推荐系统中的深度匹配模型总结
深度匹配模型
- 基于表示学习的深度匹配模型
- 基于协同过滤的方法
- CF模型
- 深度矩阵分解模型(Deep Matrix Factorization)
- collaborative Denosing Auto-Encoder模型
- 基于CF方法的深度模型总结
- 基于CF+side info的方法
- Deep collaborative Filering
- Attentive Collaborative Filtering
- Collaborative Knowledge Base Embedding
- 基于表征的深度匹配方法总结
- 基于match function learning的深度匹配模型
- CF-based model
- 基于神经网络的协同过滤(Neural collaborative filtering )
- 基于translation框架的方法
- LRML模型
- feature-based 的深度模型
- wide & deep 模型
- DeepFM
- AFM模型(Attention Factorization Machines)
- AutoInt(Auto Feature Interaction)
基于表示学习的深度匹配模型
这种方法分别学习user和item的embedding向量,然后通过matching score如向量內积、cosine距离函数来得到匹配分数,构建如下图所示。
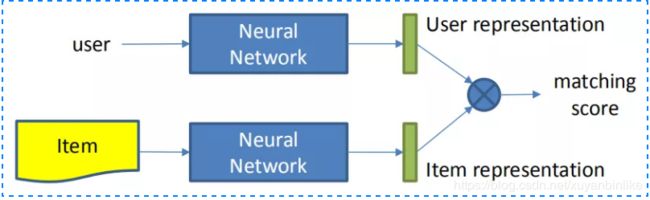
基于表示学习的方法主要有基于协同过滤(CF)以及CF+上下文信息的方法。
基于协同过滤的方法
CF模型
主要分为user-based、item-based和model-based三类。
- 输入层:userid、itemid
- 表征函数: 线性embedding层
- 匹配函数:向量內积
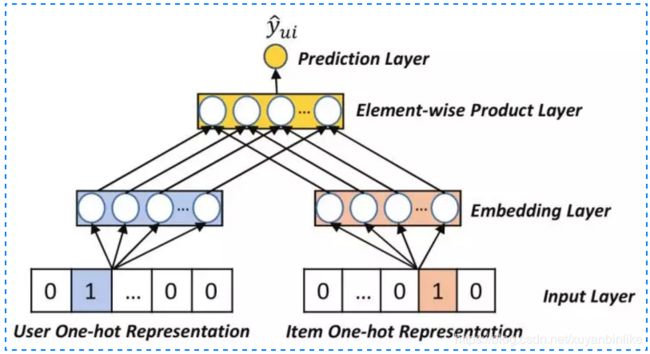
深度矩阵分解模型(Deep Matrix Factorization)
- 输入层:user由交互过的item表示,item由交互过的user表示,都是multi-hot表示。
- 表征函数:MLP,全连接网络。
- 匹配评分函数:cosine。
collaborative Denosing Auto-Encoder模型
- 输入层:用户id,用户交互过的item以及itemid
- 表征函数:
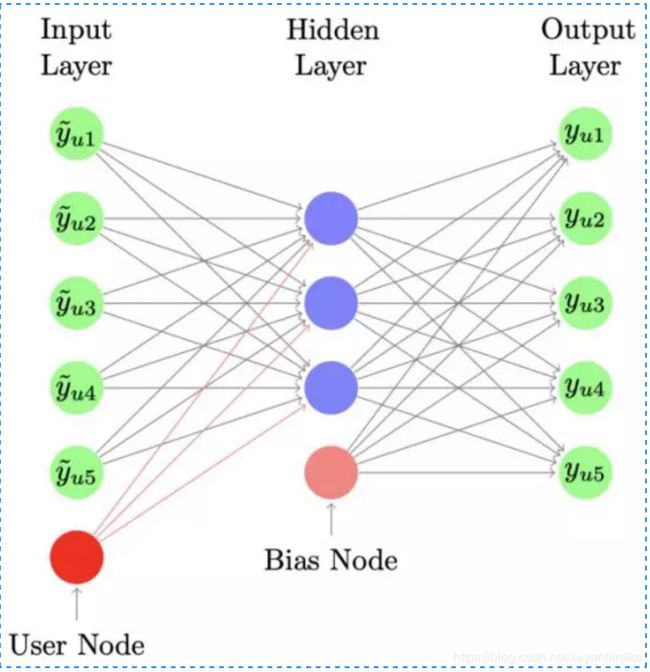
从输入-隐藏层,会针对用户id学习一个和item无关的Vu表示,该向量可以很好地刻画不同用户之间的评分喜好差异。
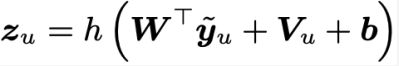
对于输出节点,可以认为是用户u对物品i的打分预测:
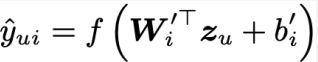
- 匹配评分函数:向量內积。
基于CF方法的深度模型总结
这类方法有如下几个特点:
- User或Itemi ID要么由本身id表达,要么使用其历史交互信息来表示,用历史交互信息来表示的效果较好。
- 模型训练过程中仅用到user-item的交互信息,未引入side info。
基于CF+side info的方法
Deep collaborative Filering
- 输入层:除了用户和物品的交互矩阵,还有用户特征X和物品特征Y
- 表征函数: 和传统的 CF 表示学习不同,这里引入了用户侧特征X例如年龄、性别等;物品侧特征 Y 例如文本、标题、类目等;user 和 item 侧的特征各自通过一个 auto-encoder 来学习,而交互信息 R 矩阵依然做矩阵分解 U,V,模型架构如下图所示。
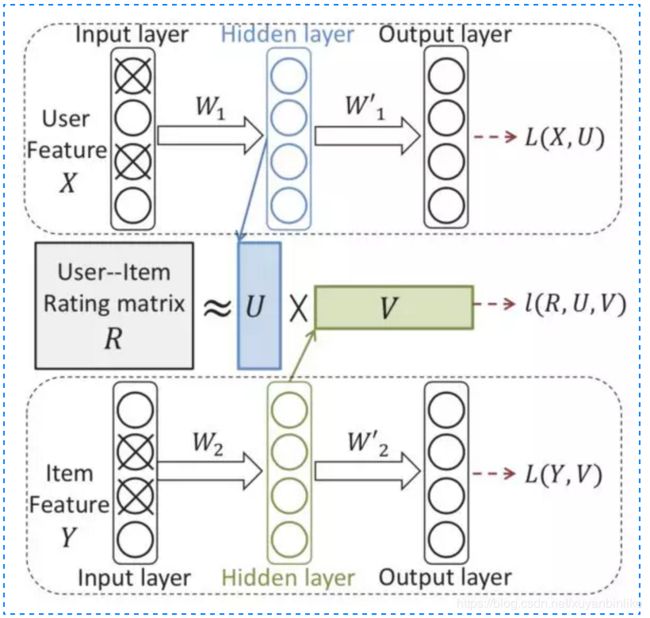
相应地损失函数包含三个部分:用户侧特征、物品侧特征以及用户-物品交互矩阵和预测矩阵的平方差,最后再加上L2正则,如下图所示。

整个模型的学习,既需要保证用户特征 X 和物品特征 Y 本身 encode 尽可能准确 ( auto-encoder 的 reconstruction 误差 ),又需要保证用户对物品的预估和实际观测的尽可能接近 ( 矩阵分解误差 ),同时正则化也约束了模型的复杂度不能太高。
Attentive Collaborative Filtering
在传统的CF模型中加入了Attention机制,这里的Attention机制有两层意思:(1)用户历史交互过的 item 的权重是不一样的。(2)用户对一个物品中的特征结合权重也是不一样的,如下图所示。
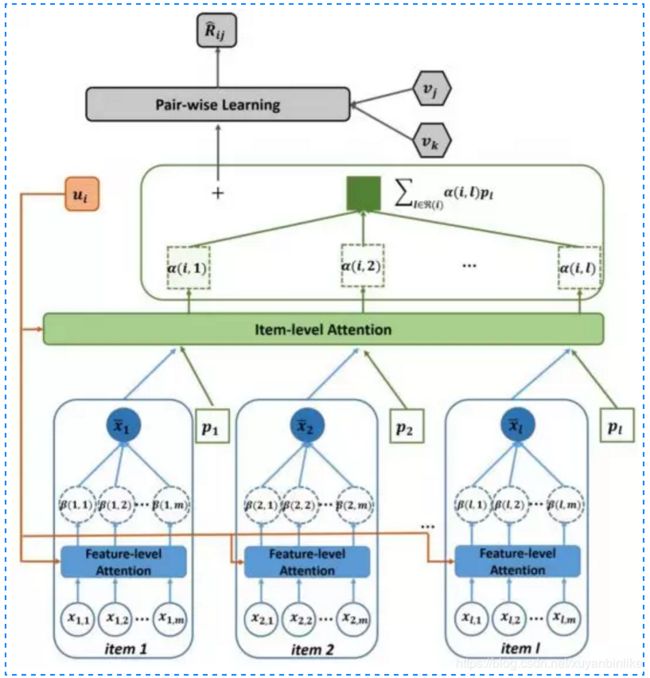
- 输入层:(1)用户侧:userid;用户交互过的item(2)物品侧:itemid;item相关的特征。
- 表征函数:可以分为两个 attention,一个是 component 层级的 attention,主要是提取视觉特征;第二层是 item 层级的 attention,主要提取用户对物品的喜好程度权重。
- 匹配评分函数:user和item的向量內积。
Collaborative Knowledge Base Embedding
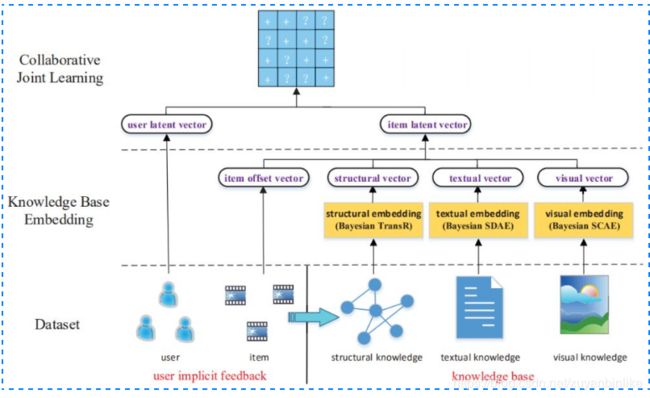
利用知识图谱做 representation learning,分别在结构化信息、文本信息和视觉信息中提取 item 侧特征作为 item 的 representation。
- 输入层:user侧:userid。item侧:itemid以及基于知识图谱的item特征(structual,textual,visual)
- 表征函数: 从知识图谱的角度,从结构化信息,文本信息以及图文信息分别提取 item 侧的表达,最终作为 item 的 embedding。(1)结构化特征 struct embedding: transR,transE(2)文本特征 Textual embedding: stacked denoising auto-encoders(3)文本特征 Textual embedding: stacked denoising auto-encoders
- 匹配评分函数:得到用户向量和 item 向量后,用向量点击表示 user 和 item 的匹配分数;损失函数则用如下的 pair-wise loss 表示:
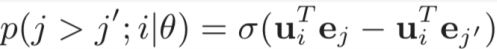
基于表征的深度匹配方法总结
该方法可用如下图所示的框架作为范式表达:
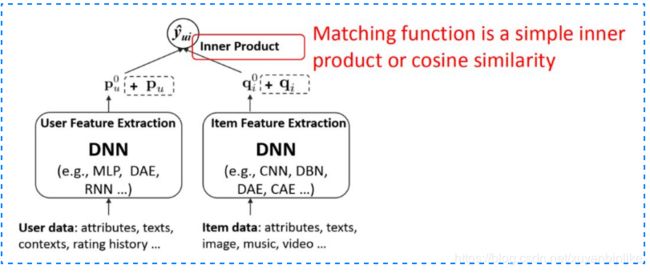
这些方法有着以下特点:
1.representation learning:目的是学习到 user 和 item 各自的 representation ( 也叫 latent vector,或者 embedding )。
2. 特征表达:user 侧特征除了用户 id 本身 userid,可以加上其他 side info;item 侧特征除了物品 id 本身 itemid,还有其他文本特征、图文特征、视频帧特征等信息。
3. 模型表达:除了传统的 DNN,其他结构如 Auto-Encoder ( AE ),Denoise-Auto-Encoder ( DAE ),CNN,RNN 等。
基于match function learning的深度匹配模型
与表示学习最大的不同,就是基于match function learning不直接学习user和item的embedding,而是通过输入和神经网络框架来直接拟合user和item的匹配分数,简单来说,第一种方法 representation learning 不是一种 end-2-end 的方法,通过学习 user 和 item 的 embedding 作为中间产物,然后可以方便的计算两者的匹配分数;而第二种方法 matching function learning 是一种 end2end 的方法,直接拟合得到最终的匹配分数。本章主要介绍基于 match function learning 的深度学习匹配方法。
CF-based model
基于神经网络的协同过滤(Neural collaborative filtering )
在得到 user vector 和 item vector 后,连接了 MLP 网络后,最终拟合输出,得到一个 end-2-end 的 model。这套框架好处就是足够灵活,user 和 item 侧的双塔设计可以加入任意 side info 的特征,而 MLP 网络也可以灵活的设计,如下图所示:
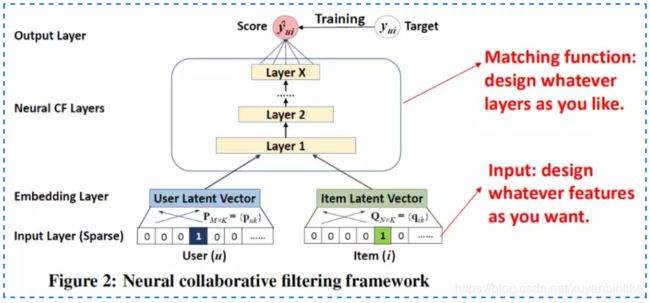
NCF 框架对比之前的CF方法最主要引入了 MLP 去拟合 user 和 item 的非线性关系,而不是直接通过 inner product 或者 cosine 去计算两者关系,提升了网络的拟合能力。基于 NCF 框架的方法基础原理是基于协同过滤,而协同过滤本质上又是在做 user 和 item 的矩阵分解,所以,基于 NCF 框架的方法本质上也是基于 MF 的方法。矩阵分解本质是尽可能将 user 和 item 的 vector,通过各种方法去让 user 和 item 在映射后的空间中的向量尽可能接近 ( 用向量点击或者向量的 cosine 距离直接衡量是否接近)。
另一种思路是基于翻译的方法,也叫 translation based model,认为 user 和 item 在新的空间中映射的 vector 可以有 gap,这个 gap 用 relation vector 来表达,也就是让用户的向量加上 relation vector 的向量,尽可能和 item vector 接近。
基于translation框架的方法
2017年的 recsys 会议上提出的一种基于 “translate” 的推荐方法,要解决的是 next item 的推荐问题。基本思想是说用户本身的向量,加上用户上一个交互的 item 的向量,应该接近于用户下一个交互的 item 的向量,输入是 (user, prev item, next item),预测下个 item 被推荐的概率。

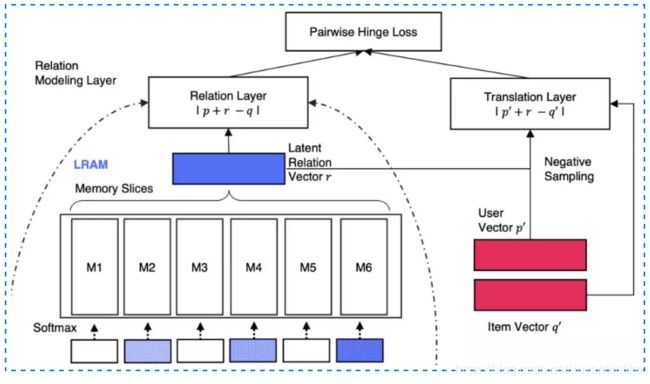
LRML模型
LRML 模型通过引入 memory network 来学习度量距离。可以分为三层 layer,分别是 embedding layer, memory layer 和 relation layer。
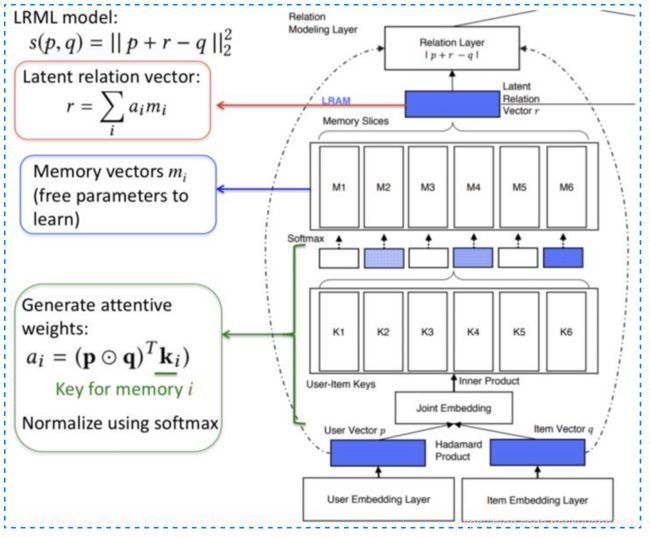
- embedding层
底层是常规的双塔 embedding,分别是用户 embedding 矩阵和物品的 embedding 矩阵,用户 one-hot 输入和 item 的 one-hot 输入通过 embedding 后得到用户向量 p 和物品向量 q。 - memory 层
记忆网络是本模型的核心结构,首先从embedding层得到的user向量p和item向量q做哈达玛內积,得到向量s:
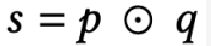
然后利用s去和memory记忆模块中的各个memory vector挨个计算相似度,相似度可以用內积表达并使用softmax做归一化。
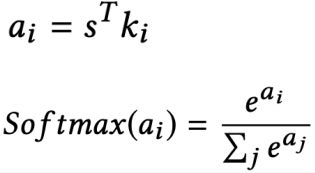
最终得到relation vector是上述不同记忆网络中不同vector的加权表达,如下所示:
- relation 层
从 memory layer 得到的 r 向量可以认为是用户向量 p 与物品向量 q 的 relation vector,最终的距离用平方损失衡量,如下图所示
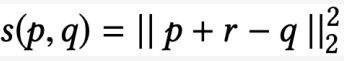
feature-based 的深度模型
之前介绍的基于CF的方法,输入的特征向量都是稀疏且高维的,而特征之间的交叉关系对模型来说非常重要。例如,用户一般会在一天快吃三餐的时候,打开和订餐相关的 app,这样,用户使用订餐 app 和时间存在着二阶交叉关系。因此,如何捕捉特征之间的交叉关系,衍生了众多基于特征的模型,在这里将这些捕捉特征交叉关系的模型称为 feature-based model。
wide & deep 模型
2016年 google 提出的 wide and deep 模型。说是模型,不如说是通用的一套范式框架,在整个工业界一举奠定了风靡至今的模型框架,如下图所示: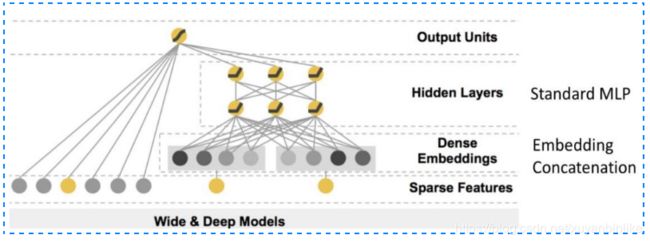
在这个经典的 wide&deep 模型中,google 提出了两个概念:generalization ( 泛化性 ) 和 memory ( 记忆性 )。
1.记忆性:wide 部分长处在于学习样本中的高频部分,优点是模型的记忆性好,对于样本中出现过的高频低阶特征能够用少量参数学习;缺点是模型的泛化能力差,例如对于没有见过的 ID 类特征,模型学习能力较差。
2. 泛化性:deep 部分长处在于学习样本中的长尾部分,优点是泛化能力强,对于少量出现过的样本甚至没有出现过的样本都能做出预测 ( 非零的 embedding 向量 ),容易带来惊喜。缺点是模型对于低阶特征的学习需要用较多参数才能等同 wide 部分效果,而且泛化能力强某种程度上也可能导致过拟合出现 bad case。尤其对于冷启动的一些 item,也有可能用用户带来惊吓。
DeepFM
Google 的 wide&deep 框架固然强大,但由于 wide 部分是个 LR 模型,仍然需要人工特征工程。华为诺亚方舟团队结合 FM 相比 LR 的特征交叉的功能,在2017年提出了 deepFM,将 wide&deep 部分的 LR 部分替换成 FM 来避免人工特征工程,如下图所示:
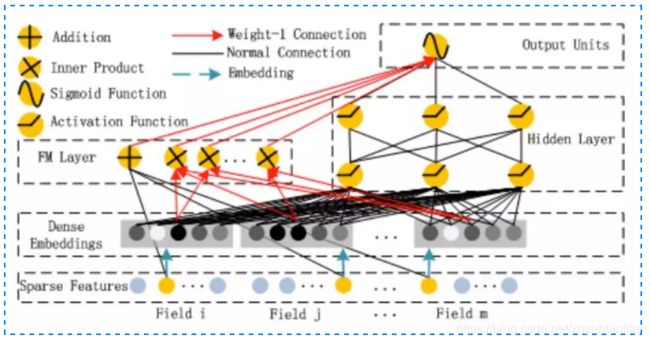
DeepFM有着如下特点:
- 更强的低阶特征表达
- Embedding层共享:Wide&deep 部分的 embedding 层得需要针对 deep 部分单独设计;而在 deepFM 中,FM 和 DEEP 部分共享 embedding 层,FM 训练得到的参数既作为 wide 部分的输出,也作为 DNN 部分的输入。
- 端到端的训练方式:Embedding 和网络权重联合训练,无需预训练和单独训练。
AFM模型(Attention Factorization Machines)
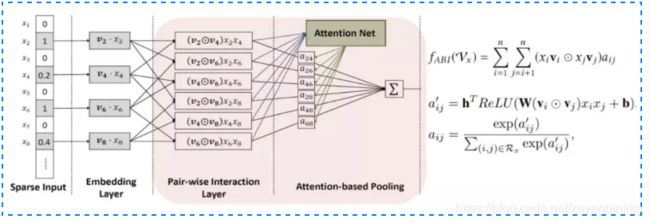
前面提到的各种网络结构中的 FM 在做特征交叉时,让不同特征的向量直接做交叉,基于的假设是各个特征交叉对结果的贡献度是一样的。这种假设往往不太合理,原因是不同特征对最终结果的贡献程度一般是不一样的。AFM模型通过引入attention机制来解决这个问题。
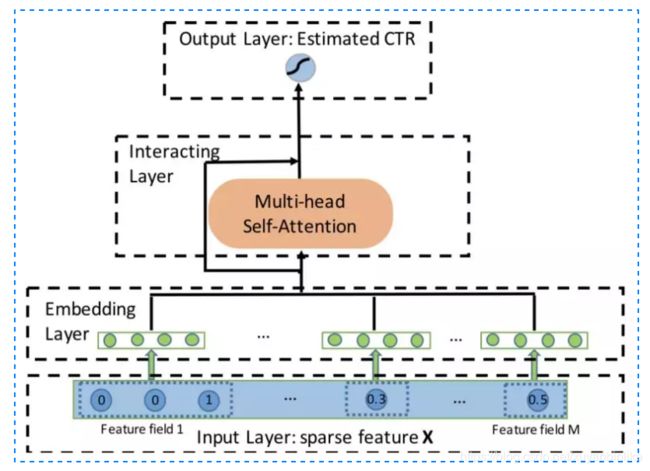
AutoInt(Auto Feature Interaction)
目前为止讲到的模型中,使用到 attention 的是 AFM 模型,而在 AutoInt 文章中,作者除了 attention 机制,还使用了在 transform 中很火的 multi-head 和 self-attention 的概念,整体框架如图所示。
声明:转载于https://zhuanlan.zhihu.com/p/101136699,如有侵权,联系删除,谢谢!