调用写。
·读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件结束的问题。
注意:从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛弃,释放空间以便写更多的数据。
一个普通的管道仅可供具有共同祖先的两个进程之间共享,并且这个祖先必须已经建立了供它们使用的管道。
关于管道的详细分析可参考专门的资料。
3.4 Socket
参考Linux内核源代码情景分析。