Oracle编程艺术学习笔记—01
Oracle编程艺术学习笔记—01
文章目录
- Oracle编程艺术学习笔记—01
- 环境准备
- 1. 按书中所示,先创建一个eoda用户,并赋予相关权限
- 2. 以 eoda 身份登录,然后创建 SCOTT 用户下的四张表
- 3. 设置每次启动时都启动 DBMS_OUTPUT
- 4. 设置 AUTORACE
- 5. 配置 Statspack
- 6. 安装runstats
- 7. 创建测试表 big_table
- 8. 测试runstats安装是否成功
- 8. mystat和mystat2
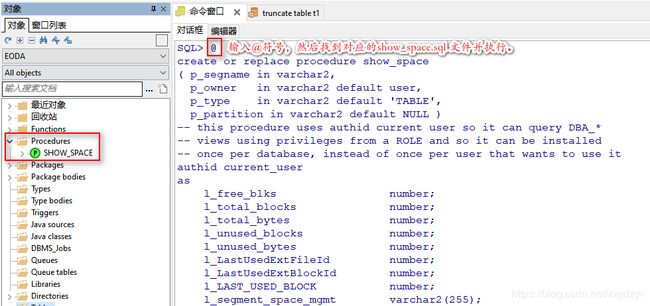
- 9. show_space
注:下面的代码大部分可以在作者的GIthub上找到,还有一部分在Oracle的安装目录下可以找到,只有少许我做了改动。
环境准备
1. 按书中所示,先创建一个eoda用户,并赋予相关权限
注意:本来我是直接运行书上的代码的,估计是需要在dos窗口运行,plsql的命令窗口还有些问题,所以我就自己修改了下,写了段能在SQL窗口运行的脚本。
create user eoda identified by foo;
grant dba to eoda;
grant execute on dbms_stats to eoda;
grant select on V_$STATNAME to eoda;
grant select on V_$MYSTAT to eoda;
grant select on V_$LATCH to eoda;
grant select on V_$TIMER to eoda;
2. 以 eoda 身份登录,然后创建 SCOTT 用户下的四张表
注意:这段脚本来自于 $Oracle_home$\RDBMS\ADMIN 路径下的 utlsampl.sql 文件,同样,这里也出现了问题,插入emp 表时,有两条数据时间格式貌似有问题。所有我也修改了下。
CREATE TABLE DEPT
(DEPTNO NUMBER(2) CONSTRAINT PK_DEPT PRIMARY KEY,
DNAME VARCHAR2(14) ,
LOC VARCHAR2(13) ) ;
CREATE TABLE EMP
(EMPNO NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) CONSTRAINT FK_DEPTNO REFERENCES DEPT);
INSERT INTO DEPT VALUES
(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES (20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES
(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES
(40,'OPERATIONS','BOSTON');
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO EMP VALUES
(7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO EMP VALUES
(7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO EMP VALUES
(7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO EMP VALUES
(7788,'SCOTT','ANALYST',7566,to_date('13-7-1987','dd-mm-yyyy')-85,3000,NULL,20);
INSERT INTO EMP VALUES
(7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO EMP VALUES
(7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO EMP VALUES
(7876,'ADAMS','CLERK',7788,to_date('13-7-1987', 'dd-mm-yyyy')-51,1100,NULL,20);
INSERT INTO EMP VALUES
(7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO EMP VALUES
(7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES
(7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);
CREATE TABLE BONUS
(
ENAME VARCHAR2(10) ,
JOB VARCHAR2(9) ,
SAL NUMBER,
COMM NUMBER
) ;
CREATE TABLE SALGRADE
( GRADE NUMBER,
LOSAL NUMBER,
HISAL NUMBER );
INSERT INTO SALGRADE VALUES (1,700,1200);
INSERT INTO SALGRADE VALUES (2,1201,1400);
INSERT INTO SALGRADE VALUES (3,1401,2000);
INSERT INTO SALGRADE VALUES (4,2001,3000);
INSERT INTO SALGRADE VALUES (5,3001,9999);
COMMIT;
3. 设置每次启动时都启动 DBMS_OUTPUT
1. 脚本
define _editor=vi
set serveroutput on size 1000000
set trimspool on -- AUTOTRACE 报告既包括优化路径,又包括SQL语句的执行统计信息
set long 5000
set linesize 100
set pagesize 9999
column plan_plus_exp format a80
set sqlprompt '&_user.@&_connect_identifier.> '
2. 脚本解析
1. define _editor=vi:设置SQL*Plus使用的默认编辑器。可以把它设置为你最喜欢的文本编辑器(而不是字处理器),如记事本(Notepad )或emacs。
2. set serveroutput on size unlimited:这会默认地打开DBMS_OUTPUT (这样就不必每次都键入这个命令了)。另外,这条命令也会将默认缓冲区设置得尽可能大。
3. set trimspool on:当我们把一些命令及其输出写入文本时,这条命令会去除文本行两端的空格,而且不会固定行宽。如果设置为OFF(默认设置),那么行的宽度则等同于linesize0
4. set long 5000:设置选择LONG和CLOB列时显示的默认字节数。
5. set linesize 100:设置SQL*Plus显示的文本行宽为100个字符。
6. set pagesize 9999: pagesize可以控制SQL*Plus多久打印一次标题。这里将pagesize设置为一个很大的数(所以每页只有一组标题)。
7. column plan_plus_exp format a80:设置 AUTOTRACE 输出的执行计划默认宽度。a80 通常足以放下整个计划。
login.sql中下面这部分用于建立SQL*Plus提示符:
set sqlprompt '&_user.@&_connect_identifier.> '
这样设置的提示符就能让我知道登录的用户以及登录的是哪一个数据库。
3. 未设置时,输出格式
set serveroutput on; -- 需要加上这条语句才能设置开启输出
declare
begin
dbms_output.put_line('hello world');
end;
/
4. 设置方法
这里踩了不少的坑…就不一一例举出来了,直接说解决方案。
- 复制好脚本
- 找到
$oracle_home$\sqlplus\admin文件夹 - 打开里面的
glogin.sql - 将脚本复制进去
- 然后启动dos窗口登录就可以了。
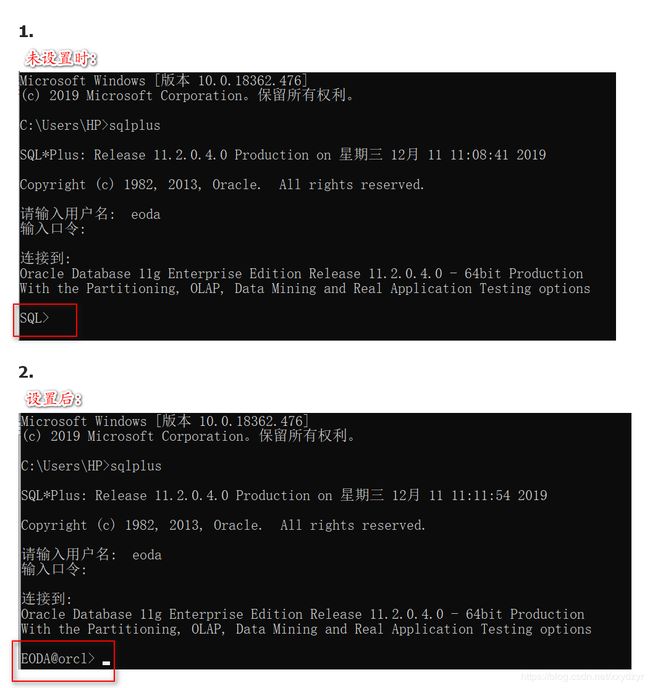
还有一种方案没有测试:
先创建一个 login.sql 文件,包存上面的脚本,然后将这个放到 $oracle_home$\sqlplus 路径下,再删除 admin 文件夹中的 glogin.sql 文件。
貌似 login.sql 文件也可以不用放置在这个位置,不过需要以SQLPATH 环境变量来指定路径。
原因:sqlplus在启动时会先执行 glogin.sql 脚本,没有找到的情况下再去寻找 login.sql ,路径和上面的一致。
4. 设置 AUTORACE
该部分按照书上,需要新建一个角色然后在赋权限给它,我这边直接在第三步中添加了,没有新建角色,然后赋权。
书中的要求执行的 plustrce脚本:
set echo on -- 设置运行命令是是否显示语句
drop role plustrace; -- 删除角色名
create role plustrace; -- 新建角色
-- 赋权限
grant select on v_$sesstat to plustrace;
grant select on v_$statname to plustrace;
grant select on v_$mystat to plustrace;
grant plustrace to dba with admin option;
set echo off -- 显示start启动的脚本中的每个sql命令,缺省为on
5. 配置 Statspack
该配置只需要运行$oracle_home$\RDBMS\ADMIN 文件夹下的 spcreate.sql 脚本即可。
注意:
-
运行该脚本后需要指定默认表空间和临时表空间
-
如果之前输入的有误或者不小心取消安装,在下一次尝试安装 Statspack 时,需要先执行
$oracle_home$\RDBMS\ADMIN文件夹下的 spdrop.sql 。 -
我们可以从
$oracle_home$\RDBMS\ADMIN文件夹下的 spdoc.txt 下找到相关说明。 -
Statspack 的报表数据还是相当占控件的,特别时在多次连续采用的情况下,所以我们这边新建一个表空间专门用来存储,同时初始空间起码给100M。(第一次安装失败后修改了下,改成500M了)
该部分详解见: Oracle基础知识01
-- 以sys用户登录 --创建表空间(永久表空间) CREATE TABLESPACE eodatbs DATAFILE 'D:\Oracle_db\practice\eodatbs.dbf' -- 数据文件路径 SIZE 500m -- 数据文件的初始大小 AUTOEXTEND ON -- 自动扩展 NEXT 50M -- 自动扩展的大小 MAXSIZE UNLIMITED -- 最大大小 ; --创建表空间(临时表空间) CREATE TEMPORARY TABLESPACE eodatemptbs TEMPFILE 'D:\Oracle_db\practice\eodatemptbs.dbf' -- 数据文件路径 SIZE 200m -- 数据文件的初始大小 AUTOEXTEND ON -- 自动扩展 NEXT 20M -- 自动扩展的大小 MAXSIZE UNLIMITED -- 最大大小 ;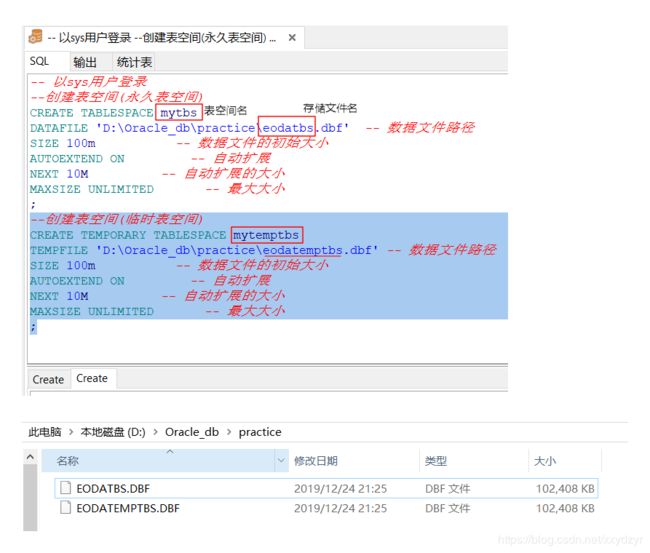
注意:图片中的表空间名和文件名没有对上,现脚本中的是对上的。
-
安装 Statspack ,还是以SYS用户登录,运行运行
$oracle_home$\RDBMS\ADMIN文件夹下的 spcreate.sql 脚本,输入设置的密码,然后指定表空间和临时表空间。这里忘记截图了0.0
运行脚本后需要输入设定的密码,为了方便,我就输入的数据库密码:foo
然后输入指定的默认存储表空间名:eodatbs
最后还要输入指定的临时表空间名:eodatemptbs
6. 安装runstats
runstats会测量三个要素:
- 耗用时间。
- 系统统计信息:会并排的显示每个方法做某件事(如执行一个解析调用)的次数,并展示出二者之差。
- 闩定:报告的关键输出(闩事一种轻量级的锁)。
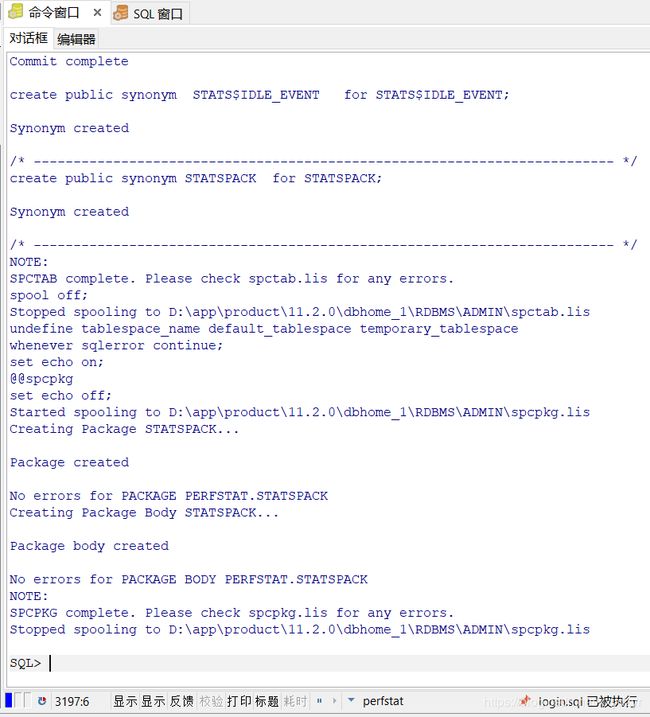
在eoda用户的命令窗口,用@符号执行下面脚本,然后要求登录DBA用户,用sys用户登录
conn / as sysdba
-- 赋权给eoda
grant select on v_$statname to eoda;
grant select on v_$mystat to eoda;
grant select on v_$latch to eoda;
grant select on v_$timer to eoda;
-- 重新用eoda登录
conn eoda/foo
-- 避免表重复,先删除小表run_stats
drop table run_stats;
set echo on;
create or replace view stats
as select 'STAT...' || a.name name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
union all
select 'LATCH.' || name, gets
from v$latch
union all
select 'STAT...Elapsed Time', hsecs from v$timer;
-- 创建表run_stats来存储数据
create global temporary table run_stats
( runid varchar2(15),
name varchar2(80),
value int )
on commit preserve rows;
-- 创建 runstats_pkg 包,
-- 包括测试入口(测试开始时调用)的 rs_start
-- 测试中调用的 RS_MIDDLE
-- 测试完成时调用 RS_STOP,并打印报告,其中 p_difference_threshold 参数用于控制最后打印的数据量。
create or replace package runstats_pkg
as
procedure rs_start;
procedure rs_middle;
procedure rs_stop(p_difference_threshold in number default 0 );
end;
/
-- runstats_pkg 包的实现
create or replace package body runstats_pkg
as
-- 定义全局变量,用于记录每次运行的耗时
g_start number;
g_run1 number;
g_run2 number;
-- 第一个存储过程会先清空表,然后填入运行第一个方式之前按的统计和闩信息,并且会记录当前时间,用于计算耗用时间
procedure rs_start
is
begin
delete from run_stats;
insert into run_stats
select 'before', stats.* from stats;
g_start := dbms_utility.get_cpu_time;
end;
-- 第二个中间运行,会记录第一次测试运行的耗用时间在G_RUN1中,然后记录当前的系统和闩的统计信息
-- 这些值与先前在 RS_START 中包存的值相减就能得出第一个方法使用了多少资源
-- 最后再记录下一次运行的开始时间
procedure rs_middle
is
begin
g_run1 := (dbms_utility.get_cpu_time-g_start);
insert into run_stats
select 'after 1', stats.* from stats;
g_start := dbms_utility.get_cpu_time;
end;
-- 这里的任务时打印每次运行CPU的时间,然后分别打印两次运行的统计/闩值只差
procedure rs_stop(p_difference_threshold in number default 0)
is
begin
g_run2 := (dbms_utility.get_cpu_time-g_start);
dbms_output.put_line( 'Run1 ran in ' || g_run1 || ' cpu hsecs' );
dbms_output.put_line( 'Run2 ran in ' || g_run2 || ' cpu hsecs' );
if ( g_run2 <> 0 )
then
dbms_output.put_line
( 'run 1 ran in ' || round(g_run1/g_run2*100,2) ||
'% of the time' );
end if;
dbms_output.put_line( chr(9) );
insert into run_stats
select 'after 2', stats.* from stats;
dbms_output.put_line
( rpad( 'Name', 30 ) || lpad( 'Run1', 16 ) ||
lpad( 'Run2', 16 ) || lpad( 'Diff', 16 ) );
for x in
( select rpad( a.name, 30 ) ||
to_char( b.value-a.value, '999,999,999,999' ) ||
to_char( c.value-b.value, '999,999,999,999' ) ||
to_char( ( (c.value-b.value)-(b.value-a.value)),
'999,999,999,999' ) data
from run_stats a, run_stats b, run_stats c
where a.name = b.name
and b.name = c.name
and a.runid = 'before'
and b.runid = 'after 1'
and c.runid = 'after 2'
and abs( (c.value-b.value) - (b.value-a.value) )
> p_difference_threshold
order by abs( (c.value-b.value)-(b.value-a.value))
) loop
dbms_output.put_line( x.data );
end loop;
dbms_output.put_line( chr(9) );
dbms_output.put_line
( 'Run1 latches total versus runs -- difference and pct' );
dbms_output.put_line
( lpad( 'Run1', 14 ) || lpad( 'Run2', 19 ) ||
lpad( 'Diff', 18 ) || lpad( 'Pct', 11 ) );
for x in
( select to_char( run1, '9,999,999,999,999' ) ||
to_char( run2, '9,999,999,999,999' ) ||
to_char( diff, '9,999,999,999,999' ) ||
to_char( round( run1/decode( run2, 0, to_number(0), run2) *100,2 ), '99,999.99' ) || '%' data
from ( select sum(b.value-a.value) run1, sum(c.value-b.value) run2,
sum( (c.value-b.value)-(b.value-a.value)) diff
from run_stats a, run_stats b, run_stats c
where a.name = b.name
and b.name = c.name
and a.runid = 'before'
and b.runid = 'after 1'
and c.runid = 'after 2'
and a.name like 'LATCH%'
)
) loop
dbms_output.put_line( x.data );
end loop;
end;
end;
/

7. 创建测试表 big_table
这玩意貌似之前就有出现过,不过忘记有没有说怎么创建它的了。
这个使用的很频繁,创建它也很简单,执行下面的脚本即可。
define numrows=10000000
drop table big_table purge;
create table big_table
as
select rownum id, OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from all_objects
where 1=0
/
alter table big_table nologging;
declare
l_cnt number;
l_rows number := &numrows;
begin
insert /*+ append */
into big_table
select rownum id, OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from all_objects
where rownum <= &numrows;
--
l_cnt := sql%rowcount;
commit;
while (l_cnt < l_rows)
loop
insert /*+ APPEND */ into big_table
select rownum+l_cnt,OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from big_table a
where rownum <= l_rows-l_cnt;
l_cnt := l_cnt + sql%rowcount;
commit;
end loop;
end;
/
alter table big_table add constraint
big_table_pk primary key(id);
exec dbms_stats.gather_table_stats( user, 'BIG_TABLE', estimate_percent=> 1);

8. 测试runstats安装是否成功
测试方法:创建两张表(t1,t2),表结构与big_table一致,然后使用批量的方式插入数据致t1,以单独的方式插入致t2,调用runstats,查看耗时。
测试脚本:demo1.sql
-
先创建 t1 和 t2 表
prompt 创建表 t1 prompt ========================== prompt create table t1 as select * from big_table where 1=0; prompt 创建表 t2 prompt ========================== prompt create table t2 as select * from big_table where 1=0;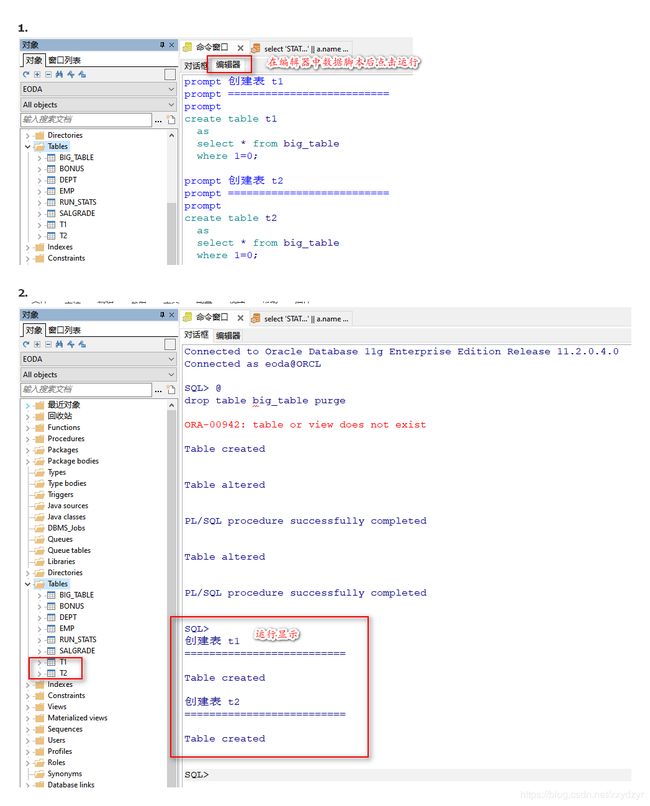
-
先运行测试入口
exec runstats_pkg.rs_start; -
然后向t1中批量插入数据
insert into t1 select * from big_table where rownum <= 1000000; commit; -
接着运行测试中的存储过程。
exec runstats_pkg.rs_middle; -
再向t2中单条单条的插入数据
begin for x in ( select * from big_table where rownum <= 1000000 ) loop insert into t2 values X; end loop; commit; end; / -
最后执行测试的最后命令
exec runstats_pkg.rs_stop(1000000);
上面的测试可以放在一个脚本中执行,分开写只是为了说明步骤。
2-6整体执行结果:
set serveroutput on; -- 注意:没有这条语句,看不到结果,踩坑之一
prompt 开始测试
prompt ==========================
prompt
exec runstats_pkg.rs_start;
prompt 向t1批量插入数据
prompt ==========================
prompt
insert into t1
select *
from big_table
where rownum <= 1000000;
commit;
prompt 执行中间接口,记录时间
prompt ==========================
prompt
exec runstats_pkg.rs_middle;
prompt 向t2逐条插入数据
prompt ==========================
prompt
begin
for x in ( select *
from big_table
where rownum <= 1000000 )
loop
insert into t2 values X;
end loop;
commit;
end;
/
prompt 执行停止接口,打印报告
prompt ==========================
prompt
exec runstats_pkg.rs_stop(1000000);
注意:如果是在PLSQL上执行的,则需要加上上面脚本的第一句话,打开plsql的输出。
之前没有加,导致一致显示执行成功却看不到结果。

8. mystat和mystat2
这两个脚本属于直接执行的脚本,不会创建什么,只会查询数据。
9. show_space
show_space 存储过程用于打印数据库段的空间利用率信息。
该存储过程执行脚本见:show_space.sql