总结Redis问题
Redis 线程模型

客户端 socket01 向 redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
假设此时客户端发送了一个 set key value 请求,此时 redis 中的 socket01 会产生 AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的 AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
如果此时客户端准备好接收返回结果了,那么 redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
为啥 redis 单线程模型也能效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。处理事件是纯内存操作。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
redis 过期策略
定期删除+惰性删除
所谓定期删除,指的是 redis 默认是每隔 100ms 就随机抽取一些设置了过期时间的 key,检查其是否过期,如果过期就删除。
所谓惰性删除在你获取某个 key 的时候,redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
但是这样:当有大量key过期时 这个策略往往是不够的。只有走走内存淘汰机制。
这个看具体业务设置适合的淘汰机制
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
手写一个 LRU 算法
利用已有的 JDK 数据结构实现一个 Java 版的 LRU。
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
*
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
// true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > CACHE_SIZE;
}
}
Redis 主从架构 与哨兵机制保证高并发 高可用
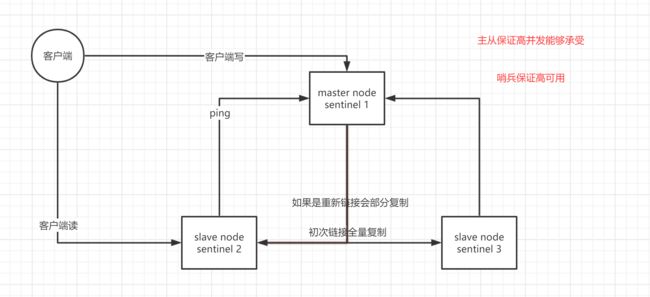
sentinel,中文名是哨兵。哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
- 故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题。
- 即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了。
- 哨兵至少需要 3 个实例,来保证自己的健壮性。
- 哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性。
- 对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
redis 哨兵主备切换的数据丢失问题
异步复制导致的数据丢失:意思就是master还没来得及同步数据到slave 的时候master 就宕机了。
脑裂,也就是说,某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个 master ,也就是所谓的脑裂。

怎么解决
min-slaves-to-write 1
min-slaves-max-lag 10
表示,要求至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒。
如果说一旦所有的 slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,master 就不会再接收任何请求了。 这是为了减少数据丢失。
- sdown 是主观宕机,就一个哨兵如果自己觉得一个 master 宕机了,那么就是主观宕机
- odown 是客观宕机,如果 quorum 数量的哨兵都觉得一个 master 宕机了,那么就是客观宕机
redis 持久化的两种方式
-
RDB:RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。保存的是实际的数据
-
AOF:AOF 机制对每条写入命令作为日志(resp协议命令),以
append-only的模式写入一个日志文件中,在 redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。 -
如果同时使用 RDB 和 AOF 两种持久化机制,那么在 redis 重启的时候,会使用 AOF 来重新构建数据,因为 AOF 中的数据更加完整。
RDB 优缺点
-
RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能,因为 redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
-
由于RDB是保存的数据,恢复就比较快,但是RDB都是每隔一段时间保存一次数据,所以在周期内可能会有数据丢失。
-
RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF优缺点
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次
fsync操作,最多丢失 1 秒钟的数据。 - AOF 日志文件以
append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。 - 适合做适合做灾难性的误删除的紧急恢复 比如某人不小心用
flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝 AOF 文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据 - 相对来说性能会比RDB低,因为AOF 一般会配置成每秒
fsync一次日志文件。
Redis cluster

分布式寻址算法
hash 算法(大量缓存重建)

来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库
一致性 hash 算法+虚拟节点
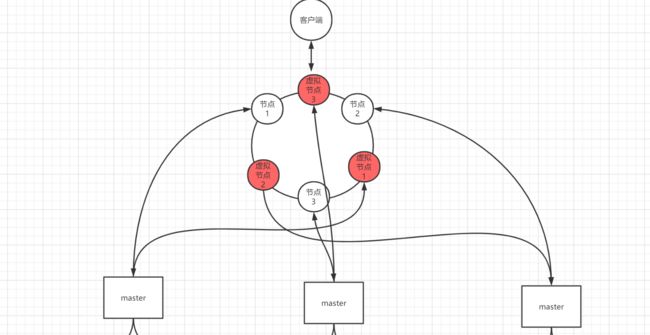
一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
对key首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。
在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
燃鹅,一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
Redis cluster 的 hash slot 算法
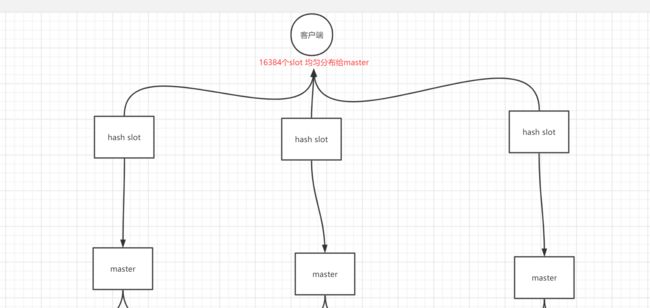
Redis cluster 有固定的 16384 个 hash slot,对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。
redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过 hash tag 来实现。
任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。
缓存雪崩 击穿 穿透
雪崩
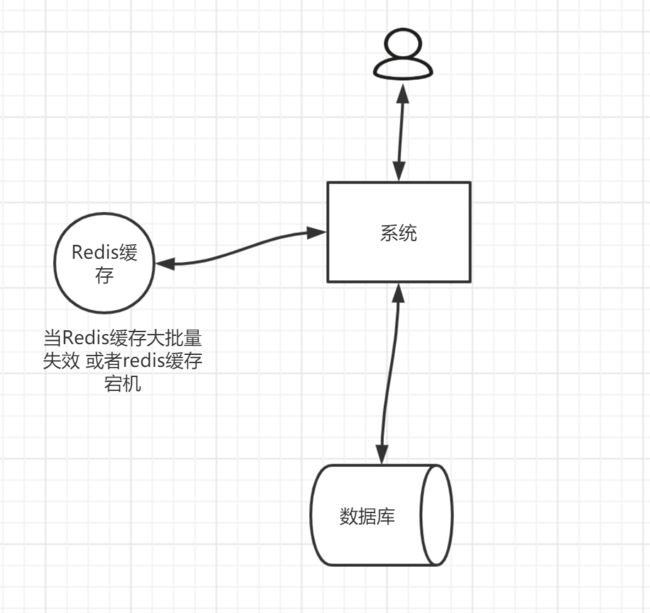
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
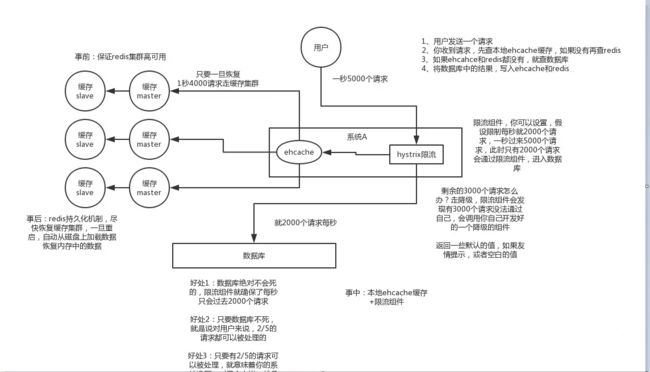
穿透
用户大量请求库中不存在的数据
每次系统 从数据库中只要没查到,就写一个空值到缓存里去,比如 set -999 UNKNOWN。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。
击穿
某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞
可以将热点数据设置为永远不过期;或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。