作者原创, 谢绝任何形式转载, 包括部分转载!
上篇:Faster R-CNN原理详解(基于keras代码)(一)
本部分主要介绍,RPN网络的来龙去卖.可以说,整个Faster R-CNN网络中,最关键,最核心的部分就是RPN网络了,这也是论文的创新之处.本部分讲解均使用VOC2007数据集中的000910.jpg图片来作为样例
1. 再探RPN网络定义:
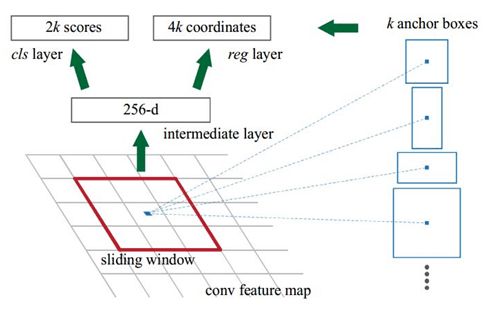
该网络非常简单,仅仅在前面定义的base net的基础上加了一个(3, 3)的卷基层,然后就是由两个一个(1, 1)的卷基层构成的输出层。一个输出用于判断前景和背景,另外一个用于bboxes回归.而且,这里的卷积层都不改变featuremap的尺度,仅仅改变通道数。
该网络的输入为:
base_layers: 也就是前面Vgg版本的base Net网络最后的输出。假设输入base Net的图片尺度为(600 * 600 * 3).则该RPN输入featuremap的shape也就是(37 * 37 * 512)。
num_anchors: 这个是值得每个锚点产生的RoI的数量。例如:根据论文中anchors的尺度为:[16, 32, 64]共3种, 长宽比例为:[1:1,1:2,2:1]也是三种。则num_anchors=3*3.
(该值并不固定,可能需要根据具体实验数据以及应用场景做相应的修改)
网络的输出为:
x_class: 根据前面的输入,可知输出的shape为:(37 * 37 * 9).注意在论文中输出的时29=18维,因为考虑使用的时softmax分别输出forground和background的概率,但是次数仅仅输出foreground的概率所以时19=9维。效果其实是一样的。
x_regr: bboxes回归层.bboxes回归由于是RCNN系列的核心部分,所以需要特别说明.请参照这里
def rpn(base_layers, num_anchors):
x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers)
x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x)
x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x)
return [x_class, x_regr, base_layers]
假如输入给base Net的图片如下图所示:

则从Base Net输出的feature map特征图如下所示:





其实最后输出的block5_conv3卷基层feature map就是输入到RPN网络base_layers.总共有512个通道, 这里只显示了16个通道.
2. 为RPN网络准备训练数据
2.1 RPN网络的训练部分代码(只列出训练RPN相关的代码, 而且是一次训练):
下列代码几处调用函数说明:
nn.base: 其实调用的就是上一篇介绍过的base Net网络, 本文讲解使用的VGG16作为基网络.
nn.rpn: 就是上一节定义的RPN网络, 最后返回三个值, 也就是说len(rpn)=3
data_gen_train: 通过next来调用,可以知道是一个迭代器, 最终调用的函数是get_anchor_gt, 后面将会详细介绍该函数, 返回三个值
data_gen_train = data_generators.get_anchor_gt(train_imgs, classes_count, C, nn.get_img_output_length, K.image_dim_ordering(), mode='train')
img_input = Input(shape=input_shape_img)
shared_layers = nn.nn_base(img_input, trainable=True)
num_anchors = len(C.anchor_box_scales) * len(C.anchor_box_ratios) # 3*3=9
rpn = nn.rpn(shared_layers, num_anchors)
model_baseNet = Model(img_input, shared_layers)
model_rpn = Model(img_input, rpn[:2]) # rpn[:2] = [x_class, x_regr]
model_baseNet.load_weights(C.base_net_weights, by_name=True) # 注意此处必须按name来加载模型, 所以by_name=True
optimizer = Adam(lr=1e-5)
model_rpn.compile(optimizer=optimizer, loss=[losses.rpn_loss_cls(num_anchors), losses.rpn_loss_regr(num_anchors)])
X, Y, img_data = next(data_gen_train)
loss_rpn = model_rpn.train_on_batch(X, Y) # 返回两个误差值rpn_loss_cls和rpn_loss_regr,以及一个样本权重
P_rpn = model_rpn.predict_on_batch(X) # 预测返回也就是model中网络最后的两个输出一个是判断前景和背景的rpn_cls输出,其shape为(1,37,37,9),另外一个是对应输入的图片的各个anchor的修正参数矩阵,其shape为(1,37,37,4*9)
2.2 为RPN网络生成训练数据集代码:
简单介绍一下整个函数的输入:
① all_img_data: 首先其类型是一个list, 也就是说type(all_img_data)='list', 其中的每个元素都是字典类型,都存储这一张图片的信息,输出all_img_data中的一张图片数据为:
all_img_data[0] = {'width': 500, 'height': 500,
'bboxes': [{'y2': 500, 'y1': 27, 'x2': 183, 'x1': 20, 'class': 'person', 'difficult': False},
{'y2': 500, 'y1': 2, 'x2': 249, 'x1': 112, 'class': 'person', 'difficult': False},
{'y2': 490, 'y1': 233, 'x2': 376, 'x1': 246, 'class': 'person', 'difficult': False},
{'y2': 468, 'y1': 319, 'x2': 356, 'x1': 231, 'class': 'chair', 'difficult': False},
{'y2': 450, 'y1': 314, 'x2': 58, 'x1': 1, 'class': 'chair', 'difficult': True}], 'imageset': 'test',
'filepath': './datasets/VOC2007/JPEGImages/000910.jpg'}
可以看到,这里面主要包含图片的宽度(width), 高度(heigth), 边框(bboxes), 数据来源(imageset), 图片所在的路径(filepath).注意: 因为每张图片可能包含有多余一个目标,所以会出现多个边框的情况, 此处的列出的图片数据就包含6个目标.该图片信息对应的图片如下所示:

② class_count: 对应的是数据集中, 各种类别的样本的数量, 也是一个字典形式的数据.例如下面给出的示例.由于仅仅为了说明一下, 我只选择了VOC2007训练集中的100张图片.
{'sheep': 8, 'horse': 5, 'bg': 0, 'bicycle': 7, 'motorbike': 15, 'cow': 6, 'car': 34, 'aeroplane': 2, 'dog': 4, 'bus': 4, 'cat': 6, 'person': 113, 'train': 7, 'diningtable': 4, 'bottle': 3, 'sofa': 9, 'pottedplant': 7, 'tvmonitor': 7, 'chair': 27, 'bird': 6, 'boat': 7}
③ C: 这个是针对整个项目的配置文件参数, 所有的参数可以在其中设置, 在源代码中有专门的config文件.
④ img_length_calc_function: 这是一个用于获取, 原始图片经过base Net后尺寸, 其实就是在原始图片的尺度上除16, 这个在第一篇讲解VGG网络的时候介绍过.
再简单说明一下代码中调用的函数:
①data_augment.augment: 是一个数据增强的函数, 会对原始图片进行旋转, 镜像, 同时增强之后, 修改图片数据中相应的参数, 目标边框的位置, 以及整个图片的宽度和高度. 最后返回增强后的图片数据以及图片.
②get_new_img_size: 这个函数是配合, 其下面的cv2.resize来进行的, 主要时将图片的最小宽度, resize到指定的宽度(如600px).例如前面给出的样例图片, 其width=500, height=500, 则经过该函数之后, width=600, height=600.
③cal_rpn: 这个函数也就rpn网络的关键所在了, 将在后面重点介绍.这个函数基本上就获取到了RPN网络的类别训练数据, 该函数返回两个值, 一个是训练网络用的前景背景的数据, 第二个是网络对anchors做bboxes回归的修正参数.
整个代码后面部分, 主要时对数据维度的调整, 以适应RPN网络训练输入格式.
def get_anchor_gt(all_img_data, class_count, C, img_length_calc_function, backend, mode='train'):
# The following line is not useful with Python 3.5, it is kept for the legacy
# all_img_data = sorted(all_img_data)
sample_selector = SampleSelector(class_count) # 这个函数可以忽略, 在整套代码中没有用到, 用于平衡训练样本
while True:
if mode == 'train':
np.random.shuffle(all_img_data)
for img_data in all_img_data: # 从这个地方可以看到最终提取RPN训练集数据, 是一张图片一张图片的去提取的.下面的说明均以图片000910.jpg为例子
try:
if C.balanced_classes and sample_selector.skip_sample_for_balanced_class(img_data):
continue
# read in image, and optionally add augmentation
if mode == 'train':
img_data_aug, x_img = data_augment.augment(img_data, C, augment=True)
else:
img_data_aug, x_img = data_augment.augment(img_data, C, augment=False)
(width, height) = (img_data_aug['width'], img_data_aug['height'])
(rows, cols, _) = x_img.shape
assert cols == width
assert rows == height
# get image dimensions for resizing
(resized_width, resized_height) = get_new_img_size(width, height, C.im_size)
# resize the image so that smalles side is length = 600px
x_img = cv2.resize(x_img, (resized_width, resized_height), interpolation=cv2.INTER_CUBIC)
try:
y_rpn_cls, y_rpn_regr = calc_rpn(C, img_data_aug, width, height, resized_width, resized_height, img_length_calc_function)
except:
continue
# Zero-center by mean pixel, and preprocess image
x_img = x_img[:,:, (2, 1, 0)] # BGR -> RGB
x_img = x_img.astype(np.float32)
x_img[:, :, 0] -= C.img_channel_mean[0]
x_img[:, :, 1] -= C.img_channel_mean[1]
x_img[:, :, 2] -= C.img_channel_mean[2]
x_img /= C.img_scaling_factor
x_img = np.transpose(x_img, (2, 0, 1))
x_img = np.expand_dims(x_img, axis=0)
y_rpn_regr[:, y_rpn_regr.shape[1]//2:, :, :] *= C.std_scaling
if backend == 'tf':
x_img = np.transpose(x_img, (0, 2, 3, 1))
y_rpn_cls = np.transpose(y_rpn_cls, (0, 2, 3, 1))
y_rpn_regr = np.transpose(y_rpn_regr, (0, 2, 3, 1))
yield np.copy(x_img), [np.copy(y_rpn_cls), np.copy(y_rpn_regr)], img_data_aug
except Exception as e:
print(e)
continue
2.3 生成RPN网络训练数据集代码中calc_rpn函数介绍
输入参数说明:
img_data = {'width': 500, 'height': 500,
'bboxes': [{'y2': 500, 'y1': 27, 'x2': 183, 'x1': 20, 'class': 'person', 'difficult': False},
{'y2': 500, 'y1': 2, 'x2': 249, 'x1': 112, 'class': 'person', 'difficult': False},
{'y2': 490, 'y1': 233, 'x2': 376, 'x1': 246, 'class': 'person', 'difficult': False},
{'y2': 468, 'y1': 319, 'x2': 356, 'x1': 231, 'class': 'chair', 'difficult': False},
{'y2': 450, 'y1': 314, 'x2': 58, 'x1': 1, 'class': 'chair', 'difficult': True}], 'imageset': 'test',
'filepath': './datasets/VOC2007/JPEGImages/000910.jpg'}
width=500
height=500
resized_width=600
resized_height=600
要想明白下面的代码,就必须知道以下几个概念:
- 什么anchor? 怎么去提取anchor? 一张图片要提取多少个anchor?(参考第3部分)
- 什么是IOU? 怎么计算IOU?(参考第4部分)
- 什么时bbox 回归(参考第5部分)
代码如下:
def calc_rpn(C, img_data, width, height, resized_width, resized_height, img_length_calc_function):
"""
此函数非常重要,是RPN网络中的核心函数,用于提取RPN网络训练集,也就是产生各种anchors以及anchors对应与ground truth的修正参数.
:param C: 包含整个项目的配置参数
:param img_data: 图片的数据, 包含图片的宽度width, 高度height, bboxes参数, 类别信息.此时的img_data仅仅是一张图片的信息
:param width: 这个宽度其实就是img_data里面包含的宽度
:param height: 这个值时img_data里面的对应的值
:param resized_width: 注意这个宽度跟 img_data里面包含的宽度有所区别, 这个宽度是经过resize时候的图片的宽度
:param resized_height: 同resized_width值, 是经过resize后的
:param img_length_calc_function: 就是将图片的尺寸缩小16倍的一个函数
:return:
"""
downscale = float(C.rpn_stride) # 16
anchor_sizes = C.anchor_box_scales # [128, 256, 512]
anchor_ratios = C.anchor_box_ratios # [[1,1], [1/sqrt(2), sqrt(2)], [sqrt(2), 1/sqrt(2)]]
num_anchors = len(anchor_sizes) * len(anchor_ratios) # 3*3 = 9
# calculate the output map size based on the network architecture
(output_width, output_height) = img_length_calc_function(resized_width, resized_height) # (600/16, 600/16)=(37, 37)
n_anchratios = len(anchor_ratios)
# initialise empty output objectives
y_rpn_overlap = np.zeros((output_height, output_width, num_anchors))
y_is_box_valid = np.zeros((output_height, output_width, num_anchors))
y_rpn_regr = np.zeros((output_height, output_width, num_anchors * 4))
num_bboxes = len(img_data['bboxes'])
num_anchors_for_bbox = np.zeros(num_bboxes).astype(int)
best_anchor_for_bbox = -1*np.ones((num_bboxes, 4)).astype(int)
best_iou_for_bbox = np.zeros(num_bboxes).astype(np.float32)
best_x_for_bbox = np.zeros((num_bboxes, 4)).astype(int)
best_dx_for_bbox = np.zeros((num_bboxes, 4)).astype(np.float32)
# get the GT box coordinates, and resize to account for image resizing
gta = np.zeros((num_bboxes, 4))
for bbox_num, bbox in enumerate(img_data['bboxes']):
# get the GT box coordinates, and resize to account for image resizing
gta[bbox_num, 0] = bbox['x1'] * (resized_width / float(width))
gta[bbox_num, 1] = bbox['x2'] * (resized_width / float(width))
gta[bbox_num, 2] = bbox['y1'] * (resized_height / float(height))
gta[bbox_num, 3] = bbox['y2'] * (resized_height / float(height))
# rpn ground truth
for anchor_size_idx in range(len(anchor_sizes)):
for anchor_ratio_idx in range(n_anchratios):
anchor_x = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][0]
anchor_y = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][1]
for ix in range(output_width):
# x-coordinates of the current anchor box
x1_anc = downscale * (ix + 0.5) - anchor_x / 2
x2_anc = downscale * (ix + 0.5) + anchor_x / 2
# ignore boxes that go across image boundaries
if x1_anc < 0 or x2_anc > resized_width: # 过滤掉超出宽度边界的anchors, 不进行计算, 直接使用初始值
continue
for jy in range(output_height):
# y-coordinates of the current anchor box
y1_anc = downscale * (jy + 0.5) - anchor_y / 2
y2_anc = downscale * (jy + 0.5) + anchor_y / 2
# ignore boxes that go across image boundaries
if y1_anc < 0 or y2_anc > resized_height: # 过滤掉超出高度边界的anchors, 不进行计算, 直接使用初始值
continue
# bbox_type indicates whether an anchor should be a target
bbox_type = 'neg'
# this is the best IOU for the (x,y) coord and the current anchor
# note that this is different from the best IOU for a GT bbox
best_iou_for_loc = 0.0
for bbox_num in range(num_bboxes):
# get IOU of the current GT box and the current anchor box
curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 2], gta[bbox_num, 1], gta[bbox_num, 3]], [x1_anc, y1_anc, x2_anc, y2_anc])
# calculate the regression targets if they will be needed
if curr_iou > best_iou_for_bbox[bbox_num] or curr_iou > C.rpn_max_overlap:
cx = (gta[bbox_num, 0] + gta[bbox_num, 1]) / 2.0
cy = (gta[bbox_num, 2] + gta[bbox_num, 3]) / 2.0
cxa = (x1_anc + x2_anc)/2.0
cya = (y1_anc + y2_anc)/2.0
tx = (cx - cxa) / (x2_anc - x1_anc)
ty = (cy - cya) / (y2_anc - y1_anc)
tw = np.log((gta[bbox_num, 1] - gta[bbox_num, 0]) / (x2_anc - x1_anc))
th = np.log((gta[bbox_num, 3] - gta[bbox_num, 2]) / (y2_anc - y1_anc))
if img_data['bboxes'][bbox_num]['class'] != 'bg':
# all GT boxes should be mapped to an anchor box, so we keep track of which anchor box was best
if curr_iou > best_iou_for_bbox[bbox_num]:
best_anchor_for_bbox[bbox_num] = [jy, ix, anchor_ratio_idx, anchor_size_idx]
best_iou_for_bbox[bbox_num] = curr_iou
best_x_for_bbox[bbox_num,:] = [x1_anc, x2_anc, y1_anc, y2_anc]
best_dx_for_bbox[bbox_num,:] = [tx, ty, tw, th]
# we set the anchor to positive if the IOU is >0.7 (it does not matter if there was another better box, it just indicates overlap)
if curr_iou > C.rpn_max_overlap:
bbox_type = 'pos'
num_anchors_for_bbox[bbox_num] += 1
# we update the regression layer target if this IOU is the best for the current (x,y) and anchor position
if curr_iou > best_iou_for_loc:
best_iou_for_loc = curr_iou
best_regr = (tx, ty, tw, th)
# if the IOU is >0.3 and <0.7, it is ambiguous and no included in the objective
if C.rpn_min_overlap < curr_iou < C.rpn_max_overlap:
# gray zone between neg and pos
if bbox_type != 'pos':
bbox_type = 'neutral'
# turn on or off outputs depending on IOUs
if bbox_type == 'neg':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
elif bbox_type == 'neutral':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
elif bbox_type == 'pos':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
start = 4 * (anchor_ratio_idx + n_anchratios * anchor_size_idx)
y_rpn_regr[jy, ix, start:start+4] = best_regr
# we ensure that every bbox has at least one positive RPN region
for idx in range(num_anchors_for_bbox.shape[0]):
if num_anchors_for_bbox[idx] == 0:
# no box with an IOU greater than zero ...
if best_anchor_for_bbox[idx, 0] == -1:
continue
y_is_box_valid[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2] + n_anchratios *
best_anchor_for_bbox[idx,3]] = 1
y_rpn_overlap[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2] + n_anchratios *
best_anchor_for_bbox[idx,3]] = 1
start = 4 * (best_anchor_for_bbox[idx,2] + n_anchratios * best_anchor_for_bbox[idx,3])
y_rpn_regr[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], start:start+4] = best_dx_for_bbox[idx, :]
y_rpn_overlap = np.transpose(y_rpn_overlap, (2, 0, 1))
y_rpn_overlap = np.expand_dims(y_rpn_overlap, axis=0)
y_is_box_valid = np.transpose(y_is_box_valid, (2, 0, 1))
y_is_box_valid = np.expand_dims(y_is_box_valid, axis=0)
y_rpn_regr = np.transpose(y_rpn_regr, (2, 0, 1))
y_rpn_regr = np.expand_dims(y_rpn_regr, axis=0)
pos_locs = np.where(np.logical_and(y_rpn_overlap[0, :, :, :] == 1, y_is_box_valid[0, :, :, :] == 1))
neg_locs = np.where(np.logical_and(y_rpn_overlap[0, :, :, :] == 0, y_is_box_valid[0, :, :, :] == 1))
num_pos = len(pos_locs[0])
# one issue is that the RPN has many more negative than positive regions, so we turn off some of the negative
# regions. We also limit it to 256 regions.
num_regions = 256
if len(pos_locs[0]) > num_regions/2:
val_locs = random.sample(range(len(pos_locs[0])), len(pos_locs[0]) - num_regions/2)
y_is_box_valid[0, pos_locs[0][val_locs], pos_locs[1][val_locs], pos_locs[2][val_locs]] = 0
num_pos = num_regions/2
if len(neg_locs[0]) + num_pos > num_regions:
val_locs = random.sample(range(len(neg_locs[0])), len(neg_locs[0]) - num_pos)
y_is_box_valid[0, neg_locs[0][val_locs], neg_locs[1][val_locs], neg_locs[2][val_locs]] = 0
y_rpn_cls = np.concatenate([y_is_box_valid, y_rpn_overlap], axis=1)
y_rpn_regr = np.concatenate([np.repeat(y_rpn_overlap, 4, axis=1), y_rpn_regr], axis=1)
return np.copy(y_rpn_cls), np.copy(y_rpn_regr)
3. 对一张图片提取anchors
考虑解决以下几个问题:
- 什么是anchor?
- 一张图片需要提取多少个anchor?
- 怎么提取anchor?
同样假如输入的图片时VOC2007中的000910.jpg, 如图9所示.和前面如图2所示一样.其宽度width=500,高度height=500, 我们在本文中把这一步的图片叫做原始图片(original picture).

整个图片的处理流程如下:
- 由于将图片放入整个网络之前有时候会有一个数据增强的操作, 是随机的(包括翻转, 旋转), 但是对图片大小没有影响. 然后还需要对图片进行resize.所以会改变图片的尺寸.经过resize之后图片的width=600, height=600, 我们在本文中把resize之后的图片称为初始图片(initial picture).
- 再将resize之后的图片放入到Base Net(VGG16)里面, 最后输出的的feature map的尺寸为width=600/16=37, height=600/16=37. 我们把这一步得到的图片称为特征图谱(feature map)
- 最终计算anchors, RoI, 也就是在初始图片和特征图谱上进行的.
下面逐一解决前面提到的三个问题:
3.1 什么是anchor
其实anchor这个名字我个人感觉是作者的一个噱头, 就是为了给论文来点创新, 搞一个新的名词. 其实这个东西在以前我们都见过, 也都知道, 他有很多相近的马甲, 比如Region Proposal, RoI(region of interest). Region Proposal 和 RoI就是一个东西, 看成一样就行. 现在谈谈anchor和RoI的相同点和细微区别:
相同点:
不管是anchor还是RoI都是通过一个bbox(bounding box)来表示的, 也就是一个图片上的一个方框, 图片上的一个方框的又可以通过(x_min, y_min, x_max, y_max), (x_center, y_center, width, height)或者(x_min, y_min, width, height)来表示. 这几种表示方法可以相互转换, 在代码中会有体现. 其中:
x_min: bbox左上角那个点的x轴坐标, 也是整个方框区域所有点中x坐标最小值
y_min: bbox左上角那个点的y轴坐标, 也是整个方框区域所有点中y坐标最小值
x_max: bbox右下角那个点的x轴坐标, 也是整个方框区域所有点中x坐标最大值
y_max: bbox右下角那个点的y轴坐标, 也是整个方框区域所有点中y坐标最大值
x_center: 整个bbox中心的坐标的x轴坐标. (x_min + x_max)/2
y_center: 整个bbox中心的坐标的y轴坐标. (x_min + x_max)/2
width: 也就是bbox的宽度, width=x_max-x_min
height: 也就是bbox的高度, height=y_max-y_min
细微区别:
- anchor一般对应的是初始图片 , 也就是这种bbox是在初始图片上的bbox.
- RoI一般对应的是特征图谱, 也就是feature map, 也就是说这种bbox是在feature map上的bbox
所以, 在阅读源代码的时候, 我们可以看到很多尺度上的变换, 就是因为anchor和RoI是不同尺度上的bbox, 整个RPN的目的是提取RoI, 使用anchor只是一个中间过程, 是为了给RPN网络准备训练数据.
3.2 一张图片需要提取多少个anchors
anchor的数量由以下几个部分决定:
- 初始图片的宽度和高度。以图片000910.jpg为例子,输出图片的尺寸为(600, 600)。
- base Net网络。本文中base Net为VGG16, 则经过base Net处理后的feature map的尺度为(600/16, 600/16)=(37, 37)
- anchor_size的数量。本文所用代码使用的anchor_size = [128, 256, 512], 也即数量为3.
- anchor_ratios的数量。本文所用代码使用的anchor_ratios = [[1,1], [1/sqrt(2), sqrt(2)], [sqrt(2), 1/sqrt(2)]], 数量也是3.
结论:
最终提取的anchors的数量为:37 * 37 * 3 * 3 = 12321个anchors
3.3 怎么提取anchors
根据3.2可知,我们没张图片需要提取的anchors是12321个anchors, 这些anchor是根据图片的feature map尺寸(37, 37)来的。所以我们先将初始图片(shape=(600, 600))切分成37 × 37 块, 如下所示:

注: 图片中除了最后一行和最后一列之外, 所有的方格块都是16 × 16 的长宽。由于初始图片的长宽600无法被16整除, 所以会出先最后一列, 和最后一行的冗余。图片中所有的格子的数量就是37 × 37 = 1369
继续给出图10对应的中心点图片, 如图11所示。


这些描出来的点, 就是接下来提取anchors的参考中心点。根据前面分析, 我们会使用图片的每个点作为中心点, 提取9个不同size和aspect ratio的anchors。 图片中点的个数等于图片中方块的个数,即 37 × 37 = 1369, 所以最终提取的anchors的总数为: 1369 × 9 = 12321.
随机选择图12中的一个点, 来提取该点的9个anchors。
假设选择的点的如下图13所示。 该点所对应的方块位于图12中的第27行, 22列。因为每个方块的长和宽都是16, 所以可以简单推算出该方块的坐标(x_min, y_min, x_max, y_max)为:
x_min = 16 * ( 22 - 1 ) = 336
x_max = 16 * 22 = 352
y_min = 16 * ( 27 - 1 ) = 416
y_max = 16 * 27 = 432
进而可以推算出该方块中对应点的坐标(x_center, y_center)为:
x_center = (x_min + x_max) / 2 = 344
y_center = (y_min + y_max) / 2 = 424

使用如下代码提取该点对应的9个anchors:
import math
downscale = 16
anchor_sizes = [128, 256, 512]
anchor_ratios = [[1, 1], [1./math.sqrt(2), 2./math.sqrt(2)], [2./math.sqrt(2), 1./math.sqrt(2)]]
n_anchratios = len(anchor_ratios)
ix = 22-1 # 22指的是第22列
jy = 27-1 # 27指的是第27行
anchors = []
for anchor_size_idx in range(len(anchor_sizes)):
for anchor_ratio_idx in range(n_anchratios):
anchor_x = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][0]
anchor_y = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][1]
# x-coordinates of the current anchor box
x1_anc = downscale * (ix + 0.5) - anchor_x / 2
x2_anc = downscale * (ix + 0.5) + anchor_x / 2
# y-coordinates of the current anchor box
y1_anc = downscale * (jy + 0.5) - anchor_y / 2
y2_anc = downscale * (jy + 0.5) + anchor_y / 2
# save the current anchor
anchors.append([x1_anc, y1_anc, x2_anc, y2_anc])
该点提取的9个anchors如下图所示:




从图17可以看到, 针对一个点, 总共提取了9个anchors, 需要说明的是, 并不是所有的anchors都是有效的, 实际使用的时候会那些超出图片本身范围的anchors过滤掉.
从上述提取过程可知, 如果提取整张图片中所有 37 * 37 = 1396 个点对应的anchors, 仅仅需要在前面提取anchors的python代码中, 加上循环遍历图中的每个点就可以实现了.
4. IoU的理解和求解
首先看一下, IoU(Intersection over Union)的定义式:

可知IoU是用来衡量两个BBox的重叠情况的, IoU越大, 则两个BBox重叠越多, 否则重叠越少.计算IoU也就是计算两个BBox交集面积(AOO)除以两个BBox并集的面积(AOU).
假如两个BBox的面积分别为和, 则最终的IoU为:
以图14中的3个anchor为例子, 计算IoU, 给出初始图片中的一个ground truth叠加在图14上, 如下图所示.

从图19可以看到, 除了图14中的三个anchors(宽高比分别为1:1, 1:2, 2:1)外, 多了一个ground truth的边框, 如图中的鲜红色边框(最大的边框)所示.接下来一宽高比1:1的anchor为例计算IoU.
给出ground truth以及anchors的bbox(x_min, y_min, x_max, y_max)值如下所示:
ground truth: (295.2, 279.6, 451.2, 588)记为BB0
width:height为1:1的anchor: (280, 360, 408, 488)记为BB1
则ground truth和第一个anchor的IoU值为:
ground truth的面积为:
该anchor的面积为:
所以最终的IoU为:
Iou计算代码如下所示.其中输入的a, b分别为两个BBox
def iou(a, b):
# a and b should be (x1,y1,x2,y2)
if a[0] >= a[2] or a[1] >= a[3] or b[0] >= b[2] or b[1] >= b[3]:
return 0.0
x = max(a[0], b[0])
y = max(a[1], b[1])
w = min(a[2], b[2]) - x
h = min(a[3], b[3]) - y
if w < 0 or h < 0:
AOO = 0
else:
AOO = w * h
S_a = (a[2] - a[0]) * (a[3] - a[1])
S_b = (b[2] - b[0]) * (b[3] - b[1])
AOU = S_a + S_b - AOO
return float(AOO) / float(AOU + 1e-6)
5. BBox回归的原理
5.1 bbox回归的意义

如图20所示, 绿色的框为图片中飞机的ground truth, 假设红色的框是一个anchor, 也就是我们通过前面介绍的方法提取的anchor. 可知这个anchor虽然包含了飞机的大部分区域,但是跟ground truth相比, 还是差了一点. 而这个bbox回归就是用来修正这个anchor的, 使得其尽可能的接近ground truth.
值得注意的是, 并不是所有的anchor都可以通过bbox修正来接近ground truth的, 这个需要该anchor已经比较接近ground truth才可以.在论文 RCNN设置的 IoU>0.6才会通过bbox回归进行修正,否则直接丢弃掉.
5.2 bbox回归的求解
如图21所示, 给出三种不同颜色的框分别标记为、和. 其中:
表示提取的anchor, 待修正的bbox. 用表示
修正后的bbox. 用表示.
预测目标对应ground truth. 用
而


如图22所示, bbox回归, 就可以帮助我门修正一个不精确的anchor box到一个比较精确的bbox().
直观上看, 我们很有可能会认为bbox回归, 就是直接将作为整个模型的输入输出对来训练的.实际上并不是的.
在RCNN论文中, bbox回归:
输入的是
输出的是.
我们可以看看前面RPN网络的结构:

从图中可以看到, 最初输入的就是图片, 最后输出的两个部分, 包括anchors的分类, 还有就是anchor对应的bbox回归输出, 可以看到:
如果输入一张图片到整个网络, 且该图片的尺寸为, 其中3为通道数.则最终输出为:
rpn_out_class:
rpn_out_regress: .
也就是说, 如果算上前面base Net, 那么整个的bbox回归输入输出应该是:
输入: 初始图片
输出: 图片中anchors对应的ground truth的修正参数.
现在有个问题出现了, 怎么获取这个bbox回归的训练数据, 也就是如果有了初始图片了, 怎么获取anchors对应的ground truth的修正参数.
这里其实需要分好几步:
- 怎么通过一张图片获取anchors?
- 怎么找到每个anchors对应的ground truth?
- 那个anchors和ground truth的修正参数是怎么定义的? 怎么计算?
接下来逐一解决上面的问题:
1. 怎么通过一张图片获取anchors?
其实这个问题, 在上一节已经解决了, 这里再强调一遍, 回顾前面的过程我们发现, 对于任何一张图片, 只要给定我们提取anchors的大小(anchor_sizes)和长宽比(anchor_ratios). 则可以提取所有的anchors. 需要注意的是, 这个anchor_sizes和anchor_ratios是固定的, 对所有的输入图片来说, 都不会变化. 所以, 输入图片和和图片中的anchors是对应这的. 也就是说, 给定一张输入图片, 也就相当于给定了图片中的anchors.
再来计算一遍一张图片中anchors的数量:
输入初始图片:
anchors数量为 :
2. 怎么找到每个anchors对应的ground truth?
因为一张图片中会有多个目标, 例如图8中, 就出现了3个person目标和2个chair目标, 也就是说共有5个ground truth. 对于一个anchor来说, 有且仅有一个对应的ground truth, 通过计算和初始图片中的每个ground truth的值, 那么IoU值最大的那个ground truth就是该anchor对应的ground truth了.
3. 怎么计算anchors 和对应的ground truth的修正参数?
对于一个anchor, 例如:, 和与其对应的ground truth 如:, 则定义修正参数为:
注: 和都是一个bbox, 在前面已经介绍过, 表示一个bbox可以有不同的方法. 这里使用的就是bbox的中心点坐标, 以及bbox的宽度和高度来表示的.
在这里为了不使讨论的问题复杂化, 于是直接给出了修正参数的定义, 如果想知道这个东西为什么会这么定义, 怎么来的, 请参考[7]和[8] .
我们再来分析一下图23的输入输出, 对于输入一张初始图片, shape=(600, 600, 3), 最终输出包含一个(37, 37, 9)分类输出, 用来表征每个anchor是前景还是背景. 以及一个(37, 37, 36)的修正参数输出, 用来表征图片中anchor与其对应的ground truth的修正参数.
所以我们可以给出整个RPN网络获取训练数据的流程图如图24所示.

注意, 在faster R-CNN中IoU的阈值为0.7。图24中还有一个特殊的情况就是, 当发现于是图片中存在ground truth没有任何anchors与其IoU>0.7时, 会将所有anchors的IoU最大的那个anchor作为该ground truths的anchor, 并将其分类设置为1.
到目前为止, 可以说是基本讲完了RPN网络的来龙去脉了.接下来将会说明RPN提取出来的RoI怎么来训练接下来的R-CNN部分的
下篇: Faster R-CNN原理详解(基于keras代码)(三)
[参考链接]:
- https://zhuanlan.zhihu.com/p/31426458
- http://geyao1995.com/Faster_rcnn%E4%BB%A3%E7%A0%81%E7%AC%94%E8%AE%B0_test_2_roi_helpers/
- https://dongjk.github.io/code/object+detection/keras/2018/05/21/Faster_R-CNN_step_by_step,_Part_I.html
- 原论文:http://www.ee.bgu.ac.il/~rrtammy/DNN/reading/FastSun.pdf
- github代码: https://github.com/Jeozhao/Keras-FasterRCNN
- https://blog.csdn.net/lanchunhui/article/details/71190055
- http://caffecn.cn/?/question/160
- RCNN论文: https://arxiv.org/pdf/1311.2524.pdf