linux文件描述符限制和单机最大长连接数
linux文件描述符限制和单机最大长连接数
相关参数
linux系统中与文件描述符相关的参数有以下几个:
soft/hard nofilefile-max(/proc/sys/fs/file-max)nr_open(/proc/sys/fs/nr_open)
这三个参数的作用都是限制一个进程可以打开的最大文件数,它们之间有什么区别和联系呢?本文会从内核代码出发,分析这些参数是怎么影响文件打开的,以及它们之间什么区别,并在最后讨论一个于此有关的流行话题:单机最大长连接数。
如果你没有兴趣看内核代码,请直接跳到“文件描述符总结”处。
内核剖析
(本文中引用的内核是linux-2.6.39的代码,用于测试的操作系统为centos7 Linux 3.10.0-229.el7.x86_64)
当用户调用open时,产生中断进入内核态,内核接着调用这个函数do_sys_open:
long do_sys_open(int dfd, const char __user *filename, int flags, int mode)
{
struct open_flags op;
int lookup = build_open_flags(flags, mode, &op); // 根据传入的参数构造open_flags结构
char *tmp = getname(filename); // 对文件名做长度检测
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
fd = get_unused_fd_flags(flags); // 根据flags获取一个空闲的fd,此处为关键之一
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op, lookup); // 打开指定文件,并和之前获取的fd关联,此处为关键之二
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
}
return fd;
}
根据以上代码,文件的打开主要分为两个步骤:
- 先是获取一个空闲可用的文件描述符fd;
- 然后再打开文件,并和上一步获取的fd关联。
获取空闲fd就是这个函数get_unused_fd_flags,它实际上是个宏定义:#define get_unused_fd_flags(flags) alloc_fd(0, (flags)), 真正调用的是alloc_fd:
int alloc_fd(unsigned start, unsigned flags)
{
struct files_struct *files = current->files;// current指向当前进程的结构,而current->files管理着本进程所有打开的文件
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files); // 获取文件描述表,由此可知每个进程都维护一张文件描述符表,这张表的大小限制着本进程可以打开的文件数
fd = start;
if (fd < files->next_fd)
fd = files->next_fd;
if (fd < fdt->max_fds) // 先尝试在现有表范围内寻找未使用的fd,fdt->max_fds是文件描述符表里最大的fd
fd = find_next_zero_bit(fdt->open_fds->fds_bits,
fdt->max_fds, fd);
// 扩展文件描述表, 仅当现有表没有未使用的fd时才扩展
error = expand_files(files, fd);
if (error < 0)
goto out;
...
}
接下来看怎么扩展fdtable的, 下面才是解开真相的地方:
int expand_files(struct files_struct *files, int nr)
{
struct fdtable *fdt;
fdt = files_fdtable(files);
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
// rlimit(RLIMIT_NOFILE)的作用是获取soft nofile,当新的fd大于soft nofile时返回-EMFILE,EMFILE对应我们通常看到的错误信息“Too many open files”
if (nr >= rlimit(RLIMIT_NOFILE))
return -EMFILE;
/* Do we need to expand? */
if (nr < fdt->max_fds) // 此处判断是否需要扩展文件描述符表
return 0;
/* Can we expand? */
if (nr >= sysctl_nr_open) // sysctl_nr_open即/proc/sys/fs/nr_open。当fd大于nr_open时返回EMFILE
return -EMFILE;
/* All good, so we try */
return expand_fdtable(files, nr);
}
从上面代码可以看到,当fd大于soft nofile或者大于nr_open时,返回EMFILE。soft nofile和nr_open都限制了fd的申请,区别在于,nr_open的判断是在需要扩展fdtable的时候,因此可以理解为soft nofile直接限制打开fd的数目,而nr_open限制了fdtable的扩展(间接限制了fd的打开数目)。
另一点区别是soft nofile是进程内部的参数,修改它不影响其他进程,而nr_open是操作系统参数,修改它影响到系统的所有进程。上述代码里面的rlimit(RLIMIT_NOFILE)实际上是调用的current->signal->rlim[limit].rlim_cur,current是当前进程的结构指针,因此soft nofile是进程级别的,而sysctl_nr_open是内核全局变量,定义在file.c里面:int sysctl_nr_open __read_mostly = 1024*1024,这个值可以通过sysctl来修改。
内核在限制fd时没有用打开的fd数目来比较(内核也没有专门的变量来记录打开的fd数目)而是用fd直接比较,因为fd的申请是按从小到大顺序的,因此用fd来做数目的比较可以达到相同的效果。
至此,我们已经看到了两个参数soft nofile和nr_open它们是在fd的申请过程中起作用,再来看下文件的打开过程:
struct file *do_filp_open(int dfd, const char *pathname,
const struct open_flags *op, int flags)
{
struct nameidata nd;
struct file *filp;
// 实际的打开函数path_openat
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(dfd, pathname, &nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_REVAL);
return filp;
}
do_filp_open做了一层封装,真正起作用的是path_openat,根据路径来打开文件,并返回file指针:
static struct file *path_openat(int dfd, const char *pathname,
struct nameidata *nd, const struct open_flags *op, int flags)
{
struct file *base = NULL;
struct file *filp;
struct path path;
int error;
filp = get_empty_filp(); // 获取空闲file指针,此处为关键
if (!filp)
return ERR_PTR(-ENFILE);
filp->f_flags = op->open_flag;
nd->intent.open.file = filp;
nd->intent.open.flags = open_to_namei_flags(op->open_flag);
nd->intent.open.create_mode = op->mode;
error = path_init(dfd, pathname, flags | LOOKUP_PARENT, nd, &base);
...
}
类似于fd的申请,文件打开过程也有相似的函数get_empty_filp(),获取空闲指针,进入这个函数看看:
struct file *get_empty_filp(void)
{
const struct cred *cred = current_cred();
static long old_max;
struct file * f;
/*
* Privileged users can go above max_files
*/
// get_nr_files获取当前打开的文件数,而files_stat.max_files对应file-max参数,可以在sysctl的代码里面找到
// 下面这段代码的意思是当当前进程没有CAP_SYS_ADMIN权限的时候,才会比较file-max,
// 而root用户默认是有CAP_SYS_ADMIN权限的,这意味着当程序以root用户启动时,可打开的文件数不受file-max限制。
if (get_nr_files() >= files_stat.max_files && !capable(CAP_SYS_ADMIN)) {
/*
* percpu_counters are inaccurate. Do an expensive check before
* we go and fail.
*/
// 更精确的计算打开的文件数:所有cpu计数累加,这种操作有数据同步问题,更耗时,因此先用本cpu计数做判断。
if (percpu_counter_sum_positive(&nr_files) >= files_stat.max_files)
goto over;
}
f = kmem_cache_zalloc(filp_cachep, GFP_KERNEL);
if (f == NULL)
goto fail;
// 文件打开,计数+1
// 内核percpu counter机制,优化性能
percpu_counter_inc(&nr_files);
...
return f;
over:
/* Ran out of filps - report that */
// 当系统打开的fd超过file-max时,在log里面看到的错误信息就是从这里输出的。
// old_max的作用是仅当fd超标且一直在增加的情况下才会输出日志,减少的情况则不报日志,毕竟情况在变好嘛。
if (get_nr_files() > old_max) {
pr_info("VFS: file-max limit %lu reached\n", get_max_files());
old_max = get_nr_files();
}
goto fail;
fail_sec:
file_free(f);
fail:
return NULL;
}
从上面的代码和注释可以看出file-max是用来限制file结构的创建的,但当进程拥有CAP_SYS_ADMIN权限的时候可以突破file-max限制(man 7
capabilities),在实际应用中表现为root启动的进程不受file-max限制,也就是说nofile和nr_open有可能超过file-max,这种情况下,进程可打开的文件数就会超越file-max,这将导致其他非root启动的进程资源耗尽。
到这里一直没有看到hard nofile,hard nofile没有参与文件的打开过程,它的作用仅仅是限制soft nofile的大小,看下setrlimit的代码:
int do_prlimit(struct task_struct *tsk, unsigned int resource,
struct rlimit *new_rlim, struct rlimit *old_rlim)
{
struct rlimit *rlim;
int retval = 0;
if (resource >= RLIM_NLIMITS)
return -EINVAL;
if (new_rlim) {
// rlim_cur是soft nofile,rlim_max是hard nofile,设置的soft nofile必须小于hard nofile,否则返回失败
if (new_rlim->rlim_cur > new_rlim->rlim_max)
return -EINVAL;
// 下面这里是个意外收获,nr_open竟然和hard nofile有关系,而且hard nofile不能超过nr_open,否则返回“Operation not permitted”
if (resource == RLIMIT_NOFILE &&
new_rlim->rlim_max > sysctl_nr_open)
return -EPERM;
}
...
// 获取当前进程的rlimit
rlim = tsk->signal->rlim + resource;
task_lock(tsk->group_leader);
if (new_rlim) {
// 如果当前进程没有CAP_SYS_RESOURCE权限,则禁止设置的hard nofile超过现在的值
// 在实际应用中表现为非root用户无权提升hard nofile的值
if (new_rlim->rlim_max > rlim->rlim_max &&
!capable(CAP_SYS_RESOURCE))
retval = -EPERM;
if (!retval)
retval = security_task_setrlimit(tsk->group_leader,
resource, new_rlim);
...
}
...
}
通过上面的代码,可以知道hard nofile的作用仅仅是限制soft nofile的大小,当我们调用setrlimit设置nofile的时候,如果传入的soft nofile大于hard nofile则会返回失败。这样听起来似乎hard nofile没什么用因为很多时候我们都习惯于一起把soft nofile和hard nofile设置成一个值,但是比较安全的做法是只修改soft nofile,非必须不要修改hard nofile,改小一般不是我们想要的,但是改大hard nofile甚至超过nr_open很容易造成系统资源耗尽,导致其他进程和系统故障。最好先用getrlimit获取现在的hard nofile,然后在setrlimit时传入这个值,可以保证不修改hard nofile。
nofile、nr_open、file-max分别可以改多大?
上面提到nofile受限于nr_open,那么就先来看下nr_open,它的数据类型是int,理论上应该能达到2147483647,这个是int类型的最大值。
在设置nr_open之前先看下系统默认值:
[xuwei@localhost ~]$ cat /proc/sys/fs/nr_open
1048576
1048576正好是1024*1024,跟内核代码里面的默认值一样,现在把这个值改成2147483647:
root@localhost proc]# echo 2147483647 > /proc/sys/fs/nr_open
bash: echo: write error: Invalid argument
出错了,通过不断减小这个值,测得的最大值为2147483584,即7FFFFFC0,也就是在MAXINT(2147483647)基础上按64字节对齐:
[root@localhost proc]# echo 2147483584 > /proc/sys/fs/nr_open
[root@localhost proc]# cat /proc/sys/fs/nr_open
2147483584
因此nr_open最大值受int类型限制成立。
再看下nofile的最大值,先改hard nofile:
[root@localhost proc]# ulimit -n 2147483584 -H
[root@localhost proc]# ulimit -n 2147483585 -H
bash: ulimit: open files: cannot modify limit: Operation not permitted
[root@localhost proc]# ulimit -n -H
2147483584
hard nofile的最大值正好等于刚才设置nr_open,符合预期,接着看下soft nofile:
[root@localhost proc]# ulimit -n 2147483584 -S
[root@localhost proc]# ulimit -n 2147483585 -S
bash: ulimit: open files: cannot modify limit: Invalid argument
[root@localhost proc]# ulimit -n -S
2147483584
soft nofile的最大值等于hard nofile。
最后是file-max,它在内核里面是unsigned long类型的整数,理论上可以达到18446744073709551615, 下面来测试下:
[root@localhost proc]# echo 18446744073709551615 > /proc/sys/fs/file-max
[root@localhost proc]# cat /proc/sys/fs/file-max
18446744073709551615
[root@localhost proc]# echo 18446744073709551616 > /proc/sys/fs/file-max
[root@localhost proc]# cat /proc/sys/fs/file-max
0
可以修改成功,再大就回到0了,可见在设置file-max时内核没有对边界值做检测。不过尽管file-max可以改设置成这高,但已经意义不大了,因为打开文件时先比较nr_open,再比较file-max,所以实际可打开的文件数永远不会超过2147483584。
nofile、nr_open、file-max的大小关系
通过以上分析已经确定的是:
soft nofile <= hard nofile <= nr_open
这个是内核代码明确限制的,尚有疑惑的是nofile和file-max以及nr_open和file-max之间的大小关系。
当nofile > file-max时:
[root@localhost ~]# cat /proc/sys/fs/file-max
1000
[root@localhost ~]# ulimit -n
2147483584
[root@localhost ~]# echo a > a.txt
虽然nofile的值大于file-max,但是只要实际打开的文件没有超过file-max,即资源没有耗尽时,是没有任何关系的。虽然如此,nofile大于file-max是非常危险的,如果某个进程毫无节制的打开文件就会导致系统资源耗尽,从而导致其他进程无资源可用,系统故障、无法登陆等严重问题。
当nr_open > file-max时:
[root@localhost xuwei]# cat /proc/sys/fs/file-max
97790
[root@localhost xuwei]# cat /proc/sys/fs/nr_open
1048576
[root@localhost xuwei]# echo 80000 > /proc/sys/fs/nr_open
[root@localhost xuwei]# cat /proc/sys/fs/nr_open
80000
理论和实践证明nr_open和file-max没有直接的大小关系。虽然nr_open和file-max都是系统级参数,但是file-max限制的是系统所有进程所打开的文件的总数,它的额度是所有进程共用的,而nr_open只限制单个进程可打开的文件数,每个进程有自己独立的nr_open额度。类似于nofile,当nr_open大于file-max时,很容易造成系统资源耗尽,导致其他进程无法发文件,系统无法登陆等严重问题。
文件描述符总结
根据以上分析,文件打开流程以及三个参数对其的影响如下图所示:
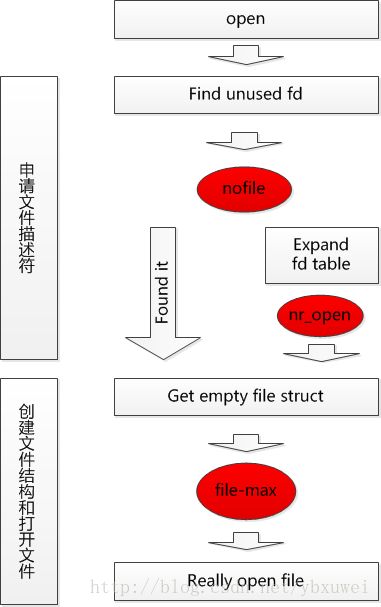
文件的打开主要分两步,即申请fd和创建文件结构两个过程,nofile和nr_open在第一个过程起作用,file-max在第二个过程起作用。nofile直接限制fd的申请,nr_open限制文件描述符表的扩展,间接限制了fd的申请,file-max限制文件的实际创建过程。
nofile,nr_open,file-max这三个参数的区别如下:
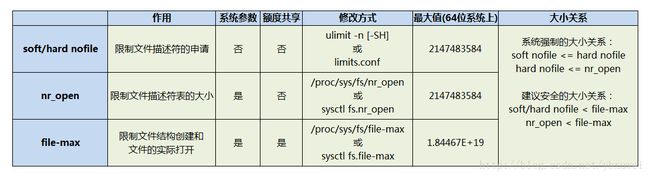
注:
- 系统参数的意思是,
nofile保存在各个进程的结构里,nr_open和file-max保存在系统变量里。 - 额度共享,
nofile和nr_open从进程级别限制,随着文件的打开,它们额度的减少不影响其他进程,file-max是系统级别的限制,一个进程多打开了一个文件,其他进程可用的file-max额度就少了一个。
单机最大长连接数?
linux系统单机支持的tcp连接数主要受三个方面的限制:
- 文件描述符的限制
- tcp本身的限制
- 系统内存限制
因为每个tcp连接都对应一个socket对象,而每个socket对象本身就占用一个文件描述符,文件描述符的限制在前文已经分析过,单机可以达到20+亿,如果不考虑其他限制,单机支持的tcp长连接数就是20+亿,这个值是非常可观的,它绝对可以满足世界上任何一个系统对长连接的需求,只要一台机器就可以哦。
谈到tcp本身的限制,就涉及到tcp四元组(远端IP,远端端口号,本地IP,本地端口号),它标识一个tcp连接。根据常识理解,IP地址限定了一台主机(准确的说是网卡),端口号则限定了这个IP上的tcp连接。对于两个tcp连接,四个参数中必然是有一个不同的,因此四元组的数目决定了tcp连接的个数。对于服务端程序来,一般来说,本地ip和本地端口号固定,因此它上面可接受的的连接数=2^32*65536=2^48(不考虑少量的特殊ip和特殊端口号),这也是个海量数字,基本可以支持世界上任何系统。对于客户端程序来说,一般本地ip、远端ip、远端口号都是固定的,因此可以支持的长连接数最多只有65536个,所以作为客户端的tcp代理比较容易出现端口号耗尽问题。
linux系统对ip没有限制,对端口号有限制,相关参数为ip_local_port_range:
[root@localhost xuwei]# cat /proc/sys/net/ipv4/ip_local_port_range
1024 65535
这两个值分别代表最小值和最大值,小于1024的端口号一般是预留给系统使用的,这不是强制的,你一定要把最小值改成小于1024也是可以的。
这个端口号范围参数ip_local_port_range对于服务端程序没太大意义,服务端监听端口号一般也就几个,对于客户端来说,比如一些tcp代理程序,或压测客户端,这些程序通常会建立很多连接,这个参数就显得很重要。
关于系统内存限制,主要是两方面,一是tcp元数据的大小,包含sock、inode、file等结构;二是tcp缓存占用空间,这又包含系统缓存和用户缓存,系统缓存是系统调用read/write使用的缓存,用户的缓存是码农在写代码时设计的缓冲区,在异步服务端程序里面用于把读写和数据解析处理分离。
我做过测试,写两个程序,服务端只接收连接,客户端只发起连接,不读写数据,客户端和服务端分别部署在两个虚拟机上,当建立50w个连接时,服务端消耗2g内存,大概每个socket占用4kb,这个4kb是内核申请的空间,并不增加用户进程的内存。至于这个4kb是由哪个部分占用的,我还么找到答案,sock、inode、file这些元数据结构加起来也就一两百字节,由于没有收发数据因此跟tcp读写缓存关系不大,而且系统默认的读写缓冲区大小均为80k+。
由于虚拟机内存有限,不能进行更多连接的测试。不过从理论上分析,在内存足够的情况下,单机应该能达到20+亿的连接,也就是文件描述符的上限。由此可见单机最大连接数主要受内存限制,至于每个连接占用多少内存,每个系统,每个应用可能都不太一样,有的应用的数据流量比较大,占用的用户缓存和系统缓存也相应的会比较大,还要以实际压测的结果为准。
(在压测过程中出现一个问题:当连接达到一定数目时,连接的速度开始变得非常慢,查看系统message日志,会看到“kernel nf_conntrack:table full, dropping packet”输出,这时候需要调整一下这个参数/proc/sys/net/netfilter/nf_conn_track_count,这是系统用来记录tcp连接的哈希表的大小)。